Analysis of the final tasks of Yandex. Algorithm 2014
On August 1, the final of our programming championship was held at the Yandex office, which opened recently in Berlin . And his winner again became known to all who are interested in sports programming, Gennady Korotkevich .
Tasks for the Algorithm were prepared by an international team. It includes programmers from Russia, Belarus, Poland and the United States. These are specialists of the Moscow State University named after MV Lomonosov University, Carnegie Mellon University, Yandex employees and Google. In Yandex, the tasks were made by the developers of the Minsk and Kiev offices, and then they were checked on their colleagues. One of the compilers last year was himself a finalist of the Algorithm. Especially for Habrakhabr we have sorted out all the tasks with the authors. By the way, despite the fact that the competition is over, you can try yourself in a virtual contest .

')
To win claimed many finalists. Among them were the winners and prize-winners of the ACM ICPC and TopCoder Open, the developers of Google and Facebook. In the final round, the winners of Algorithm 2013 fought Evgeny Kapun and Shi Bisyun, ACM ICPC champion Mikhail Kever , as well as one of the most titled sports programmers in the world, Peter Mitrichev . This year, Makoto Soezimo , the compiler of tasks for Algorithm-2013 and the administrator of TopCoder Open, also decided to compete for the prize.
The fight for the first place broke out between Gennady Korotkevich and Hosaka Katsuhiro from the University of Tokyo. The best result - four tasks at 66 minutes of penalty time - showed Korotkevich, confirming the champion title. Kazuhiro solved as many tasks, but scored more penalty time (90 minutes) and finished second. Wang Qinshi from Tsinghua University won the third place: he solved four problems with a 125-minute penalty.
Time limit: 1 second
Memory Limit: 512 mebibytes
Recently, Ksyusha's girl bought the 1024 Stack Edition application in the online store, a turn-based arcade game. As the name suggests, the game takes place around a stack filled with powers of two. According to the rules of the game, at each turn a player can perform one of three actions on the stack:
If the player chooses to add a random number to the stack, then the number 1 is added to the stack with the chance p and the number 2 is added to the chance 1- p . If the player chooses to remove the last number from the stack, he pays a 1 coin fine. Note that all other operations, except for removing the last item from the stack, do not result in a fine. In order to win, the player needs to bring the stack into such a state that there is only one element in it - 1024. At the same time, the less fine he pays, the better.
One day, Ksyusha left her phone unattended, and on her return, she discovered that someone was playing “1024 Stack Edition”. Ksyusha is not interested in knowing who it was or what his motives were. She is interested in finding out what the mathematical expectation of the fine is, which she herself will have to pay in the optimal game if she finishes the game. Your task, as you might have guessed, is to count this number.
Parsing task A
First, consider the case when N = 0 . Let f (i) be the expected minimum number of coins that need to be spent to collect the number 2 i . We present formulas for calculating f (i) if p <100. If p = 100, then the same formulas are adapted trivially.
In the case of N = 0, the answer to the problem is f (10).
Now suppose that N > 0. Denote by g (i, j) the expected smallest number of coins that we will need to spend in order to get only one number 2 j from the last (top) i stack elements. The calculation of g (i, *) for a fixed i will occur in 2 stages (by S (i) we denote the binary logarithm of the i -th top of the stack element):
1. Calculate g (i, S (i)) = 1 + min (g (i - 1; *)), i> 1 . This case corresponds to the fact that from all that is higher than the element i, we get a certain number, after which we delete it.
We also calculate g (i, S (i) + 1) = g (i - 1, S (i)) . This case corresponds to the fact that we from the elements above i collect the number 2 S (i) , and then combine it with the current element, which is also equal to 2 S (i) . For all j different from S (i) and S (i) + 1 , we set g (i, j) = + inf.
2. At the first stage, we “sorted out” the number S (i) . Before proceeding to g (i + 1, *) and the number S (i + 1) , we can perform some actions with the i- th stack element, turning it into any other element. To take this into account in dynamics, we recalculate g (i, *) as follows:
• g (i, 0) = min (g (i, 0), min (g (i, *)) + 1.0 / p) - we either use the already found value of g (i, 0) , or take any number, delete it and put there 1 = 2 0 .
• g (i, j) = min (g (i, j), min (g (i, *)) + 1 + f (j), g (i, j - 1) + f (j - 1)) , j> 0 . Here we either delete the number that stood in place i and then after f (j) of the coins put the number 2 j there , or put the number 2 j − 1 in g (i, j - 1) steps, collect in f (j - 1) steps 2 j − 1 and combine them.
The answer to the problem will be g (N, 10) . It should be noted that in intermediate calculations it is also necessary to consider g (*, 11) . The complexity of the solution is O (NR) , where R is the maximum power of two that is present in the input data (in this case, R ≤ 10 ).

Time limit: 4 seconds
Memory Limit: 512 mebibytes
Searches - what could be better? The field for entering the question, the button "find" - and the entire Internet is arranged in an ordered list of answers. Millions of search queries are saved every day in order to respond to them faster and better in the future, but this is not enough!
It is important to help the user enter the search query more quickly. For example, you can suggest popular or interesting variants of queries to the user, arranging them according to preferences. But what if we know nothing about who is asking the question? You are assigned to develop an algorithm that will offer two tips in a lexicographical order. Well, almost lexicographically.
It is known that users can make typos when entering a request. We say that line A is almost less than line B if in line A you can replace at most one letter with an arbitrary small letter of the Latin alphabet so that line A becomes lexicographically smaller than line B.
You have been given n hints. Count the number of pairs of words, the first of which is almost less than the second. The number of pairs must be calculated taking into account the order: if two words are mutually almost smaller, then consider both pairs.
Parsing task B
Consider a couple of lines s and w . A string s is almost less than a string w if and only if the minimal lexicographically string s min , which can be obtained from s by replacing one letter, is strictly less than w .
However, as is easily seen, s min is obtained from string s by replacing the first character not equal to 'a' to the character 'a'. If the string s consists only of the characters 'a', then s = s min . Consider the string s i , and find C i - the number of strings s j (possibly i = j ) such that s min i <s j . Then C i - 1 should be added to the answer if s min i ≠ s i , and C i otherwise.
To find the values of C i you can use two methods:
Time limit: 2 seconds
Memory Limit: 512 mebibytes
A cube is given whose faces are numbered with different integers from 1 to 6. Hexamino is also given, all of whose cells are numbered with different integers from 1 to 6.
Determine whether a cube can be made from a given hexamino, which can be rotated so that the numbering of the faces coincides with the numbering of the faces of the given cube, if you can only bend the hexamino along the borders of the cells, but not cut it.
Parsing task C
The main thing to notice in this problem is that hexamino can be bent in different directions. This results in two dice, differing from each other only by mutual permutation of one pair of opposite figures (since the rotation of 180 degrees rearranges two pairs of opposite figures, then the permutation of all three pairs is equivalent to the permutation of one pair).
Further there are several methods of solution. One of them consists of the following steps:
It is also possible to predict all 11 scans and then check the hexamino coincidence (turning it to the standard position), and in case of coincidence - match the pairs of numbers used to number the opposite sides of the cube with the same pairs in the scan.

Time limit: 1 second
Memory Limit: 256 mebibytes
At night, a UFO fell into a lake not far from Vasin’s house. The UFO was a frame of N -dimensional rectangular parallelepiped, assembled from titanium ribs, and all the edges had entire lengths. At the time of the collapse of the connection between the ribs collapsed, in contrast to the ribs themselves, which were on the bottom and on the shore of the lake.
In the morning, Vasya came to the shore of the lake and found K titanium rods. Assuming that these rods are the edges of the UFO frame and that, perhaps, some of the ribs are still under water, determine the smallest possible dimension of the space from which the UFO came.
Solution of Problem D
This is the easiest task of recruiting. Obviously, the dimension of the parallelepiped is not less than the number of different lengths of edges. Also note that in the K- dimensional parallelepiped 2 K-1 edges of the same type, that is, if there are X identical edges, they will be used in [(X - 1) / 2 k − 1 ] + 1 dimension.
Therefore, in ascending order, we iterate over all the dimensions, until the total number of measurements used using the above formula is less than or equal to the current dimension. Since at K = 21 edges of one type there will be 2 20 > 10 6 , the search will be small.
Time limit: 1 second
Memory Limit: 512 mebibytes
Artyomka loves matchings. A match in an undirected graph is a set of pairwise non-adjacent edges. A match is called non-complemented if it is impossible to add another edge to the match without removing any edges that are already included.
A undirected graph is called bicutal if its vertices can be divided into two sets so that any edge of the graph connects vertices from different sets.
Artem given bichromatic graph. His task is to find the number of non-complemented matchings in it modulo 1,000,000 007 (10 9 + 7). Your task is to help him.
Solving Problem E
To solve the problem, we note that the number of vertices in the left part is small.
We assume the following dynamics by adding one vertex from the right lobe: f (i, j) is the number of ways to arrange the edges in the case when we looked at the first i vertices of the right lobe, and the vertices of the left lobe are defined by the ternary mask j as follows: 0 - vertex could not be connected by an edge to any vertex from the right lobe, 1 — the vertex could be connected by an edge to one vertex from the right lobe, however we did not put this edge, 2 — the vertex was connected by an edge to one of the vertices of the right lobe.
Thus, considering the next vertex from the right lobe, we can recalculate the mask for the vertices of the left lobe. Obviously, when calculating the response, you need to consider masks without 1.
Thus, the answer is the sum f (n 2 , ValidMask) , for all ternary ValidMask masks that do not contain the units in the ternary record.

Time limit: 1 second
Memory Limit: 512 mebibytes
In the updated Yandex.Music music recommendations have become even better than before! They take into account each track listened by the user from the very beginning of using the service, and depending on the ones already listened to, they increase the pool of recommendations. The player includes the user random of the recommended tracks, and so the whole day.
But Yandex servers are so fast that they can build recommendations not only for the track that the user is listening to now, but for all the options for the following randomly selected tracks.
The user selects the first track, and then the algorithm automatically builds recommendations for N songs forward. From each song of the i -th generation, no more than Ki (1 ≤ Ki ≤ 5) of new songs in the ( i + 1) -th generation can be obtained, and for the i -th generation, the probability pi , j is known that, based on the song i- Generation j will be predicted for new j for each j from 0 to Ki .
Since experimental research was done on the indie genre, all recommended tracks are different. In order to measure the variety of statistics collected about the similarity of songs, similarity is measured for each pair of tracks. To help Yandex developers estimate the memory cost for this measurement, calculate the expectation of the number of pairs of tracks in the recommendation pool in the ( N + 1) generation.
Solution of Problem F
Let Y i be a random variable equal to the number of songs in the i -th generation. The proposed solution to the problem is based on the concept of a generating function. If you are not familiar with it, you can find it, for example, in a Wikipedia article ru.wikipedia.org/wiki/Productive_sequence_function .
Consider the generating functions of the random variables specified at the input.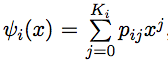 , but
, but
also generating functions of random variables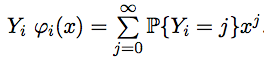 .
.
We have the explicit form of all ψ i , as well as the explicit form φ 1 (x) = x . Learn to express φ i +1 through ψ i and φ i .
If we knew for sure that Y i = k , then we could argue that φ i + 1 (x) = ψ i (x) k . But since Y i is a random variable, the desired generating function is the sum of generating functions corresponding to different values, with weights equal to the probabilities of these values, i.e.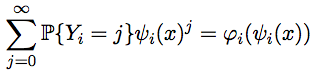 .
.
Since the maximum value of the desired quantity is very large, it is not possible to calculate the explicit form of the generating function for Y n + 1 . However, we do not need it. It is easy to see that the value to be calculated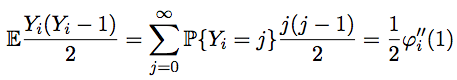
We will learn to recalculate the value, the first and second derivatives of the function φ i + 1 (x) in (1) through the previous functions. Recall that φ i (1) = ψ i (1) = 1. As we know, φ i + 1 (x) = φ i (ψ i (x)) . Then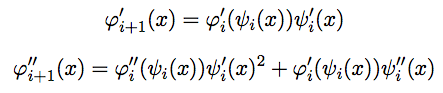
When substituting x = 1, these formulas are simplified and take the form
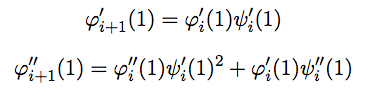
It is also easy to understand that calculations can be carried out immediately modulo 10 9 + 7, replacing the original probabilities with the corresponding modulo values.
Tasks for the Algorithm were prepared by an international team. It includes programmers from Russia, Belarus, Poland and the United States. These are specialists of the Moscow State University named after MV Lomonosov University, Carnegie Mellon University, Yandex employees and Google. In Yandex, the tasks were made by the developers of the Minsk and Kiev offices, and then they were checked on their colleagues. One of the compilers last year was himself a finalist of the Algorithm. Especially for Habrakhabr we have sorted out all the tasks with the authors. By the way, despite the fact that the competition is over, you can try yourself in a virtual contest .
')
To win claimed many finalists. Among them were the winners and prize-winners of the ACM ICPC and TopCoder Open, the developers of Google and Facebook. In the final round, the winners of Algorithm 2013 fought Evgeny Kapun and Shi Bisyun, ACM ICPC champion Mikhail Kever , as well as one of the most titled sports programmers in the world, Peter Mitrichev . This year, Makoto Soezimo , the compiler of tasks for Algorithm-2013 and the administrator of TopCoder Open, also decided to compete for the prize.
The fight for the first place broke out between Gennady Korotkevich and Hosaka Katsuhiro from the University of Tokyo. The best result - four tasks at 66 minutes of penalty time - showed Korotkevich, confirming the champion title. Kazuhiro solved as many tasks, but scored more penalty time (90 minutes) and finished second. Wang Qinshi from Tsinghua University won the third place: he solved four problems with a 125-minute penalty.
Problem A. 1024 Stack Edition
Time limit: 1 second
Memory Limit: 512 mebibytes
Recently, Ksyusha's girl bought the 1024 Stack Edition application in the online store, a turn-based arcade game. As the name suggests, the game takes place around a stack filled with powers of two. According to the rules of the game, at each turn a player can perform one of three actions on the stack:
- Add a random number to the end of the stack.
- Remove the last number from the stack.
- If the last two numbers are equal, then replace them with their sum.
If the player chooses to add a random number to the stack, then the number 1 is added to the stack with the chance p and the number 2 is added to the chance 1- p . If the player chooses to remove the last number from the stack, he pays a 1 coin fine. Note that all other operations, except for removing the last item from the stack, do not result in a fine. In order to win, the player needs to bring the stack into such a state that there is only one element in it - 1024. At the same time, the less fine he pays, the better.
One day, Ksyusha left her phone unattended, and on her return, she discovered that someone was playing “1024 Stack Edition”. Ksyusha is not interested in knowing who it was or what his motives were. She is interested in finding out what the mathematical expectation of the fine is, which she herself will have to pay in the optimal game if she finishes the game. Your task, as you might have guessed, is to count this number.
Parsing task A
First, consider the case when N = 0 . Let f (i) be the expected minimum number of coins that need to be spent to collect the number 2 i . We present formulas for calculating f (i) if p <100. If p = 100, then the same formulas are adapted trivially.
- f (0) = 1.0 / p - 1;
- f (1) = min ( f (0) • 2; 1 / (1 - p ) - 1, 1 - p);
- f (i) = 2 • f ( i - 1), i> 1.
In the case of N = 0, the answer to the problem is f (10).
Now suppose that N > 0. Denote by g (i, j) the expected smallest number of coins that we will need to spend in order to get only one number 2 j from the last (top) i stack elements. The calculation of g (i, *) for a fixed i will occur in 2 stages (by S (i) we denote the binary logarithm of the i -th top of the stack element):
1. Calculate g (i, S (i)) = 1 + min (g (i - 1; *)), i> 1 . This case corresponds to the fact that from all that is higher than the element i, we get a certain number, after which we delete it.
We also calculate g (i, S (i) + 1) = g (i - 1, S (i)) . This case corresponds to the fact that we from the elements above i collect the number 2 S (i) , and then combine it with the current element, which is also equal to 2 S (i) . For all j different from S (i) and S (i) + 1 , we set g (i, j) = + inf.
2. At the first stage, we “sorted out” the number S (i) . Before proceeding to g (i + 1, *) and the number S (i + 1) , we can perform some actions with the i- th stack element, turning it into any other element. To take this into account in dynamics, we recalculate g (i, *) as follows:
• g (i, 0) = min (g (i, 0), min (g (i, *)) + 1.0 / p) - we either use the already found value of g (i, 0) , or take any number, delete it and put there 1 = 2 0 .
• g (i, j) = min (g (i, j), min (g (i, *)) + 1 + f (j), g (i, j - 1) + f (j - 1)) , j> 0 . Here we either delete the number that stood in place i and then after f (j) of the coins put the number 2 j there , or put the number 2 j − 1 in g (i, j - 1) steps, collect in f (j - 1) steps 2 j − 1 and combine them.
The answer to the problem will be g (N, 10) . It should be noted that in intermediate calculations it is also necessary to consider g (*, 11) . The complexity of the solution is O (NR) , where R is the maximum power of two that is present in the input data (in this case, R ≤ 10 ).
Problem B. Line task
Time limit: 4 seconds
Memory Limit: 512 mebibytes
Searches - what could be better? The field for entering the question, the button "find" - and the entire Internet is arranged in an ordered list of answers. Millions of search queries are saved every day in order to respond to them faster and better in the future, but this is not enough!
It is important to help the user enter the search query more quickly. For example, you can suggest popular or interesting variants of queries to the user, arranging them according to preferences. But what if we know nothing about who is asking the question? You are assigned to develop an algorithm that will offer two tips in a lexicographical order. Well, almost lexicographically.
It is known that users can make typos when entering a request. We say that line A is almost less than line B if in line A you can replace at most one letter with an arbitrary small letter of the Latin alphabet so that line A becomes lexicographically smaller than line B.
You have been given n hints. Count the number of pairs of words, the first of which is almost less than the second. The number of pairs must be calculated taking into account the order: if two words are mutually almost smaller, then consider both pairs.
Parsing task B
Consider a couple of lines s and w . A string s is almost less than a string w if and only if the minimal lexicographically string s min , which can be obtained from s by replacing one letter, is strictly less than w .
However, as is easily seen, s min is obtained from string s by replacing the first character not equal to 'a' to the character 'a'. If the string s consists only of the characters 'a', then s = s min . Consider the string s i , and find C i - the number of strings s j (possibly i = j ) such that s min i <s j . Then C i - 1 should be added to the answer if s min i ≠ s i , and C i otherwise.
To find the values of C i you can use two methods:
- sort the strings s i and find C i by a binary search;
- add all lines in trie , and find C i by descending through it.
Problem C. Cube
Time limit: 2 seconds
Memory Limit: 512 mebibytes
A cube is given whose faces are numbered with different integers from 1 to 6. Hexamino is also given, all of whose cells are numbered with different integers from 1 to 6.
Determine whether a cube can be made from a given hexamino, which can be rotated so that the numbering of the faces coincides with the numbering of the faces of the given cube, if you can only bend the hexamino along the borders of the cells, but not cut it.
Parsing task C
The main thing to notice in this problem is that hexamino can be bent in different directions. This results in two dice, differing from each other only by mutual permutation of one pair of opposite figures (since the rotation of 180 degrees rearranges two pairs of opposite figures, then the permutation of all three pairs is equivalent to the permutation of one pair).
Further there are several methods of solution. One of them consists of the following steps:
- Set the cube with the bottom side on the appropriate hexamino cell.
- For each of the four turns of the cube around its axis, we begin to roll it along the hexamino until it is possible to roll the cube so that the lower edge falls on the cell with the corresponding number.
- If for any of the turns all 6 cells are visited, then the answer is “Yes”.
- If not, then swap the numbers on the right and left sides and repeat the procedure from step 2.
- If in this case all 6 cells are not visited at any of the turns, then the answer is “No”.
It is also possible to predict all 11 scans and then check the hexamino coincidence (turning it to the standard position), and in case of coincidence - match the pairs of numbers used to number the opposite sides of the cube with the same pairs in the scan.
Task D. UFO
Time limit: 1 second
Memory Limit: 256 mebibytes
At night, a UFO fell into a lake not far from Vasin’s house. The UFO was a frame of N -dimensional rectangular parallelepiped, assembled from titanium ribs, and all the edges had entire lengths. At the time of the collapse of the connection between the ribs collapsed, in contrast to the ribs themselves, which were on the bottom and on the shore of the lake.
In the morning, Vasya came to the shore of the lake and found K titanium rods. Assuming that these rods are the edges of the UFO frame and that, perhaps, some of the ribs are still under water, determine the smallest possible dimension of the space from which the UFO came.
Solution of Problem D
This is the easiest task of recruiting. Obviously, the dimension of the parallelepiped is not less than the number of different lengths of edges. Also note that in the K- dimensional parallelepiped 2 K-1 edges of the same type, that is, if there are X identical edges, they will be used in [(X - 1) / 2 k − 1 ] + 1 dimension.
Therefore, in ascending order, we iterate over all the dimensions, until the total number of measurements used using the above formula is less than or equal to the current dimension. Since at K = 21 edges of one type there will be 2 20 > 10 6 , the search will be small.
Problem E. Incomplete matching
Time limit: 1 second
Memory Limit: 512 mebibytes
Artyomka loves matchings. A match in an undirected graph is a set of pairwise non-adjacent edges. A match is called non-complemented if it is impossible to add another edge to the match without removing any edges that are already included.
A undirected graph is called bicutal if its vertices can be divided into two sets so that any edge of the graph connects vertices from different sets.
Artem given bichromatic graph. His task is to find the number of non-complemented matchings in it modulo 1,000,000 007 (10 9 + 7). Your task is to help him.
Solving Problem E
To solve the problem, we note that the number of vertices in the left part is small.
We assume the following dynamics by adding one vertex from the right lobe: f (i, j) is the number of ways to arrange the edges in the case when we looked at the first i vertices of the right lobe, and the vertices of the left lobe are defined by the ternary mask j as follows: 0 - vertex could not be connected by an edge to any vertex from the right lobe, 1 — the vertex could be connected by an edge to one vertex from the right lobe, however we did not put this edge, 2 — the vertex was connected by an edge to one of the vertices of the right lobe.
Thus, considering the next vertex from the right lobe, we can recalculate the mask for the vertices of the left lobe. Obviously, when calculating the response, you need to consider masks without 1.
Thus, the answer is the sum f (n 2 , ValidMask) , for all ternary ValidMask masks that do not contain the units in the ternary record.
Problem F. The musical world
Time limit: 1 second
Memory Limit: 512 mebibytes
In the updated Yandex.Music music recommendations have become even better than before! They take into account each track listened by the user from the very beginning of using the service, and depending on the ones already listened to, they increase the pool of recommendations. The player includes the user random of the recommended tracks, and so the whole day.
But Yandex servers are so fast that they can build recommendations not only for the track that the user is listening to now, but for all the options for the following randomly selected tracks.
The user selects the first track, and then the algorithm automatically builds recommendations for N songs forward. From each song of the i -th generation, no more than Ki (1 ≤ Ki ≤ 5) of new songs in the ( i + 1) -th generation can be obtained, and for the i -th generation, the probability pi , j is known that, based on the song i- Generation j will be predicted for new j for each j from 0 to Ki .
Since experimental research was done on the indie genre, all recommended tracks are different. In order to measure the variety of statistics collected about the similarity of songs, similarity is measured for each pair of tracks. To help Yandex developers estimate the memory cost for this measurement, calculate the expectation of the number of pairs of tracks in the recommendation pool in the ( N + 1) generation.
Solution of Problem F
Let Y i be a random variable equal to the number of songs in the i -th generation. The proposed solution to the problem is based on the concept of a generating function. If you are not familiar with it, you can find it, for example, in a Wikipedia article ru.wikipedia.org/wiki/Productive_sequence_function .
Consider the generating functions of the random variables specified at the input.
, butalso generating functions of random variables
.We have the explicit form of all ψ i , as well as the explicit form φ 1 (x) = x . Learn to express φ i +1 through ψ i and φ i .
If we knew for sure that Y i = k , then we could argue that φ i + 1 (x) = ψ i (x) k . But since Y i is a random variable, the desired generating function is the sum of generating functions corresponding to different values, with weights equal to the probabilities of these values, i.e.
.Since the maximum value of the desired quantity is very large, it is not possible to calculate the explicit form of the generating function for Y n + 1 . However, we do not need it. It is easy to see that the value to be calculated
We will learn to recalculate the value, the first and second derivatives of the function φ i + 1 (x) in (1) through the previous functions. Recall that φ i (1) = ψ i (1) = 1. As we know, φ i + 1 (x) = φ i (ψ i (x)) . Then
When substituting x = 1, these formulas are simplified and take the form
It is also easy to understand that calculations can be carried out immediately modulo 10 9 + 7, replacing the original probabilities with the corresponding modulo values.
Source: https://habr.com/ru/post/231939/
All Articles