Similar search queries in hh.ru
Most major search engines and services have a mechanism for similar search queries, when the user is offered options that are thematically close to what he was looking for. So do in google, yandex, bing, amazon, a few days ago it appeared and on hh.ru!
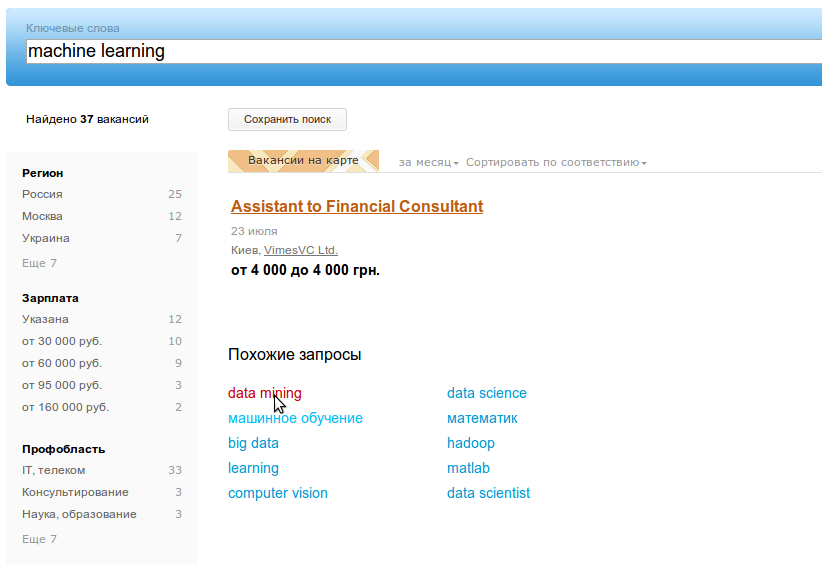
In this article I will tell about how we extracted similar search queries from the logs of the site hh.ru.
First, a few words about what “related queries” are (why) and why they are needed.
')
We have long thought about this feature, but the final push was given by a great article from LinkedIn about their implementation of similar queries - metaphor . It describes three methods for extracting such queries from the search activity of users, which we have implemented.
The simplest and most obvious of the related query extraction algorithms is overlap or search for intersecting queries.

We split all search phrases into tokens and find queries with common tokens. In reality, such requests can be very much, so the question arises about choosing the most appropriate. Following common sense, you can define two rules: the more tokens intersect, the closer the requests, and the intersection in rare tokens is more powerful than in widely used tokens. From here we get the formula:

where overlap is the number of common tokens in q1 and q2 queries,
Q (t) - the number of requests from tokens t,
N is the number of unique queries.
The next way is collaborative filtering (CF) . It is often used in recommender systems and is well suited for recommending similar requests. Behind the complex name is a simple assumption that during one session the user makes related requests. Moreover, when looking for a job, a long session can be neglected, because user preferences change slowly. It is hard to imagine that the applicant, who is currently making the request “personal driver”, will be looking for job openings for “java developer” tomorrow. But this assumption is not true for employers, they can look for candidates for very different jobs even for one hour.

So, with collaborative filtering, for each user we find all the requests made by him for a certain period and form pairs of them. To select the most frequent pairs we use the variation of the formula tf-idf.

where tf is the number of pairs of queries q1 and q2 ,
df is the number of pairs containing the q2 query,
N is the number of unique queries,
c = 0.1, this value is still hardcoded, but it can be chosen from user behavior.
df does not allow the most common requests like “manager” and “accountant” to appear in recommendations too often.
The third QRQ algorithm (query-result-query) is similar to CF, but we build pairs of queries not by user, but by job.

Those. We consider similar requests for which they go to the same vacancy. Having found all the pairs of requests, it remains for us to choose the most suitable of them. To do this, we need to find the most popular pairs, not forgetting to reduce the weight of frequency requests and vacancies. LinkedIn in its article offers the following formulas, and they provide interesting results even for rare requests: for example, for “probability theory”, related queries are “algorithmic trading” and “futures”.



Despite the fact that the formulas look complicated, there are simple things behind them. V is the contribution of the vacancy to the total rank: the ratio of the number of views of a vacancy on request q to the total number of views of this vacancy. Similarly, Q is the contribution of a query: the ratio of the number of views of a vacancy for a query q to the number of views of other vacancies for that query.
It should be noted that the last two methods are not symmetrical, i.e.

We implemented the above algorithms with hadoop and hive. Hadoop is a system for distributing “big data” storage, managing a cluster, and performing distributed computing. Every night we upload access logs of the site for the past day, while transforming them into a convenient structure for analysis.

We also use Apache Hive, an add-on for Hadoop, which allows us to formulate queries to data in the form of HiveQL (SQL-like language of zaros). HiveQL does not conform to SQL standards, but allows you to do join and subselect, contains many functions for working with strings, dates, numbers and arrays. Able to do Group By and supports various aggregate functions and window-functions. Allows you to write your map, reduce and transform functions in any programming language. For example, in order to get the most popular search queries per day, you need to run this HiveQL:
Before you start “mining” similar requests, they need to be cleaned of garbage and normalized. We did the following:
After such a modification, the request “tender department chief” turned into “# 0d26431546 head department”. You can’t show this to users, so we’ll change this code to the most popular request form “Tender Manager”.
Then we proceed to the implementation of the algorithms described above, which consists in applying several successive transformations of the original logs. All transformations are written in HiveQL, which is probably not very optimal in terms of performance, but it is simple, visual, and takes up a few lines of code. The figure shows the data transformations for collaborative filtering. QRQ is implemented similarly.

In order not to recommend “junk” requests, we drove each request through the search for vacancies on hh.ru and threw out all for which there are less than 5 results.
The final stage of the task is to combine the results of the three algorithms. We considered two options: show users three top queries from each method or try to sum up the weights. We chose the second method, normalizing before summing the weight:

And everything seemed to work out quite well, but for some queries strange results came out: “novice specialist” -> “career head”. First, here we were summed up by stemming, which “career” and “career” leads to one form. And secondly, it turned out that the three weights found had a different distribution and simply cannot be summed up.

I had to bring them to the same scale. To do this, each weight was sorted in ascending order, numbered, and the resulting sequence number was divided by the total number of pairs of queries for a particular algorithm. This number has become a new weight, the problem with the “boss of the pit” has disappeared.
To find similar search queries, we used hh.ru logs for 4 months, which is 270 million searches and 1.2 billion page views of vacancies. In total, users made about 1.5 million unique text queries, after cleaning and normalization, we left a little over 70 thousand.
Already for the first day of this feature, about 50 thousand people took advantage of the correction of requests. Most popular fixes:
driver -> personal driver
administrator -> beauty salon administrator
driver -> driver with private car
Accountant -> Accountant for primary documentation
Accountant -> Deputy Chief Accountant
Corrections of popular queries in the it sphere:
It was interesting to see in which professional areas this feature is most in demand:

It is seen that more than half of the students who were looking for jobs, tried other requests. The least popular feature is IT and Consulting.
What else would like to do:
Metaphor: A System for Related Search Recommendations
Apache hadoop
Apache heve
In this article I will tell about how we extracted similar search queries from the logs of the site hh.ru.
First, a few words about what “related queries” are (why) and why they are needed.
')
- First, not all job seekers represent exactly what they want to find. Often, they simply examine offers in several areas of activity, introducing different requests. This behavior is particularly pronounced for students starting their careers, and for applicants without a specific specialty. For such a surf will be useful hints for the correct requests.
- Often, applicants enter too general a request, for example, a “ manager in Moscow ”, who has more than 18,000 vacancies. Of these, it is difficult to choose something suitable, so the request should be narrowed down, for example, to “ sales manager of building materials ”.
- Too narrow requests, on the contrary, can lead to a blank issue. For example, the query “ trainee accountant for payroll accounting ” is not found, but if it is corrected for the more general “ accountant trainee ”, several results appear.
- Sometimes job seekers and employers speak different languages. For example, a vacancy is called an “truck mixer driver”, and the applicant is looking for a “mixer driver”. Usually we try to solve this problem with the help of synonyms, but this is not always possible. Related queries should help the user formulate a search in the language of employers.
- The most interesting case, in my opinion, when the applicant knows what he wants to find, and clearly articulates his request. But he can not guess about the existing area of activity that could interest him. For example, “soil scientist” will want to do “ecology”. This problem is usually solved by personal recommendations, but similar requests may push such a specialist to interesting vacancies, “move” him to another area of job search.
We have long thought about this feature, but the final push was given by a great article from LinkedIn about their implementation of similar queries - metaphor . It describes three methods for extracting such queries from the search activity of users, which we have implemented.
Methods for determining similar queries
The simplest and most obvious of the related query extraction algorithms is overlap or search for intersecting queries.
We split all search phrases into tokens and find queries with common tokens. In reality, such requests can be very much, so the question arises about choosing the most appropriate. Following common sense, you can define two rules: the more tokens intersect, the closer the requests, and the intersection in rare tokens is more powerful than in widely used tokens. From here we get the formula:
where overlap is the number of common tokens in q1 and q2 queries,
Q (t) - the number of requests from tokens t,
N is the number of unique queries.
The next way is collaborative filtering (CF) . It is often used in recommender systems and is well suited for recommending similar requests. Behind the complex name is a simple assumption that during one session the user makes related requests. Moreover, when looking for a job, a long session can be neglected, because user preferences change slowly. It is hard to imagine that the applicant, who is currently making the request “personal driver”, will be looking for job openings for “java developer” tomorrow. But this assumption is not true for employers, they can look for candidates for very different jobs even for one hour.
So, with collaborative filtering, for each user we find all the requests made by him for a certain period and form pairs of them. To select the most frequent pairs we use the variation of the formula tf-idf.
where tf is the number of pairs of queries q1 and q2 ,
df is the number of pairs containing the q2 query,
N is the number of unique queries,
c = 0.1, this value is still hardcoded, but it can be chosen from user behavior.
df does not allow the most common requests like “manager” and “accountant” to appear in recommendations too often.
The third QRQ algorithm (query-result-query) is similar to CF, but we build pairs of queries not by user, but by job.
Those. We consider similar requests for which they go to the same vacancy. Having found all the pairs of requests, it remains for us to choose the most suitable of them. To do this, we need to find the most popular pairs, not forgetting to reduce the weight of frequency requests and vacancies. LinkedIn in its article offers the following formulas, and they provide interesting results even for rare requests: for example, for “probability theory”, related queries are “algorithmic trading” and “futures”.
Despite the fact that the formulas look complicated, there are simple things behind them. V is the contribution of the vacancy to the total rank: the ratio of the number of views of a vacancy on request q to the total number of views of this vacancy. Similarly, Q is the contribution of a query: the ratio of the number of views of a vacancy for a query q to the number of views of other vacancies for that query.
It should be noted that the last two methods are not symmetrical, i.e.
Implementation
We implemented the above algorithms with hadoop and hive. Hadoop is a system for distributing “big data” storage, managing a cluster, and performing distributed computing. Every night we upload access logs of the site for the past day, while transforming them into a convenient structure for analysis.
We also use Apache Hive, an add-on for Hadoop, which allows us to formulate queries to data in the form of HiveQL (SQL-like language of zaros). HiveQL does not conform to SQL standards, but allows you to do join and subselect, contains many functions for working with strings, dates, numbers and arrays. Able to do Group By and supports various aggregate functions and window-functions. Allows you to write your map, reduce and transform functions in any programming language. For example, in order to get the most popular search queries per day, you need to run this HiveQL:
SELECT lower(query_all_values['text']), count(*) c FROM access_raw WHERE year=2014 AND month=7 AND day=16 AND path='/search/vacancy' AND query_all_values['text'] IS NOT NULL GROUP BY lower(query_all_values['text']) ORDER BY c DESC LiMIT 10; Before you start “mining” similar requests, they need to be cleaned of garbage and normalized. We did the following:
- threw out long requests (more than 5 words and 100 characters),
- removed the garbage symbols and words of the grammar query
- applied stemming
- combined synonyms
- sorted words.
After such a modification, the request “tender department chief” turned into “# 0d26431546 head department”. You can’t show this to users, so we’ll change this code to the most popular request form “Tender Manager”.
Then we proceed to the implementation of the algorithms described above, which consists in applying several successive transformations of the original logs. All transformations are written in HiveQL, which is probably not very optimal in terms of performance, but it is simple, visual, and takes up a few lines of code. The figure shows the data transformations for collaborative filtering. QRQ is implemented similarly.
In order not to recommend “junk” requests, we drove each request through the search for vacancies on hh.ru and threw out all for which there are less than 5 results.
The final stage of the task is to combine the results of the three algorithms. We considered two options: show users three top queries from each method or try to sum up the weights. We chose the second method, normalizing before summing the weight:
And everything seemed to work out quite well, but for some queries strange results came out: “novice specialist” -> “career head”. First, here we were summed up by stemming, which “career” and “career” leads to one form. And secondly, it turned out that the three weights found had a different distribution and simply cannot be summed up.
I had to bring them to the same scale. To do this, each weight was sorted in ascending order, numbered, and the resulting sequence number was divided by the total number of pairs of queries for a particular algorithm. This number has become a new weight, the problem with the “boss of the pit” has disappeared.
results
To find similar search queries, we used hh.ru logs for 4 months, which is 270 million searches and 1.2 billion page views of vacancies. In total, users made about 1.5 million unique text queries, after cleaning and normalization, we left a little over 70 thousand.
Already for the first day of this feature, about 50 thousand people took advantage of the correction of requests. Most popular fixes:
driver -> personal driver
administrator -> beauty salon administrator
driver -> driver with private car
Accountant -> Accountant for primary documentation
Accountant -> Deputy Chief Accountant
Corrections of popular queries in the it sphere:
| System Administrator | system administrator assistant, helpdesk, windows system administrator |
| programmer | C ++ programmer, remote programmer, c # programmer |
| Technical Director | Director of Operations, Deputy Technical Director, Technical Manager |
| tester | testing specialist, game tester, remote tester |
| junior | java junior, junior c ++, junior qa |
It was interesting to see in which professional areas this feature is most in demand:
It is seen that more than half of the students who were looking for jobs, tried other requests. The least popular feature is IT and Consulting.
Todo
What else would like to do:
- Automate Now related requests are built once for the period from January 1 to May 1, 2014. When automating, you need not forget about protection against vulnerabilities, because, knowing the algorithms, it is easy to create advertisements or simply hooligans instead of related queries.
- Experiment with algorithm weights and conduct AB testing to show the most useful queries.
- Consider the number of results for the query: suggest only those queries for which there are guaranteed results. Even with a large number of vacancies found, it will be useful to show narrowing requests, and for small ones, expanding ones.
- Related queries in resume search.
- Use in suggest.
Links
Metaphor: A System for Related Search Recommendations
Apache hadoop
Apache heve
Source: https://habr.com/ru/post/231393/
All Articles