Why you should never use MongoDB
Disclaimer from the author (the author is a girl): I do not develop database engines. I create web applications. I participate in 4-6 different projects every year, that is, I create many web applications. I see many applications with different requirements and different data storage needs. I unwrapped most of the repositories that you’ve heard about, and several that you don’t even suspect.
Several times I made the wrong choice of DBMS. This story is about one such choice - why we made such a choice, how we would know that the choice was wrong and how we struggled with it. It all happened on an open source project called Diaspora.
Diaspora is a distributed social network with a long history. A long time ago, in 2010, four students at New York University published a video on Kickstarter asking them to donate $ 10,000 to develop a distributed alternative to Facebook. They sent the link to friends, family and hoped for the best.
But they hit the nail on the head. Another scandal has just died down because of privacy on Facebook, and when the dust settled they received $ 200,000 investment from 6,400 people for a project that had not yet written a single line of code.
')
Diaspora was one of the first Kickstarter projects that managed to significantly exceed the target. As a result, they were written about in the New York Times newspaper, which turned out to be a scandal, because an indecent joke was written on the board against the photograph of the team, but nobody noticed that until the photo was printed ... in the New York Times. So I found out about this project.
As a result of the success on Kickstarter, the guys quit studying and moved to San Francisco to start writing code. So they were in my office. At that time, I worked at Pivotal Labs and one of the elder brothers of the Diaspora developers also worked at this company, so Pivotal offered the guys jobs, the Internet, and, of course, access to the fridge with beer. I worked with the company's official clients, and in the evenings I hung out with the guys and wrote the code on weekends.
They ended up staying at Pivotal for more than two years. However, by the end of the first summer they had a minimal, but working (in a sense) implementation of a distributed social network on Ruby on Rails, using MongoDB for data storage.
Quite a few baszvorodov - let's see.
If you've seen Facebook, then you know everything you need to know about Facebook. This web application, it exists in a single copy and allows you to communicate with people. The Diaspora interface looks almost the same as Facebook.
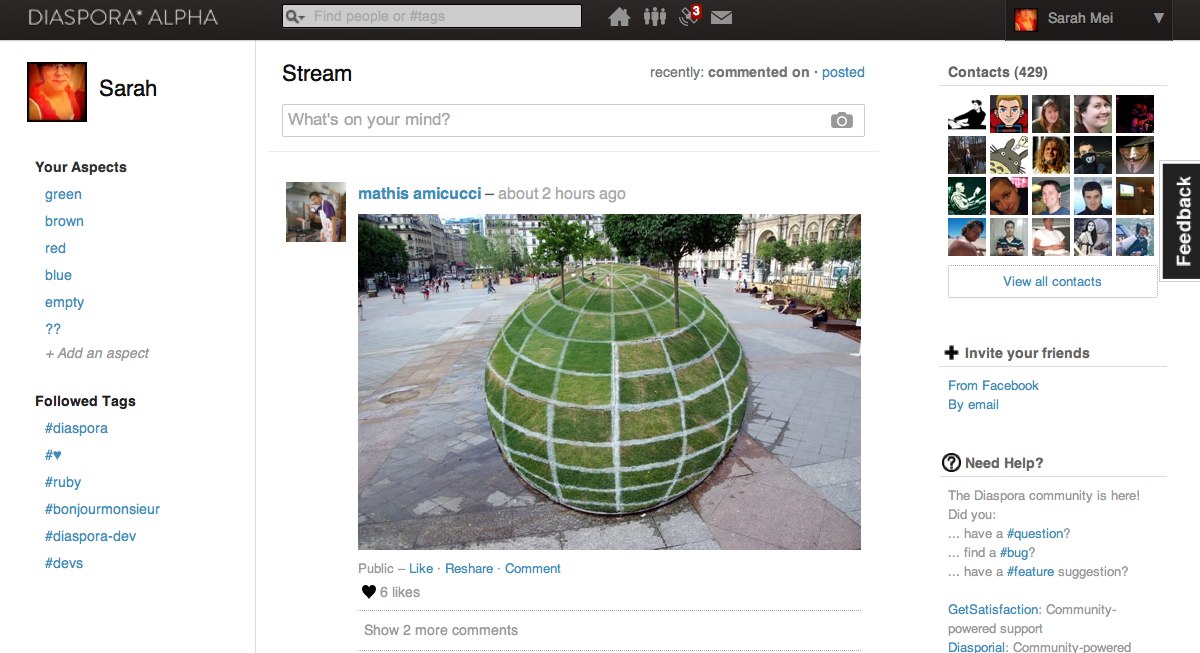
The message line in the middle shows the posts of all your friends, and around it is a pile of garbage that no one pays attention to. The main difference between Diaspora and Facebook is invisible to users, this is the “distributed” part.
The infrastructure of Disapora is not located behind a single web address. There are hundreds of independent copies of Diaspora. The code is open, so you can deploy your servers. Each copy is called a pod. It has its own database and its own set of users. Each Pod interacts with other Pods, which also have their own base and their users.
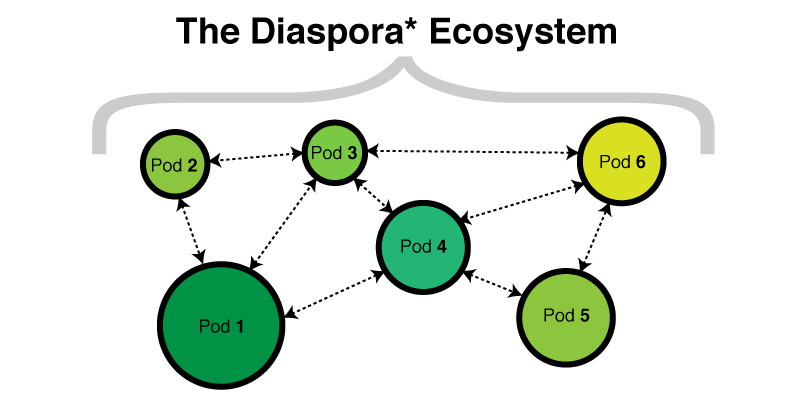
Pods communicate using API based on the HTTP protocol (now it is fashionable to call it REST API - approx. Lane ). When you unwrap your Pod, it will be pretty boring until you add friends. You can add as a friend to users in your Pod, or in other Pods. When someone publishes something, this is what happens:
Comments work the same way. Each message can be commented on by users from the same Pod as well as people from other Pods. Anyone who has permission to view the message will also see all comments. As if everything happens in one application.
There are technical and legal advantages of this architecture. The main technical advantage is fault tolerance.

(such a fail-safe system should be available in every office)
If one of the pods falls, then all others continue to work. The system causes, and even expects, network separation. The political implications of this are, for example, if in your country they block access to Facebook or Twitter, your local Pod will be available to other people in your country, even if everyone else is not available.
The main legal advantage is server independence. Each Pod is a legally independent entity, governed by the laws of the country where the Pod is located. Each Pod can also set its own terms, on most you do not give up rights to all content, such as on Facebook or Twitter. Diaspora is free software, both in the “free” sense, and in the “independent” sense. Most of those who run their Pods are very concerned.
This is the system architecture, let's look at the architecture of a single Pod.
Each Pod is a Ruby on Rails application with its MongoDB base. In a sense, this is a “typical” Rails application — it has a user interface, a programming API, Ruby logic, and a database. But in all other respects it is far from typical.

The API is used for mobile clients and for "federation", that is, for interaction between Pods. Distribution adds several layers of code that are absent in a typical application.
And, of course, MongoDB is far from a typical choice for web applications. Most Rails applications use PostgreSQL or MySQL. (as of 2010 - approx. lane. )
So here's the code. Consider what data we store.
“Social data” is information about our network of friends, their friends and their activities. Conceptually, we think of it as a network — an undirected graph in which we are in the center, and our friends are around us.

(Photos from rubyfriends.com. Thanks to Matt Rogers, Steve Klabnik, Nell Shamrell, Katrina Owen, Sam Livingston Gray, Josh Sasser, Akshay Khole, Pradyumna Dandwate and Hefziba Watharkar for contributing to # rubyfriends!)
When we store social data, we save both topology and actions.
For several years now we have known that social data is not relational, if you store social data in a relational database, then you are doing it wrong.
But what are the alternatives? Some argue that graph databases are best suited, but I will not consider them, since they are too niche for mass projects. Others say that documentary data is ideal for social data, and they are fairly mainstream for real use. Let's take a look at why people think that MongoDB is much better suited for social data than PostgreSQL.
MongoDB is a document database. Instead of storing data in tables consisting of separate rows , as in relational databases, MongoDB stores data in collections consisting of documents . A document is a large JSON object with no predefined format and schema.
Let's look at the set of links that you need to model. This is very similar to the projects in Pivotal for which MongoDB was used, and this is the best use case for a document database engine I have ever seen.
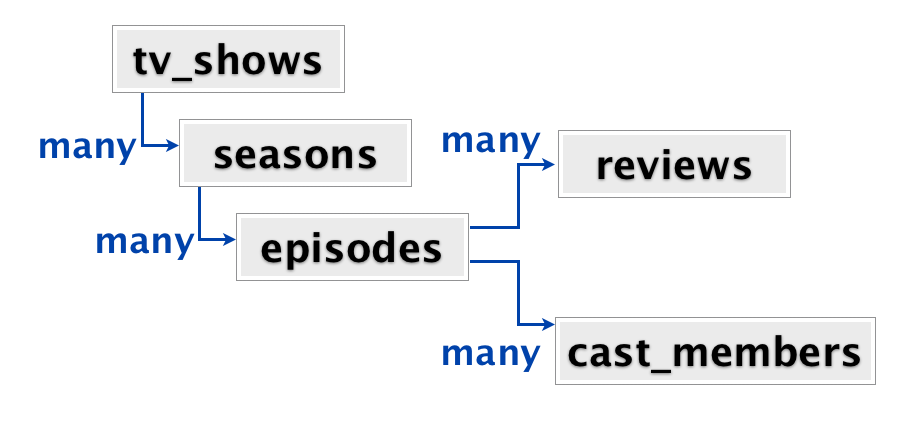
At the root we have a series of TV shows. Each series can have many seasons, each season has many episodes, each episode has many reviews and many actors. When a user comes to the site, he usually gets to the page of a particular series. The page displays all seasons, episodes, reviews and actors, all on one page. From the point of view of the application, when the user hits the page we want to get all the information related to the series.
This data can be modeled in several ways. In a typical relational repository, each of the rectangles will be a table. You will have the tv_shows table, the seasons table with a foreign key in tv_shows, the episodes table with a foreign key in seasons, reviews, and cast_members of a table with foreign keys in the episodes. Thus, to get all the information about the series, you need to join five tables.
We could also model this data as a set of nested objects (a set of key-value pairs). A lot of information about a particular series is one big structure of nested key-value sets. Inside the series, there are many seasons, each of which is also an object (a set of key-value pairs). Within each season, an array of episodes, each of which represents an object, and so on. So in MongoDB model the data. Each series is a document that contains all the information about one series.
Here is an example of a document of one series, Babylon 5:

The show has a name and an array of seasons. Each season - an object with metadata and an array of episodes. In turn, each episode has metadata and arrays of reviews and actors.
Looks like a huge fractal data structure.

(Many sets of sets. Delicious fractals.)
All data needed for the series is stored in one document, so you can get all the information very quickly at once, even if the document is very large. There is a series called General Hospital, which has 12,000 episodes for 50+ seasons. On my laptop, PostgreSQL runs for about a minute to get denormalized data for 12,000 episodes, while retrieving a document by ID in MongoDB takes a fraction of a second.
So in many ways, this application implements the ideal use for the document base.
Right. When you get into a social network, there is only one important part of the page: your activity feed. The request feed activity gets all the posts from your friends, sorted by date. Each post contains attachments such as photos, likes, reposts and comments.
The nested structure of the activity tape looks very similar to the serials.
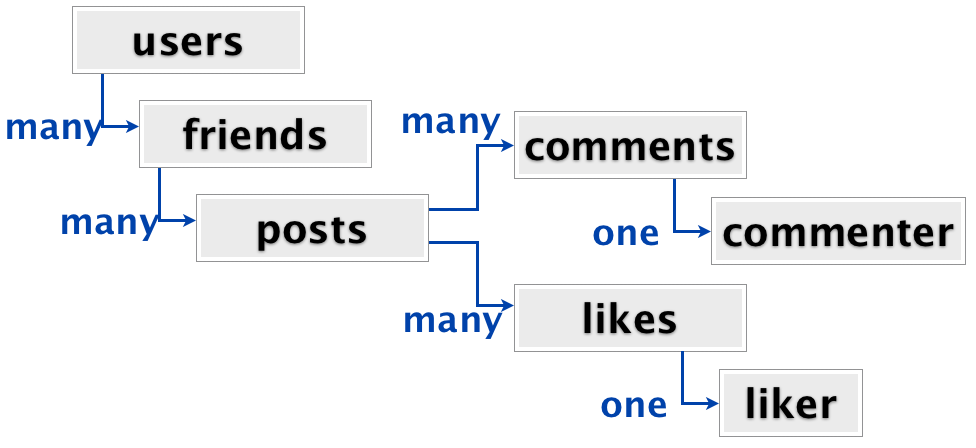
Users have friends, friends have posts, posts have comments and likes, each of which is associated with one commentator or likes. From the point of view of connections, this is not much more complicated than the structure of television series. And as in the case of serials, we want to get the whole structure at once as soon as the user enters the social network. In a relational DBMS, this would be a join of seven tables to pull out all the data.
The connection of seven tables, oh. Suddenly, saving the entire user tape as a single denormalized data structure, instead of doing joins, looks very attractive. (In PostgreSQL, such joins are slowly working cause pain - approx. Lane. )
In 2010, the Diaspora team made such a decision, Esty’s articles on using documentary DBMS turned out to be very convincing, even though they publicly rejected MongoDB in consequence. In addition, at this time, the use of Cassandra on Facebook spawned a lot of talk about abandoning relational databases. The choice of MongoDB for Disapora was in the spirit of the time. It was not an unreasonable choice at that time, given the knowledge that they had.
There is a very important difference between the social data of Diaspora and Mongo-ideal data about serials, which no one noticed at first glance.
With serials, each rectangle in the relationship diagram has a different type. Series differ from seasons, differ from episodes, differ from reviews, differ from actors. None of them is even a subtype of another type.
But with social data, some of the rectangles in the relationship diagram are of the same type. In fact, all these green rectangles of the same type are all users of the diaspora.
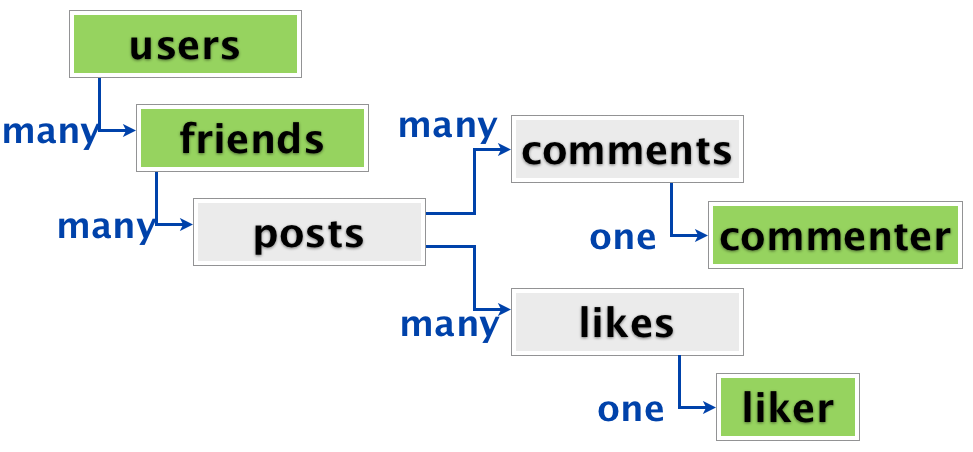
The user has friends, and each friend can be a user. Or it may not be, because it is a distributed system. (This is a whole layer of complexity that I’ll skip today.) In the same way, commentators and likes can also be users.
Such duplication of types greatly complicates the denormalization of the tape of activity into a single document. This is because in different places in the document, you can refer to the same entity - in this case, the same user. The user who liked the post can also be a user who commented on another activity.
We can model it differently in MongoDB. The easiest way is to duplicate data. All information about the user is copied to the like in the first post, and then a separate copy is saved in the comment to the second post. The advantage is that all data is present wherever you need it, and you can still pull out the entire stream of activity in another document.
This is approximately the density of a denormalized activity tape.

All copies of user data are embedded in the document. This is Joe's tape, and he has copies of user data, including his name and URL, at the top level. His tape contains a post Jane. Joe limped Jane's post, so that in lacquers to Jane's post, a separate copy of Joe's data was saved.
You can understand why this is attractive: all the data you need is already where you need it.
You can also see why this is dangerous. Updating user data means traversing all activity tapes to change data in all places where it is stored. This is very error prone, and often leads to data inconsistencies and mysterious errors, especially when working with deletions.
There is another approach to solving a problem in MongoDB, which will be familiar to those who have experience with relational databases. Instead of duplicating data, you can save links to users in the activity feed.
With this approach, instead of embedding the data where it is needed, you give each user an ID. After that, instead of embedding user data, you save only links to users. In the picture, the IDs are highlighted in green:

(MongoDB actually uses BSON identifiers - strings that look like GUIDs. The numbers in the image make it easier to read.)
This eliminates our duplication problem. When changing user data, there is only one document that needs to be changed. However, we created a new problem for ourselves. Because we can no longer build a tape of activity from a single document. This is a less effective and more complex solution. Building an activity feed now requires us to 1) get an activity feed document, and then 2) get all user documents to fill out names and avatars.
What MongoDB lacks is join operations like in SQL, which allows you to write one query that brings together the activity tape and all users that have links from the tape. In the end, you have to manually make joins in the application code.
Back to the series for a second. A lot of relationships for TV shows do not have much difficulty. Because all the rectangles in the relationship diagram are different entities, the entire request can be denormalized into one document, without duplication and without references. In this database, there are no links between documents. Therefore, joins are not required.
There are no self-sufficient entities in the social network. Every time when you see the username or avatar you expect that you can click and see the user profile, his posts. TV shows do not work this way. If you are on episode 1 of season 1 of Babylon 5, you do not expect to be able to move on to episode 1 of season 1 of General Hospital.
After we started making ugly joins manually in the Diaspora code, we realized that this was only the first sign of problems. It was a signal that our data is actually relational, that there is value in this structure of connections and we are moving against the basic idea of documentary DBMS.
Do you duplicate important data (fie), or use links and make joins in the application code (double fie), if you need links between documents, then you have outgrown MongoDB. When MongoDB apologists say “documents,” they mean things you can print on paper and work that way. Documents have an internal structure - headings and subheadings, paragraphs and footers, but do not have links to other documents. Self-contained element of semi-structured data.
If your data looks like a set of paper documents - congratulations! This is a good case for Mongo. But if you have links between documents, then you actually have no documents. MongoDB is a bad decision in this case. For social data, this is a really bad decision, since the most important part is communication between documents.
Thus, social data is not documentary. Does this mean that social data is actually ... relational?
When people say “social data is not relational,” it means not what they mean. They mean one of two things:
This is absolutely true. But there are actually very few concepts in the world that, naturally, can be modeled as normalized tables. We use this structure because it is efficient, because it avoids duplication, and because when it really becomes slow, we know how to fix it.
This is also absolutely true. When your social data is in a relational repository, you need to make the connection of many tables in order to get activity tape for a specific user, and that is slower with the growth of the table volumes. However, we have a well-understood solution to this problem. It is called caching.
At the All Your Base Conf conference in Oxfort, where I gave a talk on the topic of this post, Neha Narula presented a great talk about caching, which I recommend watching. In short, caching normalized data is a complex, but fully understood problem. I saw projects in which the tape activity was denormalized in a document database, like MongoDB, which made it possible to get data much faster. The only problem is cache invalidation.
It turns out that disabling the cache is actually quite difficult. Phil Carlton has written most of the SSL versions 3, X11 and OpenGL, so he knows something about computer science.
But what is cache invalidation, and why is it so difficult?
Cache invalidation is the knowledge when your data in the cache is out of date and you need to update or replace it. Here is a typical example that I see every day in web applications. We have long-term storage, usually PostgreSQL or MySQL, and in front of them we have a caching layer, based on Memcached or Redis. The request for reading the user's activity tape is processed from the cache, and not directly from the database, which makes the execution of the request very fast.

Writing is a much more complicated process. Suppose a user with two friends creates a new post. The first thing that happens is that the post is written to the database. After that, the background thread writes the post to the cached tape of the activity of both users who are friends of the author.
This is a very common pattern. Tweeter keeps in-memory cache tapes of the latest active users, to which posts are added when someone from the followers creates a new post. Even small applications that use something like activity tapes do this (see: joining seven tables).
Let's return to our example. When an author changes an existing post, the update is processed the same way as the creation, except that the item in the cache is updated, not added to the existing one.
What happens if the background thread, updating the cache, is interrupted in the middle? The server may fall, the network cables will be disconnected, the application will restart. Instability is the only stable fact in our work. When this happens, the data in the cache becomes inconsistent. Some copies of posts have the old name, and others - new. This is not an easy task, but with the cache, there is always the nuclear option.

You can always completely remove an item from the cache and rebuild it from the agreed long-term storage.
But what if there is no long-term storage? What if the cache is the only thing you have?
In the case of MongoDB, this is exactly the case. This is a cache, without a long-term consistent storage. And he will definitely become inconsistent. Not “finally agreed” ( eventually consistent ), but simply uncoordinated all the time (This is not so difficult to achieve, it is enough that updates occur more often than than the average time to reach a coordinated state - approx. Lane ). In this case, you have no options, even "nuclear". You have no way to rebuild the cache in a consistent state.
When Diaspora decided to use MongoDB, they combined the database with a cache. Database and cache are very different things. They are based on different ideas about stability, speed, duplication, connections and data integrity.
As soon as we realized that we had randomly selected a cache for the database, what could we do?
Well, that's a million dollar question. But I have already answered the billion dollar question. In this post, I talked about how we used MongoDB compared to what it was designed for. I talked about this as if all the information was obvious, and the Dispora team was simply not able to do the research before choosing.
But it was not at all obvious. Documentation MongoDB says that is good, and does not say that is not good. This is natural. Everybody does it. But as a result, it took about 6 months and a lot of user complaints and a lot of investigations to find out that we used MongoDB for other purposes.
There was nothing to do, other than extracting data from MongoDB and putting it into a relational database management system, solving data inconsistencies on the go. The process of extracting data from MongoDB and placing it in MySQL was straightforward. More details in the report on All Your Base Conf .
We had data for 8 months of work, which turned into 1.2 million rows in MySQL. We spent eight weeks developing the code for the migration and when the process started the main site went downstairs for 2 hours. This was a more than acceptable result for a project in the pre-alpha stage. We could reduce the downtime, but we laid 8 hours, so two hours looked fantastic.

(NOT BAD)
Remember the app for the television series? It was the perfect use for MongoDB. Each series was one self-contained document. No references to other documents, no duplication, and no way to make the data inconsistent.
After three months in development, everything worked fine with MongoDB. But once on Monday at the meeting, the client said that one of the investors wanted a new feature. He wants to be able to click on the name of the actor and watch his career in the television series. He wants a list of all the episodes in all serials in chronological order, in which this actor starred.
We stored each series as a document in MongoDB containing all the data, including the actors. If this actor met in two episodes, even in one series, the information was stored in two places. We could not even find out that this is the same actor, except by comparing names. To implement the features, it was necessary to bypass all documents, find and deduplicate all instances of actors. Wow ... You had to do this at least once, and then maintain the external index of all the actors, who will experience the same problems with consistency, like any other cache.
The client expects that the feature will be trivial. If the data were in a relational repository, then this would be true. First of all, we tried to convince the manager that this feature is not needed. But the manager did not sag and we came up with several cheaper alternatives, such as links to IMDB by the name of the actor. But the company made money on advertising, so they needed to prevent the client from leaving the site.
This feature pushed the project to switch to PosgreSQL. After talking with the customer, it turned out that the business sees a lot of value in linking the episodes to each other.They envisioned watching TV shows filmed by one director and episodes released in one week and much more.
It was ultimately a communication problem, not a technical problem. If these conversations are what happened before, if we took the time to really understand how the client wants to see the data and what he wants to do with it, then we probably would have switched PostgreSQL earlier when there was less data and it was easier.
From the experience I learned something: the perfect MongoDB case is even narrower than our serial data. The only thing that is conveniently stored in MongoDB is arbitrary JSON fragments. “ Custom ” in this context means that you absolutely don't care what's inside JSON. You do not even look there. there is no schema, not even an implicit schema, as was the case with our serial data. Each document is a set of bytes, and you do not make any assumptions about what is inside.
At RubyConf, I ran into Conrad Irwin , who proposed this script. He saved arbitrary data from clients in the form of JSON. It is reasonable. CAP theorem does not matter when your data does not make sense. But in any interesting application, the data makes sense.
I heard from many people that MongoDB is used as a replacement for PostgreSQL or MySQL. There are no circumstances under which this might be a good idea. The flexibility of the scheme (in fact, the absence of a scheme - note lane ) looks like a good idea, but in fact it is useful only when your data does not carry value. If you have an implicit scheme, that is, you expect some structure in JSON, then MongoDB is the wrong choice. I suggest looking at hstore in PostgreSQL (anyway faster than MongoDB) and learning how to make schema changes. They really aren't that complicated, even in large tables.
When you choose a data warehouse, the most important thing is to understand where the value for the customer is in the data and connections. If you still do not know, then you need to choose something that does not drive you into a corner. Cramming arbitrary JSON data into a database looks like a flexible solution, but the real flexibility is simply to add business features.
Make valuable things simple.
Thank you for reading here.
Several times I made the wrong choice of DBMS. This story is about one such choice - why we made such a choice, how we would know that the choice was wrong and how we struggled with it. It all happened on an open source project called Diaspora.
Project
Diaspora is a distributed social network with a long history. A long time ago, in 2010, four students at New York University published a video on Kickstarter asking them to donate $ 10,000 to develop a distributed alternative to Facebook. They sent the link to friends, family and hoped for the best.
But they hit the nail on the head. Another scandal has just died down because of privacy on Facebook, and when the dust settled they received $ 200,000 investment from 6,400 people for a project that had not yet written a single line of code.
')
Diaspora was one of the first Kickstarter projects that managed to significantly exceed the target. As a result, they were written about in the New York Times newspaper, which turned out to be a scandal, because an indecent joke was written on the board against the photograph of the team, but nobody noticed that until the photo was printed ... in the New York Times. So I found out about this project.
As a result of the success on Kickstarter, the guys quit studying and moved to San Francisco to start writing code. So they were in my office. At that time, I worked at Pivotal Labs and one of the elder brothers of the Diaspora developers also worked at this company, so Pivotal offered the guys jobs, the Internet, and, of course, access to the fridge with beer. I worked with the company's official clients, and in the evenings I hung out with the guys and wrote the code on weekends.
They ended up staying at Pivotal for more than two years. However, by the end of the first summer they had a minimal, but working (in a sense) implementation of a distributed social network on Ruby on Rails, using MongoDB for data storage.
Quite a few baszvorodov - let's see.
Distributed social network
If you've seen Facebook, then you know everything you need to know about Facebook. This web application, it exists in a single copy and allows you to communicate with people. The Diaspora interface looks almost the same as Facebook.
The message line in the middle shows the posts of all your friends, and around it is a pile of garbage that no one pays attention to. The main difference between Diaspora and Facebook is invisible to users, this is the “distributed” part.
The infrastructure of Disapora is not located behind a single web address. There are hundreds of independent copies of Diaspora. The code is open, so you can deploy your servers. Each copy is called a pod. It has its own database and its own set of users. Each Pod interacts with other Pods, which also have their own base and their users.
Pods communicate using API based on the HTTP protocol (now it is fashionable to call it REST API - approx. Lane ). When you unwrap your Pod, it will be pretty boring until you add friends. You can add as a friend to users in your Pod, or in other Pods. When someone publishes something, this is what happens:
- The message will be saved in the author’s database.
- Your Pod will be notified through the API.
- The message will be saved in your Pod database.
- In your feed you will see a message along with messages from other friends.
Comments work the same way. Each message can be commented on by users from the same Pod as well as people from other Pods. Anyone who has permission to view the message will also see all comments. As if everything happens in one application.
Who cares?
There are technical and legal advantages of this architecture. The main technical advantage is fault tolerance.
(such a fail-safe system should be available in every office)
If one of the pods falls, then all others continue to work. The system causes, and even expects, network separation. The political implications of this are, for example, if in your country they block access to Facebook or Twitter, your local Pod will be available to other people in your country, even if everyone else is not available.
The main legal advantage is server independence. Each Pod is a legally independent entity, governed by the laws of the country where the Pod is located. Each Pod can also set its own terms, on most you do not give up rights to all content, such as on Facebook or Twitter. Diaspora is free software, both in the “free” sense, and in the “independent” sense. Most of those who run their Pods are very concerned.
This is the system architecture, let's look at the architecture of a single Pod.
This is a Rails application.
Each Pod is a Ruby on Rails application with its MongoDB base. In a sense, this is a “typical” Rails application — it has a user interface, a programming API, Ruby logic, and a database. But in all other respects it is far from typical.
The API is used for mobile clients and for "federation", that is, for interaction between Pods. Distribution adds several layers of code that are absent in a typical application.
And, of course, MongoDB is far from a typical choice for web applications. Most Rails applications use PostgreSQL or MySQL. (as of 2010 - approx. lane. )
So here's the code. Consider what data we store.
I don't think that word means what you think it means
“Social data” is information about our network of friends, their friends and their activities. Conceptually, we think of it as a network — an undirected graph in which we are in the center, and our friends are around us.
(Photos from rubyfriends.com. Thanks to Matt Rogers, Steve Klabnik, Nell Shamrell, Katrina Owen, Sam Livingston Gray, Josh Sasser, Akshay Khole, Pradyumna Dandwate and Hefziba Watharkar for contributing to # rubyfriends!)
When we store social data, we save both topology and actions.
For several years now we have known that social data is not relational, if you store social data in a relational database, then you are doing it wrong.
But what are the alternatives? Some argue that graph databases are best suited, but I will not consider them, since they are too niche for mass projects. Others say that documentary data is ideal for social data, and they are fairly mainstream for real use. Let's take a look at why people think that MongoDB is much better suited for social data than PostgreSQL.
How MongoDB stores data
MongoDB is a document database. Instead of storing data in tables consisting of separate rows , as in relational databases, MongoDB stores data in collections consisting of documents . A document is a large JSON object with no predefined format and schema.
Let's look at the set of links that you need to model. This is very similar to the projects in Pivotal for which MongoDB was used, and this is the best use case for a document database engine I have ever seen.
At the root we have a series of TV shows. Each series can have many seasons, each season has many episodes, each episode has many reviews and many actors. When a user comes to the site, he usually gets to the page of a particular series. The page displays all seasons, episodes, reviews and actors, all on one page. From the point of view of the application, when the user hits the page we want to get all the information related to the series.
This data can be modeled in several ways. In a typical relational repository, each of the rectangles will be a table. You will have the tv_shows table, the seasons table with a foreign key in tv_shows, the episodes table with a foreign key in seasons, reviews, and cast_members of a table with foreign keys in the episodes. Thus, to get all the information about the series, you need to join five tables.
We could also model this data as a set of nested objects (a set of key-value pairs). A lot of information about a particular series is one big structure of nested key-value sets. Inside the series, there are many seasons, each of which is also an object (a set of key-value pairs). Within each season, an array of episodes, each of which represents an object, and so on. So in MongoDB model the data. Each series is a document that contains all the information about one series.
Here is an example of a document of one series, Babylon 5:
The show has a name and an array of seasons. Each season - an object with metadata and an array of episodes. In turn, each episode has metadata and arrays of reviews and actors.
Looks like a huge fractal data structure.
(Many sets of sets. Delicious fractals.)
All data needed for the series is stored in one document, so you can get all the information very quickly at once, even if the document is very large. There is a series called General Hospital, which has 12,000 episodes for 50+ seasons. On my laptop, PostgreSQL runs for about a minute to get denormalized data for 12,000 episodes, while retrieving a document by ID in MongoDB takes a fraction of a second.
So in many ways, this application implements the ideal use for the document base.
Good. But what about social data?
Right. When you get into a social network, there is only one important part of the page: your activity feed. The request feed activity gets all the posts from your friends, sorted by date. Each post contains attachments such as photos, likes, reposts and comments.
The nested structure of the activity tape looks very similar to the serials.
Users have friends, friends have posts, posts have comments and likes, each of which is associated with one commentator or likes. From the point of view of connections, this is not much more complicated than the structure of television series. And as in the case of serials, we want to get the whole structure at once as soon as the user enters the social network. In a relational DBMS, this would be a join of seven tables to pull out all the data.
The connection of seven tables, oh. Suddenly, saving the entire user tape as a single denormalized data structure, instead of doing joins, looks very attractive. (In PostgreSQL, such joins are slowly working cause pain - approx. Lane. )
In 2010, the Diaspora team made such a decision, Esty’s articles on using documentary DBMS turned out to be very convincing, even though they publicly rejected MongoDB in consequence. In addition, at this time, the use of Cassandra on Facebook spawned a lot of talk about abandoning relational databases. The choice of MongoDB for Disapora was in the spirit of the time. It was not an unreasonable choice at that time, given the knowledge that they had.
What could go wrong?
There is a very important difference between the social data of Diaspora and Mongo-ideal data about serials, which no one noticed at first glance.
With serials, each rectangle in the relationship diagram has a different type. Series differ from seasons, differ from episodes, differ from reviews, differ from actors. None of them is even a subtype of another type.
But with social data, some of the rectangles in the relationship diagram are of the same type. In fact, all these green rectangles of the same type are all users of the diaspora.
The user has friends, and each friend can be a user. Or it may not be, because it is a distributed system. (This is a whole layer of complexity that I’ll skip today.) In the same way, commentators and likes can also be users.
Such duplication of types greatly complicates the denormalization of the tape of activity into a single document. This is because in different places in the document, you can refer to the same entity - in this case, the same user. The user who liked the post can also be a user who commented on another activity.
Data duplication data duplication
We can model it differently in MongoDB. The easiest way is to duplicate data. All information about the user is copied to the like in the first post, and then a separate copy is saved in the comment to the second post. The advantage is that all data is present wherever you need it, and you can still pull out the entire stream of activity in another document.
This is approximately the density of a denormalized activity tape.
All copies of user data are embedded in the document. This is Joe's tape, and he has copies of user data, including his name and URL, at the top level. His tape contains a post Jane. Joe limped Jane's post, so that in lacquers to Jane's post, a separate copy of Joe's data was saved.
You can understand why this is attractive: all the data you need is already where you need it.
You can also see why this is dangerous. Updating user data means traversing all activity tapes to change data in all places where it is stored. This is very error prone, and often leads to data inconsistencies and mysterious errors, especially when working with deletions.
Is there no hope?
There is another approach to solving a problem in MongoDB, which will be familiar to those who have experience with relational databases. Instead of duplicating data, you can save links to users in the activity feed.
With this approach, instead of embedding the data where it is needed, you give each user an ID. After that, instead of embedding user data, you save only links to users. In the picture, the IDs are highlighted in green:
(MongoDB actually uses BSON identifiers - strings that look like GUIDs. The numbers in the image make it easier to read.)
This eliminates our duplication problem. When changing user data, there is only one document that needs to be changed. However, we created a new problem for ourselves. Because we can no longer build a tape of activity from a single document. This is a less effective and more complex solution. Building an activity feed now requires us to 1) get an activity feed document, and then 2) get all user documents to fill out names and avatars.
What MongoDB lacks is join operations like in SQL, which allows you to write one query that brings together the activity tape and all users that have links from the tape. In the end, you have to manually make joins in the application code.
Simple denormalized data
Back to the series for a second. A lot of relationships for TV shows do not have much difficulty. Because all the rectangles in the relationship diagram are different entities, the entire request can be denormalized into one document, without duplication and without references. In this database, there are no links between documents. Therefore, joins are not required.
There are no self-sufficient entities in the social network. Every time when you see the username or avatar you expect that you can click and see the user profile, his posts. TV shows do not work this way. If you are on episode 1 of season 1 of Babylon 5, you do not expect to be able to move on to episode 1 of season 1 of General Hospital.
Not. It is necessary. Refer. On. Documents.
After we started making ugly joins manually in the Diaspora code, we realized that this was only the first sign of problems. It was a signal that our data is actually relational, that there is value in this structure of connections and we are moving against the basic idea of documentary DBMS.
Do you duplicate important data (fie), or use links and make joins in the application code (double fie), if you need links between documents, then you have outgrown MongoDB. When MongoDB apologists say “documents,” they mean things you can print on paper and work that way. Documents have an internal structure - headings and subheadings, paragraphs and footers, but do not have links to other documents. Self-contained element of semi-structured data.
If your data looks like a set of paper documents - congratulations! This is a good case for Mongo. But if you have links between documents, then you actually have no documents. MongoDB is a bad decision in this case. For social data, this is a really bad decision, since the most important part is communication between documents.
Thus, social data is not documentary. Does this mean that social data is actually ... relational?
Again this word
When people say “social data is not relational,” it means not what they mean. They mean one of two things:
1. "Conceptually, social data is more a graph than a set of tables."
This is absolutely true. But there are actually very few concepts in the world that, naturally, can be modeled as normalized tables. We use this structure because it is efficient, because it avoids duplication, and because when it really becomes slow, we know how to fix it.
2. "It is much faster to obtain all social data when they are denormalized in one document"
This is also absolutely true. When your social data is in a relational repository, you need to make the connection of many tables in order to get activity tape for a specific user, and that is slower with the growth of the table volumes. However, we have a well-understood solution to this problem. It is called caching.
At the All Your Base Conf conference in Oxfort, where I gave a talk on the topic of this post, Neha Narula presented a great talk about caching, which I recommend watching. In short, caching normalized data is a complex, but fully understood problem. I saw projects in which the tape activity was denormalized in a document database, like MongoDB, which made it possible to get data much faster. The only problem is cache invalidation.
“There are only two difficult tasks in the field of computer science: disabling the cache and inventing names.”
Phil carlton
It turns out that disabling the cache is actually quite difficult. Phil Carlton has written most of the SSL versions 3, X11 and OpenGL, so he knows something about computer science.
cache invalidation as a service
But what is cache invalidation, and why is it so difficult?
Cache invalidation is the knowledge when your data in the cache is out of date and you need to update or replace it. Here is a typical example that I see every day in web applications. We have long-term storage, usually PostgreSQL or MySQL, and in front of them we have a caching layer, based on Memcached or Redis. The request for reading the user's activity tape is processed from the cache, and not directly from the database, which makes the execution of the request very fast.
Writing is a much more complicated process. Suppose a user with two friends creates a new post. The first thing that happens is that the post is written to the database. After that, the background thread writes the post to the cached tape of the activity of both users who are friends of the author.
This is a very common pattern. Tweeter keeps in-memory cache tapes of the latest active users, to which posts are added when someone from the followers creates a new post. Even small applications that use something like activity tapes do this (see: joining seven tables).
Let's return to our example. When an author changes an existing post, the update is processed the same way as the creation, except that the item in the cache is updated, not added to the existing one.
What happens if the background thread, updating the cache, is interrupted in the middle? The server may fall, the network cables will be disconnected, the application will restart. Instability is the only stable fact in our work. When this happens, the data in the cache becomes inconsistent. Some copies of posts have the old name, and others - new. This is not an easy task, but with the cache, there is always the nuclear option.
You can always completely remove an item from the cache and rebuild it from the agreed long-term storage.
But what if there is no long-term storage? What if the cache is the only thing you have?
In the case of MongoDB, this is exactly the case. This is a cache, without a long-term consistent storage. And he will definitely become inconsistent. Not “finally agreed” ( eventually consistent ), but simply uncoordinated all the time (This is not so difficult to achieve, it is enough that updates occur more often than than the average time to reach a coordinated state - approx. Lane ). In this case, you have no options, even "nuclear". You have no way to rebuild the cache in a consistent state.
When Diaspora decided to use MongoDB, they combined the database with a cache. Database and cache are very different things. They are based on different ideas about stability, speed, duplication, connections and data integrity.
Transformation
As soon as we realized that we had randomly selected a cache for the database, what could we do?
Well, that's a million dollar question. But I have already answered the billion dollar question. In this post, I talked about how we used MongoDB compared to what it was designed for. I talked about this as if all the information was obvious, and the Dispora team was simply not able to do the research before choosing.
But it was not at all obvious. Documentation MongoDB says that is good, and does not say that is not good. This is natural. Everybody does it. But as a result, it took about 6 months and a lot of user complaints and a lot of investigations to find out that we used MongoDB for other purposes.
There was nothing to do, other than extracting data from MongoDB and putting it into a relational database management system, solving data inconsistencies on the go. The process of extracting data from MongoDB and placing it in MySQL was straightforward. More details in the report on All Your Base Conf .
Damage
We had data for 8 months of work, which turned into 1.2 million rows in MySQL. We spent eight weeks developing the code for the migration and when the process started the main site went downstairs for 2 hours. This was a more than acceptable result for a project in the pre-alpha stage. We could reduce the downtime, but we laid 8 hours, so two hours looked fantastic.
(NOT BAD)
Epilogue
Remember the app for the television series? It was the perfect use for MongoDB. Each series was one self-contained document. No references to other documents, no duplication, and no way to make the data inconsistent.
After three months in development, everything worked fine with MongoDB. But once on Monday at the meeting, the client said that one of the investors wanted a new feature. He wants to be able to click on the name of the actor and watch his career in the television series. He wants a list of all the episodes in all serials in chronological order, in which this actor starred.
We stored each series as a document in MongoDB containing all the data, including the actors. If this actor met in two episodes, even in one series, the information was stored in two places. We could not even find out that this is the same actor, except by comparing names. To implement the features, it was necessary to bypass all documents, find and deduplicate all instances of actors. Wow ... You had to do this at least once, and then maintain the external index of all the actors, who will experience the same problems with consistency, like any other cache.
See what happens?
The client expects that the feature will be trivial. If the data were in a relational repository, then this would be true. First of all, we tried to convince the manager that this feature is not needed. But the manager did not sag and we came up with several cheaper alternatives, such as links to IMDB by the name of the actor. But the company made money on advertising, so they needed to prevent the client from leaving the site.
This feature pushed the project to switch to PosgreSQL. After talking with the customer, it turned out that the business sees a lot of value in linking the episodes to each other.They envisioned watching TV shows filmed by one director and episodes released in one week and much more.
It was ultimately a communication problem, not a technical problem. If these conversations are what happened before, if we took the time to really understand how the client wants to see the data and what he wants to do with it, then we probably would have switched PostgreSQL earlier when there was less data and it was easier.
Study, study and study again
From the experience I learned something: the perfect MongoDB case is even narrower than our serial data. The only thing that is conveniently stored in MongoDB is arbitrary JSON fragments. “ Custom ” in this context means that you absolutely don't care what's inside JSON. You do not even look there. there is no schema, not even an implicit schema, as was the case with our serial data. Each document is a set of bytes, and you do not make any assumptions about what is inside.
At RubyConf, I ran into Conrad Irwin , who proposed this script. He saved arbitrary data from clients in the form of JSON. It is reasonable. CAP theorem does not matter when your data does not make sense. But in any interesting application, the data makes sense.
I heard from many people that MongoDB is used as a replacement for PostgreSQL or MySQL. There are no circumstances under which this might be a good idea. The flexibility of the scheme (in fact, the absence of a scheme - note lane ) looks like a good idea, but in fact it is useful only when your data does not carry value. If you have an implicit scheme, that is, you expect some structure in JSON, then MongoDB is the wrong choice. I suggest looking at hstore in PostgreSQL (anyway faster than MongoDB) and learning how to make schema changes. They really aren't that complicated, even in large tables.
Find value
When you choose a data warehouse, the most important thing is to understand where the value for the customer is in the data and connections. If you still do not know, then you need to choose something that does not drive you into a corner. Cramming arbitrary JSON data into a database looks like a flexible solution, but the real flexibility is simply to add business features.
Make valuable things simple.
the end
Thank you for reading here.
Source: https://habr.com/ru/post/231213/
All Articles