Lossless data compression algorithms
Part one is historical .
Existing data compression algorithms can be divided into two large classes - with losses and without. Lossy algorithms are commonly used to compress images and audio. These algorithms allow you to achieve high degrees of compression due to selective loss of quality. However, by definition, it is impossible to recover the original data from the compressed result.
Lossless compression algorithms are used to reduce the size of the data, and work in such a way that it is possible to recover data exactly as they were before compression. They are used in communications, archivers and some algorithms for compressing audio and graphic information. Next, we consider only lossless compression algorithms.
The basic principle of compression algorithms is based on the fact that in any file containing non-random data, information is partially repeated. Using statistical mathematical models, one can determine the probability of a repetition of a certain combination of symbols. After that, you can create codes denoting the selected phrases, and assign the shortest codes to the most frequently repeated phrases. Different techniques are used for this, for example: entropy coding, repetition coding, and compression using a dictionary. With their help, an 8-bit character, or an entire string, can be replaced with just a few bits, thus eliminating redundant information.
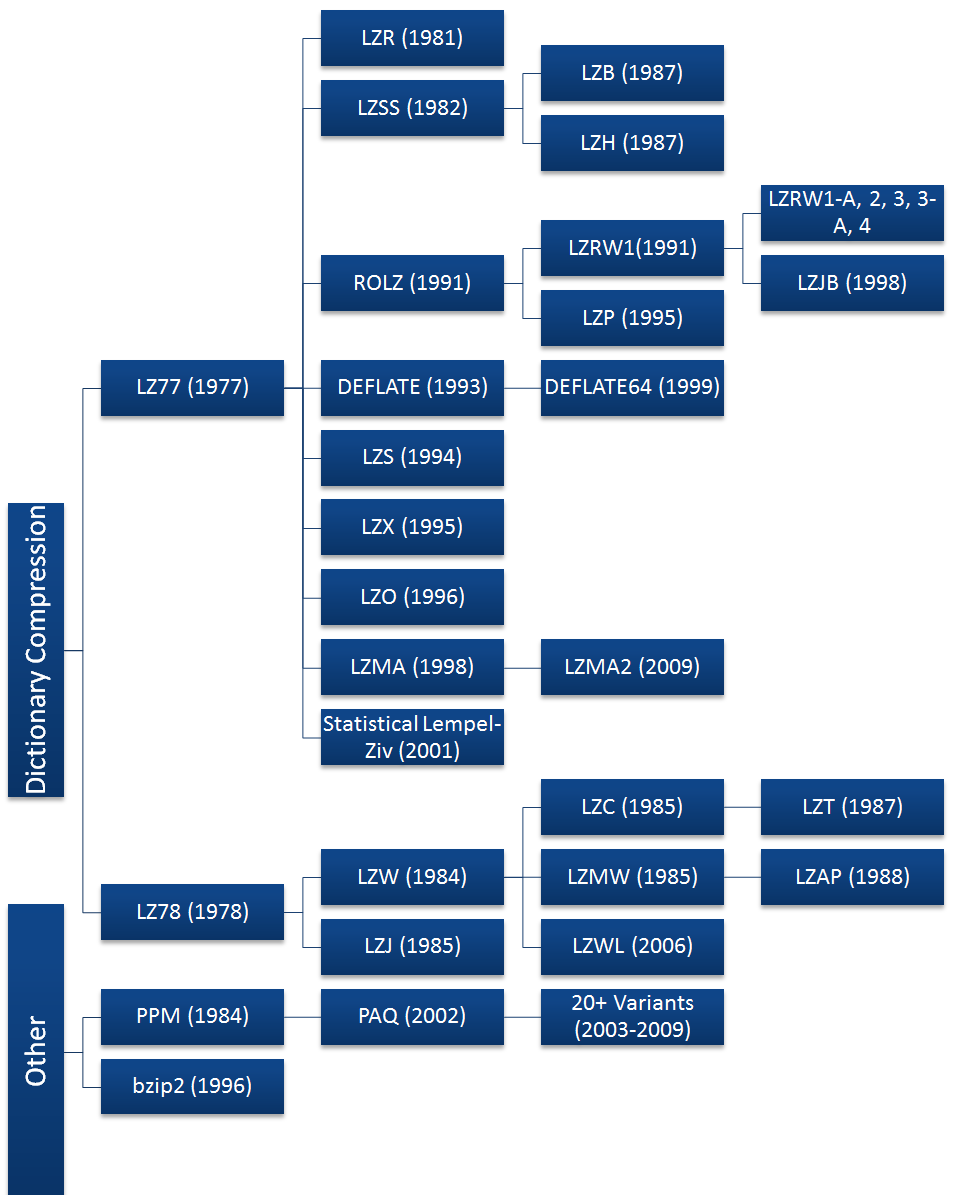
Algorithm hierarchy:
Although data compression has become widespread along with the Internet and after the invention of the Lempel and Ziv algorithms (LZ algorithms), several earlier examples of compression can be cited. Morse, inventing his code in 1838, reasonably assigned the most frequently used letters in the English language, “e” and “t”, the shortest sequences (dot and dash). Soon after the appearance of mainframes in 1949, the Shannon-Fano algorithm was invented, which assigned codes to symbols in a data block, based on the probability of their appearance in the block. The probability of a symbol appearing in a block was inversely proportional to the length of the code, which allowed compressing the representation of the data.
David Huffman was a student in the classroom with Robert Fano and chose the search for an improved method of binary data coding as an educational work. As a result, he managed to improve the algorithm of Shannon-Fano.
Early versions of the Shannon-Fano and Huffman algorithms used predefined codes. Later, they began to use codes created dynamically based on data intended for compression. In 1977, Lempel and Ziv published their LZ77 algorithm, based on the use of a dynamically created dictionary (it is also called a “sliding window”). In 78, they published the LZ78 algorithm, which first parses the data and creates the dictionary, instead of creating it dynamically.
')
Algorithms LZ77 and LZ78 gained great popularity and caused a wave of improvers, of which DEFLATE, LZMA and LZX have survived to this day. Most of the popular algorithms are based on LZ77, because the LZW algorithm derived from LZ78 was patented by Unisys in 1984, after which they began to troll one and all, including even cases of using GIF images. At this time, a variation of the LZW algorithm called LZC was used on UNIX, and due to problems with rights, their use had to be curtailed. Preference was given to the DEFLATE algorithm (gzip) and the Burrows – Wheeler transform, BWT (bzip2). That was for the better, since these algorithms are almost always superior to LZW in compression.
By 2003, the patent had expired, but the train had already left and the LZW algorithm was preserved, perhaps, only in GIF files. The dominant algorithms are based on LZ77.
In 1993, there was another patent battle, when Stac Electronics discovered that the LZS algorithm developed by it was used by Microsoft in a disk compression program supplied with MS-DOS 6.0. Stac Electronics sued and managed to win the case, as a result of which they received more than $ 100 million.
Large corporations used compression algorithms to store increasing data sets, but the true distribution of the algorithms occurred with the birth of the Internet in the late 80s. Channel capacity was extremely narrow. For compression of data transmitted over the network, ZIP, GIF and PNG formats were invented.
Tom Henderson invented and released the first commercially successful ARC archiver in 1985 (System Enhancement Associates). ARC was popular among BBS users, because she was one of the first who could compress several files into the archive, and besides, its sources were open. ARC used a modified LZW algorithm.
Phil Katz, inspired by the popularity of ARC, released the PKARC program in shareware format, in which he improved the compression algorithms by rewriting them in Assembler. However, he was convicted by Henderson and was found guilty. PKARC copied the ARC so openly that sometimes there were even typos in the comments to the source code.
But Phil Katz did not lose his head, and in 1989 he greatly changed the archiver and released PKZIP. After he was attacked in connection with the patent for the LZW algorithm, he changed the basic algorithm to a new one, called IMPLODE. The format was again replaced in 1993 with the release of PKZIP 2.0, and the replacement was DEFLATE. Among the new features was the function of splitting the archive into volumes. This version is still widely used, despite its venerable age.
The GIF (Graphics Interchange Format) image format was created by CompuServe in 1987. As you know, the format supports lossless image compression, and is limited to a palette of 256 colors. Despite all the attempts of Unisys, she was unable to stop the spread of this format. It is still popular, especially in connection with the support of animation.
Lightly agitated by patent issues, CompuServe released the Portable Network Graphics (PNG) format in 1994. Like ZIP, it used the new trendy algorithm DEFLATE. Although DEFLATE was patented by Katz, he did not make any claims.
Now it is the most popular compression algorithm. In addition to PNG and ZIP, it is used in gzip, HTTP, SSL and other data transfer technologies.
Unfortunately, Phil Katz did not live to see the triumph of DEFLATE, he died of alcoholism in 2000 at the age of 37. Citizens - excessive drinking is dangerous to your health! You may not live to see your triumph!
ZIP reigned supreme until the mid-90s, but in 1993, the simple Russian genius Eugene Roshal came up with his own format and RAR algorithm. Its latest versions are based on PPM and LZSS algorithms. Now ZIP, perhaps the most common of the formats, RAR - until recently was the standard for distributing various low-legal content over the Internet (due to increased bandwidth, more and more files are distributed without archiving), and 7zip is used as the format with the best compression at an acceptable time. In the UNIX world, a bunch of tar + gzip is used (gzip is an archiver, and tar combines several files into one, because gzip does not know how).
Note trans. Personally, besides the listed ones, I came across ARJ (Archived by Robert Jung) archiver, which was popular in the 90s in the BBS era. He supported multivolume archives, and just like after him RAR was used to distribute games and other warez. There was also the HA archiver from Harri Hirvola, who used HSC compression (could not find a clear explanation - only the “limited context model and arithmetic coding”), which coped well with the compression of long text files.
In 1996, a version of the open source BWT algorithm bzip2 appeared, and quickly gained popularity. In 1999, a 7z zip program appeared. In terms of compression, it competes with RAR, its advantage is openness, as well as the ability to choose between bzip2, LZMA, LZMA2 and PPMd algorithms.
In 2002, another archiver appeared, PAQ. Author Matt Mahone used an improved version of the PPM algorithm using a technique called contextual blending. It allows you to use more than one statistical model to improve the prediction of the frequency of occurrence of characters.
Of course, God knows, but apparently, the PAQ algorithm is gaining popularity due to a very good compression ratio (although it works very slowly). But thanks to the increase in the speed of computers, the speed of work becomes less critical.
On the other hand, the Lempel-Ziv – Markov LZMA algorithm is a compromise between speed and compression ratio and can generate many interesting branches.
Another interesting technology is "substring enumeration" or CSE, which is still little used in programs.
In the next part we will look at the technical side of the algorithms mentioned and the principles of their work.
Introduction
Existing data compression algorithms can be divided into two large classes - with losses and without. Lossy algorithms are commonly used to compress images and audio. These algorithms allow you to achieve high degrees of compression due to selective loss of quality. However, by definition, it is impossible to recover the original data from the compressed result.
Lossless compression algorithms are used to reduce the size of the data, and work in such a way that it is possible to recover data exactly as they were before compression. They are used in communications, archivers and some algorithms for compressing audio and graphic information. Next, we consider only lossless compression algorithms.
The basic principle of compression algorithms is based on the fact that in any file containing non-random data, information is partially repeated. Using statistical mathematical models, one can determine the probability of a repetition of a certain combination of symbols. After that, you can create codes denoting the selected phrases, and assign the shortest codes to the most frequently repeated phrases. Different techniques are used for this, for example: entropy coding, repetition coding, and compression using a dictionary. With their help, an 8-bit character, or an entire string, can be replaced with just a few bits, thus eliminating redundant information.
Story
Algorithm hierarchy:
Although data compression has become widespread along with the Internet and after the invention of the Lempel and Ziv algorithms (LZ algorithms), several earlier examples of compression can be cited. Morse, inventing his code in 1838, reasonably assigned the most frequently used letters in the English language, “e” and “t”, the shortest sequences (dot and dash). Soon after the appearance of mainframes in 1949, the Shannon-Fano algorithm was invented, which assigned codes to symbols in a data block, based on the probability of their appearance in the block. The probability of a symbol appearing in a block was inversely proportional to the length of the code, which allowed compressing the representation of the data.
David Huffman was a student in the classroom with Robert Fano and chose the search for an improved method of binary data coding as an educational work. As a result, he managed to improve the algorithm of Shannon-Fano.
Early versions of the Shannon-Fano and Huffman algorithms used predefined codes. Later, they began to use codes created dynamically based on data intended for compression. In 1977, Lempel and Ziv published their LZ77 algorithm, based on the use of a dynamically created dictionary (it is also called a “sliding window”). In 78, they published the LZ78 algorithm, which first parses the data and creates the dictionary, instead of creating it dynamically.
')
Rights issues
Algorithms LZ77 and LZ78 gained great popularity and caused a wave of improvers, of which DEFLATE, LZMA and LZX have survived to this day. Most of the popular algorithms are based on LZ77, because the LZW algorithm derived from LZ78 was patented by Unisys in 1984, after which they began to troll one and all, including even cases of using GIF images. At this time, a variation of the LZW algorithm called LZC was used on UNIX, and due to problems with rights, their use had to be curtailed. Preference was given to the DEFLATE algorithm (gzip) and the Burrows – Wheeler transform, BWT (bzip2). That was for the better, since these algorithms are almost always superior to LZW in compression.
By 2003, the patent had expired, but the train had already left and the LZW algorithm was preserved, perhaps, only in GIF files. The dominant algorithms are based on LZ77.
In 1993, there was another patent battle, when Stac Electronics discovered that the LZS algorithm developed by it was used by Microsoft in a disk compression program supplied with MS-DOS 6.0. Stac Electronics sued and managed to win the case, as a result of which they received more than $ 100 million.
The rise in popularity of Deflate
Large corporations used compression algorithms to store increasing data sets, but the true distribution of the algorithms occurred with the birth of the Internet in the late 80s. Channel capacity was extremely narrow. For compression of data transmitted over the network, ZIP, GIF and PNG formats were invented.
Tom Henderson invented and released the first commercially successful ARC archiver in 1985 (System Enhancement Associates). ARC was popular among BBS users, because she was one of the first who could compress several files into the archive, and besides, its sources were open. ARC used a modified LZW algorithm.
Phil Katz, inspired by the popularity of ARC, released the PKARC program in shareware format, in which he improved the compression algorithms by rewriting them in Assembler. However, he was convicted by Henderson and was found guilty. PKARC copied the ARC so openly that sometimes there were even typos in the comments to the source code.
But Phil Katz did not lose his head, and in 1989 he greatly changed the archiver and released PKZIP. After he was attacked in connection with the patent for the LZW algorithm, he changed the basic algorithm to a new one, called IMPLODE. The format was again replaced in 1993 with the release of PKZIP 2.0, and the replacement was DEFLATE. Among the new features was the function of splitting the archive into volumes. This version is still widely used, despite its venerable age.
The GIF (Graphics Interchange Format) image format was created by CompuServe in 1987. As you know, the format supports lossless image compression, and is limited to a palette of 256 colors. Despite all the attempts of Unisys, she was unable to stop the spread of this format. It is still popular, especially in connection with the support of animation.
Lightly agitated by patent issues, CompuServe released the Portable Network Graphics (PNG) format in 1994. Like ZIP, it used the new trendy algorithm DEFLATE. Although DEFLATE was patented by Katz, he did not make any claims.
Now it is the most popular compression algorithm. In addition to PNG and ZIP, it is used in gzip, HTTP, SSL and other data transfer technologies.
Unfortunately, Phil Katz did not live to see the triumph of DEFLATE, he died of alcoholism in 2000 at the age of 37. Citizens - excessive drinking is dangerous to your health! You may not live to see your triumph!
Modern archivers
ZIP reigned supreme until the mid-90s, but in 1993, the simple Russian genius Eugene Roshal came up with his own format and RAR algorithm. Its latest versions are based on PPM and LZSS algorithms. Now ZIP, perhaps the most common of the formats, RAR - until recently was the standard for distributing various low-legal content over the Internet (due to increased bandwidth, more and more files are distributed without archiving), and 7zip is used as the format with the best compression at an acceptable time. In the UNIX world, a bunch of tar + gzip is used (gzip is an archiver, and tar combines several files into one, because gzip does not know how).
Note trans. Personally, besides the listed ones, I came across ARJ (Archived by Robert Jung) archiver, which was popular in the 90s in the BBS era. He supported multivolume archives, and just like after him RAR was used to distribute games and other warez. There was also the HA archiver from Harri Hirvola, who used HSC compression (could not find a clear explanation - only the “limited context model and arithmetic coding”), which coped well with the compression of long text files.
In 1996, a version of the open source BWT algorithm bzip2 appeared, and quickly gained popularity. In 1999, a 7z zip program appeared. In terms of compression, it competes with RAR, its advantage is openness, as well as the ability to choose between bzip2, LZMA, LZMA2 and PPMd algorithms.
In 2002, another archiver appeared, PAQ. Author Matt Mahone used an improved version of the PPM algorithm using a technique called contextual blending. It allows you to use more than one statistical model to improve the prediction of the frequency of occurrence of characters.
The future of compression algorithms
Of course, God knows, but apparently, the PAQ algorithm is gaining popularity due to a very good compression ratio (although it works very slowly). But thanks to the increase in the speed of computers, the speed of work becomes less critical.
On the other hand, the Lempel-Ziv – Markov LZMA algorithm is a compromise between speed and compression ratio and can generate many interesting branches.
Another interesting technology is "substring enumeration" or CSE, which is still little used in programs.
In the next part we will look at the technical side of the algorithms mentioned and the principles of their work.
Source: https://habr.com/ru/post/231177/
All Articles