Lock-free data structures. Queue dissection

Much time has passed since the previous post in the life of lock-free containers. I expected to quickly write a continuation of the treatise on queues, but there was a hitch: what to write about, I knew, but I did not have a C ++ implementation. “It’s not good to write about what I didn’t try myself,” I thought, and as a result I tried to implement new queue algorithms in libcds .
Now the moment has come when I can continue my cycle with arguments. This article will finish with the queues.
Let me briefly remind you of what I’ve stopped at. Several interesting lock-free queue algorithms were considered, and under the curtain the results of their work on some synthetic tests are presented. The main conclusion - everything is bad! The hope that the lock-free approach on the magic compare-and-swap (CAS) will give us, if not linear, but at least some increase in performance with an increase in the number of threads, did not materialize. Queues do not scale. What is the reason?..
The answer to this question lies in the features of the architecture of modern processors. Primitive CAS is a rather heavy instruction, heavily loading the cache and the internal synchronization protocol. With the active use of CAS over the same cache line, the processor is mainly busy supporting the coherence of the cache, as Professor Paul McKenney has already written
Stacks and queues are very unfriendly for the lock-free approach of the data structure, since they have a small number of entry points. For the stack, there is only one such point — the top of the stack; for the queue, there are two of them — the head and the tail. CAS competes for access to these points, while performance drops at 100% processor load - all threads are busy with something, but only one will win and gain access to the head / tail. Nothing like? .. It's a classic spin-lock! It turns out that with the lock-free approach on CAS, we got rid of external synchronization with a mutex, but we got an internal one, at the level of the processor instruction, and won little.
Restricted Queues
It should be noted that all of the above applies to unlimited (unbounded) MPMC (multiple producer / multiple consumer) queues. In limited (bounded) by the number of elements of queues, which are built, as a rule, on the basis of an array, this problem may not be so clearly expressed due to the accurate dispersion (scatter) of elements of the queue over the array. Also, faster algorithms can be built for queues with one writer or / and one reader.
')
The problem of effective implementation of competitive queues interests researchers until now. In recent years, the understanding that different tricks in the implementation of the lock-free queue "head on" does not give the expected result has increased, and some other approaches should be invented. Next we look at some of them.
Flat combining
I already described this method in the article about the stack, but flat combining is a universal method, therefore, it is applicable to the queue. I refer readers to the video of my presentation on C ++ User Group, Russia , dedicated to the implementation of flat combining.
As advertising
Taking this opportunity, I want to send rays of support to the sermp - the mastermind and organizer of the C ++ User Group, Russia. Sergey, your selfless work in this field is priceless!
Readers urge to pay attention to this event and support it with your turnout, as well as who have something to share, presentations. I learned from my own experience that live communication is much better than even reading Habr.
I also draw your attention to the upcoming C ++ Russia conference on February 27-28, 2015 in Moscow, - come!
Readers urge to pay attention to this event and support it with your turnout, as well as who have something to share, presentations. I learned from my own experience that live communication is much better than even reading Habr.
I also draw your attention to the upcoming C ++ Russia conference on February 27-28, 2015 in Moscow, - come!
Array of queues
An approach that lies on the surface, but nevertheless rather difficult to implement, with a lot of pitfalls, was proposed in 2013 in the article titled “Replacing competition with cooperation for the implementation of a scalable lock-free queue” that best suits the topic of this post. .
The idea is very simple. Instead of one queue, an array of the size of K is built, each element of which is a lock-free queue represented by a simply linked list. A new element is added to the next (modulo K) slot of the array. Thereby, the crowds on the tail of the queue are leveled, - instead of one tail, we have K tails, so we can expect that we will obtain linear scalability up to K parallel streams. Of course, we need to have a certain atomic monotonically increasing counter of push operations in order to multiplex each insert into its slot of the array. Naturally, this counter will be a single “sticking point” for all push streams. But the authors argue (according to my observations, not without reason) that the
xadd instruction of atomic addition (in our case, increment) on the x86 architecture is slightly faster than CAS. Thus, we can expect that on x86 we will get a win. On other architectures, the atomic fetch_add emulated by CAS, so the gain will not be so noticeable.The code for removing an element from a queue is similar: there is an atomic counter for deleted elements (pop-counter), on the basis of which an array slot is selected modulo K. To prevent violation of the main property of the queue - FIFO - each element contains an additional load (
ticket ) - the value of the push counter at the time of adding the element, in fact - the sequence number of the element. When deleting a slot, an item with ticket = is searched for the current value of the pop-counter, the item found is the result of the pop() operation.An interesting way that solves the problem of removing from an empty queue. In this algorithm, the atomic increment of the deletion counter (pop-counter) goes first, and then the search in the corresponding slot. It may well be that the slot is empty. This means that the whole queue is empty. But the pop-counter is already incremented, and its further use will lead to violation of the FIFO and even to the loss of elements. It is impossible to roll back (decrement) - all of a sudden, at the same time, other flows add or remove elements (in general, “back-play-cannot be” is an essential feature of the lock-free approach). Therefore, when a
pop() situation arises from an empty queue, the array is declared invalid, which leads to the creation of a new array with new push and pop counters the next time the element is inserted.Unfortunately, the authors did not bother (as they write, due to lack of space) the problem of freeing memory, giving it only a few sentences with a superficial description of the application of the Hazard Pointer scheme to its algorithm. I
libcds library. In addition, the algorithm is subject to unlimited accumulation of deleted items if the queue is never empty, that is, if the array is not invalidated, since it is not envisaged to delete items from the list-slot of the array. pop() simply searches for an item with the current ticket in the corresponding slot, but does not physically exclude an item from the list until the entire array is invalidated.Summing up, we can say: the algorithm is interesting, but the memory management is not described clearly enough. Additional study required.
Segmented Queues
Another way to increase the scalability of a queue is to break its main first-in property, first-out (FIFO). Is it really scary, depends on the task: for some, strict compliance with the FIFO is mandatory, for others - within certain limits it is quite acceptable.
Of course, absolutely no one wants to violate the basic FIFO property - in this case we will get a data structure called a pool, in which no order is observed at all: the
pop() operation returns any element. This is not a queue. For a queue with a FIFO violation, I would like to have some guarantees of this violation, for example: the pop() operation will return one of the first K elements. For K = 2, this means that for a queue with elements A, B, C, D, ... pop() returns A or B. Such queues are called segmented or K-segmented to emphasize the value of the factor K - the limit on the FIFO violation. Obviously, for a strict (fair) FIFO queue, K = 1.As far as I know, for the first time the simplest segmented queue was considered in detail in 2010 in a paper on just the allowable attenuation of requirements imposed on a lock-free data structure. The internal structure of the queue is quite simple (image from the above article, K = 5):
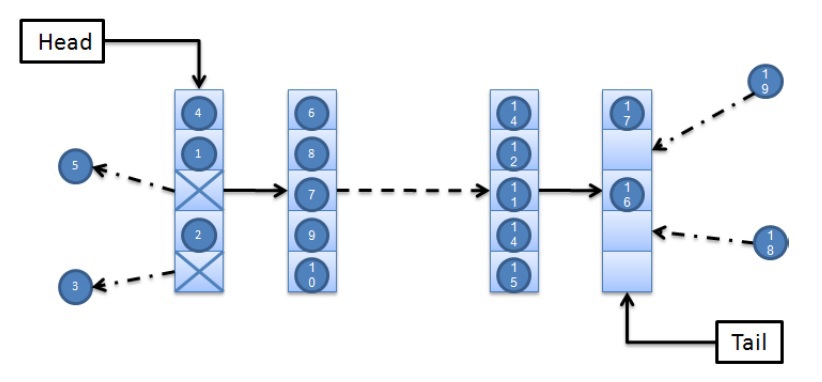
The queue is a single-linked list of segments, each segment is an array of K elements.
Head and Tail point to the first and last segment in the list, respectively. The push() operation inserts a new element into an arbitrary free slot of the tail segment, the pop() operation extracts the element from an arbitrary busy head segment slot. With this approach, it is obvious that the smaller the K segment size, the less is the FIFO property violated; with K = 1 we get a strict queue. Thus, by varying K, we can control the degree of FIFO violation.In the described algorithm, each slot of a segment can be in one of three states: free, busy (contains an element) and "garbage" (the element was read from the slot). Note that the
pop() operation pop() slot in the garbage state, which is not equivalent to the “free” state: the garbage state is the final slot state, writing the value to such a slot is invalid. This demonstrates the lack of an algorithm — a slot in the garbage state cannot be reused, which leads to the distribution of new segments even in such a typical sequence of operations for the queue, such as alternating push() / pop() . This flaw was corrected in another work at the cost of a significant code complication.Investigate
So, in libcds, there are implementations of two new algorithms for queues - FCQueue and SegmentedQueue. Let's see their performance and try to understand whether it was worth doing them.
Unfortunately, the server on which I drove the tests for the previous article was loaded with other tasks, and subsequently crashed. I had to run tests on another server, less powerful - 2 x 12 core AMD Opteron 1.5GHz with 64G of memory running Linux, which was practically free - idle at 95%.
I changed the visualization of the results - instead of the test time on the Y axis, I now postpone the number of mega-operations per second (Mop / s). Let me remind you that the test is a classic producer / consumer: only 20 million operations - 10M push and 10M pop without any emulation of payload, that is, a dull swotting into a queue. In all tests, lock-free queues are used by the Hazard Pointer to safely free up memory.
Old data in new parrots
The graph from the previous article in the new parrots - MOp / s, looks like this
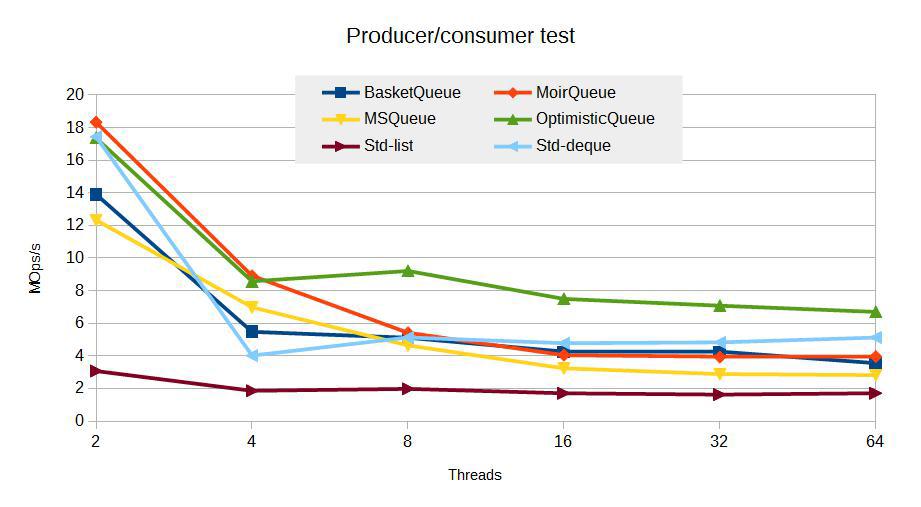
First, a digression: what are we striving for? What do we want to get in terms of scalability?
The ideal scaling is a linear increase in Mop / s with an increase in the number of streams, if the iron physically supports such a number of streams. A really good result would be some kind of increase in Mop / s, more like a logarithmic one. If, with an increase in the number of threads, we get a performance drop, the algorithm is non-scalable, or scalable to some limits.
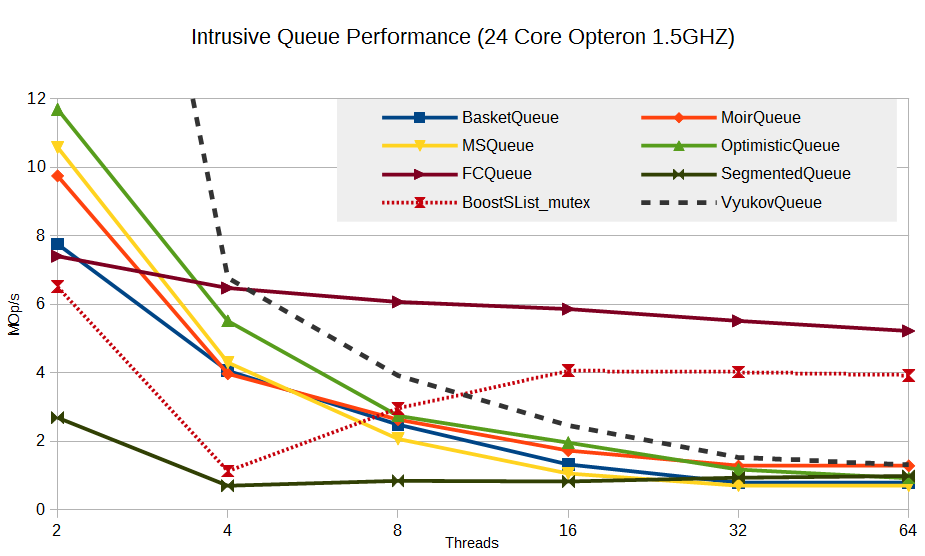
Results for intrusive queues (remember, an intrusive container is characterized by the fact that it contains a pointer to the data itself, and not their copy, as in STL; thus, it is not required to allocate memory for a copy of the elements, which is considered a move in the world of lock-free).
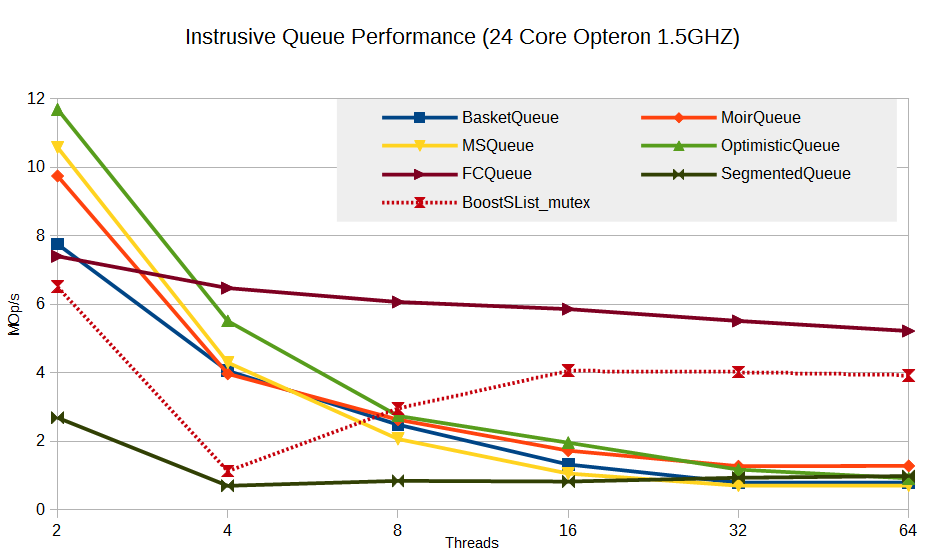
It can be seen that Flat Combining is not implemented in vain - this technique shows a very good result compared to other algorithms. Yes, it does not increase productivity, but there is no significant subsidence either. Moreover, a significant bonus is that it practically does not load the processor - only one core always works. The remaining algorithms show 100% CPU usage with a large number of threads.
The segmented queue shows itself as an outsider. Perhaps this is due to the specifics of the implemented algorithm: memory allocation for segments (in this test, the segment size is 16), the inability to reuse segment slots, which leads to permanent allocations, the implementation of the list of segments based on boost :: intrusive :: slist under blocking (I tried two types of locks - spin-lock and std :: mutex; the results are almost the same).
I had a hope that the main brake is false sharing. In the implementation of a segmented queue, the segment was an array of pointers to elements. When the segment size is 16, the segment occupies 16 * 8 = 128 bytes, that is, two cache lines. With constant crush of flows on the first and last segments, false sharing can manifest itself in full growth. Therefore, I entered an additional option in the algorithm - the required padding. By specifying padding = cache line size (64 bytes), the segment size increases to 16 * 64 = 1024 bytes, but this way we exclude false sharing. Unfortunately, it turned out that padding has almost no effect on the performance of the SegmentedQueue. Perhaps the reason for this is that the cell search algorithm of a segment is probabilistic, which leads to many unsuccessful attempts to read occupied cells, that is, again, to false sharing. Or, false sharing is not at all the main brake on this algorithm, and you need to look for the true reason.
Despite the loss, there is one interesting observation: SegmentedQueue does not show a performance drop with an increase in the number of threads. This gives hope that the algorithms of this class have some perspective. You just need to implement them differently, more efficiently.
For STL-like queues, with the creation of a copy of the element, we have a similar picture:
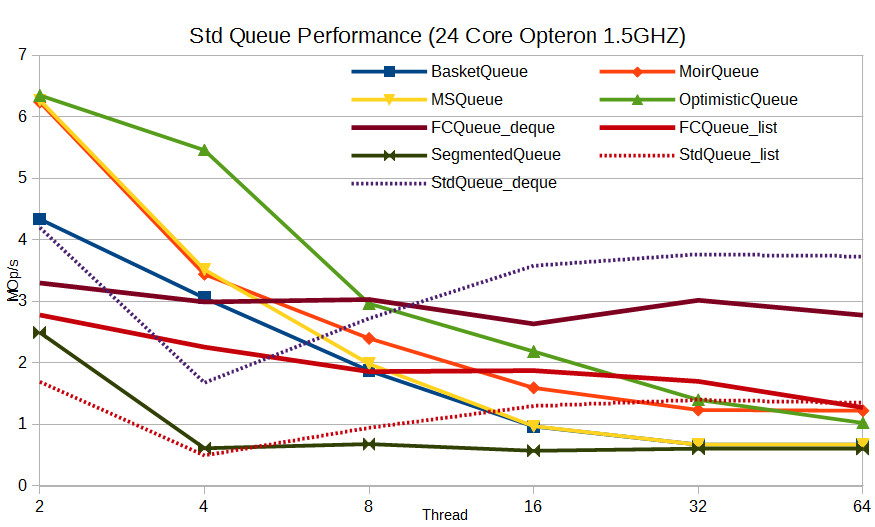
Finally, just for the sake of interest, I will give the result of a bounded queue - an array of Dmitry Vyukov, an intrusive implementation:
With the number of threads = 2 (one reader and one writer), this queue shows 32 MOPS / s, which did not fit on the chart. With an increase in the number of threads, we also observe a degradation of performance. As an excuse, it can be noted that for the Vyukov queue, false sharing can also be a very significant inhibiting factor, but the option, including padding along the cache line, is not yet in libcds for it.
for lovers of strange
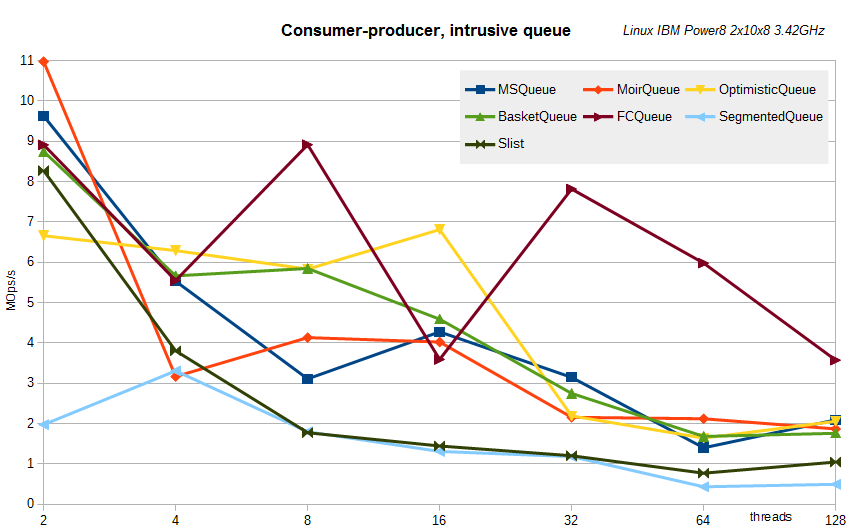
I also got an unusual Linux server on IBM Power8 - two 3.42 GHz processors with ten cores in each, each core can simultaneously execute up to 8 instructions simultaneously, for a total of 160 logical processors. Here are the results of the same tests on it.
Intrusive turns:
STL-like queues:
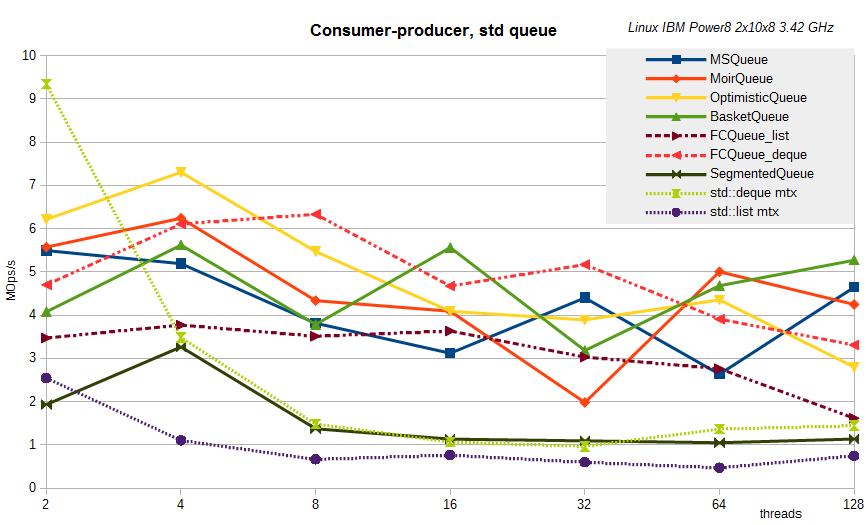
As can be seen, no fundamental changes are observed. But no, there is one thing - the results for the segmented queue are shown with the segment size K = 256 - this is exactly what K was for this server close to the best.
Intrusive turns:
STL-like queues:
As can be seen, no fundamental changes are observed. But no, there is one thing - the results for the segmented queue are shown with the segment size K = 256 - this is exactly what K was for this server close to the best.
In conclusion, I want to note one interesting observation. In the above tests for readers and writers there is no payload (payload), our goal is just to stuff into the queue and read from it. In real tasks, there is always some kind of load - we do something with the data read from the queue, and before we put in the queue, we prepare the data. It would seem that payload should lead to a drop in performance, but practice shows that this is not always the case. I have repeatedly observed that payload leads to a significant increase in MOp / s

In this article, I touched on a small part of the work on queues, and only dynamic (unbounded), that is, without limiting the number of elements. As I said, the queue is one of the favorite data structures for researchers, apparently because it is difficult to scale. There are many other works left overboard — about bounded queues, work-stealing queues used in task schedulers, single consumer or single producer queues — the algorithms of such queues are significantly sharpened per writer or reader, and therefore often easier / or much more productive, etc. etc.
News from the microworld libcds
Since the previous article, version 1.6.0 of the library has been released, in which, in addition to the implementation of the Flat Combining and SegmentedQueue techniques, a certain number of errors have been fixed, and SkipList and EllenBinTree have been significantly reworked.
The repository for the upcoming version 2.0 moved to github , and version 2.0 itself is devoted to the transition to the C ++ 11 standard, combing code, unifying interfaces, which will break the notorious backward compatibility (which means that some entities will be renamed) and remove crutches support of old compilers (well, and, as usual, fix found and generate new bugs).
The repository for the upcoming version 2.0 moved to github , and version 2.0 itself is devoted to the transition to the C ++ 11 standard, combing code, unifying interfaces, which will break the notorious backward compatibility (which means that some entities will be renamed) and remove crutches support of old compilers (well, and, as usual, fix found and generate new bugs).
I am glad that I managed, despite the large time lag, to bring the story about queues and stacks to a logical end, because these are not the most friendly for the lock-free approach and modern data structure processors, and not very interesting for me .
Much more interesting structures are waiting for us - associative containers (set / map), in particular, hash map, with beautiful algorithms and, I hope, more grateful in terms of scalability.
Continuation, I think, will follow ...
Source: https://habr.com/ru/post/230349/
All Articles