Time versus memory using Java hash tables
This article illustrates the so-called. speed and memory tradeoff — a rule that runs in many areas of CS — using different implementations of hash tables in Java as an example. The more memory a hash table takes, the faster operations are performed on it (for example, taking a value by key).
We tested hash maps with intovy keys and values.
A measure of memory use is the relative amount of memory additionally occupied in excess of the theoretical minimum for a given size map. For example, 1000 intovy key-value pairs occupy (4 (inta size) + 4) * 1000 = 8000 bytes. If a map of this size occupies 20,000 bytes, its measure of memory usage will be (20,000 - 8,000) / 8,000 = 1.5.
')
Each implementation was tested at 9 load factors. Each implementation at each level was run on 10 sizes, logarithmically evenly distributed between 1000 and 10 000 000. Then the memory utilization figures and average operation times were independently averaged: by the three smallest sizes (“small sizes” on the charts), the three largest (large sizes ) and all ten from 1000 to 10 000 000 (all sizes).
Implementations:
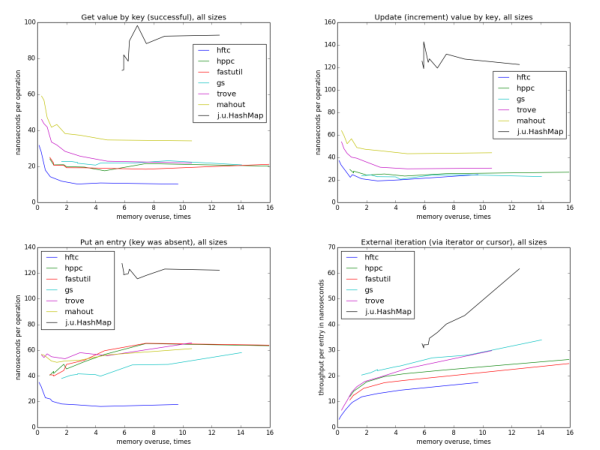
Only by looking at these pictures can we assume that HFTC, Trove and Mahout on the one hand, fastutil, HPPC and GS on the other, use the same hashing algorithm. (Actually, this is not quite the case.) The more sparse hash tables on average check fewer slots before finding the key, so less reads from memory occur, so the operation is faster. It can be noted that on small sizes the most unloaded maps are also the fastest for all six implementations, but on large sizes and when averaged over all sizes, starting with the memory reuse rate of ~ 4, the acceleration is not visible. This is because if the total size of the map exceeds the cache capacity of any level, the cache misses become more frequent as the size of the mapa grows. This effect compensates for the theoretical gain from a smaller number of tested slots.



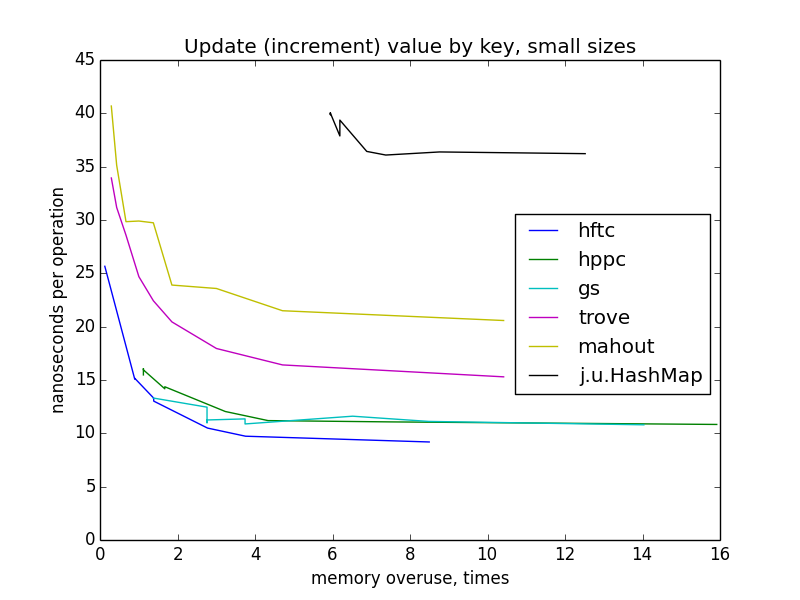
The update is quite similar to taking on a key. The implementation of fastutil was not tested, because there is no special optimized method for this operation (for the same reason, some implementations are missing when testing other operations).


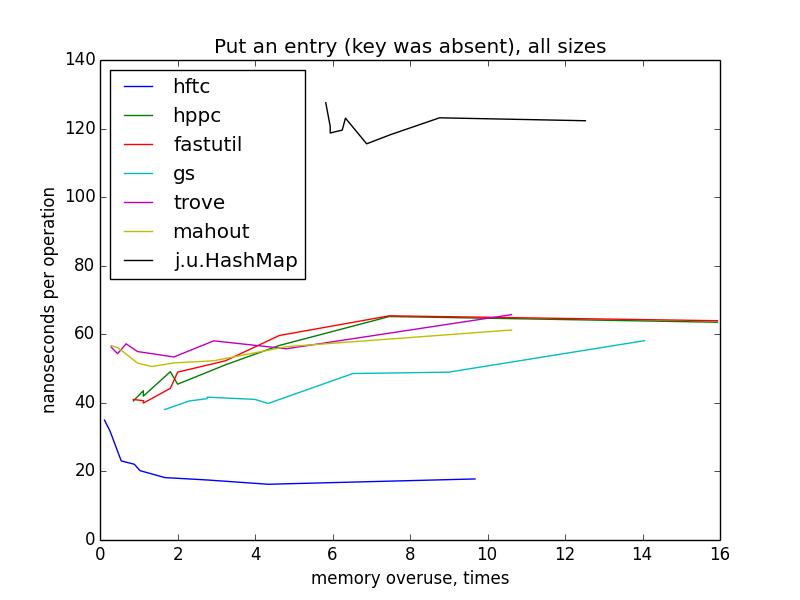
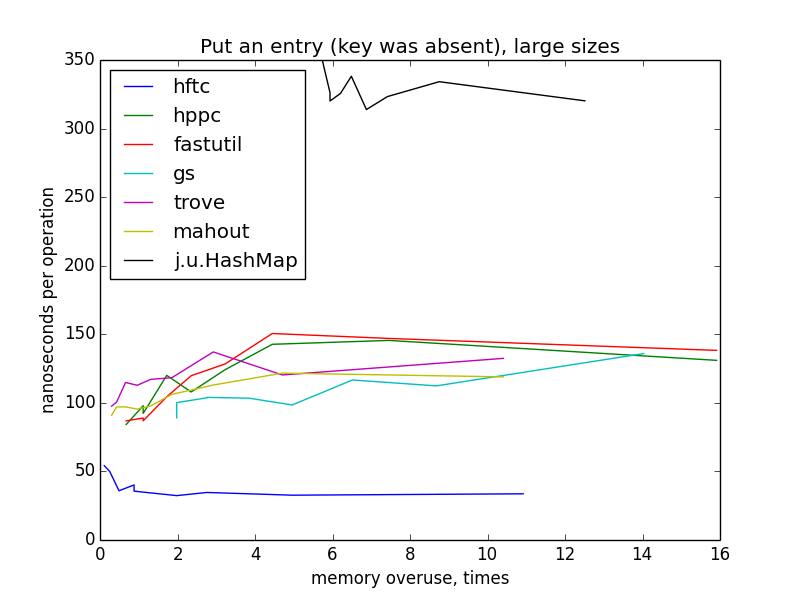
To measure this operation, the maps were filled from zero to the target size (1000 - 10 000 000). Rebuilding hash tables should not have happened, because the maps were initialized by the target size in the constructors.
On small sizes, the graphics are still similar to hyperbolas, but I do not have a clear explanation for such a dramatic change in the image when switching to large sizes and the difference between HFTC and other primitive implementations.

The iteration becomes slower with decreasing memory efficiency, in contrast to individual key operations. It is also interesting that for all implementations with open hashing, the speed depends only on the reuse of memory, and not on the theoretical table load, because it differs for different implementations at the same reuse level. Also, unlike other operations, forEach speed is practically independent of the size of the table.
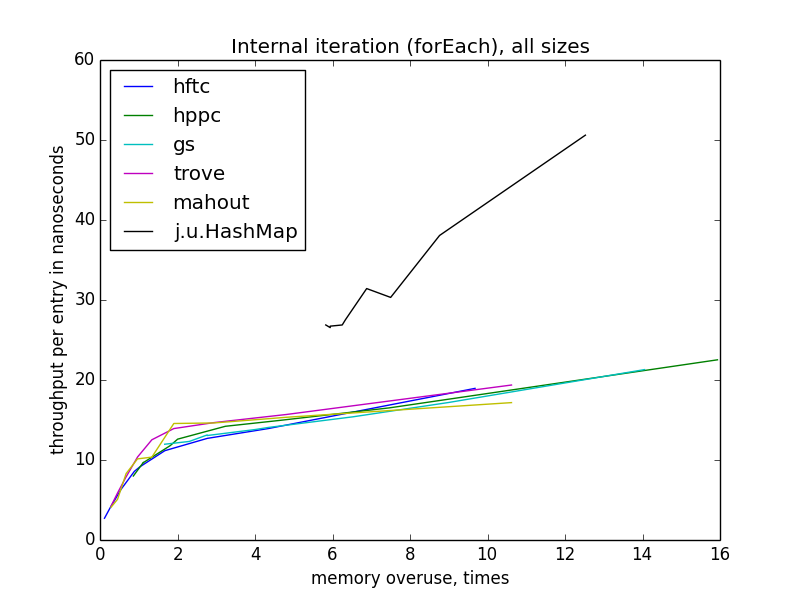
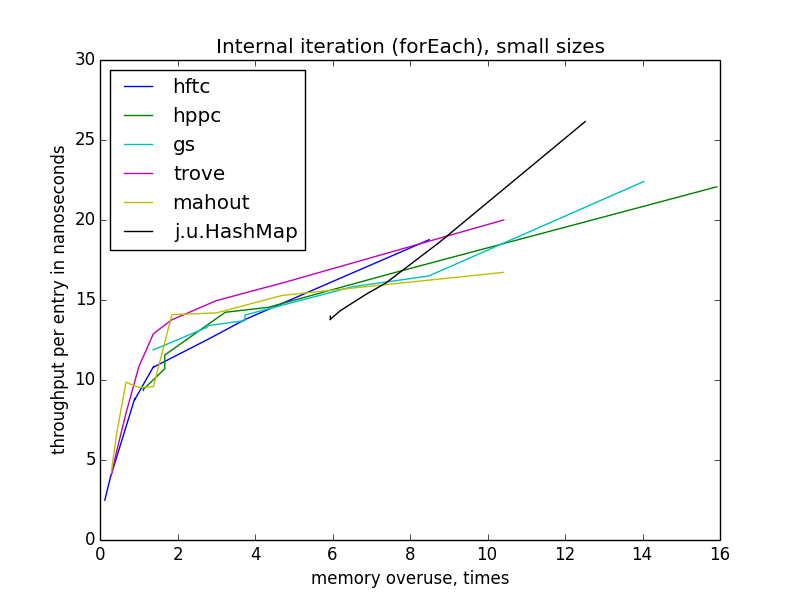

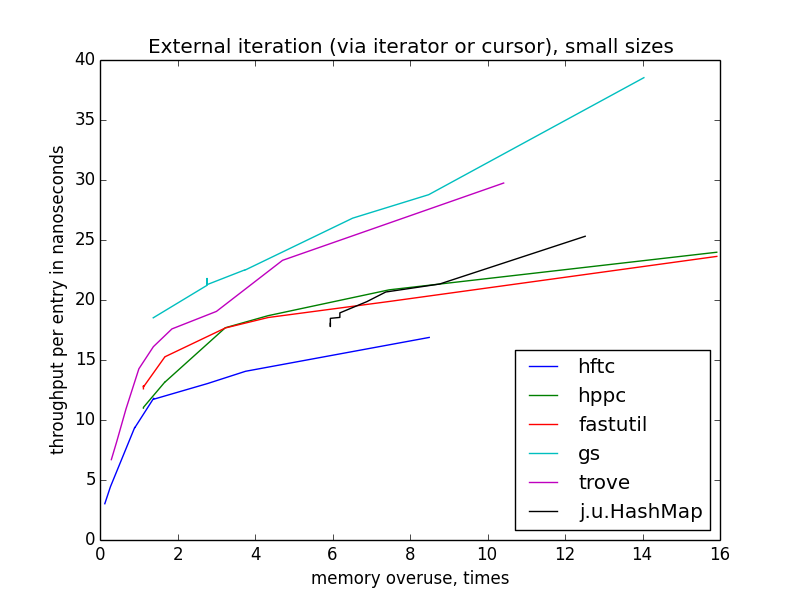
The speed of the outer iteration is dancing a lot more than the internal one, because there is more space for optimizations (more precisely, there are more opportunities to do something that is not optimal). HFTC and Trove use their own interfaces, other implementations are


Raw results of measurements on which the pictures were built in this post. There, in the description, there is a link to the benchmark code and information about the runtime environment.
PS This article is in English .
How to measure
We tested hash maps with intovy keys and values.
A measure of memory use is the relative amount of memory additionally occupied in excess of the theoretical minimum for a given size map. For example, 1000 intovy key-value pairs occupy (4 (inta size) + 4) * 1000 = 8000 bytes. If a map of this size occupies 20,000 bytes, its measure of memory usage will be (20,000 - 8,000) / 8,000 = 1.5.
')
Each implementation was tested at 9 load factors. Each implementation at each level was run on 10 sizes, logarithmically evenly distributed between 1000 and 10 000 000. Then the memory utilization figures and average operation times were independently averaged: by the three smallest sizes (“small sizes” on the charts), the three largest (large sizes ) and all ten from 1000 to 10 000 000 (all sizes).
Implementations:
- Higher Frequency Trading Collections (HFTC)
- High Performance Primitive Collections (HPPC)
- fastutil collections
- Goldman Sachs Collections (GS)
- Trove collections
- Mahout Collections
java.util.HashMapfor comparison. All other implementations are primitive specializations, andHashMapbauxite values, so the comparison is notoriously unfair, but nonetheless.
Taking value by key (successful search)
Only by looking at these pictures can we assume that HFTC, Trove and Mahout on the one hand, fastutil, HPPC and GS on the other, use the same hashing algorithm. (Actually, this is not quite the case.) The more sparse hash tables on average check fewer slots before finding the key, so less reads from memory occur, so the operation is faster. It can be noted that on small sizes the most unloaded maps are also the fastest for all six implementations, but on large sizes and when averaged over all sizes, starting with the memory reuse rate of ~ 4, the acceleration is not visible. This is because if the total size of the map exceeds the cache capacity of any level, the cache misses become more frequent as the size of the mapa grows. This effect compensates for the theoretical gain from a smaller number of tested slots.
Update (increment) values by key
The update is quite similar to taking on a key. The implementation of fastutil was not tested, because there is no special optimized method for this operation (for the same reason, some implementations are missing when testing other operations).
Writing a key-value pair (the key was not in the map)
To measure this operation, the maps were filled from zero to the target size (1000 - 10 000 000). Rebuilding hash tables should not have happened, because the maps were initialized by the target size in the constructors.
On small sizes, the graphics are still similar to hyperbolas, but I do not have a clear explanation for such a dramatic change in the image when switching to large sizes and the difference between HFTC and other primitive implementations.
Internal Iteration (forEach)
The iteration becomes slower with decreasing memory efficiency, in contrast to individual key operations. It is also interesting that for all implementations with open hashing, the speed depends only on the reuse of memory, and not on the theoretical table load, because it differs for different implementations at the same reuse level. Also, unlike other operations, forEach speed is practically independent of the size of the table.
External iteration (via iterator or cursor)
The speed of the outer iteration is dancing a lot more than the internal one, because there is more space for optimizations (more precisely, there are more opportunities to do something that is not optimal). HFTC and Trove use their own interfaces, other implementations are
java.util.Iterator .Raw results of measurements on which the pictures were built in this post. There, in the description, there is a link to the benchmark code and information about the runtime environment.
PS This article is in English .
Source: https://habr.com/ru/post/230283/
All Articles