We write a simple system of recommendations on the example of Habr

Today we will talk about recommender systems, and more precisely about the simplest form of collaborative filtering. In the program guide: what is a recommender system, what is it based on, what is the mathematical apparatus and how can it be translated into code. As a bonus, we will provide the results in the form of a simple service.
- What is a recommendation system
- Intuition
- Theory
- Implementation: code and data
- Service Habra-recommendations
- Habra analytics
What is a recommendation system
In fact, we are confronted daily with recommendatory systems, even if sometimes we don’t notice it. In the most explicit form, their work is visible in online stores such as Amazon.

')
The main task of the system is to offer new products based on the purchased-viewed. Several goals are pursued at once, but the main one is to offer the goods to the buyer, which will most likely lead to the sale and satisfy its demands. This means that, informally, the recommender system offers some sort of ordered list of products, based on the buyer's background.
Intuition
In this article we are talking about user-based collaborative filtering. This title may seem formidable, but quite simple ideas stand behind it. “Collaborative” means based on the preferences of a particular group. For example, if Vasya, Petya and Sasha buyers of a bookstore and their tastes are similar, then we can recommend to Sasha purchases based on the purchasing history of Vasya and Petit.

(picture taken from here ).
The picture describes a simple situation where several users watched the video, and only some of them liked it. When we decide whether to recommend a video to a user, we find that similar users dislike this video. As a result, it is not worth recommending. In other words, we filter content based on a similar group, hence the name collaborative filtering .
Theory
In this article we will consider only the case of a binary evaluation: “like” or “no rating”. This model is applicable to favorites on Habré. If the user has saved an article to himself, then he considers it interesting or useful, and if there is no assessment, then this does not mean anything, maybe he just did not see this article.
There are several ways to filter (or more precisely, rank) content, we will look at the so-called user-based ( user-based ) method.
Data
We have two user entities and articles in favorites . With each user i, we associate multiple articles u i .
Related users
We define the "similarity" of two users i and j as
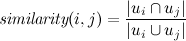
This is the so-called Jacquard coefficient , which determines the degree of similarity of the two sets.
The idea is simple - to determine how the total part of the articles of two users relates to their total.
Recommend article
Let some article p (from the post) is not in favorites, i.e. does not belong to the set u i , then we define the similarity of likes (“how likely you will like it”) between the user and the article as follows:
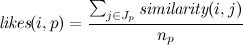
where n p and J p are the number of users and the users who added the post p favorites.
The idea behind the formula is simple, the contribution of one user equals the degree of similarity, and normalization to the number of users themselves.
Recommendations
Recommendations are a few posts with the maximum likes value.
Implementation: code and data
To implement, we need to take a few steps:
- Collect user list
- Collect recommendations
- Count n p
- Write a likes function and get maximum k results
Collect user list
The algorithm is simple: one of the first posts for 2013 was chosen and for each post users who left a comment were gathered, and the author of the post himself. Total compiled a list of 25 thousand users. The function code get_all_user_names can be found via git in the file: recommender.py , and the list of users in the HabraData repository itself (this is the repository where I collect all sorts of interesting data from Habra) in the file user_list.txt
Collect recommendations
Each user, for example, has a favorites tab that can be parsed and get data from the list. The collected data can be found in the user_f favorites.csv file, and the collection code itself is in the same source as above.
Count n p
For each collected post we go through all users and count the number of post appearances. The data in the post_counts.csv file.
Likes function
The main function code is shown in the spoiler below. Brief description: for each user, we consider its similarity with all other users, and if for another user the similarity is not zero, then we update the similarity of the input-user and the corresponding post. At the end, we normalize and sort in descending order.
def give_recommendations (username, preferences, weights)
def give_recommendations(username, preferences, weights): preference = preferences[username] rank = {} for user_other, preference_other in preferences.iteritems(): if username != user_other: similarity = jaccard_index(preference, preference_other) if not similarity: continue for post in preference_other: if post not in preference: rank.setdefault(post, 0) rank[post] += similarity #normalize and convert to post_list = [(similarity/weights[post], post) for post, similarity in rank.items()] post_list.sort(reverse=True) To perusal: practical book Programming Collective Intelligence and this post .
Service Habra-recommendations
Based on the algorithm, we will make a simple recommendation service for users:
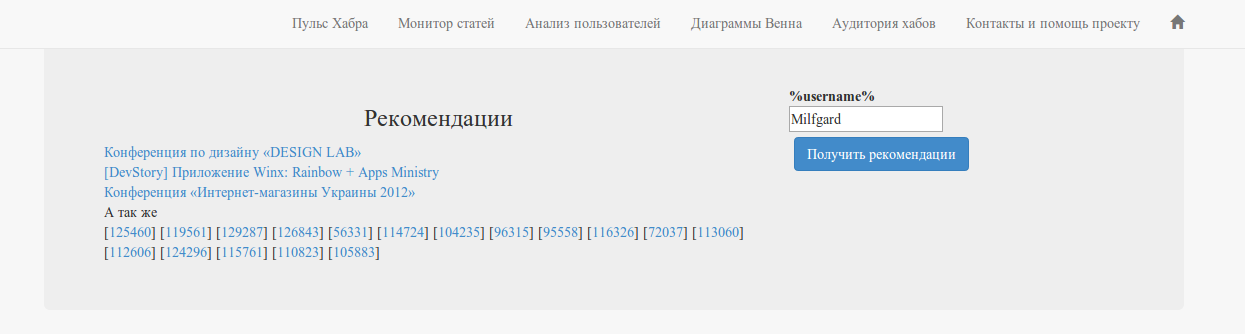
Available at:
www.habr-analytics.com/recommender
(carefully, the author tested the recommendation system at 4 am)
The algorithm considered in this article is one of the most simple and naive (according to the model's assumptions), so you should not overestimate the results of its work. On the other hand, advanced algorithms are largely based on the same ideas and use similar techniques for modeling recommendations, and therefore it is useful to have at least a general understanding of user-based filtering.
Habra Analytics
If analyst on the example of Habr interested, then in addition to the recommendations of the current version of the project www.habr-analytics.com supports the monitor of articles, user analysis and a number of other options. More information about the interesting application of the system is written in the article " The syndrome of the step and cut of attendance Habr ."
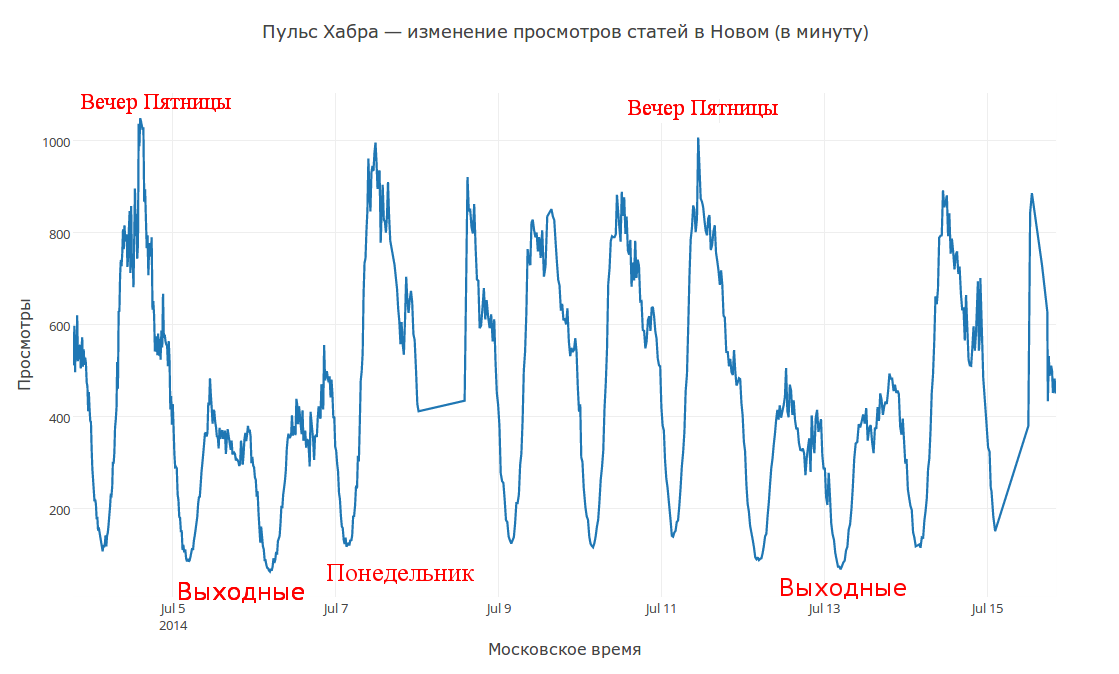
And also in this article describing each of the functions separately.
Source: https://habr.com/ru/post/230155/
All Articles