Automatic code alignment

Good day.
Among the ways to improve the readability of the code associated with the visual perception of the text, the following can be highlighted:
')
- Syntax highlighting
- Use indents
- Vertical alignment
The first 2 methods have proven themselves and are used in almost all modern IDE and advanced text editors. The third method did not find such wide distribution. This gap, both from a theoretical and from a practical point of view, I will try to fill in this article.
It would be a mistake to say that this problem was never solved. A quick search showed that there are many implementations, including for the Sublime Text editor I use.
However, if you look more closely, it becomes clear that almost all of these plug-ins implement alignment only for one pre-selected symbol. Among the most advanced versions builds highlight the following tool . But it also has a significant drawback: it uses a closed source DLL for its work, which makes it impossible to use it cross-platform, including under Linux.
In this regard, I decided to look for my own method for solving the problem.
It should be noted that initially I assumed that I would spend no more than a couple of evenings on the decision, but the task turned out to be much more difficult than it seemed to me at first glance.
The first unsuccessful option was to simply find pairs of similar tokens in two adjacent lines, and then align it to them. Moreover, it would be necessary to find such pairs that, firstly, would not overlap each other, and secondly, they would have the maximum weighted sum of similarity coefficients. However, the following example illustrates the non-viability of this approach:
// from f(a, b + c) g(b + c, a) // to f(a, b + c ) g( b + c, a) In this case, the second argument of the function f and the first argument of the function g are so similar that they outweigh the comma resemblance. Such an alignment is unacceptable, it can knock down the table, since to determine the number of parameters of a function, it is necessary to recalculate the number of commas located in completely different places.
Obviously, a simple increase in weight for a pair (comma, comma) does not solve the problem, since the parameters of the function themselves can be arbitrarily large and, therefore, have an arbitrarily large weight.
Therefore, it is necessary to take into account not only the degree of similarity of tokens, but also the syntactic structure of the lines to be aligned.
In this case, there is a problem related to the fact that different languages have their own, sometimes unique, syntax, and I would like to see the tool as universal as possible.
Moreover, in the text of the program there can be places, which can not be aligned in any way. These include string constants and comments. Different languages recognize comments differently, for example, C / C ++ uses // , and Ruby and Python # . Therefore, the only way to increase versatility is to use the method of quickly describing the syntax of a language.
Grammar
The basic idea of using grammars is to build an expression tree in such a way that each node of this tree would be aligned separately with the corresponding node of another tree and only with it.
The structure obtained from the previous example:
f ( a , b + c ) g ( b + c , a ) 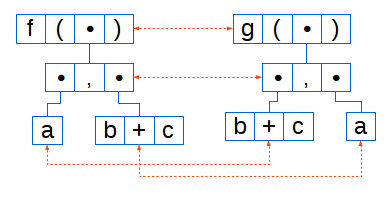
Dotted lines show the nodes between which alignment will occur.
Due to the fact that the task of the tool does not include the interpretation of the code, there is no need to keep a complete description of the syntax of each language in the program. On the contrary, it suffices to describe only those rules that we want to use for alignment. These may include the function arguments mentioned above, assignment operations, bracket constructions.
Among the requirements for grammar, the following should also be singled out: any sequence of tokens, one way or another, must be adopted by the grammar. This requirement will allow the use of a single grammar for similar languages.
The grammar used to construct the structure shown above can be described in the Backus-Naur form as follows:
main ::= expr expr ::= expr p | p | expr ',' expr p ::= '(' expr ')' |'(' ')' | any_token_except(',', ')', '(') If the string cannot be accepted by the grammar (there is no closing bracket, for example), then the recognition output will be a linear structure.
It can be noted that the selection of nodes in the tree does not correspond to every rule of grammar convolution; otherwise, each token would be in a separate node. To achieve the desired structure, it is necessary to highlight in the grammar those rules, the application of which should form new nodes in the tree. In our case, such rules should be:
expr ::= expr ',' expr p ::= '(' expr ')' During the development, an LR-0 parser was implemented using a grammar description to build an expression tree. A description of the parser construction algorithm is beyond the scope of this article; you can find more information on it in the book: Aho, Lam, Networks, Ulman - Compilers. Principles, technologies, tools.
Comparison
After receiving the expression tree, it is necessary to align the tokens with regard to their similarity. A similar problem arises in genetics when studying the genome. Sequence alignment is a method based on placing two or more sequences of DNA, RNA or protein monomers under each other in such a way that it is easy to see similar areas in these sequences [ wiki ].
One of the ways to solve this problem in bioinformatics is the use of dynamic programming, which I took as the basis for the task of aligning tokens.
As in all problems of dynamic programming, the original problem is divided into more accurate ones, the solution of which is sought recursively. In this case, a smaller task for aligning strings is to align the suffixes of these strings. As a result of the recursive passage, a matrix is obtained that associates the indices i, j of the tokens of the rows X and Y with the maximum possible total weight of the similarity of the remaining suffixes of these strings.
The restoration of similar pairs in this matrix is not difficult.
Description for getting pairs of tokens from 2 arrays in Ruby language
def match(x,y,i,j) if(@cache[[i,j]] != nil) then return @cache[[i,j]][0]; end if x.size == i then @cache[[i,j]] = [0, 3]; return 0; end if y.size == j then @cache[[i,j]] = [0, 3]; return 0; end value = []; value[0] = x[i].cmp(y[j]) + match(x,y,i+1,j+1) value[1] = match(x, y, i ,j+1) value[2] = match(x, y, i+1,j ) max_value = 0; max_index = 0; index = 0; value.each{ |x| if x > max_value then max_value = x; max_index = index; end index += 1; } @cache[[i,j]] = [max_value, max_index]; return max_value; end def get_pairs(x,y, start = 0) @cache = {}; match(x, y, start, start); pairs = []; i = j = start; curr = @cache[[i,j]][1] while curr != 3 case curr when 0 then pairs += [[i,j]] if x[i].cmp(y[j]) > Float::EPSILON i+=1; j+=1; when 1 then j+=1; when 2 then i+=1; end curr = @cache[[i,j]][1] end return [@cache[[start, start]][0], pairs]; end In order to ensure the possibility of alignment of more than two lines, among the many arrays of pairs are allocated chains, along which the alignment takes place.

The figure shows a chain of commas, which will be aligned.
Token allocation
Tokens are extracted from the string using a sequence of attempts to apply a regular expression for the corresponding type of tokens. This sequence should be arranged in such a way that more specific regular expressions are applied first, and then more general, highlighting, perhaps even individual characters. After successful recognition, the token is assigned the type corresponding to the regular expression. The project also implements a type hierarchy, which is designed to simplify the construction of grammars and improve alignment accuracy.
Until now, the question of how to calculate the similarity of two separately taken tokens has not been raised. Unfortunately, I did not manage to find a strict formal solution for this task, therefore the similarity of tokens in the current implementation is determined mainly by heuristic methods.
In particular, the similarity of identifiers is defined as the ratio of the Levenshtein distance between identifiers to the length of the maximum of them.
The default values in this case are as follows:
1 max(Levenshtein_dist / max_length, 0.1) 0 Determining the minimum indent between tokens
Placing indentation in some language constructions is considered a good programming style.
Such cases include setting spaces after a comma in the function arguments, spaces around comparison operators, etc ...
However, the options for setting spaces are not only different for different languages, but also different programmers use different styles.
f (a, b) //VS f(a, b) To simplify the setup of automatic indentation in this case, it was decided to add the possibility of learning.
A number of properly formatted strings are used as source data. For each successive pair of tokens: their type and number of spaces is remembered. The resulting data is then summarized according to the type hierarchy.
Current implementation
At the time of this writing, the program is implemented as a plugin for the Sublime Text 3 editor. Among the features, the following should be noted:
- Align selected lines using hotkeys;
- Protection against alignment of lines with different indentation. (It is assumed that before aligning the lines, indents are set correctly.);
- Support for different grammar options, selection of tokens and type hierarchy depending on the language used;
- At the time of this writing, only specialization has been implemented for the C language of the 99th standard and java.
- Source code written in Ruby, open and available on GitHub
Among the plans for the future I would like to note the following:
- Expansion of the list of specialized grammars;
- Determining the maximum number of gaps in alignment based on machine learning.
- The ability to add lines to the training set using hot keys.
Examples of the results
Examples
The last example uses the separation of the type description at the grammar level, so similar
switch (state) { case State.QLD: city = "Brisbane"; break; case State.WA: city = "Perth"; break; case State.NSW: city = "Sydney"; break; default: city = "???"; break; } // To switch (state) { case State.QLD:city = "Brisbane"; break; case State.WA :city = "Perth" ; break; case State.NSW:city = "Sydney" ; break; default :city = "???" ; break; } // From types[:space] = nil; types[:quote] = nil; types[:regexp] = nil; types[:id] = nil; types[:spchar] = nil; // To types[:space ] = nil; types[:quote ] = nil; types[:regexp] = nil; types[:id ] = nil; types[:spchar] = nil; // From long int a = 2; long long double b = 1; const int doubl = 4; // To long int a = 2; long long double b = 1; const int doubl = 4; The last example uses the separation of the type description at the grammar level, so similar
double and doubl were not aligned with each other.Thanks for attention.
Source: https://habr.com/ru/post/229465/
All Articles