Pseudo-random image (on the example of the 404th error page)
One day the author of this post worked on one order to develop a simple website and then an idea appeared - to give all pages some uniqueness and memorability - to use unique background textures or design elements (parallax-scrolling was actively used). Since at that moment the deadline was quite close, and the idea was in its infancy, it was implemented much easier - with simple blanks, but the idea was not thrown away.
After some time, I stumbled upon a dead link that led to a nonexistent Tumblr-blog, and the error page immediately attracted attention. Having updated the page, the background image (in the form of gif-animation) has changed - the attention has become even stronger. After reading the source code, it became clear that all the images are "registered" static, but this prompted another idea, which you will learn about under the cut.
')
The idea was as follows: “Why would we, when it is necessary to design a page (in particular, a service page — input, exit, error ), or just get a thematic image for the content, not use pseudo-random images?”
Semantically, by “pseudo-random” I mean images of a certain subject (or having some common features), but over time the result of “falling out” would be more or less unique.
Possible solutions:
Parsing search results was dropped for reasons of low relevance, a large amount of “garbage”, and the images themselves are stored where the devil knows where. Image hosting - somehow did not work out (maybe in vain) right away. Instagram - low image quality (640x640 pixels) and difficulty in querying to get relevant answers. And there was an extreme option - a blog platform.
I will not say that the choice was painful, as I myself am on Tumblr for a couple of blogs and I am aware of statistics. Including - statistics of posts:

Advantages of this solution:
Minuses:
Now it remains to be easy - to get the pictures themselves. I would like to separately express my gratitude to the developers of this platform, since api for receiving and selecting content is very simple and qualitatively implemented. It was decided to entrust the work of receiving and parsing the data to the client (which, without any difficulty, is copied to any server language). As a result, I got the following example (in order to reduce the length of the post css wrapped in a spoiler):
The algorithm of the function is as follows:
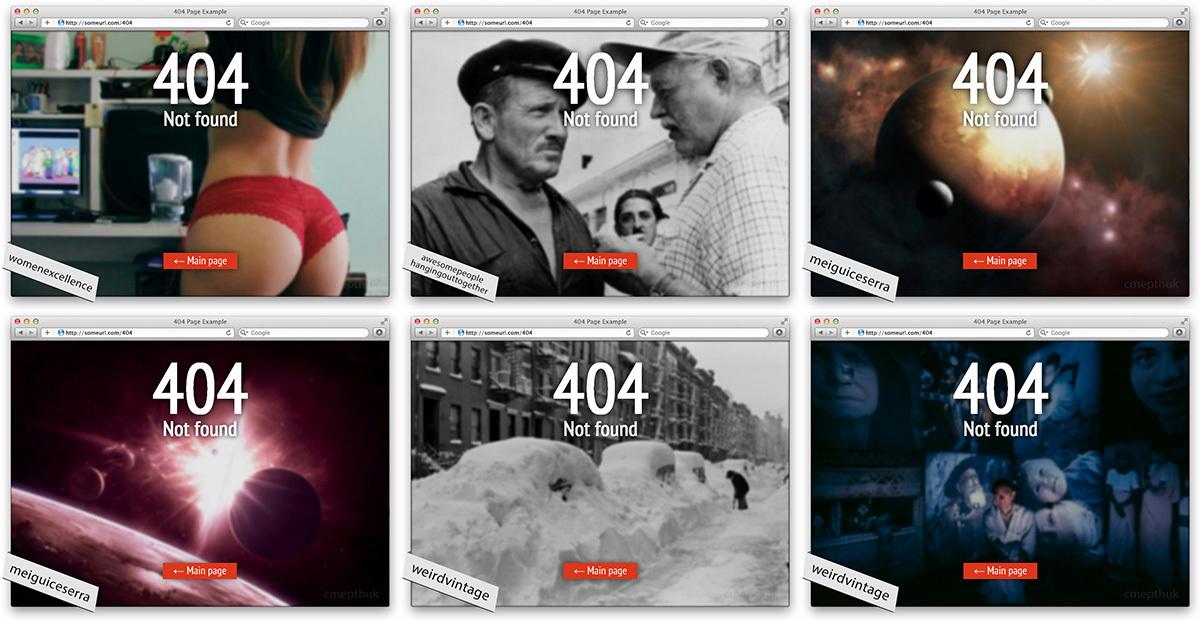
The result of the example is as follows (one image - one show):

And a few words about the form in which we return data:

Advantages of this implementation:
And cons:

This method can perfectly fit into small sites, portfolios, studios, blogs. Does not need support, easily integrates into ready-made solutions, does not load the server. It is quite realistic to use in templates for filling with test content (several lines on jQuery for replacing ' src' with <img />). I would be glad if someone helped, or pointed to another worthwhile thought.
After some time, I stumbled upon a dead link that led to a nonexistent Tumblr-blog, and the error page immediately attracted attention. Having updated the page, the background image (in the form of gif-animation) has changed - the attention has become even stronger. After reading the source code, it became clear that all the images are "registered" static, but this prompted another idea, which you will learn about under the cut.
')
The idea was as follows: “Why would we, when it is necessary to design a page (in particular, a service page — input, exit, error ), or just get a thematic image for the content, not use pseudo-random images?”
Semantically, by “pseudo-random” I mean images of a certain subject (or having some common features), but over time the result of “falling out” would be more or less unique.
Possible solutions:
- Parsing search results (google, yandex) by pictures;
- Parsing image hosting with image or tagging;
- Instagram and services like it;
- Use blogging tools with a focus on photo content.
Parsing search results was dropped for reasons of low relevance, a large amount of “garbage”, and the images themselves are stored where the devil knows where. Image hosting - somehow did not work out (maybe in vain) right away. Instagram - low image quality (640x640 pixels) and difficulty in querying to get relevant answers. And there was an extreme option - a blog platform.
I will not say that the choice was painful, as I myself am on Tumblr for a couple of blogs and I am aware of statistics. Including - statistics of posts:
Advantages of this solution:
- Images in thematic blogs stick to their concept in 9 out of 10 cases;
- If you have a corporate or personal blog on the same service, images can be taken directly from it, it turns out pretty cool;
- No need to worry about relevance;
- Images are publicly available;
- Tumblr is very friendly with ifttt .
Minuses:
- If you take content not from a blog with a well-established format, there is a chance to get an image of a
bald man in headdresses thatdoes not match the format;
Now it remains to be easy - to get the pictures themselves. I would like to separately express my gratitude to the developers of this platform, since api for receiving and selecting content is very simple and qualitatively implemented. It was decided to entrust the work of receiving and parsing the data to the client (which, without any difficulty, is copied to any server language). As a result, I got the following example (in order to reduce the length of the post css wrapped in a spoiler):
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta name="description" content="404 | Page Not Found" /> <title>404 | Page Not Found</title> <meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no" /> <link rel="shortcut icon" href="./blank-favicon.ico" /> <link href="//fonts.googleapis.com/css?family=PT+Sans+Narrow&subset=latin,cyrillic" rel="stylesheet" type="text/css" /> <style type="text/css"> CSS (click for disclosure)
* { margin:0; padding:0 } html,body{ min-height: 100%; height: 100%; min-width: 100%; background-color: #000; overflow: hidden; } body{ position:fixed; font-family: 'PT Sans Narrow',Helvetica,Arial,Verdana,sans-serif; visibility:visible; top:0; right:0; left:0; -webkit-font-smoothing:antialiased } #bg-fullscreen { position: absolute; -moz-opacity: 0; opacity: 0; top: 0; left: 0; width: 100%; height: 100%; background-size: cover; background-position: 50% 50%; -webkit-transition: opacity 2s ease-in-out; -moz-transition: opacity 2s ease-in-out; -ms-transition: opacity 2s ease-in-out; -o-transition: opacity 2s ease-in-out; transition: opacity 2s ease-in-out; -webkit-filter: blur(3px); -moz-filter: blur(3px); -o-filter: blur(3px); -ms-filter: blur(3px); filter: blur(3px); } #bg-fullscreen.show { -moz-opacity: 0.9; opacity: 0.9; } #content { position: absolute; top: 0; left: 0; width: 100%; height: 100%; text-align: center; } #content * { color: #fff; } #content h1 { font-size: 20em; text-shadow: 0px 0px 42px rgba(0, 0, 0, 1); } #content h3 { font-size: 5.4em; position: relative; top: -0.9em; text-shadow: 0px 0px 22px rgba(0, 0, 0, 1); -moz-opacity: 0.9; opacity: 0.9; } #content div.link{ position: absolute; bottom: 80px; text-align: center; width: 100%; } #content div a { display: inline-block; font-size: 3em; position: relative; padding: 0 30px 5px 30px; background-color: #d63a0a; color: #fff; text-decoration: none; -webkit-box-shadow: 0px 0px 30px 0px rgba(0, 0, 0, 0.6); -moz-box-shadow: 0px 0px 30px 0px rgba(0, 0, 0, 0.6); box-shadow: 0px 0px 30px 0px rgba(0, 0, 0, 0.6); } #content a:hover { top: -1px; } #content a:active { top: +2px !important; } #content a.home {} @media only screen and (max-width: 1280px) { #content h1 { font-size: 13em; } #content h3 { font-size: 3.8em; } #content div a { font-size: 2em; } } @media only screen and (max-width: 479px) { #content h1 { font-size: 10em; } #content h3 { font-size: 2.8em; } #content div a { font-size: 1.4em; } } </style> <noscript> <style type="text/css"> #bg-fullscreen { -moz-opacity: 0.9; opacity: 0.9; background-image: url('//habrastorage.org/files/7c1/dfc/c33/7c1dfcc3386347d0aa20b4f3cc1a410a.jpg'); } </style> </noscript> <script type="text/javascript" src="//code.jquery.com/jquery-latest.min.js"></script> <script type="text/javascript"> $(document).ready(function (){ var imagesArray = [], debug = true; function getImagesFromTumblr(blogName, imgArr, imgCount, callback, makeOffset){ var offsetStep = 20, makeOffset = typeof makeOffset !== 'undefined' ? makeOffset : 0, imgCount = typeof imgCount !== 'undefined' ? imgCount : 5; $.ajax({ type: 'GET', // https://www.tumblr.com/docs/en/api/v2 url : '//api.tumblr.com/v2/blog/'+ blogName +'.tumblr.com/posts', dataType: 'jsonp', data: { // https://www.tumblr.com/oauth/apps api_key: 'P1M2xgqzN8Q5V9Oh1eMp2a6V2YceKV5Z7FvlPZlWgDXvPT6AMs', offset: makeOffset }, success: function (data) { if(debug) console.log('Makeing request with offset = %d', makeOffset); if(data.meta.status === 200) { // if answer is 'ok' $.each(data.response.posts, function(){ if(this.type === 'photo') { $.each(this.photos, function(){ var ext = this.original_size.url.split('.').pop(); // find image extension if( // check image for: (ext === 'jpg') // 1. type - 'jpg' && (this.original_size.width >= 640) // 2. minimal width //&& (this.original_size.width > this.original_size.height) // 2. horizontal ) { if(imgArr.length < imgCount) { imgArr.push(this); } } }); } }); } // if array not full.. if(imgArr.length < imgCount) // ..make a recrussive run getImagesFromTumblr( blogName, imgArr, imgCount, callback, ((makeOffset === 0) ? offsetStep : makeOffset + offsetStep) ) else if($.isFunction(callback)) callback(true); }, error: function () { if(debug) console.error('Error try ajax request'); if($.isFunction(callback)) callback(false); }}); } // 'womenexcellence' - girls, +18 // 'life' - black'n'white photos // 'weirdvintage' - weird vintage // 'awesomepeoplehangingouttogether' - awesome people hanging out together // 'meiguiceserra' - space planets if(debug) console.time('Getting Tumblr Images Data'); getImagesFromTumblr('awesomepeoplehangingouttogether', imagesArray, 10, function(noerror){ if(debug) console.timeEnd('Getting Tumblr Images Data'); function getArrayItem(arr) { return arr[Math.floor(Math.random() * arr.length)]; } function preloadImg(url, callback) { var pImg = new Image(); pImg.onload = function() { if($.isFunction(callback)) callback(true); } pImg.src = url; } if(debug) console.log(imagesArray); if(imagesArray.length > 0) { var imageUrl = getArrayItem(imagesArray).original_size.url; if(debug) console.log('Random image url: %s', imageUrl); if(debug) console.time('Image downloading'); preloadImg(imageUrl, function(){ if(debug) console.timeEnd('Image downloading'); $('#bg-fullscreen').css({ 'background-image': 'url('+ imageUrl +')'}).addClass('show'); }); } }); }); </script> </head> <body> <div id="bg-fullscreen"></div> <div id="content"> <h1>404</h1> <h3>Not found</h3> <div class="link"> <a href="" class="home">← Main page</a> </div> </div> </body> </html> The algorithm of the function is as follows:
- We form and send an Ajax request to the Tumblr-a API ;
- We check the status of the answer and pass through each post;
- If this is a photo-post, then we go through each image;
- If the image suits us (for example, type, minimum size, aspect ratio), then add it to the final array;
- If at the end of the passage the required number of images is not collected - recursively start again, but with a new indent.
The result of the example is as follows (one image - one show):
And a few words about the form in which we return data:
Advantages of this implementation:
- If you want to use a gif-image - change the desired extension (line ~ 178) and revise the image size check;
- To change the source of images - you need to change one function call;
- When JavaScript is disabled, we will display the image from the blank (see <noscript> ... </ noscript>);
- Various image sizes are available;
- It even works in IE6 (with 'debug' turned off - mode, line ~ 153);
- Easy to "finish" by yourself.
And cons:
- On average, receiving and parsing data (it turned out 1..2 queries, 10 images) during the tests took about 0.4..1 seconds, which is quite long;
- Need to drag jQuery.
Epilogue
This method can perfectly fit into small sites, portfolios, studios, blogs. Does not need support, easily integrates into ready-made solutions, does not load the server. It is quite realistic to use in templates for filling with test content (several lines on jQuery for replacing ' src' with <img />). I would be glad if someone helped, or pointed to another worthwhile thought.
Source: https://habr.com/ru/post/229449/
All Articles