Amateur approach to computational linguistics
With this post I want to draw attention to an interesting area of applied programming that has been booming in recent years - computer linguistics. Namely - systems capable of parsing and understanding the text in Russian. But I want to shift the main focus of attention from academic and industrial systems, in which tens and thousands of man-hours are invested, to the description of the ways amateurs can achieve success in this field.
For success, we need several components: the ability to parse the text into words and lemmas, the ability to conduct morphological and syntactic analysis, and, perhaps most interestingly, the ability to search for text in the text.
In the Russian segment of the Internet, there are syntax engines, free for non-commercial use, that solve morphological and syntactic problems with good quality. I want to mention two of them.
The first one I use with great benefit is the SDK of the Russian grammar dictionary .
The second is Tomita-parser from Yandex.
')
They contain a dictionary, thesaurus, text parsing functions and have a rather low threshold of entry.
Syntax engines allow you to turn any text into a format suitable for machine processing. This can be a parse tree, which can be used to trace the relationships of words in a phrase:
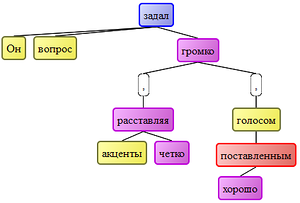
for the phrase “He asked the question loudly, clearly placing accents, in a well-placed voice.” source
And just the vector of indices of normal forms of words.
Unfortunately, for the Russian language, powerful FreeBase -level networks (1.9 billion connections) are not currently represented, and the Russian segment of DBPedia is much poorer than the English-speaking one. Commercial sources, such as the manually verified network used by ABBYY’s Compreno , are also not available to amateurs. Therefore, the network will have to form independently.
We need dictionaries, grammatical and semantic connections between words.
I used two main sources:
Wiktionary and a set of dictionaries from the site Akademik .
Wiktionary gives us the semantic properties of most common words and the connection of words with related words. Later it will be described how to use it. The Academic presents dictionaries of synonyms and antonyms - perfectly complementing Wiktionary.
With this harder. Semantic links are defined in thesauri, including the recently opened public access to the RuThes Thesaurus, but the common problem of all thesauri is their limitations. Too few words, too few links. Therefore, the connection between words can be accumulated independently - by doing a set of statistics on coordinated and inconsistent data on fiction libraries, news feeds.
The processing of large amounts of text, however, is relatively fast - 1 gigabyte of text in single-byte encoding can be processed in less than a week.
The network unites most of the currently used words of the Russian language, with 32 types of connections between words. Links such as “synonym”, “antonym”, “characteristic”, “definition”, etc. For comparison, FreeBase has more than 14 thousand types of links. But even this modest network allows you to get non-trivial results.
Imagine that a question-answer pair was received at the input of the system as a training sample:
What color is cucumber? Cucumber green.
and we want the system to correctly answer the question What is the color of orange?
How to do it? It is necessary to find a path through the network that connects the "cucumber" and "green." And which can be applied to the "orange". And it must be done automatically. The abundance of links between words in the network allows you to solve this problem as follows:
1. green is a color hyponym ( Wiktionary ).
2. Cucumber has a high-frequency connection with green (agreed ngramma. This means that in the processed literature there was often a connection between green and cucumber "on the table lay green cucumbers").
3. Therefore, the network path is defined as “cucumber <ngram“ characteristic “> GOAL <hyperonym (inverse to hyponym)> color”.
Actually, the task of finding a path through a network is a classic task of finding a path along a non-directed graph. It is clear that there may be several such paths, and each of them leads not only to the goal we need - “green”, but also to other similar words. For example - yellow. Yellow cucumbers (overripe) are also found in literature, although less often than green ones. And yellow, of course, is in exactly the same way associated with the word "color", as well as green. Therefore, we must carry out the weighting of each of the ways by weighting factors so that the search target would have the highest rating. Reworking a little, we can say that we form a self-learning network, which perceives not numerical values, but words as input signals.
So, let's try to apply the found path to other arguments:
Orange is orange, the sea is blue, the clouds are gray, and the clouds are white. The grass usually turns green, although sometimes the color is purple. Apparently, with the accumulation of ngrams there were some fantastic stories.
But also, the ocean is deep, the puddle is shallow, and the seed is small. The path is universal, and works not only for color. The path works for most questions focused on obtaining the value of the "what color / size / depth ..." characteristic.
We can use our network to form a metric — calculating the degree of similarity between different words. What does grass and cucumber have in common? They both have a connection with the word "green". But they also have connections with the words “eat”, “grow” and many others. Therefore, if you calculate the number of links that coincide in two different words, you can calculate the degree of similarity between these words. Even if these words are not represented in dictionaries and all connections between words are obtained as a result of accumulating statistics.
How can we use the numerical value of the degree of similarity between words? For example, to determine coreference links. The words “mayor” and “official” are often mentioned in the same context, and therefore have a close relationship structure with other words. We can reasonably assume that in the analyzed text behind the words "mayor" and "official" is hiding the same person. That is - to establish a connection between them.
Similarly, having met in the text "he went" it can be calculated that we are talking about an object that walks - a person or an animal. Or the official, because the official is much like a man. And having met in the text "it was closed" it can be calculated that we are talking about an enterprise, or objects similar to an enterprise.
Thus, the calculation of similarity allows the word to be attributed, taking into account its context, to one of the well-known classes “person”, “enterprise”, “place”, etc., which brings us closer to highlighting the meaning of the text.
For example, such an approach allows us to separate such texts and correctly define the meaning of the word “she”:
At the meeting, the director of the factory Sokolova. Remember, it opened in early May. and The director of the Sokolov factory spoke at the meeting. She announced plans to increase production.
In the framework of the recently held international conference on machine linguistics “Dialogue”, a review of computer linguistics systems was held, in which I participated. My system was developed specifically for the contest for 1.5 months and was based on the described similarity calculation technology between words. In the near future, the results of the competition will be published.
In any case, I want to pay special attention to the fact that “technologies have matured” and anyone who is interested can literally come close to understanding the text, to extract meaning, in just a few months. That is, to experiments in the field of artificial intelligence, previously available only in academic circles.
For success, we need several components: the ability to parse the text into words and lemmas, the ability to conduct morphological and syntactic analysis, and, perhaps most interestingly, the ability to search for text in the text.
Parsing text
In the Russian segment of the Internet, there are syntax engines, free for non-commercial use, that solve morphological and syntactic problems with good quality. I want to mention two of them.
The first one I use with great benefit is the SDK of the Russian grammar dictionary .
The second is Tomita-parser from Yandex.
')
They contain a dictionary, thesaurus, text parsing functions and have a rather low threshold of entry.
Syntax engines allow you to turn any text into a format suitable for machine processing. This can be a parse tree, which can be used to trace the relationships of words in a phrase:
for the phrase “He asked the question loudly, clearly placing accents, in a well-placed voice.” source
And just the vector of indices of normal forms of words.
Building your own semantic network
Unfortunately, for the Russian language, powerful FreeBase -level networks (1.9 billion connections) are not currently represented, and the Russian segment of DBPedia is much poorer than the English-speaking one. Commercial sources, such as the manually verified network used by ABBYY’s Compreno , are also not available to amateurs. Therefore, the network will have to form independently.
We need dictionaries, grammatical and semantic connections between words.
Dictionaries
I used two main sources:
Wiktionary and a set of dictionaries from the site Akademik .
Wiktionary gives us the semantic properties of most common words and the connection of words with related words. Later it will be described how to use it. The Academic presents dictionaries of synonyms and antonyms - perfectly complementing Wiktionary.
Semantic connection
With this harder. Semantic links are defined in thesauri, including the recently opened public access to the RuThes Thesaurus, but the common problem of all thesauri is their limitations. Too few words, too few links. Therefore, the connection between words can be accumulated independently - by doing a set of statistics on coordinated and inconsistent data on fiction libraries, news feeds.
The processing of large amounts of text, however, is relatively fast - 1 gigabyte of text in single-byte encoding can be processed in less than a week.
What was the result?
The network unites most of the currently used words of the Russian language, with 32 types of connections between words. Links such as “synonym”, “antonym”, “characteristic”, “definition”, etc. For comparison, FreeBase has more than 14 thousand types of links. But even this modest network allows you to get non-trivial results.
Conclusion by analogy
Imagine that a question-answer pair was received at the input of the system as a training sample:
What color is cucumber? Cucumber green.
and we want the system to correctly answer the question What is the color of orange?
How to do it? It is necessary to find a path through the network that connects the "cucumber" and "green." And which can be applied to the "orange". And it must be done automatically. The abundance of links between words in the network allows you to solve this problem as follows:
1. green is a color hyponym ( Wiktionary ).
2. Cucumber has a high-frequency connection with green (agreed ngramma. This means that in the processed literature there was often a connection between green and cucumber "on the table lay green cucumbers").
3. Therefore, the network path is defined as “cucumber <ngram“ characteristic “> GOAL <hyperonym (inverse to hyponym)> color”.
Actually, the task of finding a path through a network is a classic task of finding a path along a non-directed graph. It is clear that there may be several such paths, and each of them leads not only to the goal we need - “green”, but also to other similar words. For example - yellow. Yellow cucumbers (overripe) are also found in literature, although less often than green ones. And yellow, of course, is in exactly the same way associated with the word "color", as well as green. Therefore, we must carry out the weighting of each of the ways by weighting factors so that the search target would have the highest rating. Reworking a little, we can say that we form a self-learning network, which perceives not numerical values, but words as input signals.
So, let's try to apply the found path to other arguments:
Orange is orange, the sea is blue, the clouds are gray, and the clouds are white. The grass usually turns green, although sometimes the color is purple. Apparently, with the accumulation of ngrams there were some fantastic stories.
But also, the ocean is deep, the puddle is shallow, and the seed is small. The path is universal, and works not only for color. The path works for most questions focused on obtaining the value of the "what color / size / depth ..." characteristic.
Similarity calculation
We can use our network to form a metric — calculating the degree of similarity between different words. What does grass and cucumber have in common? They both have a connection with the word "green". But they also have connections with the words “eat”, “grow” and many others. Therefore, if you calculate the number of links that coincide in two different words, you can calculate the degree of similarity between these words. Even if these words are not represented in dictionaries and all connections between words are obtained as a result of accumulating statistics.
How can we use the numerical value of the degree of similarity between words? For example, to determine coreference links. The words “mayor” and “official” are often mentioned in the same context, and therefore have a close relationship structure with other words. We can reasonably assume that in the analyzed text behind the words "mayor" and "official" is hiding the same person. That is - to establish a connection between them.
Similarly, having met in the text "he went" it can be calculated that we are talking about an object that walks - a person or an animal. Or the official, because the official is much like a man. And having met in the text "it was closed" it can be calculated that we are talking about an enterprise, or objects similar to an enterprise.
Thus, the calculation of similarity allows the word to be attributed, taking into account its context, to one of the well-known classes “person”, “enterprise”, “place”, etc., which brings us closer to highlighting the meaning of the text.
For example, such an approach allows us to separate such texts and correctly define the meaning of the word “she”:
At the meeting, the director of the factory Sokolova. Remember, it opened in early May. and The director of the Sokolov factory spoke at the meeting. She announced plans to increase production.
Final part
In the framework of the recently held international conference on machine linguistics “Dialogue”, a review of computer linguistics systems was held, in which I participated. My system was developed specifically for the contest for 1.5 months and was based on the described similarity calculation technology between words. In the near future, the results of the competition will be published.
In any case, I want to pay special attention to the fact that “technologies have matured” and anyone who is interested can literally come close to understanding the text, to extract meaning, in just a few months. That is, to experiments in the field of artificial intelligence, previously available only in academic circles.
Source: https://habr.com/ru/post/229403/
All Articles