How the SMSDirect system works

Hello!
After reading here about the comparison of SMS services for mailings , we decided to tell you about our experience in building such a system, which faithfully and faithfully serves us for several years and is constantly being improved and improved. We hope our experience will be useful to you. In general, those who are interested, please under the cat.
')
What is our SMS messaging system?
The main task of the SMSDirect system is to send or send single SMS messages.
Frontend
The service represents the whole complex, the tip of the iceberg of which is the client part - the site. This is the entry point to the system. There is a personal account (if you want to download mailing lists manually), as well as a set of API methods for creating mailings and sending messages.
To log in, the client must register, and then use either a set of API methods or a personal account interface. Here, the following functions are implemented: loading and storing customer client databases (subscriber lists), as well as creating and managing mailings for these lists (or manually entered numbers).
Backend
Compounding systems: a solution capable of processing a large amount of data of the same type and forming mailings from them and a reliable mechanism linking our system with operators. The principal task here is to store a huge amount of user databases, their quick processing and access to them.
Routing
Since we have a very large amount of data, we had to decide how to process them, divide and route them.
After we divided the entire volume of data across several internal connections, we needed to ensure that each message got into the necessary gateway. Accordingly, messages need to be distributed in a certain way to the operators. Such distribution is carried out in the complex routing, which is a system of applications that is engaged in the direction of millions of messages on a particular gateway. The division is based on the analysis of the message attributes: the subscriber’s belonging to one or another operator (not just by code, but by the serving operator), message text, sender number, that is, message properties are fully analyzed and processed. Thus, we solve the problem of message distribution: the distribution seems to be one, and the messages are distributed and go in different ways depending on their operator (subscriber number) and, for example, the sender's number. Routing traffic is handled by several dedicated servers, representing part of the infrastructure outside the UI and backend.
Internal architecture
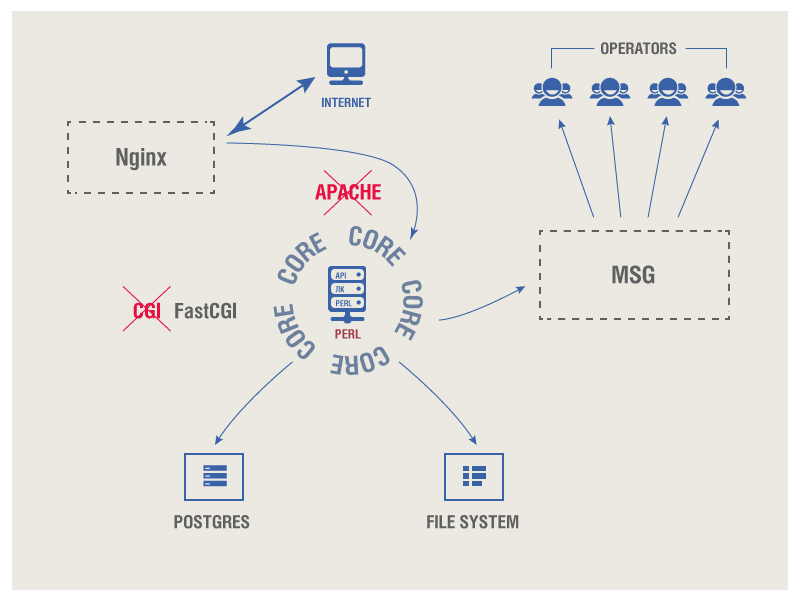
The web server that handles user access to the UI and API requests is nginx.
This solution is a classic, almost universal for such problems. Lower level, it would be logical to deploy an Apache web server, but we decided not to use them, thus saving resources (we don’t need all the functionality, and it’s not advisable to pay the full price for the 1% of our capabilities we need), and created our own Perl core . This is what, in fact, is the basis of the system.
Why Perl?
Short answer:
Long answer: This is a holivarny question, in fact there is no particular reason to use this or that language. The key issue in a large and complex project is a well-designed architecture, not a language. We have specialists who know and love different languages, the story has turned out that when developing this project, the specialists who know Perl showed the greatest zeal :) At the same time, since Perl was finally chosen, we can note the advantages of this language, the most important of which Undoubtedly, there are CPAN (read - ready-made solutions for any task) and maturity of the language (read - guaranteed performance of the code during updates (here pin to PHP)).
Core
The kernel interacts with the web server via the FastCGI interface, which, firstly, serves to forward the request that came to us and the received nginx to our kernel, secondly, FastCGI and its associated modules represent the kernel launching mechanism in the form of several “daemons”, There is always a kernel running.
The core itself is divided into several separate "demons", each of which is responsible for its own part of the processes. The most important of them are a site with a personal account, a set of API, functionality that is responsible for downloading files from the user (subscriber bases), and the core also includes a service part that does not interact with external data and is focused exclusively on internal (service) processes. By itself, this part is divided into several low-level functions. For example, when a user has downloaded a subscriber database, at first the system sees it as just a certain file with data that is not suitable for work. After the file is loaded, it is processed - the subscriber numbers are checked for correct length and prefixes, empty and too short numbers are discarded, that is, the raw file is converted into some standard internal structure containing subscriber numbers, ID, region identifier and some other service parameters .
Database
The databases loaded by the user are saved to disk and lie in the file system, but after we have run through our service scripts, the necessary descriptive information is retrieved from them, which is stored in the database. This information is structured, in it you can make queries with filters for each attribute.
When processing databases and allocating some necessary entities from them, or when processing the received statistics, sorting takes up a huge amount. Conventional sorters are unsuitable for such a volume and complexity of sorting, so for this we use MSORT.
File system
As the user loads us with large subscriber lists, they need to be stored somewhere, plus each mailing generates a huge amount of own service data: a block of generated messages for the mailing list, statuses received for these blocks, as well as a final file for export. Intermediate files are deleted after the broadcast is complete. For example, sending out 10 million messages causes 3-5 signals for each of them, and this is already 30-50 million records to a file. In general, we generate billions of records that we should not lose, because at any moment the client may need to understand the details. To do this, a separate file storage is connected to our kernel.
In some cases, there is an urgent need to find some specific record in a particular file, be it a base of numbers or some other statistics. Reading it from start to finish is long and expensive, so in a number of processes we use the forgotten tool by many - Berkeley DB (BDB). This kind of hash on the disk, which contains a certain identifier, which indicates the offset in the file from which you want to read the necessary information.
Routing and delivery of information to operators
The kernel interacts with the internal routing system that sends SMS messages to operators. This part was developed by i-Free and supported by the company's infrastructure.
We are connected to the operators, and send messages (SMS messages) using native tools. As a rule, this is SMPP, which the operator assigns to its suppliers.
Source: https://habr.com/ru/post/229279/
All Articles