Explore and test queues from Hazelcast
Many of us have heard of the Hazelcast . This is a convenient product that implements various distributed objects. In particular: storage key-values, queues, locks, etc. As a whole, assertions on distribution, scalability, resiliency and other positive properties are applied to it.
Is this true for its implementation of queues? Where are the limits of their use? This is what we will try to find out.
All tests are available on GitHub . At all, the JVM memory limit was set to 64mb to speed up the achievement of the goal, memory dump during its overflow (OOM) and forced kill the application in case of this trouble
')
And so, let's go. The latest stable version of hazelcast is used - 3.2.3.
(The tests provide approximate data on the measurement of speed and quantity. The configuration of the test machine is not published. The data are sufficient to compare the tests with each other, which is the goal)
In the first test, we will use one hazelcast node. Create a queue and add items there until we fall from a lack of memory.
The result is expected. It was possible to record 460 thousand objects at a speed of 0.026ms per item. These data will be useful to us further for comparison.
We study memory dump:
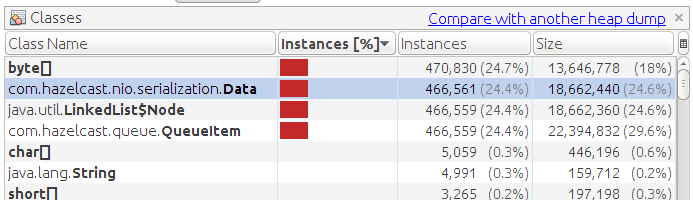
We see a large number of objects QueueItem. This internal object is created for each queue item. Contains the unique identifier of the element and the data itself (Data object)
In order not to store data in memory and thereby free it, we can connect storage to the queue. For the test, we prepared MockQueueStore, which does nothing, but regularly depicts the repository, losing all the elements sent to it. We specify the parameter "memory-limit = 0" in order to completely eliminate the storage of data in memory (by default, 1000 items are stored).
Our expectations are in getting rid of OOM, but it was not there. We managed to write more objects - 980k, but we still fell.
We look memory dump:
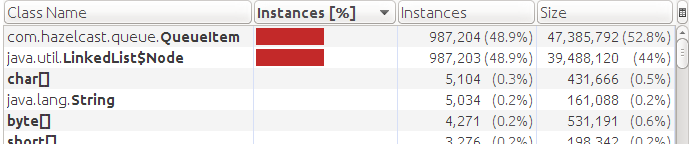
It can be seen that there are no Data objects, but the QueueItem is still in memory. This is our first discovery. The implementation of a hazelcast queue (QueueContainer) does not dispose of an auxiliary object if there is a repository. She always keeps them in the internal queue (LinkedList).
This circumstance will not allow the use of queues where potentially their uncontrolled growth in volumes exceeding the availability of free memory is potentially possible. It does not put a cross, by no means. At 50 megabytes, there are about a million items. Not all tasks are possible, so many, and more memory will be in reality. But remember this restriction is necessary. Go ahead.
Reading the source code, another feature or bug was discovered. Hazelcast allows us to manipulate our distributed objects in a transaction. Let's see what happens if we add transactions to the third test while adding items.
We get OOM on approximately 250k queue items. We look at the dump:
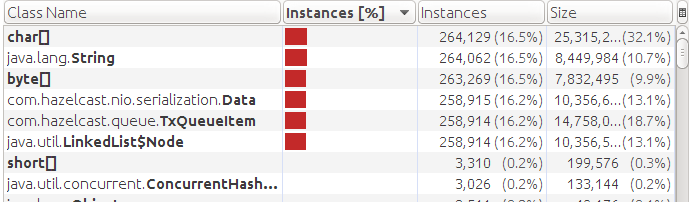
We see that there is data storage in memory (Data), although we have a storage connected. And instead of QueueItem objects, TxQueueItem is used. This is all a consequence of the implementation. When using transactions, data is not reset to the repository. And since the TxQueueItem object is a QueueItem descendant with additional fields that consumes more memory, we got even fewer items to OMM than in the first test.
Conclusion - transactions and storage for queues do not work together.
Let's move on. Let's see how queues work in a cluster.
We do not use any additional queue settings. All by default. Without storage. We put and read 100k elements. We put and read in the node owning the queue. The latter is sometimes important for data access speeds. The fact is that unlike Map, the implementation of queues is not distributed. All elements of the queue live on one of the cluster nodes - the owner of the queue. More specifically, the owner of the partition to which the queue belongs. We expect that access will be fast - like without a cluster, as we interact with the owner.
As a result, we have the following speed:
The speed dropped by an order of magnitude (compared to 0.026ms in the first test). The fact is that the default for the queue is one backup. And hazelcast when adding and reading synchronized data with the second node.
Is there a difference in speed if you add to the queue and read not from the owner of the partition?
It turns out there is no significant difference:
See comparable speed. Like in test 4, both nodes perform a similar set of operations and the result does not change from changing places of the components. The actual work goes with the owner of the queue through an intermediary containing a backup.
Let's try after filling the queue to kill the node that owns the queue. And read the data from the remaining node. We get the following result:
One remaining node begins to work much faster. He remains alone in the cluster and does not spend resources on communications to create backup.
Let's see what happens if you disable backup in the queue configuration and, as in the previous test, remove the owner.
The result is a high speed of work with the owner of the queue. He does not spend resources on a backup. But after his fall - the whole line is lost.
We don’t have a backup, and quite rightly we lost all the data after the destruction of the node - the queue owner. Let's connect the storage to this configuration and see if the data will survive? We'll store the storage a bit smarter so that it stores and gives data from the memory (MemoryQueueStore).
Result:
We see that the speed is good everywhere - an order of magnitude higher than with backup. We also see that the queue has recovered on the remaining node.
Some details about restoring the queue on the second node. In this process, all keys from the storage are first read into memory by the implementation of the QueueContainer and the largest value is determined from them for further generation of new ones. An internal queue on LinkedList is filled at once with all elements of the queue, but without data. In order to preserve the order of the elements in the queue after recovery from the storage, the storage must issue them in the correct order in the set (Set). Further, if necessary, load data from the repository. Loading comes packs. The default is 250 pieces.
And of course the main conclusion is that we must continue to test products before using them for critical tasks.
PS: The way to fix the QueueContainer implementation is outside the scope of this document. I hope there will be time and energy with this too.
Is this true for its implementation of queues? Where are the limits of their use? This is what we will try to find out.
All tests are available on GitHub . At all, the JVM memory limit was set to 64mb to speed up the achievement of the goal, memory dump during its overflow (OOM) and forced kill the application in case of this trouble
')
-Xms64m -Xmx64m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp -XX:OnOutOfMemoryError="kill -9 %p"And so, let's go. The latest stable version of hazelcast is used - 3.2.3.
(The tests provide approximate data on the measurement of speed and quantity. The configuration of the test machine is not published. The data are sufficient to compare the tests with each other, which is the goal)
Test 1 - memory is not infinite
In the first test, we will use one hazelcast node. Create a queue and add items there until we fall from a lack of memory.
The result is expected. It was possible to record 460 thousand objects at a speed of 0.026ms per item. These data will be useful to us further for comparison.
We study memory dump:
We see a large number of objects QueueItem. This internal object is created for each queue item. Contains the unique identifier of the element and the data itself (Data object)
Test 2 - connect storage
In order not to store data in memory and thereby free it, we can connect storage to the queue. For the test, we prepared MockQueueStore, which does nothing, but regularly depicts the repository, losing all the elements sent to it. We specify the parameter "memory-limit = 0" in order to completely eliminate the storage of data in memory (by default, 1000 items are stored).
Our expectations are in getting rid of OOM, but it was not there. We managed to write more objects - 980k, but we still fell.
We look memory dump:
It can be seen that there are no Data objects, but the QueueItem is still in memory. This is our first discovery. The implementation of a hazelcast queue (QueueContainer) does not dispose of an auxiliary object if there is a repository. She always keeps them in the internal queue (LinkedList).
This circumstance will not allow the use of queues where potentially their uncontrolled growth in volumes exceeding the availability of free memory is potentially possible. It does not put a cross, by no means. At 50 megabytes, there are about a million items. Not all tasks are possible, so many, and more memory will be in reality. But remember this restriction is necessary. Go ahead.
Test 3 - a spy feature with transactions
Reading the source code, another feature or bug was discovered. Hazelcast allows us to manipulate our distributed objects in a transaction. Let's see what happens if we add transactions to the third test while adding items.
We get OOM on approximately 250k queue items. We look at the dump:
We see that there is data storage in memory (Data), although we have a storage connected. And instead of QueueItem objects, TxQueueItem is used. This is all a consequence of the implementation. When using transactions, data is not reset to the repository. And since the TxQueueItem object is a QueueItem descendant with additional fields that consumes more memory, we got even fewer items to OMM than in the first test.
Conclusion - transactions and storage for queues do not work together.
Let's move on. Let's see how queues work in a cluster.
Test 4 - just two nodes
We do not use any additional queue settings. All by default. Without storage. We put and read 100k elements. We put and read in the node owning the queue. The latter is sometimes important for data access speeds. The fact is that unlike Map, the implementation of queues is not distributed. All elements of the queue live on one of the cluster nodes - the owner of the queue. More specifically, the owner of the partition to which the queue belongs. We expect that access will be fast - like without a cluster, as we interact with the owner.
As a result, we have the following speed:
INFO: add 100000 0.255ms
INFO: poll 100000 0.223msThe speed dropped by an order of magnitude (compared to 0.026ms in the first test). The fact is that the default for the queue is one backup. And hazelcast when adding and reading synchronized data with the second node.
Test 4_1 - we try to work not with the owner
Is there a difference in speed if you add to the queue and read not from the owner of the partition?
It turns out there is no significant difference:
INFO: add 100000 0.215msINFO: poll 100000 0.201msSee comparable speed. Like in test 4, both nodes perform a similar set of operations and the result does not change from changing places of the components. The actual work goes with the owner of the queue through an intermediary containing a backup.
Test 5 - kill the owner
Let's try after filling the queue to kill the node that owns the queue. And read the data from the remaining node. We get the following result:
INFO: add 100000 0.267msINFO: poll 100000 0.025msOne remaining node begins to work much faster. He remains alone in the cluster and does not spend resources on communications to create backup.
Test 6 - turn off backup
Let's see what happens if you disable backup in the queue configuration and, as in the previous test, remove the owner.
INFO: add 100000 0.022msThe result is a high speed of work with the owner of the queue. He does not spend resources on a backup. But after his fall - the whole line is lost.
Test 7 - connect the storage to the cluster
We don’t have a backup, and quite rightly we lost all the data after the destruction of the node - the queue owner. Let's connect the storage to this configuration and see if the data will survive? We'll store the storage a bit smarter so that it stores and gives data from the memory (MemoryQueueStore).
Result:
INFO: add 100000 0.023msINFO: poll 100000 0.018msWe see that the speed is good everywhere - an order of magnitude higher than with backup. We also see that the queue has recovered on the remaining node.
Some details about restoring the queue on the second node. In this process, all keys from the storage are first read into memory by the implementation of the QueueContainer and the largest value is determined from them for further generation of new ones. An internal queue on LinkedList is filled at once with all elements of the queue, but without data. In order to preserve the order of the elements in the queue after recovery from the storage, the storage must issue them in the correct order in the set (Set). Further, if necessary, load data from the repository. Loading comes packs. The default is 250 pieces.
Some conclusions
- Using storage does not completely free memory. It is necessary to predict the amount of data and not get on OOM
- When using storage, it is necessary to forcibly disable backup. By default it is enabled and will affect the speed and used memory of other nodes.
- The implementation of queue recovery from storage is resource-intensive and not optimal. When restoring a new owner must have no less memory than the previous one.
- When using transactions not used storage for queues
And of course the main conclusion is that we must continue to test products before using them for critical tasks.
PS: The way to fix the QueueContainer implementation is outside the scope of this document. I hope there will be time and energy with this too.
Source: https://habr.com/ru/post/228445/
All Articles