EMC XtremIO and VDI. Effective, but still raw stuff
The third day ended our two-week test period of EMC XtremIO .
CROC has already shared his impressions of this experience, but mostly in the form of synthetic test results and enthusiastic statements that, in relation to any storage system, looks impressive, but not very informative. I am currently working in the customer, not in the integrator, the application aspect is more important to us, so the testing was organized in an appropriate manner. But in order.
XtremIO is a new (relatively) product from EMC, more precisely, from XtremIO, purchased by EMC. It is an All-Flash array consisting of five modules - two single-unit Intel servers as controllers, two Eaton UPSs and one 25-disk shelf. All of the above is combined in a brick (brick) - a unit of expansion XtremIO.
The killer feature of the solution is on-the-fly deduplication. This fact was especially interesting to us, because we use VDI with full clones and we have a lot of them. Marketing promised that all will fit into one brick (brik capacity - 7.4 TB). At the moment, on a regular array, they occupy almost 70+ TB.
I forgot to photograph the subject matter of the story, but in KROK's post you can see everything in detail. I’m even sure that this is the same array.
The device came mounted in a mini-wreck. Thoughtlessly we went to take it together and almost burst out, just dragging from the car into the cart. Having disassembled into components, however, I moved it to the data center and mounted it alone without too much difficulty. Installation of the slide proposes a large number of screws to be screwed in, so I had to spend a lot of time with a screwdriver in the “G” position, but the switching pleased me - all cables of necessary and sufficient length were easily inserted and removed, but they were protected from accidental tearing. (This fact was positively noted after testing another flash storage system - Violin - in which the cable connecting two neighboring sockets for some reason was made one and a half meters long, and inserting one of the ethernet patch cords cannot be pulled out without an additional flat tool, for example, a screwdriver) .
A specially trained engineer arrived to tune the subject. It was very interesting to find out that at the moment the update of the control software is happening with data loss. Adding a new brik to the system - too. Departure of two disks at once also leads to data loss (without loss the second disk can be lost after a rebuild), but this is promised to be fixed in the next update. As for me, it would be better to do the first two points in a normal way.
To fully configure and manage the array, the system requires a dedicated server (XMS - XtremeIO Management Server). It can be ordered as a physical addition to the kit (I suppose, by increasing the cost of the solution by the price of the weight equivalent of this server in gold), or you can simply deploy the virtual machine (linux) from the template. After that, you need to put into it an archive with software and install it. And then set up using a half dozen default uchetok. In general, the initial configuration process differs from the usual storage configuration and is not to say that it is in the direction of relief. I hope it will be finalized.
Without further ado, as a test, we decided to transfer part of the combat VDI to the device under test and see what happens. Especially interested in the effectiveness of dedupu. I didn’t believe in the 10: 1 ratio, because even though we have complete clones, profiles and some user data lie inside the VM (although their volume is often small relative to the OS), and I’m just skeptical about claimed miracles.
')
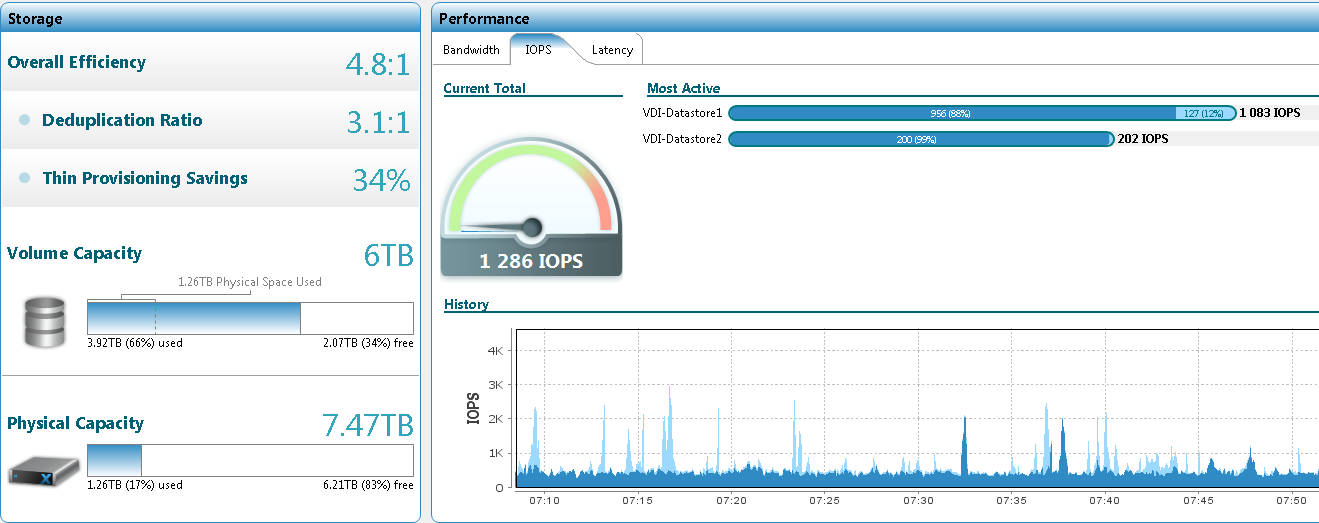
The first transferred 36 VMs occupied 1.95 TB on the datastore, and 0.64 TB on the disks. The deduplication ratio is 2.7: 1. True, the first batch consisted of virtual desktops of IT department representatives who especially like to keep everything inside their PC, no matter if it is physical or virtual. Many even have extra drives. As the system is filled with all new machines, the coefficient has grown, but not significantly, without jerks. Here's an example of a screenshot of a system with a hundred virtual locks:
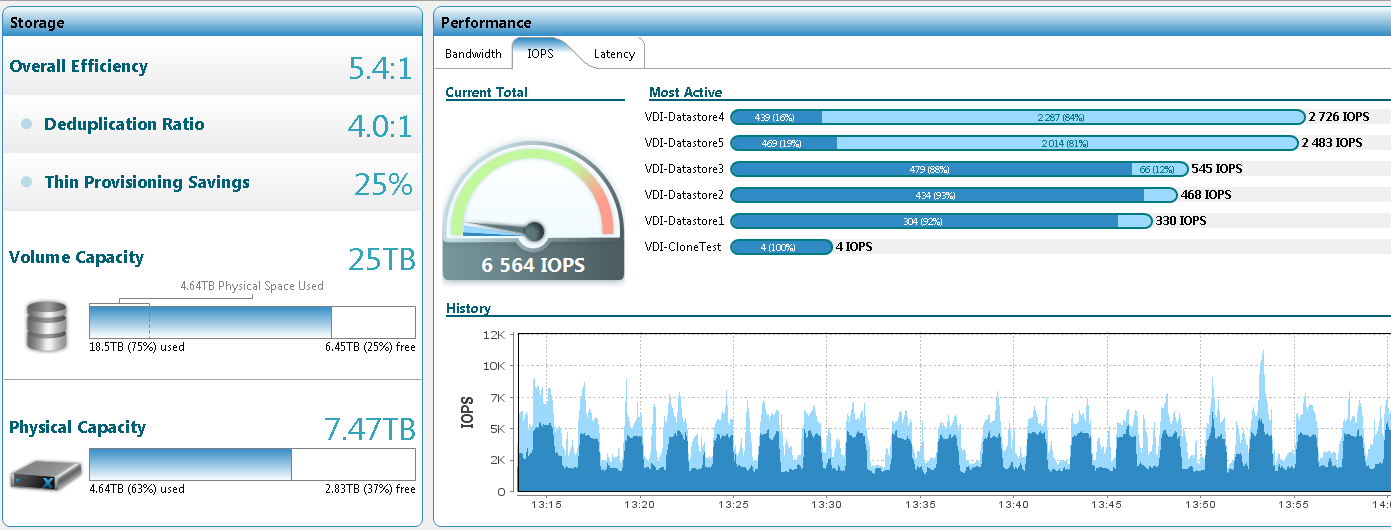
But 450:

The average vmdk size is 43 GB. Inside - Windows 7 EE.
I decided to stop on this amount and turn a new test - create a new datastor and score it with “clean” clones, freshly deployed from a template, checking both the deployment time and dedup. The results are impressive:
100 clones created;
datastor 4 TB full;
the amount of disk space occupied increased by 10 GB.
Screenshot (compare with previous):
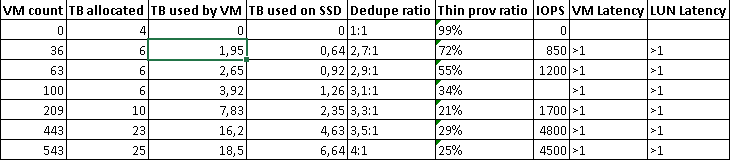
Here is the full results tab:
There was also a thought to include these 100 clones and see a) how the system behaves in bootstrap, b) how the dedupus ratio will change after switching on and some time of the clean system operation. However, these activities had to be postponed, because something happened that can be called unpleasant behavior. One of the five LUNs was blocked and staked the entire cluster.
We have to admit that the reason lies in the features of the configuration of hosts. Due to the use of IBM SVC as a storage aggregator (it’s not okay), the hosts had to disable Hardware Assist Lock - an essential element of VAAI, which allows you to block not the entire datastor when changing metadata, but a small sector of it. So why LUN was blocked is understandable. Why he did not unlock - not very. And it is completely incomprehensible why it did not unblock even after it was disconnected from all hosts (it was necessary, because until we did this, not a single VM could turn on or emigrate, but as luck would have it, at that very moment someone from Very Important People of the company needed to rebuild their cars) and passed all imaginable and inconceivable timeouts. According to the old-timers, this behavior was observed on the old IBM DSxxxx, but they had a special LUN unlock button for such cases.
There is no such button here, as a result, 89 people were left without access to their desktops for three hours, and we were already thinking about restarting the array and were looking for the safest and most reliable way to this (alternately restarting the controllers did not help).
EMC support helped, who at first took out the necessary engineer from their depths, who then checked and looked through all the tabs and consoles for a long time, and the solution itself was simple and elegant:
vmkfstools --lock lunreset /vmfs/devices/disks/vml.02000000006001c230d8abfe000ff76c198ddbc13e504552432035
that is, the command to unlock from any host.
Live and learn.
For the next week, I frantically transferred desktops back to HDD storage, setting all tests aside for later-if-if-then-time. There is no time left, since the array was taken away two days earlier than the promised time, since the next tester was not in Moscow, but Ufa (the surprise and orderliness in the return procedure costs separate non-fully standard statements).
Ideologically, I liked the solution. If we slightly finish our VDI infrastructure by bringing user data to a file server, then we can place all of our 70 TB if not on one, then on two or three bricks. That is, 12-18 units against the whole rack. Could not, of course, not like the speed of svMotion and clone deployment (less than a minute). However, it is still damp. Data loss when updating and scaling cannot be considered acceptable in the enterprise. And the moment with the reservation lock was also embarrassing.
On the other hand, it somehow looks like an unfinished Nutanix. The last truth can only be assessed by presentations, but they are always beautiful.
And about the price. CROC, in his posts, wrote about some incomprehensible figure of 28 million. I heard about six and a half, and it was not yet the minimum. Although I have no access to price negotiations nowadays, so I’ll not take it for sure.
CROC has already shared his impressions of this experience, but mostly in the form of synthetic test results and enthusiastic statements that, in relation to any storage system, looks impressive, but not very informative. I am currently working in the customer, not in the integrator, the application aspect is more important to us, so the testing was organized in an appropriate manner. But in order.
general information
XtremIO is a new (relatively) product from EMC, more precisely, from XtremIO, purchased by EMC. It is an All-Flash array consisting of five modules - two single-unit Intel servers as controllers, two Eaton UPSs and one 25-disk shelf. All of the above is combined in a brick (brick) - a unit of expansion XtremIO.
The killer feature of the solution is on-the-fly deduplication. This fact was especially interesting to us, because we use VDI with full clones and we have a lot of them. Marketing promised that all will fit into one brick (brik capacity - 7.4 TB). At the moment, on a regular array, they occupy almost 70+ TB.
I forgot to photograph the subject matter of the story, but in KROK's post you can see everything in detail. I’m even sure that this is the same array.
Installation and configuration
The device came mounted in a mini-wreck. Thoughtlessly we went to take it together and almost burst out, just dragging from the car into the cart. Having disassembled into components, however, I moved it to the data center and mounted it alone without too much difficulty. Installation of the slide proposes a large number of screws to be screwed in, so I had to spend a lot of time with a screwdriver in the “G” position, but the switching pleased me - all cables of necessary and sufficient length were easily inserted and removed, but they were protected from accidental tearing. (This fact was positively noted after testing another flash storage system - Violin - in which the cable connecting two neighboring sockets for some reason was made one and a half meters long, and inserting one of the ethernet patch cords cannot be pulled out without an additional flat tool, for example, a screwdriver) .
A specially trained engineer arrived to tune the subject. It was very interesting to find out that at the moment the update of the control software is happening with data loss. Adding a new brik to the system - too. Departure of two disks at once also leads to data loss (without loss the second disk can be lost after a rebuild), but this is promised to be fixed in the next update. As for me, it would be better to do the first two points in a normal way.
To fully configure and manage the array, the system requires a dedicated server (XMS - XtremeIO Management Server). It can be ordered as a physical addition to the kit (I suppose, by increasing the cost of the solution by the price of the weight equivalent of this server in gold), or you can simply deploy the virtual machine (linux) from the template. After that, you need to put into it an archive with software and install it. And then set up using a half dozen default uchetok. In general, the initial configuration process differs from the usual storage configuration and is not to say that it is in the direction of relief. I hope it will be finalized.
Operation, deduplication and problem situation
Without further ado, as a test, we decided to transfer part of the combat VDI to the device under test and see what happens. Especially interested in the effectiveness of dedupu. I didn’t believe in the 10: 1 ratio, because even though we have complete clones, profiles and some user data lie inside the VM (although their volume is often small relative to the OS), and I’m just skeptical about claimed miracles.
')
The first transferred 36 VMs occupied 1.95 TB on the datastore, and 0.64 TB on the disks. The deduplication ratio is 2.7: 1. True, the first batch consisted of virtual desktops of IT department representatives who especially like to keep everything inside their PC, no matter if it is physical or virtual. Many even have extra drives. As the system is filled with all new machines, the coefficient has grown, but not significantly, without jerks. Here's an example of a screenshot of a system with a hundred virtual locks:
But 450:
The average vmdk size is 43 GB. Inside - Windows 7 EE.
I decided to stop on this amount and turn a new test - create a new datastor and score it with “clean” clones, freshly deployed from a template, checking both the deployment time and dedup. The results are impressive:
100 clones created;
datastor 4 TB full;
the amount of disk space occupied increased by 10 GB.
Screenshot (compare with previous):
Here is the full results tab:
There was also a thought to include these 100 clones and see a) how the system behaves in bootstrap, b) how the dedupus ratio will change after switching on and some time of the clean system operation. However, these activities had to be postponed, because something happened that can be called unpleasant behavior. One of the five LUNs was blocked and staked the entire cluster.
We have to admit that the reason lies in the features of the configuration of hosts. Due to the use of IBM SVC as a storage aggregator (it’s not okay), the hosts had to disable Hardware Assist Lock - an essential element of VAAI, which allows you to block not the entire datastor when changing metadata, but a small sector of it. So why LUN was blocked is understandable. Why he did not unlock - not very. And it is completely incomprehensible why it did not unblock even after it was disconnected from all hosts (it was necessary, because until we did this, not a single VM could turn on or emigrate, but as luck would have it, at that very moment someone from Very Important People of the company needed to rebuild their cars) and passed all imaginable and inconceivable timeouts. According to the old-timers, this behavior was observed on the old IBM DSxxxx, but they had a special LUN unlock button for such cases.
There is no such button here, as a result, 89 people were left without access to their desktops for three hours, and we were already thinking about restarting the array and were looking for the safest and most reliable way to this (alternately restarting the controllers did not help).
EMC support helped, who at first took out the necessary engineer from their depths, who then checked and looked through all the tabs and consoles for a long time, and the solution itself was simple and elegant:
vmkfstools --lock lunreset /vmfs/devices/disks/vml.02000000006001c230d8abfe000ff76c198ddbc13e504552432035
that is, the command to unlock from any host.
Live and learn.
For the next week, I frantically transferred desktops back to HDD storage, setting all tests aside for later-if-if-then-time. There is no time left, since the array was taken away two days earlier than the promised time, since the next tester was not in Moscow, but Ufa (the surprise and orderliness in the return procedure costs separate non-fully standard statements).
Summary
Ideologically, I liked the solution. If we slightly finish our VDI infrastructure by bringing user data to a file server, then we can place all of our 70 TB if not on one, then on two or three bricks. That is, 12-18 units against the whole rack. Could not, of course, not like the speed of svMotion and clone deployment (less than a minute). However, it is still damp. Data loss when updating and scaling cannot be considered acceptable in the enterprise. And the moment with the reservation lock was also embarrassing.
On the other hand, it somehow looks like an unfinished Nutanix. The last truth can only be assessed by presentations, but they are always beautiful.
And about the price. CROC, in his posts, wrote about some incomprehensible figure of 28 million. I heard about six and a half, and it was not yet the minimum. Although I have no access to price negotiations nowadays, so I’ll not take it for sure.
Source: https://habr.com/ru/post/228107/
All Articles