Three new items in MongoDB 2.8
The other day I visited a great crowd of fans of NoSQL - World MongoDB Conference .

Eliot Horowitz, Co-Founder and CTO in MongoDB, spoke about 3 innovations that will be available in the next release.
Each of the announced innovations is aimed at achieving the following principles in the MongoDB architecture:
Presentation video can be viewed here .
MongoDB has been under development for 7 years. And what have users heard about consistency all these years? Mostly they heard about global lokas at the level of the whole database.
')
It is important to remember that the locks in MongoDB are very similar to the latches in relational databases - they are very simple and usually take no more than 10 milliseconds. In MongoDB 2.2, the problem of locks at the level of the entire database was solved, and the lock yielding agorhythm was also improved. This made it possible to significantly reduce the number of problems that the community had in connection with the locks. However, the MongoDB developers continued to work in this direction.
And now the moment of truth has come: MongoDB 2.8 will have document level locks! This is certainly a far greater improvement than the long-awaited lock at the collection level .
The document-level blocking has already been posted on github (v.2.7.3), but is not yet ready for production use . To enable document-level blocking, you must run
Let's try to answer one simple question: which data storage engine is best for the future of MongoDB? Focused on reading speed? Write speed? Security? The guys from MongoDB chose not to bother with the answer. They decided that none of the engines can be considered optimal for all needs at once. And you really can't argue with that. In general, they developed a replaceable API for an arbitrary storage engine.
There are quite a few requirements for this API, since it should support all existing MongoDB features, support operational scalability, add one or more nodes to the cluster, and more.
As a result, we will get the ability to connect replaceable storage, which will be optimized for specific needs: performance, data compression, etc.
Estimated storage types:
- In-Memory
- RocksDB (from Facebook, sharpened for compression)
- InnoDB (from MySQL)
- TokuKV
- FusionIO (works around the file system, sharpened for low latency)
In-Memory and RocksDB are already available in the developer branch on github. Again, do not rush to use it on combat servers.
As you know, MongoDB is able to replicate out of the box and shard. As a result, we get not one copy of the database, but several at once. In truly large projects such nodes can be very much. And the problem lies not only in the deployment of all these nodes, but also in their further updating, backup, monitoring and much more.
Mongo Management Service (MMS) will now do this routine for us.
MMS is a friendly web-based interface that allows you to solve a whole range of tasks in just a couple of mouse clicks:
And for a snack: MMS will teach you to integrate with Amazon EC2 .
I really like the fact that the MongoDB team pays a lot of attention to making their product comfortable and useful for developers. And they do it not in a spherical vacuum, but actively taking an interest in the opinion directly from the community . Therefore, I am confident that MongoDB will continue to maintain an excellent pace of introducing new features, improve security, automate and make the whole routine even more invisible.
Eliot Horowitz, Co-Founder and CTO in MongoDB, spoke about 3 innovations that will be available in the next release.
Each of the announced innovations is aimed at achieving the following principles in the MongoDB architecture:
- Developer Productivity
- Horizontal scalability
- Operational scalability
- Administration of a single web server should be simple. The same goes for clusters.
Presentation video can be viewed here .
Data consistency
MongoDB has been under development for 7 years. And what have users heard about consistency all these years? Mostly they heard about global lokas at the level of the whole database.
')
It is important to remember that the locks in MongoDB are very similar to the latches in relational databases - they are very simple and usually take no more than 10 milliseconds. In MongoDB 2.2, the problem of locks at the level of the entire database was solved, and the lock yielding agorhythm was also improved. This made it possible to significantly reduce the number of problems that the community had in connection with the locks. However, the MongoDB developers continued to work in this direction.
And now the moment of truth has come: MongoDB 2.8 will have document level locks! This is certainly a far greater improvement than the long-awaited lock at the collection level .
The document-level blocking has already been posted on github (v.2.7.3), but is not yet ready for production use . To enable document-level blocking, you must run
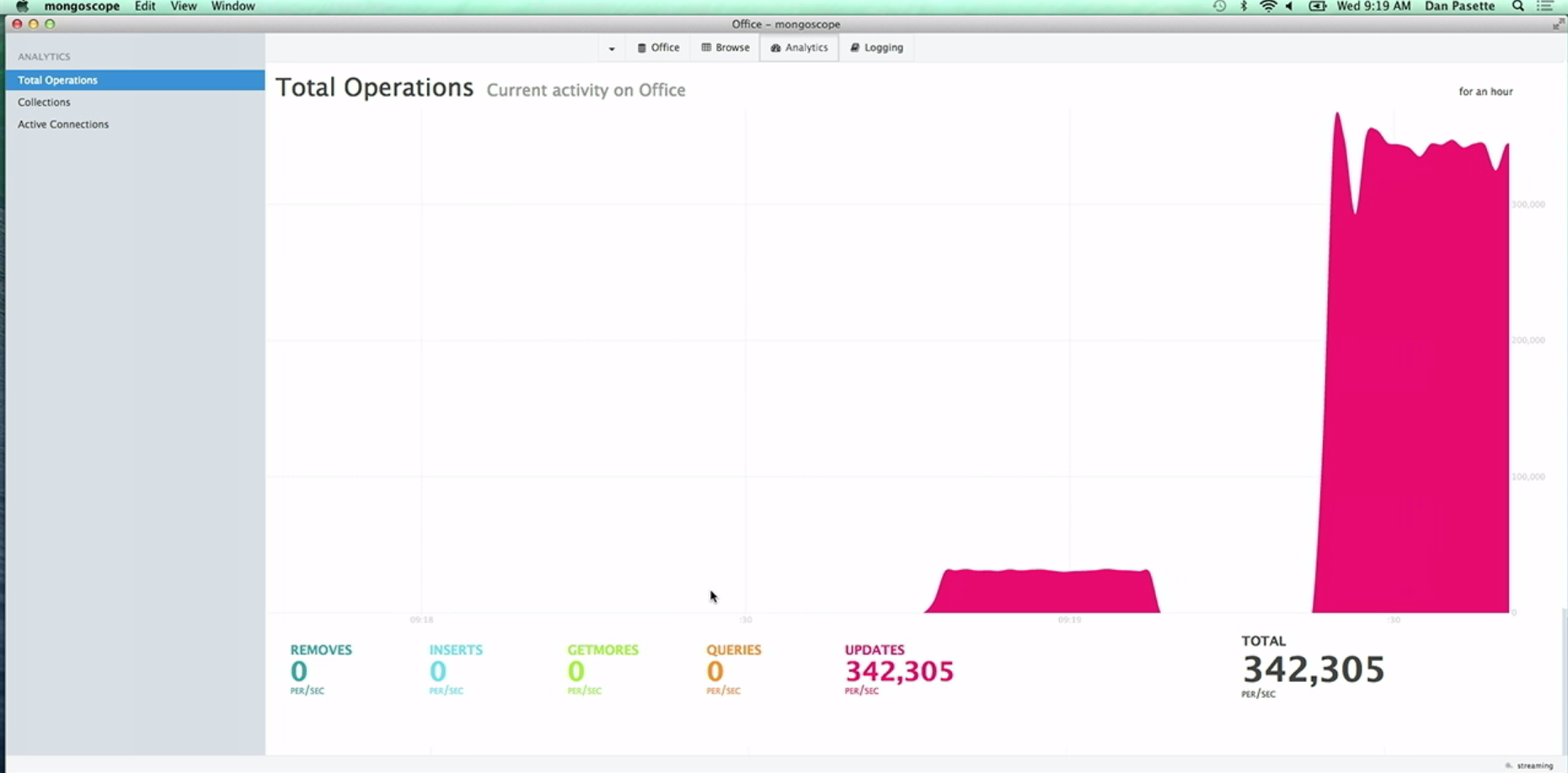
mongod with the useExperimantalDocLocking=true . The growth rate of updates demonstrated at the presentation is staggering: it increased about 10 times from 30,000 per / sec to 340,000 per / sec!Arbitrary data storage
Let's try to answer one simple question: which data storage engine is best for the future of MongoDB? Focused on reading speed? Write speed? Security? The guys from MongoDB chose not to bother with the answer. They decided that none of the engines can be considered optimal for all needs at once. And you really can't argue with that. In general, they developed a replaceable API for an arbitrary storage engine.
There are quite a few requirements for this API, since it should support all existing MongoDB features, support operational scalability, add one or more nodes to the cluster, and more.
As a result, we will get the ability to connect replaceable storage, which will be optimized for specific needs: performance, data compression, etc.
Estimated storage types:
- In-Memory
- RocksDB (from Facebook, sharpened for compression)
- InnoDB (from MySQL)
- TokuKV
- FusionIO (works around the file system, sharpened for low latency)
In-Memory and RocksDB are already available in the developer branch on github. Again, do not rush to use it on combat servers.
Automation
As you know, MongoDB is able to replicate out of the box and shard. As a result, we get not one copy of the database, but several at once. In truly large projects such nodes can be very much. And the problem lies not only in the deployment of all these nodes, but also in their further updating, backup, monitoring and much more.
Mongo Management Service (MMS) will now do this routine for us.
MMS is a friendly web-based interface that allows you to solve a whole range of tasks in just a couple of mouse clicks:
- One-click deployment (coming soon)
- Instant update coming (coming soon)
- Continuous (logging) and incremental backup
- Rollback to any state
- Monitoring 100+ system metrics
- Customizable notifications
And for a snack: MMS will teach you to integrate with Amazon EC2 .
What's next?
I really like the fact that the MongoDB team pays a lot of attention to making their product comfortable and useful for developers. And they do it not in a spherical vacuum, but actively taking an interest in the opinion directly from the community . Therefore, I am confident that MongoDB will continue to maintain an excellent pace of introducing new features, improve security, automate and make the whole routine even more invisible.
Source: https://habr.com/ru/post/227921/
All Articles