Why should a cat tail: realtime statistics in conditions of medium visibility
My name is Igor, a year and a half ago I started working in the Mail.ru Rating project, and a year later I began to use real-time statistics as part of this project. Today I will talk in a little more detail about how our statistics work. If you suddenly do not know, the Mail.ru Rating counter is set to approximately 20% of all websites of the RuNet. We process and show statistics on the dynamics of visits, statistics on users (demographics: gender, age), and many, many other reports, including page load time. Realtime statistics is a more dynamic statistics, which shows the number of users right now on the site, which site pages are popular right now, with approximately 1-second delay.
Dashboard that brings all realtime reports together looks like this:
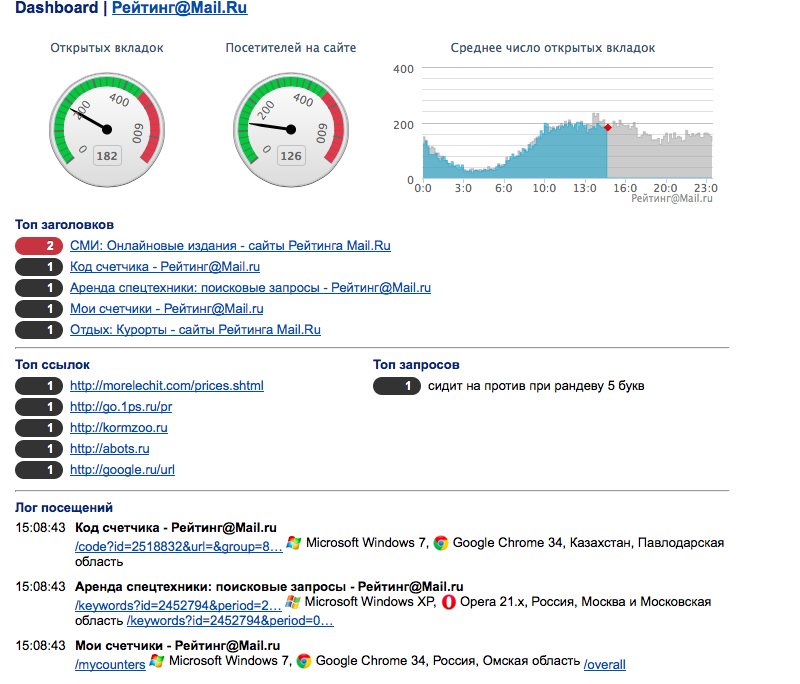
He shows:
Of course, individual reports are also available. I do not want to engage in tautology, in more detail you can read about each report in our corporate blog .
')
Recently, I finished working on this project, and I want to share some of the patterns that I found interesting.
Ten thousand lines of code, four months of work and zilch at the exit. The richness of the functionality is not much more complicated than the CD Ejector. Religious fanatical “Not invented here” leads to a lot of development time and unsupported code.
Now I am committed to draining into my piggy bank carefully crafted libraries with an elegant API written by professionals. This, for example, BOOST, Intel Threading Building Blocks, Google Protobuf. I'm not quite sure what the antipattern name “Not Inveted Here” is called, but personally I tend to “No man is an island”. In the current project, there is an order of magnitude more functionality than in my variation on “CD Ejector”. All this functionality breaks into two thousand lines of code, and was developed in the same 4 months. From the components I use the following:
I do not paint the architecture completely - it is a great pleasure to develop it, and I do not want to spoil the pleasure for those of us who will solve a similar task. But I want to share some technical solutions that I found useful.
One of the straightforward solutions is to iterate and delete expired records. There is a more elegant solution, when a record is added or updated, a record about the need to delete is added to concurrent_bounded_queue. And in a separate thread, a blocking pop is used, which returns a record if there is something to read. Since the timeout is constant, each next entry will be relevant later than the one that was returned. And, if the removal time has not yet come, it is enough to do sleep () until the moment when it is relevant. After that, it is enough to compare the expiration time and the last update time of the record, and if it has really expired (it has not been updated since the time the current deletion record was added), delete it. Cheap and angry.
Logging in the code looks like this:
This is how the message looks in the log:
It is implemented using a macro that places std :: string into the usual tbb :: concurrent_bounded_queue, from which, in one stream, messages are read and written to the log file.
Therefore, the only constructor parameter that LiveObject accepts is a reference to an object of the Context class. LiveObject is just a class object that has a run method; This method is performed in a separate thread. Usually one such object is responsible for one execution thread.
The solution is quite simple - use an atomic pointer to this table and replace it once per second. The problem is this: after serialization (which occurs quite quickly, 0.5-50ms), the old data structure is deleted. And if the stream that “enriches” the entries in the tail (geolocation by ip, mapping of OS, browsers), writes to the remote data structure, it will be bobo. Also known as SEGFAULT.
Record processing time is counted in microseconds. On a lightly loaded server, you should not expect the magic hang of streams a la Java “stop the world”. And if to add sleep before serialization the problem will be solved. An alternative may be one of the classic synchronization primitives, but it is not elegant and unnecessary.
The original lossy counting works as follows: there is a stream of elements. It is broken into buckets (in some descriptions the bucket is called a window). If there is already an element in the table with elements, its counter is incremented by 1. If there is no element and there is space in the table, the element is added and its counter is set to 1. At the end of the bake, one is subtracted from all counters. Items with counters reaching zero are removed. In the modified element for each element, the number of sessions is counted. When the number of sessions on an element drops to zero, it is deleted. When the “end of the window” comes, not one a is subtracted from the counters (which is of the float type) (1 - (the number of deleted elements for zero sessions) / window size).
Tops are becoming more dynamic, especially for sites with low traffic.
Register and enjoy life. Please note that on sites with a small number of visits, realtime statistics are not so interesting.
Dashboard that brings all realtime reports together looks like this:
He shows:
- number of visitors on the site;
- how many browser tabs are open;
- top pages;
- top links from which transitions are made;
- top queries from which come from search engines;
- and, of course, a log of visits.
Of course, individual reports are also available. I do not want to engage in tautology, in more detail you can read about each report in our corporate blog .
')
Recently, I finished working on this project, and I want to share some of the patterns that I found interesting.
Not Invented Here vs. No man is an island
I think the most important pattern I used is the reverse pattern to “Not Invented Here”. Ten years ago I studied at Baumansky (KF), and as one of my coursework I made a small application with five forms that counted word frequencies (well, of course, I tried to sell it as shareware). It is still available at archive.org . I was an apologist for the anti-pattern “Not Inveted Here” and did not believe in using other people's libraries. The program was written in “C with classes” and had its own OO library wrapping the Win32 API.Ten thousand lines of code, four months of work and zilch at the exit. The richness of the functionality is not much more complicated than the CD Ejector. Religious fanatical “Not invented here” leads to a lot of development time and unsupported code.
Now I am committed to draining into my piggy bank carefully crafted libraries with an elegant API written by professionals. This, for example, BOOST, Intel Threading Building Blocks, Google Protobuf. I'm not quite sure what the antipattern name “Not Inveted Here” is called, but personally I tend to “No man is an island”. In the current project, there is an order of magnitude more functionality than in my variation on “CD Ejector”. All this functionality breaks into two thousand lines of code, and was developed in the same 4 months. From the components I use the following:
- C ++ 11 is convenient and fast and half of BOOST is already there.
- Google TMalloc - we will do everything a little faster.
- Google Protobuf - serialization / deserialization for nothing, and let no one go offended.
- Intel TBB - one mutex is used throughout the realtime statistics daemon, everything else is done using TBB: concurrent_hash_table, concurrent_bounded_queue.
- BOOST - for everything that is not covered with C ++ 11.
- MongoDB - for state storage and messaging. Capped collections + tailable cursors work just fine in this role, although I would prefer TibcoRV's certified messaging, but this is definitely overkill. Macros for working with BSON are very convenient.
I do not paint the architecture completely - it is a great pleasure to develop it, and I do not want to spoil the pleasure for those of us who will solve a similar task. But I want to share some technical solutions that I found useful.
Bookkeeping
If somewhere something was added, somewhere something should decrease. All users and sessions should be stored somewhere (and they are stored by the counters). After some time, the session expires and the record should be deleted.One of the straightforward solutions is to iterate and delete expired records. There is a more elegant solution, when a record is added or updated, a record about the need to delete is added to concurrent_bounded_queue. And in a separate thread, a blocking pop is used, which returns a record if there is something to read. Since the timeout is constant, each next entry will be relevant later than the one that was returned. And, if the removal time has not yet come, it is enough to do sleep () until the moment when it is relevant. After that, it is enough to compare the expiration time and the last update time of the record, and if it has really expired (it has not been updated since the time the current deletion record was added), delete it. Cheap and angry.
Asynchronous logging
Some logging libraries do not work asynchronously well and write to multiple threads in one file. Well, and do not forget that the log file for log rotation should be rediscovered by SIGHUP. I allowed myself to spend half an hour to make logging more elegant.Logging in the code looks like this:
LOG("All msgs: " << sum);This is how the message looks in the log:
2014-05-15 18:57:17 INFO void QueueCounter::run(): All msgs: 38288It is implemented using a macro that places std :: string into the usual tbb :: concurrent_bounded_queue, from which, in one stream, messages are read and written to the log file.
Context
If you think, concurrent_bounded_queue is nothing but a message queue. And it is logical to have a message broker who knows about all the message queues. It would be called MessageBroker. But then I would not be able to add to it other services necessary for many components (for example, logging and configurations) and call it Context.Therefore, the only constructor parameter that LiveObject accepts is a reference to an object of the Context class. LiveObject is just a class object that has a run method; This method is performed in a separate thread. Usually one such object is responsible for one execution thread.
Synchronization with sleep
“Visits log” (analogue of tail) is written in concurrent_hash_table. It is written in 1 second buckets. The key is the counter id. Small problem: tbb :: concurrent_hash_table cannot be bypassed if it uses non-POD structures.The solution is quite simple - use an atomic pointer to this table and replace it once per second. The problem is this: after serialization (which occurs quite quickly, 0.5-50ms), the old data structure is deleted. And if the stream that “enriches” the entries in the tail (geolocation by ip, mapping of OS, browsers), writes to the remote data structure, it will be bobo. Also known as SEGFAULT.
Record processing time is counted in microseconds. On a lightly loaded server, you should not expect the magic hang of streams a la Java “stop the world”. And if to add sleep before serialization the problem will be solved. An alternative may be one of the classic synchronization primitives, but it is not elegant and unnecessary.
Counting tops
To count the tops (top keywords, top pages, and so on), slightly modified lossy counting is used.The original lossy counting works as follows: there is a stream of elements. It is broken into buckets (in some descriptions the bucket is called a window). If there is already an element in the table with elements, its counter is incremented by 1. If there is no element and there is space in the table, the element is added and its counter is set to 1. At the end of the bake, one is subtracted from all counters. Items with counters reaching zero are removed. In the modified element for each element, the number of sessions is counted. When the number of sessions on an element drops to zero, it is deleted. When the “end of the window” comes, not one a is subtracted from the counters (which is of the float type) (1 - (the number of deleted elements for zero sessions) / window size).
Tops are becoming more dynamic, especially for sites with low traffic.
Why should a cat tail
Why does the cat need a tail, I do not know, but I guess. As for the realtime statistics, everything is simpler with it - it turned out to be quite popular. And we decided to make from one of the most popular reports an informer that can be installed on the site. For the sites visited, it looks very interesting, displaying the most popular pages on the site and the number of people who are looking at them right now .Register and enjoy life. Please note that on sites with a small number of visits, realtime statistics are not so interesting.
Source: https://habr.com/ru/post/227429/
All Articles