3D models of human viruses. Part Two: Molecular Modeling and Bioinformatics
In our first post about three-dimensional modeling of viruses, we listed the main stages of the process and talked about where we start and how we collect the initial information. In this article we will talk about the next stage of work - about creating models of individual molecules, from which a whole particle will be collected later.

Components of influenza A / H1N1 virus particle
A virus particle is a molecular mechanism that solves two fundamental problems. First, the particle must ensure the packaging of the viral genome and its protection from destructive environmental factors while the virus travels from the cell in which it is assembled, to the cell that it can infect. Secondly, the particle must be able to join the infected cell, and then deliver the viral genome and the accompanying molecules inwards to trigger a new breeding cycle. There are not so many tasks, so viruses, with rare exceptions, can afford to be quite economical in terms of structure.
')
In particular, the genome of most viruses is small and does not encode very many proteins, often this number is less than 10. At the same time, the virus can cause the cell to synthesize a large number of proteins of the same type, from which the viral envelope, the capsid, will then assemble. Thus, viral particles usually consist of a large number of identical elements that are associated with each other as designer details, often forming regular and symmetrical structures. So, many, although not all viral packages or their fragments have a spiral or icosahedral form.

Examples of viral capsid with icosahedral symmetry. Bactriorodopsin molecule in the lower right corner - for comparison. ( Illustration from review ).
To assemble a virus model, it is crucially important to know how the individual proteins of the general structure are arranged and how they bind to each other, forming this structure. Modern science has a whole set of methods that can provide answers to these questions, however, none of the approaches, unfortunately, is not universal and only solves some of the tasks that we face when creating scientifically reliable models of viruses with atomic detail.
Recall that proteins are polymeric molecules consisting of sequentially linked monomers - amino acids. In aqueous solutions, proteins usually fold into complex three-dimensional globules (almost like the Rubik's Snake puzzle), the shape of which depends on the amino acid composition and some other factors. The spatial structure of these globules is determined mainly by X-ray diffraction and NMR spectroscopy. Also recently, electron microscopy allows us to approach this task.
In general, the methods for determining the spatial structure of molecules are complex and have a whole set of limitations, therefore not all viral proteins are described in full. Thus, X-ray diffraction analysis suggests the presence of a crystal through which x-rays are transmitted. The atoms of the crystal provoke X-ray diffraction, from the picture of which it is possible to estimate the distribution of electron densities in the crystal, and from these data it is already possible to restore the positions of specific atoms. This method gives resolution up to just over 1 angstrom (0.1 nm), but in the case of proteins, the problem is that not all of them can be crystallized. This is especially difficult if the protein has flexible motile or anchored fragments in the membrane.
NMR spectroscopy is based on the phenomenon of nuclear magnetic resonance and allows you to describe the structure of proteins in solution. This approach reveals a set of possible positions of atoms in a molecule and, unlike the previous method, makes it possible to assess the degree of flexibility of one or another of its sections. But NMR spectroscopy works well only for relatively small molecules, because large proteins make too much noise.
Electron microscopy allows you to describe the structure of large molecular complexes, which is very useful when it comes to viruses. For many symmetric structures, you can get a large set of images from different angles, after analyzing which you can recreate a three-dimensional picture. For individual objects, the resolution obtained as a result of using different variants of electron microscopy (up to 4-5 angstroms) is not much worse than the resolution of X-ray diffraction analysis, although usually for obtaining complete information it is necessary to combine different approaches and, for example, “enter” the structures of individual proteins in electron density maps obtained by electron microscopy.

Trimer structures of the HIV envelope protein (red and blue fragments of molecules) in complex with a region of one of the antibodies to this protein (green and yellow fragments), inscribed in an electron density map obtained by cryo-electron microscopy with a resolution of 9 angstroms. From the article Structural Mechanism of Trimeric HIV-1 Envelope Glycoprotein Activation .
As we wrote in the last post, the resulting structures are organized and stored in the Protein Data Bank database. At the same time, atomic coordinates are recorded in the * .pdb format, and there is a whole set of programs that allow this data to be visualized and worked with such structures. Among them, for example, VMD , Chimera , PyMol and dozens of others .
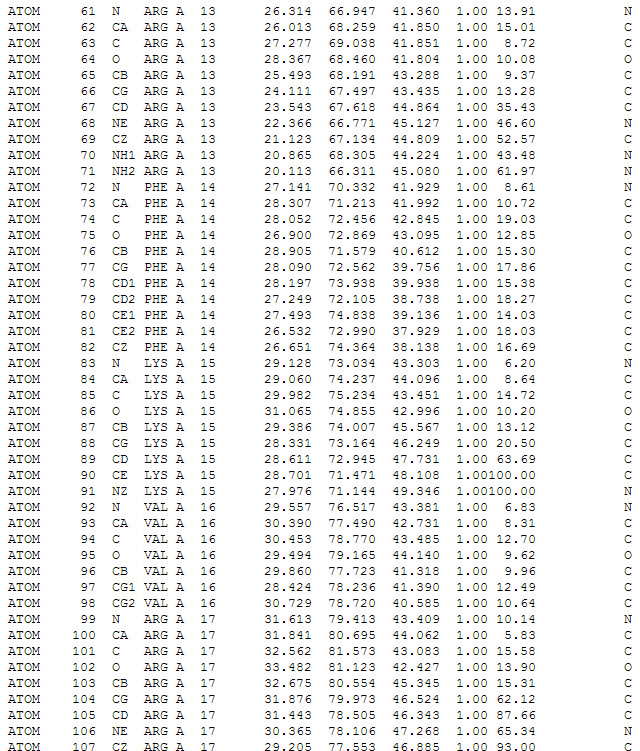
Screenshot of text file display in * .pdb format. Coordinates of individual atoms in protein amino acids are described.
Programs can display proteins in several ways. In addition to simply displaying atoms with spheres of different diameters, corresponding to the van der Waals radii of atoms, there is an opportunity to show individual bonds, the surface of the molecule, and also the bends of the amino acid chain using ribbon-like structures ( ribbon diagram ), which clearly demonstrate where form alpha-helix , where the beta layers , and where unstructured areas.

Various options for visualizing the structure of the outer part of the hemagglutinin of the influenza virus in the Chimera program.
As a digression, I must say that the programs in which scientists usually work by visualizing individual molecules or protein complexes most often allow you to get only quite primitive from an aesthetic point of view results (for example, look at some screenshots from the VMD program ). Fundamentally more opportunities open up if you import molecule models into programs that professional designers and computer-generated three-dimensional graphics use. These programs in combination with the plug-ins that improve the quality of the render, allow you to get really interesting and attractive visualization. We will tell about it in the next posts. For now, just give an example:

Images of immunoglobulin G molecule .
Missing protein structures can be tried to predict what we have to do in order to create complete models of viral particles. For this, a number of computer methods are used, based in part on data on the structures already described, and in part on algorithms that allow calculating interactions between individual atoms of the molecule with a certain reliability. Modeling based on already known structures is used, since modern computing powers do not yet allow building spatial models of proteins solely by the sequence of amino acids, based on quantum mechanical principles. Plus, it is believed that at the present time, the folding of such a multitude of proteins has already been determined, that almost every new protein structure already has an analogue in the PDB bank, the main thing is to find it.
It is known that proteins, in which more than 30% of amino acid residues are the same, have very similar structures. We can find a protein with a similar amino acid sequence and already known structure, and use it as a template for building a model - this is called homology modeling. A BLAST program is usually used to search for a similar sequence.
However, some proteins with similar structures have approximately the same sequence similarity as a pair of randomly selected proteins. In order to find a suitable template in such cases, use the methods of Fold recognition. They “pull” the sequence of the protein being modeled onto various known structures, and evaluate how this pattern suits them. Different programs use different evaluation functions, and therefore give different results. There is no single and optimal algorithm for Fold recognition, usually several programs are used at once and select a template based on all their results. For example, you can take as a template a protein that has a similar function.
There are methods that allow you to build a model using several templates at once, combining them in an optimal way. The best of them is called I-Tasser. It was not the creators of the program who declared it to be the best - for several years in a row I-Tasser, under the name “ Zhang-server ”, has won the competition for the prediction of CASP protein structures .
For example, when working with the influenza virus model, we were faced with the fact that one of the surface proteins, neuraminidase, was experimentally determined only that part of the structure that directly performs an enzymatic function (splitting sialic acid as part of cellular membrane glycoproteins). The parts of the molecule that form the “stalk” of the protein and anchor the neuraminidase in the lipid envelope of the virus had to be simulated by homology. The patterns of the hemagglutinin neuraminidase of the parainfluenza virus ( 3TSI ) and one of the transmembrane peptides ( 2LAT ) were taken as templates.

Templates for modeling the neuraminidase complex of influenza virus. A - a fragment of the neuraminidase N2 monomer from the 2AEP structure in the PDB database, B - the “stem” of the hemagglutinin-neuraminidase parainfluenza (3TSI), C is the transmembrane peptide 2LAT. D - the final model obtained.
The final protein model is usually created taking into account the known structures of its fragments, found by various template methods, as well as models from the I-Tasser server. For this program Modeller is used . It allows you to build a model on homology using one or more templates, as well as make additional modifications, for example, to create disulfide bonds in given places.
Another important aspect of the structure of viruses, information about which is often incomplete in the scientific literature, is the interaction between individual proteins. In our case, it depends on what surfaces the models of individual proteins will contact with each other and other components of the virion in the final model. Information on interactions also allows you to specify the structural bioinformatics.
The docking program does not model the natural process of complex formation, it would be too slow and resource-intensive, but goes through options for the relative position of two or more molecules in search of the best structure. In docking, usually a large molecule in the complex is called a receptor, and a smaller one is called a ligand. Various evaluation functions are used to determine the quality of the structure of the ligand complex with the receptor. Ideally, the free energy of the system should act as such a function, but it is too difficult to calculate, therefore, different empirical pseudopotentials are used that take into account potential energy (which is just calculated), the contact area of the ligand and the receptor, and the different rules that the researchers derived from the analysis a large number of complexes, and any mysterious components that have no physical meaning, but improve the result of the program when tested on a large number of known complexes. The search for a minimum of such a pseudopotential in modern programs usually occurs with the help of various variations of the Monte Carlo method and genetic algorithms. Currently, there are many molecular docking programs (the most famous of them are Dock , Autodock , GOLD , Flexx , Glide ), which are distinguished by evaluation functions, minimization methods and additional features. At the same time, during the search, the receptor and ligand molecules can either remain stationary (this type of docking is called hard), and also slightly change the conformation (flexible docking). Obviously, the second option is more resource-intensive, but the results of such a search are usually more plausible. Docking of small molecules to proteins is now a standard stage in the development of new drugs. You can, for example, carry out docking for 10 million ligands, and select the hundreds of the most promising compounds for further experimental work — this is called virtual screening.
In addition to studies of small molecules, docking can also be used to build protein-protein and protein-nucleotide complexes. For these purposes, a large number of programs and online services have also been developed ( ZDOCK , pyDOCK , HEX ). For example, during our work on the human papillomavirus (HPV), we were faced with the fact that, despite the complete structure of the outer capsid layer formed by the L1 protein, there was absolutely no information about the structure of the L2 protein, which is closer to the genome in the capsid, accordingly, there is no evidence of how L1 pentamers interact with L2 molecules. We built the L2 protein model by homology using the Tasser server, and then we docked in the HeX program. During docking, the pentamer L1 served as the receptor. It was on its surface that the search for an optimal L2 landing site was carried out. At the same time, all structures remained stationary. Those. hard docking method was used. As a result, a plausible structure of the pentamer complex, assembled from L1 and the minor L2 protein, was obtained.
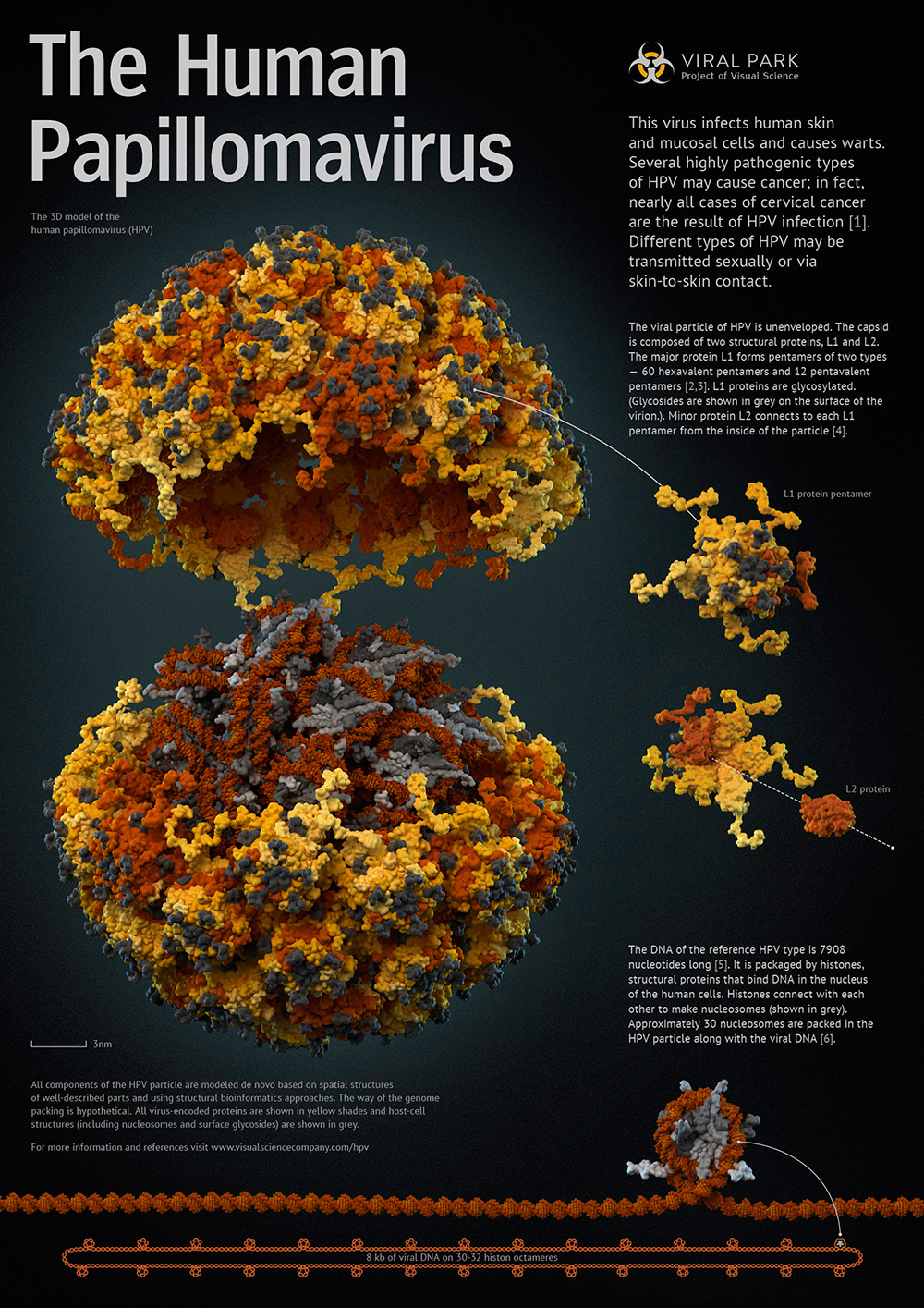
The pentamer of the main capsid protein L1 in combination with the minor protein L2 (shown on the poster to the right of the viral particle). View from below (disassembled) and view from above. Structures obtained by a combination of methods for modeling homology and docking.
Finally, using bioinformatics methods, one can try to reconstruct what changes the structure of viral proteins is made by the cell in which they are formed. Most of the proteins after synthesis undergo additional chemical posttranslational modifications (PTM), which can seriously affect the functions performed by the protein. Among such modifications are phosphorylation, ubiquitination, glycosylation, nitrosylation, insertion breaks and other chemical changes. Many surface proteins of viruses are glycosylated, and this modification is of direct importance for performing the main function of the surface proteins of the virus - binding to cell receptors. On the other hand, proteins of viral matrices - layers that are found directly under the lipid membranes of certain viruses, must often be associated, for example, with myristic acid, a small hydrophobic molecule that facilitates the interaction of proteins with lipids. Thus, in our work, protein modifications also require attention.
At present, possible PTM are rather difficult to predict. The main existing methods and services are based on the search for relevant experimental information for similar proteins or the search in the sequence of the studied protein for small areas characteristic of a particular type of modification.
In our work in the preparation of models, we use the experimental information reflected in the corresponding record of the UNIPROT database.
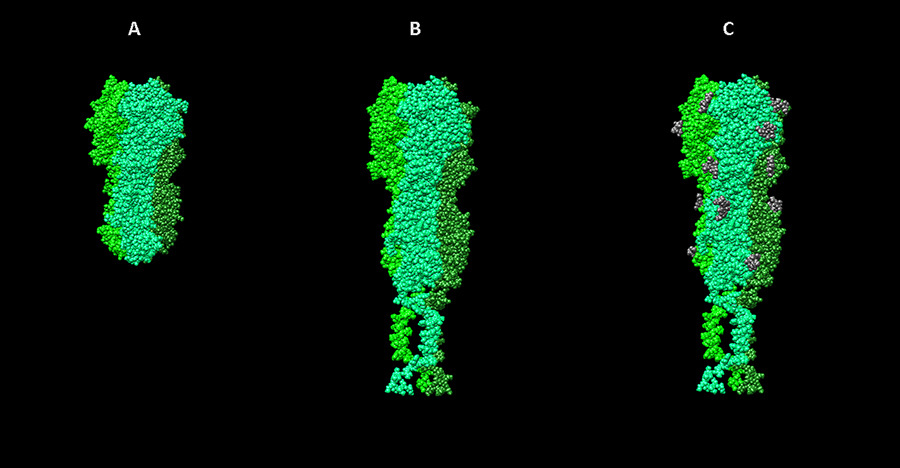
Stages of work on the hemagglutinin model of influenza virus. A - visualization of the 3ZTJ structure from the PDB database. B - hemagglutinin model of the H1N1 influenza virus, built on the basis of homology with 3ZTJ with the extension of transmembrane parts of the molecule. C - model with posttranslational modifications (glycosylation).
The last thing I want to mention is that when preparing new models of proteins and, especially, their complexes, it is necessary to optimize the structures. The simplest optimization method is energy minimization. It is used for sufficiently quick “descent” of the system to the local minimum of potential energy. This manipulation is preferably carried out after each modification of the structure of molecules. It avoids such troubles as overlapping atoms or the appearance of irregular bond lengths. Various energy minimization methods are provided in almost any molecular modeling software package.
It should be noted that this method allows only preliminary and very rough optimization. For more accurate preparation of spatial structures, the methods of molecular dynamics or quantum mechanics are used. The latter, for example, are used for the best optimization of the structure of small ligand molecules and the most accurate calculations of the energy of intermolecular interactions. But, the greatest accuracy, which is quite logical, is associated with more resource-intensive calculations, which makes these methods practically unaffordable for large biological macromolecules.
Molecular dynamics methods can be used to evaluate the behavior and stability of structures of rather massive molecules, such as polypeptides and nucleic acids.
The method of molecular dynamics consists in studying the behavior of atoms and molecules and their movements in time. Calculations of molecular dynamics make it possible, for example, to investigate the stability of both individual molecules and their complexes, allow us to estimate the significance of possible conformational rearrangements, the effect of point mutations, and much more. Modern methods of analyzing the results of molecular dynamics simulations provide the most detailed information about the behavior in time of both individual atoms and the entire system under study.
Depending on how well the proteins of that virus are studied, the model of which we want to create, each time it is necessary to select approaches for completing and optimizing the models of all proteins and their interactions. After all the structures are obtained, you can proceed to the assembly of the full model. How this is done, we will describe in the next posts of the series about the creation of scientifically reliable models of human viruses.
PS:
The subject of Medical Anatomical Illustration, which has become a leader in the survey of the last post, is the history of studying the human body in the works of 5 centuries illustrators . With stunning prints, wax models of the last century, plasticities of corpses, atlases, outstanding researchers, 3D reconstructions based on layered sections of frozen suicide bombers, interactive applications and works of modern medical illustrators. Soon.
Components of influenza A / H1N1 virus particle
A virus particle is a molecular mechanism that solves two fundamental problems. First, the particle must ensure the packaging of the viral genome and its protection from destructive environmental factors while the virus travels from the cell in which it is assembled, to the cell that it can infect. Secondly, the particle must be able to join the infected cell, and then deliver the viral genome and the accompanying molecules inwards to trigger a new breeding cycle. There are not so many tasks, so viruses, with rare exceptions, can afford to be quite economical in terms of structure.
')
In particular, the genome of most viruses is small and does not encode very many proteins, often this number is less than 10. At the same time, the virus can cause the cell to synthesize a large number of proteins of the same type, from which the viral envelope, the capsid, will then assemble. Thus, viral particles usually consist of a large number of identical elements that are associated with each other as designer details, often forming regular and symmetrical structures. So, many, although not all viral packages or their fragments have a spiral or icosahedral form.
Examples of viral capsid with icosahedral symmetry. Bactriorodopsin molecule in the lower right corner - for comparison. ( Illustration from review ).
To assemble a virus model, it is crucially important to know how the individual proteins of the general structure are arranged and how they bind to each other, forming this structure. Modern science has a whole set of methods that can provide answers to these questions, however, none of the approaches, unfortunately, is not universal and only solves some of the tasks that we face when creating scientifically reliable models of viruses with atomic detail.
Proteins: how to get, store and display information about their structure?
Recall that proteins are polymeric molecules consisting of sequentially linked monomers - amino acids. In aqueous solutions, proteins usually fold into complex three-dimensional globules (almost like the Rubik's Snake puzzle), the shape of which depends on the amino acid composition and some other factors. The spatial structure of these globules is determined mainly by X-ray diffraction and NMR spectroscopy. Also recently, electron microscopy allows us to approach this task.
In general, the methods for determining the spatial structure of molecules are complex and have a whole set of limitations, therefore not all viral proteins are described in full. Thus, X-ray diffraction analysis suggests the presence of a crystal through which x-rays are transmitted. The atoms of the crystal provoke X-ray diffraction, from the picture of which it is possible to estimate the distribution of electron densities in the crystal, and from these data it is already possible to restore the positions of specific atoms. This method gives resolution up to just over 1 angstrom (0.1 nm), but in the case of proteins, the problem is that not all of them can be crystallized. This is especially difficult if the protein has flexible motile or anchored fragments in the membrane.
NMR spectroscopy is based on the phenomenon of nuclear magnetic resonance and allows you to describe the structure of proteins in solution. This approach reveals a set of possible positions of atoms in a molecule and, unlike the previous method, makes it possible to assess the degree of flexibility of one or another of its sections. But NMR spectroscopy works well only for relatively small molecules, because large proteins make too much noise.
Electron microscopy allows you to describe the structure of large molecular complexes, which is very useful when it comes to viruses. For many symmetric structures, you can get a large set of images from different angles, after analyzing which you can recreate a three-dimensional picture. For individual objects, the resolution obtained as a result of using different variants of electron microscopy (up to 4-5 angstroms) is not much worse than the resolution of X-ray diffraction analysis, although usually for obtaining complete information it is necessary to combine different approaches and, for example, “enter” the structures of individual proteins in electron density maps obtained by electron microscopy.
Trimer structures of the HIV envelope protein (red and blue fragments of molecules) in complex with a region of one of the antibodies to this protein (green and yellow fragments), inscribed in an electron density map obtained by cryo-electron microscopy with a resolution of 9 angstroms. From the article Structural Mechanism of Trimeric HIV-1 Envelope Glycoprotein Activation .
As we wrote in the last post, the resulting structures are organized and stored in the Protein Data Bank database. At the same time, atomic coordinates are recorded in the * .pdb format, and there is a whole set of programs that allow this data to be visualized and worked with such structures. Among them, for example, VMD , Chimera , PyMol and dozens of others .
Screenshot of text file display in * .pdb format. Coordinates of individual atoms in protein amino acids are described.
Programs can display proteins in several ways. In addition to simply displaying atoms with spheres of different diameters, corresponding to the van der Waals radii of atoms, there is an opportunity to show individual bonds, the surface of the molecule, and also the bends of the amino acid chain using ribbon-like structures ( ribbon diagram ), which clearly demonstrate where form alpha-helix , where the beta layers , and where unstructured areas.
Various options for visualizing the structure of the outer part of the hemagglutinin of the influenza virus in the Chimera program.
As a digression, I must say that the programs in which scientists usually work by visualizing individual molecules or protein complexes most often allow you to get only quite primitive from an aesthetic point of view results (for example, look at some screenshots from the VMD program ). Fundamentally more opportunities open up if you import molecule models into programs that professional designers and computer-generated three-dimensional graphics use. These programs in combination with the plug-ins that improve the quality of the render, allow you to get really interesting and attractive visualization. We will tell about it in the next posts. For now, just give an example:
Images of immunoglobulin G molecule .
Molecular modeling
Missing protein structures can be tried to predict what we have to do in order to create complete models of viral particles. For this, a number of computer methods are used, based in part on data on the structures already described, and in part on algorithms that allow calculating interactions between individual atoms of the molecule with a certain reliability. Modeling based on already known structures is used, since modern computing powers do not yet allow building spatial models of proteins solely by the sequence of amino acids, based on quantum mechanical principles. Plus, it is believed that at the present time, the folding of such a multitude of proteins has already been determined, that almost every new protein structure already has an analogue in the PDB bank, the main thing is to find it.
It is known that proteins, in which more than 30% of amino acid residues are the same, have very similar structures. We can find a protein with a similar amino acid sequence and already known structure, and use it as a template for building a model - this is called homology modeling. A BLAST program is usually used to search for a similar sequence.
However, some proteins with similar structures have approximately the same sequence similarity as a pair of randomly selected proteins. In order to find a suitable template in such cases, use the methods of Fold recognition. They “pull” the sequence of the protein being modeled onto various known structures, and evaluate how this pattern suits them. Different programs use different evaluation functions, and therefore give different results. There is no single and optimal algorithm for Fold recognition, usually several programs are used at once and select a template based on all their results. For example, you can take as a template a protein that has a similar function.
There are methods that allow you to build a model using several templates at once, combining them in an optimal way. The best of them is called I-Tasser. It was not the creators of the program who declared it to be the best - for several years in a row I-Tasser, under the name “ Zhang-server ”, has won the competition for the prediction of CASP protein structures .
For example, when working with the influenza virus model, we were faced with the fact that one of the surface proteins, neuraminidase, was experimentally determined only that part of the structure that directly performs an enzymatic function (splitting sialic acid as part of cellular membrane glycoproteins). The parts of the molecule that form the “stalk” of the protein and anchor the neuraminidase in the lipid envelope of the virus had to be simulated by homology. The patterns of the hemagglutinin neuraminidase of the parainfluenza virus ( 3TSI ) and one of the transmembrane peptides ( 2LAT ) were taken as templates.
Templates for modeling the neuraminidase complex of influenza virus. A - a fragment of the neuraminidase N2 monomer from the 2AEP structure in the PDB database, B - the “stem” of the hemagglutinin-neuraminidase parainfluenza (3TSI), C is the transmembrane peptide 2LAT. D - the final model obtained.
The final protein model is usually created taking into account the known structures of its fragments, found by various template methods, as well as models from the I-Tasser server. For this program Modeller is used . It allows you to build a model on homology using one or more templates, as well as make additional modifications, for example, to create disulfide bonds in given places.
Docking
Another important aspect of the structure of viruses, information about which is often incomplete in the scientific literature, is the interaction between individual proteins. In our case, it depends on what surfaces the models of individual proteins will contact with each other and other components of the virion in the final model. Information on interactions also allows you to specify the structural bioinformatics.
The docking program does not model the natural process of complex formation, it would be too slow and resource-intensive, but goes through options for the relative position of two or more molecules in search of the best structure. In docking, usually a large molecule in the complex is called a receptor, and a smaller one is called a ligand. Various evaluation functions are used to determine the quality of the structure of the ligand complex with the receptor. Ideally, the free energy of the system should act as such a function, but it is too difficult to calculate, therefore, different empirical pseudopotentials are used that take into account potential energy (which is just calculated), the contact area of the ligand and the receptor, and the different rules that the researchers derived from the analysis a large number of complexes, and any mysterious components that have no physical meaning, but improve the result of the program when tested on a large number of known complexes. The search for a minimum of such a pseudopotential in modern programs usually occurs with the help of various variations of the Monte Carlo method and genetic algorithms. Currently, there are many molecular docking programs (the most famous of them are Dock , Autodock , GOLD , Flexx , Glide ), which are distinguished by evaluation functions, minimization methods and additional features. At the same time, during the search, the receptor and ligand molecules can either remain stationary (this type of docking is called hard), and also slightly change the conformation (flexible docking). Obviously, the second option is more resource-intensive, but the results of such a search are usually more plausible. Docking of small molecules to proteins is now a standard stage in the development of new drugs. You can, for example, carry out docking for 10 million ligands, and select the hundreds of the most promising compounds for further experimental work — this is called virtual screening.
In addition to studies of small molecules, docking can also be used to build protein-protein and protein-nucleotide complexes. For these purposes, a large number of programs and online services have also been developed ( ZDOCK , pyDOCK , HEX ). For example, during our work on the human papillomavirus (HPV), we were faced with the fact that, despite the complete structure of the outer capsid layer formed by the L1 protein, there was absolutely no information about the structure of the L2 protein, which is closer to the genome in the capsid, accordingly, there is no evidence of how L1 pentamers interact with L2 molecules. We built the L2 protein model by homology using the Tasser server, and then we docked in the HeX program. During docking, the pentamer L1 served as the receptor. It was on its surface that the search for an optimal L2 landing site was carried out. At the same time, all structures remained stationary. Those. hard docking method was used. As a result, a plausible structure of the pentamer complex, assembled from L1 and the minor L2 protein, was obtained.
The pentamer of the main capsid protein L1 in combination with the minor protein L2 (shown on the poster to the right of the viral particle). View from below (disassembled) and view from above. Structures obtained by a combination of methods for modeling homology and docking.
Post-translational modifications
Finally, using bioinformatics methods, one can try to reconstruct what changes the structure of viral proteins is made by the cell in which they are formed. Most of the proteins after synthesis undergo additional chemical posttranslational modifications (PTM), which can seriously affect the functions performed by the protein. Among such modifications are phosphorylation, ubiquitination, glycosylation, nitrosylation, insertion breaks and other chemical changes. Many surface proteins of viruses are glycosylated, and this modification is of direct importance for performing the main function of the surface proteins of the virus - binding to cell receptors. On the other hand, proteins of viral matrices - layers that are found directly under the lipid membranes of certain viruses, must often be associated, for example, with myristic acid, a small hydrophobic molecule that facilitates the interaction of proteins with lipids. Thus, in our work, protein modifications also require attention.
At present, possible PTM are rather difficult to predict. The main existing methods and services are based on the search for relevant experimental information for similar proteins or the search in the sequence of the studied protein for small areas characteristic of a particular type of modification.
In our work in the preparation of models, we use the experimental information reflected in the corresponding record of the UNIPROT database.
Stages of work on the hemagglutinin model of influenza virus. A - visualization of the 3ZTJ structure from the PDB database. B - hemagglutinin model of the H1N1 influenza virus, built on the basis of homology with 3ZTJ with the extension of transmembrane parts of the molecule. C - model with posttranslational modifications (glycosylation).
Molecular Dynamics and Structure Optimization
The last thing I want to mention is that when preparing new models of proteins and, especially, their complexes, it is necessary to optimize the structures. The simplest optimization method is energy minimization. It is used for sufficiently quick “descent” of the system to the local minimum of potential energy. This manipulation is preferably carried out after each modification of the structure of molecules. It avoids such troubles as overlapping atoms or the appearance of irregular bond lengths. Various energy minimization methods are provided in almost any molecular modeling software package.
It should be noted that this method allows only preliminary and very rough optimization. For more accurate preparation of spatial structures, the methods of molecular dynamics or quantum mechanics are used. The latter, for example, are used for the best optimization of the structure of small ligand molecules and the most accurate calculations of the energy of intermolecular interactions. But, the greatest accuracy, which is quite logical, is associated with more resource-intensive calculations, which makes these methods practically unaffordable for large biological macromolecules.
Molecular dynamics methods can be used to evaluate the behavior and stability of structures of rather massive molecules, such as polypeptides and nucleic acids.
The method of molecular dynamics consists in studying the behavior of atoms and molecules and their movements in time. Calculations of molecular dynamics make it possible, for example, to investigate the stability of both individual molecules and their complexes, allow us to estimate the significance of possible conformational rearrangements, the effect of point mutations, and much more. Modern methods of analyzing the results of molecular dynamics simulations provide the most detailed information about the behavior in time of both individual atoms and the entire system under study.
Depending on how well the proteins of that virus are studied, the model of which we want to create, each time it is necessary to select approaches for completing and optimizing the models of all proteins and their interactions. After all the structures are obtained, you can proceed to the assembly of the full model. How this is done, we will describe in the next posts of the series about the creation of scientifically reliable models of human viruses.
PS:
The subject of Medical Anatomical Illustration, which has become a leader in the survey of the last post, is the history of studying the human body in the works of 5 centuries illustrators . With stunning prints, wax models of the last century, plasticities of corpses, atlases, outstanding researchers, 3D reconstructions based on layered sections of frozen suicide bombers, interactive applications and works of modern medical illustrators. Soon.
Source: https://habr.com/ru/post/227371/
All Articles