GoogleDocs integration with Redmine

Introduction
If you are tied to the development, then one way or another faced with the bug-tracker systems. Nowadays, to do without them in the process of software development is not just difficult, but impossible. Naturally, it did not pass us by. In the company we use the Redmine system. Here is all we need:
- Tracking task status
- Grouping tasks in the tracker
- in-project discussion if necessary
- Record keeping (although the possibilities are very limited)
- Accounting time of employees and their activities
All this data is collected for a reason. Each of these components is somehow included in the company's internal metrics, which allow evaluating the efficiency of the production process and analyzing the weak points of the projects so as not to repeat mistakes and do better next time.
Task
Obviously, data collection should be done constantly, so that you can quickly respond to negative changes and try to direct efforts in the right direction. However, due to the large amount of data that you have to work with, manual processing becomes problematic. In addition, it is necessary to provide employees with access to such a document so that everyone can enter and assess the situation on the project independently.
')
The problem that follows from this problem is to automate the collection of data from the bug-tracker system into more convenient sources for reading and visualization.
Selection of solutions
The spreadsheet is ideally suited as a convenient source - the data in it can be well structured so that it is readable, and it is also possible to use the data array visualization functions (graphs, charts, etc.).
The set of GoogleDocs has spreadsheets with which you can work from anywhere in the world, if you have the Internet, as well as manage access rights to them. GoogleDocs also provides the ability to use GoogleScript service to process data both inside and outside the document. Access and management of external resources is carried out through the API of the corresponding service.
Redmine provides the ability to retrieve data using its API .
This combination is ideal because it solves the problem.
Where to begin?
First you need to connect from the table to the Redmine API. To do this, we perform a number of simple actions:
1. Create a new script inside our table (Tools -> Script Editor ...)

2. In the window that opens with the script, you need to remove the created function - we will write our own.
To begin, we need the following information: a link that is available Redmine and API-key. There should be no problems with the first one - if you use a bug tracker, then you know for sure what address the start page is available at (for example, we have redmine.greensight.ru ). The key is a little more complicated. You can get it by sending a request to the API. Open FireFox, and try, for example, to get a list of projects. To do this, in the address bar, enter <link to redmain> /projects.xml:

Enter the username and password of a user registered in the system. Next, in the developer’s panel, go to the “Network” tab in the “Request Headers” subsection. What is written in the “Authorization” field after the word “Basic” will be the key we need.

Now let's try to get the same using GoogleScript. We return to the script we created in the table and write the following code:
var baseUrl = "< Redmine>"; var key = "<API-key>"; function APIRequest (reqUrl) { var url = encodeURI(baseUrl + reqUrl); var payload = { 'Authorization' : 'Basic ' + key}; var opt = { 'method' : 'GET', 'headers' : payload, 'muteHttpExceptions' : true }; var response = UrlFetchApp.fetch(url, opt); return XmlService.parse(response.getContentText()).getRootElement(); } function getRedmineProjects () { var response = APIRequest ('projects.xml'); Logger.log(response); } Here it is necessary to replace <link in Redmine> and <API-key> with what you received above. Now a little more detail about what we have done.
The baseURL variable holds the link to the Redmine main page. It is needed so that in the future once again not to register it in the functions of calling API methods. Accordingly, the key variable is needed for Redmine to provide data in response to a request (you can read more about any article on Basic Authorization). The APIRequest function queries the Redmine and returns a response from it. opt is an object that stores API call parameters - the GET method, headers containing data about the user who makes the request, ignoring exceptions.
UrlFetchApp is a GoogleScript class that allows you to work with requests to external services. In this case, we use the fetch method, in which we pass the request and its parameters.
Redmine can return responses to requests in two different forms - xml and JSON. In this variant, I used the xml-representation of the response, so the XmlService.parse () is in the function to return the response to the request. The getRedmineProjects function gets a list of projects and displays them in the script execution log (to execute the script, select Run -> getRedmineProjects in the menu, and press Ctrl + Enter to view the results).
We collect data
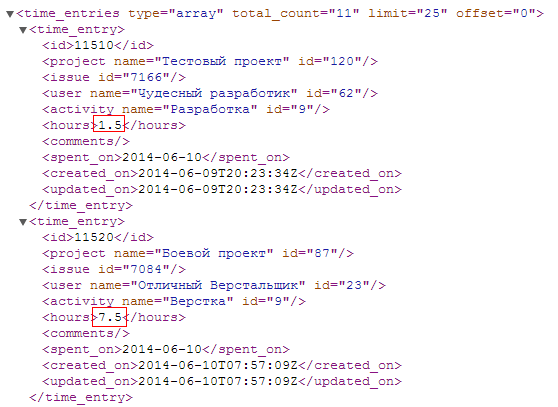
To collect data, it remains only to refer to the results of the APIRequest function and correctly retrieve data from them. I will show on the example of one xml-file how to take data. The collection mechanism for the rest is similar, and the list of available files is described in the link above. Let it be one of the metrics that will be useful to everyone - time written off (this metric is taken as an example to show how to get data, we have, of course, more complex metrics on projects). To do this, we will take data from the time_entries.xml file. They can be filtered by means of Redmine, for example, the parameter spent_on is responsible for the time written off on a certain date or period, and the project_id - on the time written off in a specific project (for a more detailed description, see the API documentation). Let's see what this file is:
<time_entries type="array" total_count="11" limit="25" offset="0"> <time_entry> <id>11510</id> <project name=" " id="150"/> <issue id="7666"/> <user name=" " id="62"/> <activity name="" id="9"/> <hours>1.5</hours> <comments/> <spent_on>2014-06-10</spent_on> <created_on>2014-06-09T20:23:34Z</created_on> <updated_on>2014-06-09T20:23:34Z</updated_on> </time_entry> <time_entry> <id>11520</id> <project name=" " id="87"/> <issue id="7484"/> <user name=" " id="23"/> <activity name="" id="9"/> <hours>7.5</hours> <comments/> <spent_on>2014-06-10</spent_on> <created_on>2014-06-10T07:57:09Z</created_on> <updated_on>2014-06-10T07:57:09Z</updated_on> </time_entry> The parent node shows the information that we also need when processing information: total_count - how many records were found for this request, limit - the number of records per page, offset - indent from the beginning of the list. The limit and offset parameters can also be adjusted in the request itself. For example, it is worth making limit more so that there are fewer requests when collecting data.
As we can see, the file has a very clear structure. We proceed to its processing. Suppose we need to write a function that collects all the time written off today on a specific project and calculate how much was spent on management and development:
function getTimes(id, params) { var time = new Array(); var offset = 0; do { var response = APIRequest ("time_entries.xml?project_id=" + id + "&spent_on=><" + params + "&offset="+offset + "&limit=100"); for (i=0; i<response.getChildren('time_entry').length; i++) { var obj = new Array(); obj.push(response.getChildren('time_entry')[i].getChild('activity').getAttribute('name').getValue()); obj.push(response.getChildren('time_entry')[i].getChild('hours').getText()); time.push(obj); } offset += 100; } while (response.getChildren('time_entry').length != 0); var manage = 0; var dev = 0; for (i=0; i<time.length; i++) { if (time[i][0] == '') { manage += +time[i][1]; } else { dev += +time[i][1]; } } return (manage/(manage+dev)); } Inside the loop, each time we retrieve information about the time written off in the project with id = id (you can see the project id also through the API request for projects.xml) spent during params. Each request to Redmine receives 100 records and, if that is not enough, we move to offset.
Next, in the loop, we execute response.getChildren ('time_entry') [i] .getChild ('activity'). GetAttribute ('name'). GetValue (). This command gets the name of the activity from each time logged entry:

Thus, we can get any name of the parameter of any nesting of any of the children of the root element of the xml-file.
To get the values themselves, use response.getChildren ('time_entry') [i] .getChild ('hours'). GetText (). By analogy with the command above, we get retired time:
Further actions of the function are aimed at calculating the management time and development time for the project.
Now we need only to organize the output of the calculated indicators. To do this, you need to write a small function that inserts the resulting value in the desired cells of our table:
function getAllTimes() { var value; SpreadsheetApp.getActive().setActiveSheet(SpreadsheetApp.getActive().getSheetByName('Project')); var data = SpreadsheetApp.getActive().getDataRange().getValues(); for (k=0; k<data.length; k++) { value = 0; if ((data[k][2].toLowerCase()=='')&&(data[k][1].toString()!='')) { value = getTimes(data[k][1], data[3][9]); SpreadsheetApp.getActive().setActiveSelection("K" + (k+1)).setValue(value); } } } To understand this requires a little explanation. The list of projects we have is stored on a sheet called “Project”. There are metrics in different columns. The time interval for which the time is filtered is recorded in the same cell as well. The data variable reads all information from the table. The cycle then finds all projects in the “Active” status with the project id from Redmine present, calls the counting function of a specific metric for this project, and writes the result to the K column (in this case).
The only thing left now is to execute our script. To do this, select the menu item Run-> <function name>. You can also customize the execution of necessary functions from the document menu or by dynamic trigger for a periodic launch.
Here is such a way to automate the removal of metrics for the project. Using the capabilities of the Redmine API, you can automatically receive arbitrarily complex data and not waste time on manual calculations.
Rake
Naturally, in the process of performing the task, we had to face some unobvious problems. I will try to bring the main.
1. Restriction on the output of the number of records on request - no more than 100 pieces. Even if you write in the request limit = 500, it will still output no more than 100.
2. In order to display tasks in all statuses, you need to add “status_id = *” to the request, otherwise, tasks in the “Closed”, “Canceled”, etc. status will not be included in the selection.
3. You can try to make a custom function and then insert it into the table cell just as we use any other formulas in the table (for example, “= gettimes (id, params)”). This method will fail with a large amount of data and instead of seeing the project data, you
will see in the cells error.
4. It is not recommended to output data through the Logger to the console. There is a similar problem with paragraph 3 - the script is not fully executed and, as a result, we have not a complete picture.
5. Watch the data that may emerge very carefully (mostly, this is in the user fields) - if it is absent, an attempt to read such a field or property in the record via getChild () will result in a null object and further work with it is impossible.
Source: https://habr.com/ru/post/227281/
All Articles