How the kernel manages memory
Earlier we saw how the virtual memory of the process is organized. Now consider the mechanisms by which the kernel manages memory. Refer to our program:
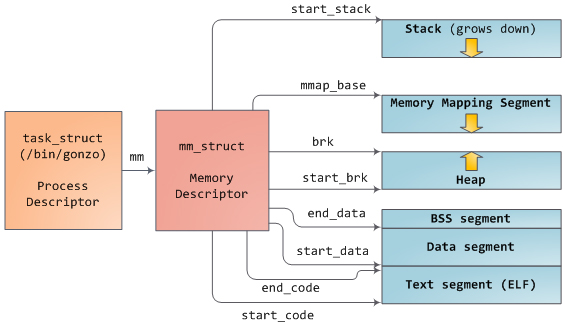
In Linux, processes are implemented as a task_struct struct object, which is essentially a process descriptor. The mm field of the task_struct object contains a pointer to a so-called. A “process memory handle” is a mm_struct struct object that contains comprehensive information about the memory usage of this process. The process memory descriptor stores information about the initial and final address of the process segments, as shown in the figure above, the number of page frames (physical pages in RAM) used by the process (this is RSS or the so-called “resident page set”), the number virtual memory allocated to the process, and another little thing. The process memory descriptor also indicates the location of the VMA (virtual memory area) descriptors and the set of page-tables for the process. The last two data structures are a kind of workhorse, since they are involved in most memory management operations. The virtual memory areas for our program are shown in the figure:
')

A virtual memory area (VMA) is a continuous range of virtual addresses; areas never overlap. An instance of the vm_area_struct struct object exhaustively describes one VMA, including the starting and ending virtual address of the area, flags, rights and other features of access to the area, the vm_file field with information about the file mapped to this area (if any). The area of virtual memory that is not associated with any file is called anonymous. Each of the program segments in the above figure (heap, stack, etc.) has its own VMA; The exception in this respect is only so-called. “Segment for mapping” (memory mapping segment). This state of affairs is not a requirement or something predetermined, but in the case of the x86 platform this is in most cases exactly the case. The virtual memory area does not care which segment to match.
The VMA set for this process is described in two ways at once. First, in the process memory descriptor (the mm_struct struct object) there is a mmap pointer to the VMA descriptors linked list (the order of the descriptors in the list corresponds to the order of the VMA in the virtual address space). Secondly, everything in the same memory descriptor has a mm_rb pointer to the structure, which is a red-black tree. An RB tree allows the kernel to quickly determine whether a virtual address is located within a particular virtual area. If you look at the contents of the / proc / pid_of_process / maps file in the proc file system, then it will be nothing more than information obtained by the kernel as a result of passing through the linked list of VMA descriptors.
In Windows, the EPROCESS block is, roughly speaking, something in between the task_struct and mm_struct structures. The analogue of the virtual memory area descriptor is the Virtual Address Descriptor or VAD. Information about VAD descriptors is stored in the AVL tree. Do you know what is funny when comparing Windows and Linux? This is the fact that there are not so many differences.
The 4-gigabyte virtual address space is represented as a series of pages. 32-bit x86 processors support page sizes of 4 KB, 2 MB, and 4 MB. Linux and Windows use 4-kilobyte pages for the user space-part of the virtual address space. Bytes 0-4095 fall into page # 0, bytes 4096-8191 fall into page # 1, etc. The size of the VMA must be a multiple of the page size. This is what a 3-gigabyte user space looks like, organized using 4-kilobyte pages:

The processor consults page-tables in order to convert a virtual address to a physical one. Each process has its own set of such page-tables; as soon as the process switch (context switch) occurs, the page tables for the user space-part of the virtual address space also change. In Linux, a pointer to the process page-table is stored in the pgd field of the process memory handle. Each virtual page corresponds to one entry in a page-table, and, in the case of a classic x86 paging, this is a simple 4-byte entry shown in the following figure:

In the Linux kernel, there are functions that allow you to score or reset any flag in the page table entry. The “P” flag indicates whether the page is in RAM or not. When this flag is set to 0, access to the corresponding page will cause page fault. It should be noted that if this flag is set to 0, then the kernel can use the remaining bits in the page table entry. The “R / W” flag means “write / read”; if the flag is not set, then only read access to the page is possible. The “U / S” flag means “user / supervisor”; if the flag is not set, only code running with privilege level 0 (i.e., the kernel) can access this page. Thus, these flags are used to implement the concept of an write-only address space and a space that is available only to the kernel.
Flags “D” and “A” mean “dirty” and “accessed”. The “dirty page” is the one that was recently written to, and the “accessed” page is the page that was accessed (read or written). Both flags are sticky, the processor can install them, but it will not reset them - the kernel must do this. Finally, the page table entry stores the initial physical address of the page in memory; The address will always be a multiple of 4K. This seemingly harmless field is the cause of many problems, since it actually limits the size of addressable physical memory to 4 gigabytes. Other fields page table entries look at some other time, as well as the Physical Address Extension mechanism.
Memory protection is carried out on a per page basis, since the page is the smallest "piece" of memory for which you can set the flags "U / S" and "R / W". However, it should be borne in mind that theoretically, two different virtual pages having a different set of flags can correspond to the same physical page. Note that in the page table format entries are not provided for flags related to the prohibition on code execution. In other words, the classic x86-paging does not prevent the execution of code in the stack. That is why it is possible to exploit vulnerabilities based on buffer overflow in the stack (non-executable stacks are still subject to vulnerabilities; in this case, use the return-to-libc technique and other techniques). The lack of a no-execute flag also indicates another important aspect: the access flags contained in the VMA descriptor do not always have direct matches in the protection system implemented by the processor, and correspond to this system only to a greater or lesser extent. Figuratively speaking, the kernel does everything in its power, but ultimately the processor architecture imposes its own limitations on what is possible to implement.
Of course, virtual memory itself does not store anything. Virtual address space is just an abstraction, but it is in a certain way matched to physical memory. The way the address bus of the processor works, generally speaking, the thing is quite non-trivial, but we can now abstract from it. We assume that the processor operates with a range of consecutive addresses from zero to the maximum address available in the system (depending on the amount of RAM) and can, if necessary, refer to any byte in this range. The physical address space is considered by the processor as a sequence of physical pages (they are also called page-frames). The processor has little to do with page frames, but for the kernel they are very important, since A page frame is a unit of accounting and management of physical memory, which is performed by the kernel. 32-bit versions of Linux and Windows use 4-kilobyte page frames; Here is an example of a machine with 2 GB of RAM:

The Linux kernel keeps track of each page frame using a special descriptor and several flags. Taken together, these descriptors describe all of the computer’s RAM; at each moment in time, the exact state of any page-frame is known. Physical memory management is based on the Buddy memory allocation algorithm. Thus, a page frame is considered free if it is available for selection from the point of view of the Buddy algorithm. Dedicated for using a page-frame can be “anonymous” (in this case it contains program data) or it can be located in a so-called. "Page cache" (page cache) and store a portion of the data from some file or block device. There are other, more exotic options for using page-frames, but let's not touch them now. Windows also has a similar structure for accounting for page-frames, and it is called the Page Frame Number database.
And now, let's put together all these concepts — virtual memory areas (VMA), page table entries and page frames — and see how it all works together. The following is an example of a heap in the user space of the program area:

Rectangles with a blue background represent virtual pages that are within the VMA. Arrows denote page table entries by which virtual pages are “mapped” into page frames (physical pages). Some virtual pages do not have arrows; This means that the presence flag is set to 0 in the corresponding page table entries. The reason for this may be that these virtual pages may or may not have been used up yet or because the corresponding physical pages were unloaded into a swap. In any case, an attempt to access these pages will result in a page fault, even though the virtual pages are within a certain VMA. It may seem strange that there is a similar misunderstanding - the pages within the VMA and yet access to them is invalid - but it really happens often.
VMA is a kind of “contract” between the program and the core. You ask the kernel to do something (for example, allocate memory or file the file), the kernel says “no problem” and creates a new one or updates an existing VMA. But the core is not in a hurry to perform these actions themselves; instead, it will postpone the immediate execution of the requested action until the page fault occurs. It turns out that the kernel is a sort of "lazy deceiver", and this is the fundamental principle of managing virtual memory. This principle applies in most situations - some of them may be quite familiar, some unexpected, but the general rule is that the VMA only records what was agreed on, while the page and table entries reflect what was directly done. lazy core. These two structures together participate in the program's memory management; both structures play a certain role in processing page fault, freeing memory, unloading pages into a swap, etc. Consider a simple case of memory allocation:

When a program requests the allocation of additional memory through the brk () system call, the kernel simply simply updates the information in the VMA descriptor and considers its task accomplished. At this time, neither new page frames are allocated, nor they are placed in RAM. However, as soon as the program tries to access the virtual page, the processor will catch the page fault and the do_page_fault () handler will be called. This function will search for the VMA, within which there is an address that the page fault caused. If such a VMA exists, then a check is made for consistency between the access rights to the VMA and the type of access to be made (read or write access). If there is no suitable VMA, then there is no “contract” that would provide for the possibility of accessing the memory. In the latter case, a Segmentation Fault signal is sent to the process, and it terminates.
Suppose VMA is still found. Further processing of the page fault is as follows - the kernel looks at the contents of the page table entry and the VMA type. In our example, the page table entry indicates that there is no page in memory. Moreover, our entry is completely empty (it consists of only zeros), and in Linux this means that the corresponding virtual page has never been tagged at all. Since we are dealing with an “anonymous” VMA, all further actions will be associated only with RAM, and the do_anonymous_page () function is called to handle this situation. This function selects the page frame and maps a virtual page into it by entering the necessary data into the page table entry.
The case could be otherwise. A page table entry for a swapped page, for example, has a presence flag set to 0, but the rest of the entry is non-empty. The remaining bits store information about whether the page is in a swap. The do_swap_page () function reads the contents of this page from disk and loads the page into RAM. This kind of page fault is called a major fault.
This concludes the first part of our excursion into how the kernel manages memory. In the next article we will complicate the picture by adding it to working with files — in this way we will get a more complete picture of the basic concepts of memory management, including some aspects of performance.
The material was prepared by employees of the company Smart-Soft. Translation of the article How the Kernel Manages Your Memory by Gustavo Duarte
smart-soft.ru
In Linux, processes are implemented as a task_struct struct object, which is essentially a process descriptor. The mm field of the task_struct object contains a pointer to a so-called. A “process memory handle” is a mm_struct struct object that contains comprehensive information about the memory usage of this process. The process memory descriptor stores information about the initial and final address of the process segments, as shown in the figure above, the number of page frames (physical pages in RAM) used by the process (this is RSS or the so-called “resident page set”), the number virtual memory allocated to the process, and another little thing. The process memory descriptor also indicates the location of the VMA (virtual memory area) descriptors and the set of page-tables for the process. The last two data structures are a kind of workhorse, since they are involved in most memory management operations. The virtual memory areas for our program are shown in the figure:
')
A virtual memory area (VMA) is a continuous range of virtual addresses; areas never overlap. An instance of the vm_area_struct struct object exhaustively describes one VMA, including the starting and ending virtual address of the area, flags, rights and other features of access to the area, the vm_file field with information about the file mapped to this area (if any). The area of virtual memory that is not associated with any file is called anonymous. Each of the program segments in the above figure (heap, stack, etc.) has its own VMA; The exception in this respect is only so-called. “Segment for mapping” (memory mapping segment). This state of affairs is not a requirement or something predetermined, but in the case of the x86 platform this is in most cases exactly the case. The virtual memory area does not care which segment to match.
The VMA set for this process is described in two ways at once. First, in the process memory descriptor (the mm_struct struct object) there is a mmap pointer to the VMA descriptors linked list (the order of the descriptors in the list corresponds to the order of the VMA in the virtual address space). Secondly, everything in the same memory descriptor has a mm_rb pointer to the structure, which is a red-black tree. An RB tree allows the kernel to quickly determine whether a virtual address is located within a particular virtual area. If you look at the contents of the / proc / pid_of_process / maps file in the proc file system, then it will be nothing more than information obtained by the kernel as a result of passing through the linked list of VMA descriptors.
In Windows, the EPROCESS block is, roughly speaking, something in between the task_struct and mm_struct structures. The analogue of the virtual memory area descriptor is the Virtual Address Descriptor or VAD. Information about VAD descriptors is stored in the AVL tree. Do you know what is funny when comparing Windows and Linux? This is the fact that there are not so many differences.
The 4-gigabyte virtual address space is represented as a series of pages. 32-bit x86 processors support page sizes of 4 KB, 2 MB, and 4 MB. Linux and Windows use 4-kilobyte pages for the user space-part of the virtual address space. Bytes 0-4095 fall into page # 0, bytes 4096-8191 fall into page # 1, etc. The size of the VMA must be a multiple of the page size. This is what a 3-gigabyte user space looks like, organized using 4-kilobyte pages:
The processor consults page-tables in order to convert a virtual address to a physical one. Each process has its own set of such page-tables; as soon as the process switch (context switch) occurs, the page tables for the user space-part of the virtual address space also change. In Linux, a pointer to the process page-table is stored in the pgd field of the process memory handle. Each virtual page corresponds to one entry in a page-table, and, in the case of a classic x86 paging, this is a simple 4-byte entry shown in the following figure:
In the Linux kernel, there are functions that allow you to score or reset any flag in the page table entry. The “P” flag indicates whether the page is in RAM or not. When this flag is set to 0, access to the corresponding page will cause page fault. It should be noted that if this flag is set to 0, then the kernel can use the remaining bits in the page table entry. The “R / W” flag means “write / read”; if the flag is not set, then only read access to the page is possible. The “U / S” flag means “user / supervisor”; if the flag is not set, only code running with privilege level 0 (i.e., the kernel) can access this page. Thus, these flags are used to implement the concept of an write-only address space and a space that is available only to the kernel.
Flags “D” and “A” mean “dirty” and “accessed”. The “dirty page” is the one that was recently written to, and the “accessed” page is the page that was accessed (read or written). Both flags are sticky, the processor can install them, but it will not reset them - the kernel must do this. Finally, the page table entry stores the initial physical address of the page in memory; The address will always be a multiple of 4K. This seemingly harmless field is the cause of many problems, since it actually limits the size of addressable physical memory to 4 gigabytes. Other fields page table entries look at some other time, as well as the Physical Address Extension mechanism.
Memory protection is carried out on a per page basis, since the page is the smallest "piece" of memory for which you can set the flags "U / S" and "R / W". However, it should be borne in mind that theoretically, two different virtual pages having a different set of flags can correspond to the same physical page. Note that in the page table format entries are not provided for flags related to the prohibition on code execution. In other words, the classic x86-paging does not prevent the execution of code in the stack. That is why it is possible to exploit vulnerabilities based on buffer overflow in the stack (non-executable stacks are still subject to vulnerabilities; in this case, use the return-to-libc technique and other techniques). The lack of a no-execute flag also indicates another important aspect: the access flags contained in the VMA descriptor do not always have direct matches in the protection system implemented by the processor, and correspond to this system only to a greater or lesser extent. Figuratively speaking, the kernel does everything in its power, but ultimately the processor architecture imposes its own limitations on what is possible to implement.
Of course, virtual memory itself does not store anything. Virtual address space is just an abstraction, but it is in a certain way matched to physical memory. The way the address bus of the processor works, generally speaking, the thing is quite non-trivial, but we can now abstract from it. We assume that the processor operates with a range of consecutive addresses from zero to the maximum address available in the system (depending on the amount of RAM) and can, if necessary, refer to any byte in this range. The physical address space is considered by the processor as a sequence of physical pages (they are also called page-frames). The processor has little to do with page frames, but for the kernel they are very important, since A page frame is a unit of accounting and management of physical memory, which is performed by the kernel. 32-bit versions of Linux and Windows use 4-kilobyte page frames; Here is an example of a machine with 2 GB of RAM:
The Linux kernel keeps track of each page frame using a special descriptor and several flags. Taken together, these descriptors describe all of the computer’s RAM; at each moment in time, the exact state of any page-frame is known. Physical memory management is based on the Buddy memory allocation algorithm. Thus, a page frame is considered free if it is available for selection from the point of view of the Buddy algorithm. Dedicated for using a page-frame can be “anonymous” (in this case it contains program data) or it can be located in a so-called. "Page cache" (page cache) and store a portion of the data from some file or block device. There are other, more exotic options for using page-frames, but let's not touch them now. Windows also has a similar structure for accounting for page-frames, and it is called the Page Frame Number database.
And now, let's put together all these concepts — virtual memory areas (VMA), page table entries and page frames — and see how it all works together. The following is an example of a heap in the user space of the program area:
Rectangles with a blue background represent virtual pages that are within the VMA. Arrows denote page table entries by which virtual pages are “mapped” into page frames (physical pages). Some virtual pages do not have arrows; This means that the presence flag is set to 0 in the corresponding page table entries. The reason for this may be that these virtual pages may or may not have been used up yet or because the corresponding physical pages were unloaded into a swap. In any case, an attempt to access these pages will result in a page fault, even though the virtual pages are within a certain VMA. It may seem strange that there is a similar misunderstanding - the pages within the VMA and yet access to them is invalid - but it really happens often.
VMA is a kind of “contract” between the program and the core. You ask the kernel to do something (for example, allocate memory or file the file), the kernel says “no problem” and creates a new one or updates an existing VMA. But the core is not in a hurry to perform these actions themselves; instead, it will postpone the immediate execution of the requested action until the page fault occurs. It turns out that the kernel is a sort of "lazy deceiver", and this is the fundamental principle of managing virtual memory. This principle applies in most situations - some of them may be quite familiar, some unexpected, but the general rule is that the VMA only records what was agreed on, while the page and table entries reflect what was directly done. lazy core. These two structures together participate in the program's memory management; both structures play a certain role in processing page fault, freeing memory, unloading pages into a swap, etc. Consider a simple case of memory allocation:
When a program requests the allocation of additional memory through the brk () system call, the kernel simply simply updates the information in the VMA descriptor and considers its task accomplished. At this time, neither new page frames are allocated, nor they are placed in RAM. However, as soon as the program tries to access the virtual page, the processor will catch the page fault and the do_page_fault () handler will be called. This function will search for the VMA, within which there is an address that the page fault caused. If such a VMA exists, then a check is made for consistency between the access rights to the VMA and the type of access to be made (read or write access). If there is no suitable VMA, then there is no “contract” that would provide for the possibility of accessing the memory. In the latter case, a Segmentation Fault signal is sent to the process, and it terminates.
Suppose VMA is still found. Further processing of the page fault is as follows - the kernel looks at the contents of the page table entry and the VMA type. In our example, the page table entry indicates that there is no page in memory. Moreover, our entry is completely empty (it consists of only zeros), and in Linux this means that the corresponding virtual page has never been tagged at all. Since we are dealing with an “anonymous” VMA, all further actions will be associated only with RAM, and the do_anonymous_page () function is called to handle this situation. This function selects the page frame and maps a virtual page into it by entering the necessary data into the page table entry.
The case could be otherwise. A page table entry for a swapped page, for example, has a presence flag set to 0, but the rest of the entry is non-empty. The remaining bits store information about whether the page is in a swap. The do_swap_page () function reads the contents of this page from disk and loads the page into RAM. This kind of page fault is called a major fault.
This concludes the first part of our excursion into how the kernel manages memory. In the next article we will complicate the picture by adding it to working with files — in this way we will get a more complete picture of the basic concepts of memory management, including some aspects of performance.
The material was prepared by employees of the company Smart-Soft. Translation of the article How the Kernel Manages Your Memory by Gustavo Duarte
smart-soft.ru
Source: https://habr.com/ru/post/226315/
All Articles