License plate recognition in detail

It is time to tell in detail how our implementation of the number recognition algorithm works: which turned out to be a good solution, which worked very badly. And just to report to Habra users - after all, with the help of Android application Recognitor, you helped us to dial a decently sized base of snapshots of rooms that were taken completely unbiased, without explaining how to shoot, and how not. A database of images in the development of recognition algorithms is the most important!
What happened with the Android application Recognitor
It was very nice that Habr's users took to download the application, try it and send us numbers.
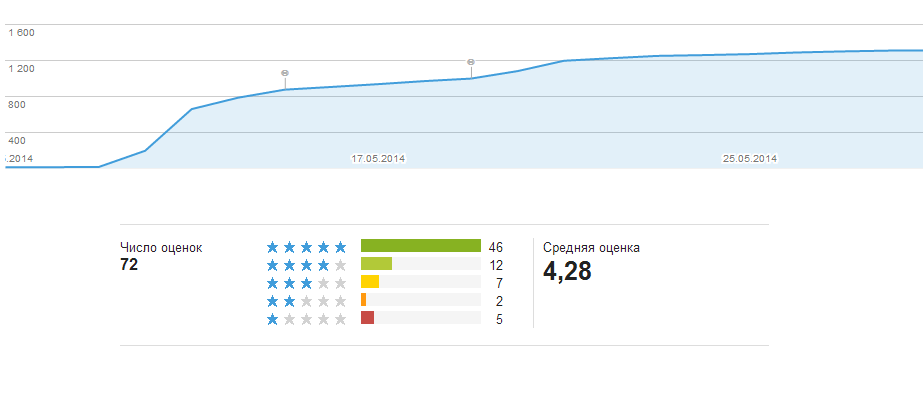
Program downloads and ratings
')
From the moment the application was laid out, 3800 snapshots of numbers from the mobile application came to the server.
And even more we were pleased with the link http://212.116.121.70:10000/uploadimage - in 2 days we were sent about 8 thousand full-size shots of license plates (mainly Vologda)! The server is almost lying.
Now we have a base of 12,000 photo shots in our hands - there is a huge work to debug algorithms ahead. All the fun is just beginning!
Let me remind you that in the Android application a number was previously allocated. In this article I will not elaborate on this stage. In our case, the cascade detector Haar . This detector does not always work if the number in the frame is strongly rotated. The analysis of how the trained cascade detector works with us, when it does not work, will be left to the following articles. This is really very interesting. It seems that this is a black box - the detector was trained and nothing more was done. In fact, it is not.
Still, the cascade detector is a good option in the case of limited computing resources. If the car number is dirty or the frame is poorly visible, then Haar also performs well with respect to other methods.
Number Recognition
Here is a story about text recognition in pictures of this type:

General approaches to recognition were described in the first article .
Initially, we set ourselves the task of recognizing dirty, partially erased, and coolly distorted perspective numbers.
Firstly, it is interesting, and secondly, it seemed that then the clean ones would work generally in 100% of cases. Usually, of course, that's what happens. But it did not work out. It turned out that if by dirty numbers the probability of success was 88%, then by pure, for example, 90%. Although in reality the probability of recognition from a photo on a mobile application before a successful answer, of course, turned out to be even worse than the indicated figure. Slightly less than 50% of the incoming images (so that people do not try to take pictures). Those. on average, you had to take a picture of the number twice in order to recognize it successfully. Although in many respects such a low percentage is due to the fact that many have tried to remove numbers from the monitor screen, and not in a real situation.
The whole algorithm was built for dirty numbers. But it turned out that now in the summer in Moscow, 9 out of 10 rooms are perfectly clean. So it is better to change the strategy and make two separate algorithms. If we were able to quickly and reliably recognize a clean number, then we will send this result to the user, and if we could not, we spend a little more processor time and run the second algorithm for dirty numbers.
A simple number recognition algorithm that would be implemented immediately
How to recognize a good and clean room? It is not difficult at all.
We have the following requirements for this algorithm:
1) some resistance to turning (± 10 degrees)
2) resistance to slight scaling (20%)
3) cutting off any boundaries of the number by the frame boundary or simply poorly pronounced boundaries should not destroy everything (this is fundamentally important, because in the case of dirty numbers you have to rely on the border of the number; if the number is clean, then nothing characterizes numbers / letters number).
So, in clean and well readable numbers all the numbers and letters are separable from each other, which means you can binarize the image and morphological methods or select related areas, or use the known functions of contour selection.
Binarize the frame
Here it is worthwhile to go through the mid-range filter and normalize the image.

The image is initially low-contrast frame for clarity.
Then binarize on a fixed threshold (you can fix the threshold, since the image was normalized).
Frame hypotheses
Suppose several possible rotation angles of the image. For example, +10, 0, -10 degrees:

In the future, the method will have a small resistance to the angle of rotation of numbers and letters, so such a large enough step in the angle is chosen - 10 degrees.
In the future, we will work with each frame independently. Whichever hypothesis will give the best result, she will win.
And then collect all related areas. Here we used the standard findContours function from OpenCV. If the connected area (contour) has a height in pixels from H1 to H2 and the width and height are related by the ratio from K1 to K2, then leave in the frame and note that there may be a sign in this area. Almost certainly, only numbers and letters will remain at this stage, the rest of the trash will leave the frame. Let's take rectangles bounding contours, bring them to the same scale and then work on each letter / number separately.
These are the bounding boxes of the contours that meet our requirements:

Letters / Numbers
The picture quality is good, all the letters and numbers are perfectly separable, otherwise we would not have reached this step.
Scale all characters to the same size, for example, 20x30 pixels. Here they are:

By the way, when performing Resize (when casting to a size of 20x30), OpenCV will turn a binarized image into a gradient, due to interpolation. We'll have to repeat the binarization.
And now the easiest way to compare with well-known symbol images is to use XOR (normalized Hamming distance). For example:
Distance = 1.0 - | Sample XOR Image | / | Sample |
If the distance is more than the threshold, then we believe that we have found the sign, less - throw it out.
Letter-digit-digit-digit-letter-letter
Yes, we are looking for car signs of the Russian Federation in this format. Here it is necessary to take into account that the number 0 and the letter “o” are completely indistinguishable from each other, the number 8 and the letter “c”. We will line up all the signs from left to right and we will take 6 characters each.
Criterion of times - letter-digit-digit-digit-letter-letter (do not forget about 0 / O, 8 / c)
Criterion two - the deviation of the lower limit of 6 characters from the line
The total points for the hypothesis is the sum of the Hamming distances of all 6 characters. The bigger, the better.
So, if the total points are less than the threshold, then we believe that we have found 6 characters of the number (without region). If more than the threshold, then go to the algorithm resistant to dirty numbers.
There is still worth considering separately the letters "H" and "M". To do this, you need to make a separate classifier, for example, on the gradient histogram.
Region
The next two or three characters above the line drawn along the bottom of the 6 characters already found are the region. If the third digit exists, and its similarity is more than the threshold, then the region consists of three digits. Otherwise, from two.
However, the recognition of a region often does not go as smoothly as we would like. The numbers in the regions are smaller, they may not successfully split. Therefore, it is better to recognize the region in a way that is more resistant to dirt / noise / overlap, as described below.
Some details of the description of the algorithm are not too detailed. Partly due to the fact that now only a mock-up of this algorithm has been made and we still have to test and debug it on those thousands of images. If the number is good and clean, then you need to recognize the number in tens of milliseconds or answer "failed" and go to a more serious algorithm.
Algorithm resistant to dirty numbers
It is clear that the algorithm described above does not work at all if the signs on the number stick together due to poor image quality (dirt, poor resolution, unsuccessful shadow or angle of shooting).
Here are examples of numbers when the first algorithm could not do anything:

And the algorithm described below could.
But you have to rely on the boundaries of the car number, and then inside a strictly defined area, look for signs with a precisely known orientation and scale. And most importantly - no binarization!
Looking for the lower limit of the number
The easiest and most reliable step in this algorithm. We look through several hypotheses on the angle of rotation and build for each hypothesis on rotation a histogram of brightness of pixels along horizontal lines for the lower half of the image:

Select the maximum gradient and so determine the angle of inclination and by what level to cut the number from the bottom. Do not forget to improve the contrast and get this image here:

In general, you should use not only the brightness histogram, but also the dispersion histogram, gradient histogram to increase the reliability of trimming the number.
We are looking for the upper limit of the number
It is no longer so obvious, it turned out, if the rear car number is removed from hands, then the upper limit can be strongly curved and partially cover the signs or in the shade, as in this case:

There is no abrupt transition of brightness in the upper part of the number, and the maximum gradient will cut the number at all in the middle.
We got out of the situation is not very trivial: we trained the Haar cascade detector for each digit and each letter, found all the characters in the image, so we determined the upper line where to cut:

It would seem that it is worth staying here - we already found numbers and letters! But in reality, of course, the Haar detector may be wrong, and we have 7-8 characters here. A good example of the number 4. If the upper limit of the number merges with the number 4, then it is not at all difficult to see the number 7. Which incidentally happened in this example. But on the other hand, despite the error in detection, the upper boundary of the rectangles found does indeed coincide with the upper limit of the license plate number.
Find the side borders of the number
Also nothing tricky - absolutely the same as the bottom. The only difference is that often the brightness of the gradient of the first or last digit in the number may exceed the brightness of the gradient of the vertical border of the number; therefore, it is not the maximum that is chosen, but the first gradient exceeding the threshold. Similarly, with the lower boundary, it is necessary to sort out several hypotheses on the slope, since, due to the perspective, the perpendicularity of the vertical and horizontal boundaries is not at all guaranteed.
So, here is a well trimmed number:

Yes! It is especially nice to insert a frame with a disgusting number that has been successfully recognized.
Only one grieves - to this stage from 5% to 15% of numbers can be cut off incorrectly. For example:

(by the way, someone sent us a yellow taxi number, as far as I understood - the format is not regular)
All this was necessary so that all this was done only to optimize the calculations, since it is computationally expensive to iterate over all possible positions, scales and slopes of characters when searching for them.
Split a string into characters
Unfortunately, because of the perspective and not the standard width of all the sign, you have to somehow select the characters in the already cropped number. Here the histogram will help out again in brightness, but already along the X axis:
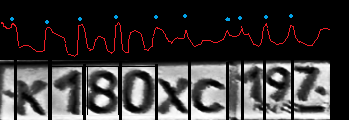
The only thing that should be further explored two hypotheses: the characters begin immediately or one of the histogram maximum should be missed. This is due to the fact that in some rooms the hole for a screw or screw head of a car number may differ, as a separate sign, and may be completely invisible.
Character Recognition
The image is still not binarized, we will use all the information that is.
Here, printed characters means weighted covariance is appropriate for comparing images with an example:
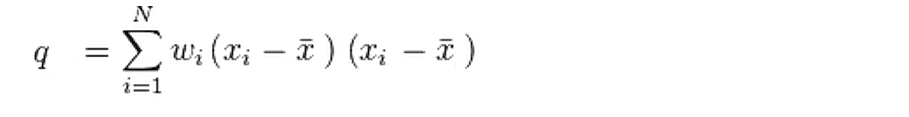
Samples for comparison and weight with covariance:

Of course, one cannot simply compare the area selected by the horizontal histogram with the samples. It is necessary to make several hypotheses on displacement and on scale.
The number of hypotheses on the position of the axis X = 4
The number of hypotheses on the position of the axis Y = 4
The number of hypotheses in scale = 3
Thus, for each region, comparing with one sign, it is necessary to calculate 4x4x3 covariance.
First of all we will find 3 big numbers. This is 3 x 10 x 4 x 4 x 3 = 1440 comparisons.
Then to the left one letter and to the right two more. Letters for comparison 12. Then the number of comparisons 3x12x4x4x3 = 1728
When we have 6 characters, everything to the right of them is the region.

In the region there may be 2 digits or 3 digits - this should be taken into account To break the region in a histogram way is already meaningless due to the fact that the image quality may be too low. Therefore, simply alternately find the numbers from left to right. We start from the upper left corner, we need several hypotheses on the X axis, Y axis and scale. Find the best match. Move to the right by the specified amount, look again. We will look for the third symbol to the left of the first and to the right of the second, if the third symbol’s similarity measure is greater than the threshold, then we are lucky - the region number consists of three digits.
findings
The practice of applying the algorithm (the second one described in the article) has once again confirmed the common truth in solving recognition problems: we need a truly presentable base when creating algorithms. We aimed at dirty and frayed numbers, because The test base was filmed in winter. Indeed, quite bad numbers were often able to be recognized, but there were almost no clean numbers in the training set.
The other side of the coin has also been revealed: there is not so much annoying the user as the situation when the automatic system does not solve an entirely primitive task. “Well, what can be missed here ?!” And the fact that the automatic system could not find out the dirty or shabby numbers is expected.
Frankly, this is our first experience in developing a recognition system for the mass consumer. And about such "trifles" as about users, it is worth learning to think. Now we are joined by a specialist who has developed a program similar to “Recognitor” under iOs. In the UI, the user has the opportunity to see what is being sent to the server, choose which of the numbers allocated by Haar is necessary, it is possible to select the necessary area in the already “frozen” frame. And it is more convenient to use it. Automatic recognition is not a stupid feature, without which nothing can be done, but simply an assistant.
Thinking through a system in which automatic image recognition will be harmonious and convenient for the user - it turned out to be no easier task than creating these recognition algorithms.
And, of course, I hope that the article will be useful.
The first article of the cycle is a general overview of technologies.
The second article - Our server
The third article - Protocol access to our server
Client-side sources with primary number allocation
Assembled prog recognizing numbers
Source: https://habr.com/ru/post/225913/
All Articles