We solve the problem of literacy on the Internet using Yandex.Speler

“If a person has died, he does not know about it, only to others is difficult. The same when he is stupid ... "
And the same thing when he is illiterate.
Unfortunately, it’s impossible to get all people to learn the rules and start writing without mistakes. This is a fact that you need to accept - there are and will be errors on the Internet.
And what if to approach this problem from the other side? It would be great to have such a browser, which, when opening the page, would check the text and correct all errors. Or at least a part. Indeed, in truth, errors are perceived in different ways: a forgotten comma is likely to remain unnoticed, while some “excuses” or “rightly” cause short-term rabies.
')
What will happen if, before reading a page, pass it through the filter and correct spelling, like adblock cuts advertising?
Surely such ideas did not come only to me, but the search for me came to nothing. Therefore, I decided to conduct such an experiment myself and want to talk about the results.
Looking ahead, I will say that the results were interesting, but I could not solve the problem of literacy in this way.
Then why this article, if nothing happened?
A negative result is also a result. I am writing this article for two reasons:
First, so that the next person to whom this idea comes to mind, does not invent everything from scratch, but could rely on my results.
And secondly, suddenly there is a person who can develop this idea further.
Implementation
The implementation is simple - I wrote a bookmarklet ( wiki ). We load the page, click on the bookmarklet - a js-script is launched that checks spelling and corrects errors.
To check the spelling, I used a great service - Yandex.Speller - api.yandex.ru/speller (Terms of use of the service “API Yandex.Speller” - legal.yandex.ru/speller_api ).
Replacement is performed on the first word offered by the service.
There is a limitation - the request should not exceed 10,000 characters. Considering that 1 Russian letter is 6 characters in the URL-encoded form (the letter “a” is% D0% B0), a significant limitation is obtained. The whole text has to be divided into several fragments. For the average page of a forum, you have to perform a dozen or two requests.
For those who want to try out the script for themselves, the source code is a link to bitbucket .
The same, but in one line:
javascript:(function(){function main(){var text=document.body.innerHTML;text=text.replace(/<.*?>/g," "),text=text.replace(/[^--]/g," "),text=text.replace(/\s+/g," ");var fragments=splitByLimit(text,1e4);for(var i=0,len=fragments.length;i<len;i++)checkAndReplace(fragments[i])}function splitByLimit(text,limit){var fragments=[],words=text.split(" "),fragment=[],fragmentLen=0;for(var i=0;i<words.length;i++){var word=words[i];fragmentLen+word.length*6>limit&&(fragments.push(fragment.join(" ")),fragment=[],fragmentLen=0),fragment.push(word),fragmentLen+=word.length*6+3,i==words.length-1&&fragments.push(fragment.join(" "))}return fragments}function checkAndReplace(text){var xhr=new XMLHttpRequest;xhr.onreadystatechange=function(){this.readyState==4&&(xhr.status==200?(data=JSON.parse(xhr.responseText),replaceWords(data)):console.log(xhr.status))},xhr.open("GET","http://speller.yandex.net/services/spellservice.json/checkText?options=7&text="+text,!0),xhr.send()}function replaceWords(data){if(!data)return;var body=document.body.innerHTML;for(var i=0,len=data.length;i<len;i++){var subst=data[i];if(subst.s.length!==0&&subst.word.length>4){var replacement='<span style="background-color: #cfc">'+subst.s[0]+" </span>";replacement+='<span style="background-color:#fcc"><span>'+subst.word.split("").join("</span><span>")+"</span></span>";var regexp=new RegExp(subst.word);body=body.replace(regexp,replacement)}}document.body.innerHTML=body}main()})(); To try, you need to create a bookmark in the browser and enter this code in the URL field.
results
First impressions are amazing! Corrects all errors. Surprisingly, even geographical names, names, and company names are corrected.
Here are some examples.
Red highlights the original words, green - what was replaced.
Example 1:

Example 2:
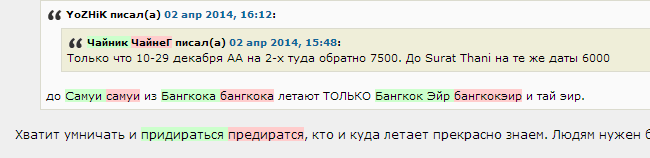
Example 3:

But, unfortunately, not everything is so rosy. There is a downside - false positives . It seems that there are even more of them than the corrected errors. This is especially noticeable on thematic sites with an excess of all sorts of terms and slang (like Habr, for example).
Example 4:
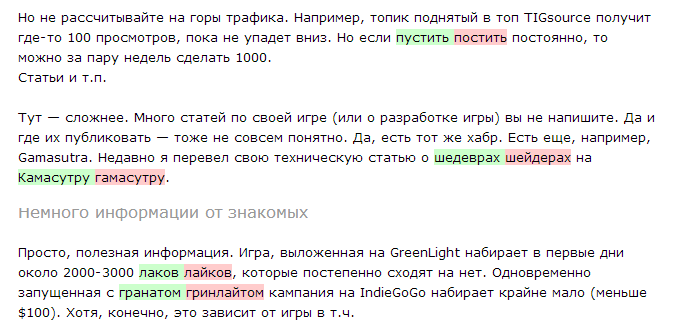
Example 5:

This fact upsets and negates all the advantages of using the script.
But still, I hope that my experiments were useful to someone.
Source: https://habr.com/ru/post/225911/
All Articles