How to use Tomita-parser in your projects. Practical course
Hi, my name is Natalya, I work in Yandex as a developer in the fact extraction team. In the spring, we talked about what a Tomita-parser is and why it is used in Yandex. And this fall, the source of the parser will be posted in open access.
In the previous post, we promised to tell you how to use the parser and the syntax of its internal language. This is what my today's story is about.

')
After reading this post, you will learn how dictionaries and grammars are compiled for Tomita, as well as how to extract facts from natural language texts with their help. The same information is available in the format of a small video course .
A grammar is a set of rules that describe a string of words in a text. For example, if we have the sentence “I like that you are not sick of me,” it can be described using the chain [first person pronoun, singular], [present tense verb and third person], [comma], [union] etc.
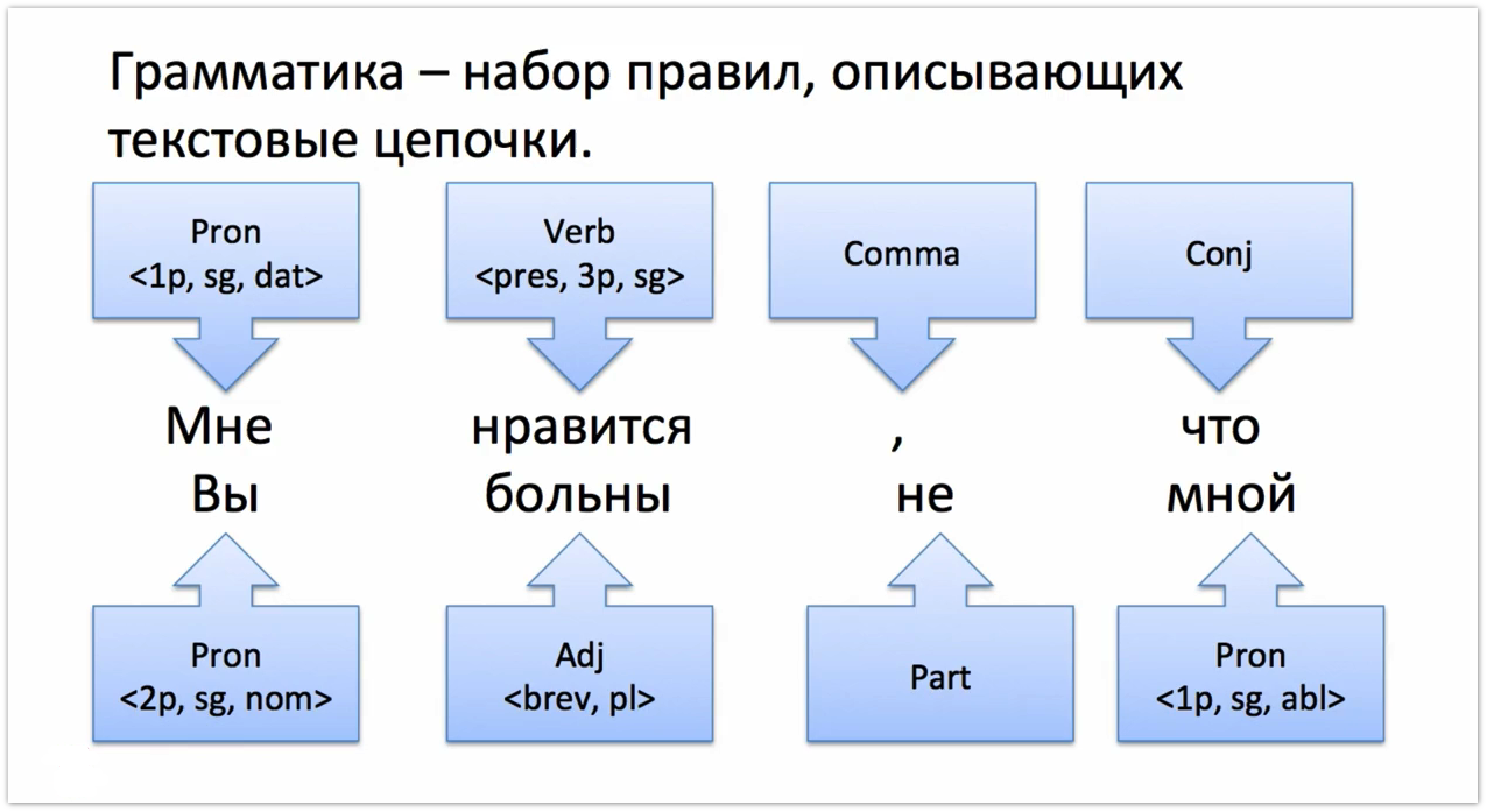
Grammar is written in a special formal language. Structurally, the rule is divided by the symbol -> into the left and right parts. On the left side there is one non-thermal, and the right consists of both terminals and non-terminals. The terminal in this context is a certain object that has a specific, immutable value. The set of terminals is the alphabet of the Tomit language, from which all the other words are built. The terminals in Tomit are the 'lemmas' - words in the initial form, written in single quotes, parts of speech ( Noun, Verb, Adj ...), punctuation marks ( Comma, Punct, Hyphen ...) and some other special characters ( Percent, Dollar ...). There are about twenty total terminals in Tomit, a complete list is presented in our documentation. Non-terminals are made up of terminals, and if we draw an analogy with natural languages, they are something like words. For example, the nonterminal NounPhrase, consisting of two terminals Adj and Noun , means a chain of two words: first an adjective, then a noun.
To compose our first grammar, you need to create a file with the extension .cxx, let's call it first_grammar. You can save it in the same place where the parser binary itself is located. In the first line of the grammar file you need to specify the encoding:
#encoding "utf8" Then you can write the rules. In our first grammar there will be two:
PP -> Prep Noun; S -> Verb PP; The first rule describes the nonterminal PP - a prepositional group consisting of a preposition and a noun ( Prep Noun ). The second rule is a verb with a prepositional group ( Verb PP ). In this case, the non-terminal S is root, because it is never mentioned on the right side of the rule. Such a non-terminal is called a treetop. It describes the entire chain that we want to extract from the text.
Our first grammar is ready, but before you run the parser, you need to do a few more manipulations. The fact is that grammar interacts with the parser not directly, but through the root dictionary - an entity that collects information about all the created grammars, dictionaries, additional files, etc. Those. The root dictionary is a kind of aggregator of everything that is created within the project. Dictionaries for Tomita-Parser are written using syntax similar to Google Protobuf (using a modified version of the Protobuf compiler, with support for inheritance). Files are usually given the extension .gzt. Create the root dictionary dic.gzt and in the beginning also specify the encoding:
encoding "utf8"; After that, we import into the root dictionary files containing the base types used in dictionaries and grammars. For convenience, these files are stored in the parser's binary, and we can import them directly, without setting the path to them:
import "base.proto"; import "article_base.proto"; Next we create an article. A dictionary entry describes how to highlight a string of words in a text. Grammar is one of the possible ways. You can select a chain using the list of keywords built into the algorithm's parser (the name and date chains). Other methods can be added at the source level of the parser (for example, the statistical named entity recognizer). The article consists of type, title and content. What types of articles are and what they are for, I will discuss below when we talk more about dictionaries. For now, we'll use the basic type of TAuxDicArticle . The name of the article must be unique, it is indicated in quotes after the type. Further, in curly brackets are listed the keys - the content of the article. In our case, the only key contains a reference to the grammar written by us. First, we specify the syntax of the file to which we refer (in the case of a file with a grammar it is always tomita ) and the path to this file, then in the type field - the type of the key (it must be indicated if the key contains a link to the grammar).
TAuxDicArticle "_" { key = {"tomita:first_grammar.cxx" type=CUSTOM} } To tell the parser where we get the source text, where we write the result, what grammars we run, what facts we extract, as well as other necessary information, we create a single configuration file with the .proto extension. Create a config.proto file in the parser folder. As usual, at the beginning we specify the encoding and proceed to the description of our configuration.
The only required parameter of the configuration file is the path to the root dictionary, which is written in the Dictionary field. All other parameters are optional. Information about the input file is in the Input field. In addition to text files, Tomit can also input a folder, an archive or stdin. The Output field records where and in what format (text, xml or protobuf) the extracted facts should be saved. We will send the input.txt file to the input . The Articles field lists the grammars we want to run. Please note that here we indicate not the grammar file itself, but the title of the article from the dictionary, which contains a link to this file: as we have said, the parser interacts with all project files indirectly through the root dictionary.
encoding "utf8"; TTextMinerConfig { Dictionary = "dic.gzt"; Input = {File = "input.txt"} Output = {File = "output.txt" Format = text} Articles = [ { Name = "_" } ] } Now that the configuration file is ready, we have to put the text file for analysis next to the binary (you can use our test file or take your own) and you can proceed to launch the grammar. In the terminal, go to the folder where our parser is located. The parser starts with a single argument — the name of the configuration file. Accordingly, in * NIX-systems, the command to start will look like this:
./tomitaparser config.proto The results can be found in the file output.txt. However, we will not see any extracted facts there, because in our grammar there are only rules for identifying chains, and in order for the selected chains to turn into structured facts, we must add an interpretation procedure. We will talk about it below. However, we can see the selected chains already at this stage, for this we need to add another parameter to the configuration file - debug output:
PrettyOutput = "pretty.html" Thanks to this parameter, the results of the parser will be recorded in an html-file with a more visual representation. Now, if we restart the grammar and open the pretty.html file that appeared in the folder, we will see that we have extracted all the chains we described in the grammar — the verbs, followed by a noun with the preposition:
| to go on the slats |
| stop near dukhan |
| stay overnight |
| walk up to him |
| go to Stavropol |
| move with |
| take on vodka |
| come on line |
| do against the highlanders |
| reckon in the third |
| follow the day |
| to be in the south |
| go to the mountain |
| look back on the valley |
| demand vodka |
| look at the captain |
| bump into a cow |
| shelter by the fire |
| be in Chechnya |
| step back |
| pull out of the suitcase |
| regret |
| go out in front |
| put on trial |
| to be visiting |
| stand in a fortress |
| settle in a fortress |
| walk on a boar |
| burst out laughing |
| be in it |
| be on money |
| clap |
| look at this |
| run after the owner |
| to become in the hut |
| go on the air |
| go to the mountains |
| Wade along fence |
| to be behind the Terek |
| ride with abreks |
| jump over stumps |
| follow the tracks |
| hang on the front |
| fly into the ravine |
| kill to death |
| drag on the steppe |
| run along the shore |
| fly from under the hooves |
| shine in the dark |
| zazvenet about chain mail |
| hit the fence |
| rush into the stable |
| grab your guns |
| spin among the crowd |
| put in a stranger |
| talk about something else |
| come from love |
| jump in the village |
| leave the fortress |
| change in the face |
| jump over a gun |
| gallop on dashing |
| snatch from cover |
| fall to the ground |
| come to the fortress |
| ride on it |
| go to the village |
| go to him |
| stand at a dead end |
| stand at a dead end |
| sit in the corner |
| wither in captivity |
| look out the window |
| sit on a stove bench |
| go to him |
| hit hands |
| to be able to crack |
| dream in a dream |
| wait by the road |
| be at dusk |
| dive from the bush |
| see from the hillock |
| chomp in the snow |
| get out of the hut |
| go out as |
| to set off |
| to get exhausted |
| lead to heaven |
| disappear into the cloud |
| rest on top |
| crunch under your feet |
| surging into the head |
| fall away from the heart |
| climb the Good Mountain |
| get off the shelf |
| descend from Hood Mountain |
| come from the word |
| fall under your feet |
| turn into ice |
| hide in the fog |
| beat the bars |
| stop in the weather |
| give vodka |
| play out on the cheeks |
| announce death |
| wash for the boars |
| go beyond the serf |
| walk around the room |
| sit on the bed |
| drag in the mountains |
| fall on the bed |
| be in September |
| walk along the serf |
| sit on the sod |
| to be from the shaft |
| sit on the corner |
| stand still |
| stand on stirrups |
| come back from hunting |
| to be behind the river |
| bet |
| change to this |
| carry on the hunt |
| yearn for home |
| put in that |
| leave custody |
| go to America |
| die on the road |
| to be in the capital |
| to come from drinking |
| to be a wonder |
| dart through the reeds |
| go to the reeds |
| get together |
| specify in the field |
| tear from the saddle |
| compare with Pechorin |
| stick with a gun |
| fall on your knees |
| to hold on hands |
| climb a cliff |
| jump off the horses |
| pour out of the wound |
| be memoryless |
| put him |
| send for a doctor |
| get out of the fortress |
| sit on a rock |
| drag in the bushes |
| jump on horse |
| sit by the bed |
| turn to the wall |
| want to go to the mountains |
| meet soul |
| will be in paradise |
| come to the idea |
| die in that |
| kneel down |
| go to serf |
| die with grief |
| sit on the ground |
| run over the skin |
| to bury behind the fortress |
| go to Georgia |
| return to Russia |
| part with maxim |
The parser tries to normalize the extracted chains, leading the main word of the chain (the first by default) to the initial form.
The next step is the introduction of an interpretation procedure, i.e. conversion of extracted chains into facts.
First we need to create a structure of the fact that we want to extract, i.e. describe what fields it consists of. To do this, create a new fact_types.proto file. Again, we will import the files with the basic types, and then proceed to the description of the fact. After the word message, the name of the fact, the colon and the base type of the fact from which the type of our fact is inherited is written. Next, in curly brackets, we list the fields of our fact. In our case, the field is one, it is required (required), the text (string) is called Field1 and we assign it the identifier 1.
import "base.proto"; import "facttypes_base.proto"; message Fact: NFactType.TFact { required string Field1 = 1; } Now we need to import the file we created into the root dictionary (dic.gzt):
import "fact_types.proto"; Let us turn to grammar, in which the interpretation procedure takes place. Suppose we want to extract the following fact from the text: verbs that control nouns with a preposition. To do this, we write interp in the rule after the verb marker, and then in parentheses the name of the fact and the period in which we want to put the extracted chain.
S -> Verb interp (Fact.Field1) PP; Interpretation can occur anywhere in the grammar, but the fact is removed only if the interpreted character gets into the root non-terminal.
The last detail needed to run is to specify in the configuration file which facts we want to extract when starting the parser. The syntax in this case is the same as when specifying the launched grammars: all necessary facts are listed in the Facts field of the square brackets. In our case, there is only one fact so far:
Facts = [ { Name = "Fact" } ] Now you can run the parser again.
| go |
| stay |
| stay |
| come up |
| go |
| move |
| to take |
| come |
| put it on |
| be considered |
| follow |
| to happen |
| go |
| look back |
| require |
| look |
| to stumble |
| take shelter |
| be |
| move away |
| pull out |
| regret |
| go out |
| give away |
| be |
| stand |
| settle |
| walk |
| to tear |
| be |
| be |
| clap |
| to look |
| run |
| become |
| go out |
| lie down |
| Wade through |
| be |
| ride |
| jump |
| to run |
| hang |
| fly |
| to be killed |
| to reach out |
| run |
| fly |
| shine |
| to ring |
| hit |
| rush |
| grapple |
| spin |
| put it on |
| to speak |
| to happen |
| to jump |
| move out |
| to change |
| jump over |
| to ride |
| snatch |
| to tumble down |
| to come |
| ride off |
| go |
| to go |
| become |
| become |
| sit |
| to fade away |
| look in |
| sit |
| come in |
| bump |
| be able to |
| to dream |
| to wait |
| be |
| dive |
| see |
| chill out |
| go out |
| go out |
| to move |
| get out |
| to lead |
| disappear |
| relax |
| crunch |
| surging |
| fall away |
| climb |
| get off |
| to go down |
| take place |
| fall through |
| turn into |
| to hide |
| to fight |
| stop |
| to give |
| play out |
| to announce |
| undermine |
| go out |
| walk |
| sit |
| to drag off |
| to fall |
| be |
| walk around |
| sit down |
| be |
| sit |
| stand |
| get up |
| return |
| be |
| to fight |
| to change |
| spend |
| to yearn |
| put it on |
| go out |
| to go |
| die |
| to happen |
| take place |
| be |
| dart |
| get away |
| get together |
| indicate |
| tear |
| compare |
| attach themselves |
| to fall |
| Keep |
| climb |
| jump off |
| pour |
| be |
| to plant |
| send |
| go out |
| sit down |
| to drag |
| jump |
| sit |
| turn away |
| want |
| to meet |
| will be |
| to come |
| die |
| become |
| to go |
| die |
| sit down |
| run through |
| bury |
| to leave |
| come back |
| breake down |
Additional grammar features
Now we will set ourselves a more difficult task: we will try to write a grammar with which we can extract street names from the text. We will search for text descriptors (the words street, highway, avenue, etc.) and analyze the chains that stand next to them. Chains must begin with a capital letter and be located to the left or right of the descriptor. Let's create a new file with the grammar of address.cxx and save it in the folder with our project. Immediately add an article with our new grammar to the root dictionary:
TAuxDicArticle "" { key = {"tomita:address.cxx" type=CUSTOM} } Now we’ll add to the fact_types.proto file a new Street fact that we want to extract. It will consist of two fields: mandatory (street name) and optional (descriptor).
message Street: NFactType.TFact { required string StreetName = 1; optional string Descr = 2; } To go directly to writing grammar, you need to enter a few new concepts, which we have not touched before.
The first concept is the operators. They allow you to get a more convenient abbreviated grammar rule entry:
- * - the symbol is repeated 0 or more times;
- + - the symbol is repeated 1 or more times;
- () - the character enters the rule 0 or 1 time;
- | - operator "or".
Let's move on to writing grammar. In the file address.cxx we will write two rules - in the first we will describe the StreetW non-terminal, which will contain the names of some street descriptors, and in the second - the
StreetSokr non- StreetSokr with abbreviations. #encoding "utf8" StreetW -> '' | '' | '' | ''; StreetSokr -> '' | '' | '-' | '' | ''; Next, we will add a StreetDescr non- StreetDescr , which will combine the two previous ones:
StreetDescr -> StreetW | StreetSokr; Now we need to describe the chains, which, in case they stand next to the descriptor, can be street names. To do this, we introduce two more concepts: restrictions and consistency markers.
Litters clarify the properties of terminals and non-terminals, i.e. impose restrictions on the set of chains, which describes the terminal or nonterminal. They are written in angle brackets after terminals / non terminals and, in the case of non terminals, are applied to the syntactically main word of the group. Litters can be varied in their structure. Some are a unary operator, some have a field that can be filled with different values. We list some litters that we will use in the future (a full list can be found in our documentation):
- The morphological litter
gramis a field that can be filled with any morphological category from the dictionary: part of speech, gender, number, case, time, mood, voice, face, etc.<gram = “, , ”>; - Graphematic labels - a group of litters that impose a restriction on the register of the extracted chain:
<h-reg1>, <l-reg>; - Special litters - can reflect the position of the word in the sentence, the alphabet, etc .:,,
, , ;
: , : <~fw>, <~lat> ., , ;.
: , : <~fw>, <~lat>A little apart is the syntactic litter
. ( ), . .. ( ), . .Litter matching is also written in angle brackets and means that the two grammatical categories must match for the two characters to which it is assigned. Most often, the following approvals apply:
- By type, number and case:
gnc-agr; - By type and number:
gn-agr; - According to the case:
c-agr.
In the rule, it is necessary to write a matching identifier that indicates which symbol matches which symbol. For example, in the following rule, the symbol A is consistent with B by gender, number and case, and from C by number and case:
S -> A<gnc-agr[1], nc-agr[2]> B<gnc-agr[1]> C<nc-agr[2]>;Let us return to our rule describing the names of streets. Usually the street name is either an adjective, consistent with a descriptor (Moskovsky Prospect), or a nominal group, standing in the nominative or genitive case (Kuznetsky Most street or Red Cadets street). We first describe the noun group. The main element of this chain will be a word, in front of which an adjective agreed with it (Veshny Vod Street) can stand, and after that - one more word in the genitive case (Moscow Eighth Anniversary Street).
StreetNameNoun -> (Adj<gnc-agr[1]>) Word<gnc-agr[1],rt> (Word<gram="">);Street names, expressed by adjectives, are described quite simply. This is a sequence of adjectives, the first of which must necessarily come with a capital letter:
StreetNameAdj -> Adj<h-reg1> Adj*;In the root rules, we put together the descriptors and street names and add an interpretation. We assume that the name of the street, expressed by the nominal group, comes after the street descriptor. It must be with a capital letter and stand in the nominative or genitive case (the litters assigned to the
StreetNameNounnon-StreetNameNounwill be applied to the main word of the chain). The street descriptor is interpreted in theDescrfield of theDescrfact, and the street name is interpreted in theDescrfield.Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName); Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName);, , ̈ , , (1- ). , , . . , , :
wff,wfl— ,wfm— .S -> A<wff=/[0-9]+.?/>;, , 0 99, , . , — —
NumberW.NumberW_1 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/>; NumberW_2 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/>; NumberW_3 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/>; NumberW -> NumberW_1 | NumberW_2 | NumberW_3;, -, . , , , .. , . .
outgram, . :NumberW_1 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/> {outgram=",,"}; NumberW_2 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/> {outgram=",,"}; NumberW_3 -> AnyWord<wff=/[1-9]?[0-9]-?(()|()|()|)/> {outgram=",,"};StreetNameAdj:NumberW, , .StreetNameAdj -> NumberW<gnc-agr[1]> Adj<gnc-agr[1]>;,
StreetNameAdj. , , , . ̈ , .. .Street -> StreetNameAdj<gnc-agr[1]> interp (Street.StreetName) StreetW<gnc-agr[1]> interp (Street.Descr); Street -> StreetNameAdj interp (Street.StreetName) StreetSokr interp (Street.Descr); Street -> StreetW<gnc-agr[1]> interp (Street.Descr) StreetNameAdj<gnc-agr[1]> interp (Street.StreetName); Street -> StreetSokr interp (Street.Descr) StreetNameAdj interp (Street.StreetName);. , ( ). , , , , . , .
not_norm. , , .Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName::not_norm); Street -> StreetDescr interp (Street.Descr) StreetNameNoun<gram="", h-reg1> interp (Street.StreetName::not_norm);, , address.cxx
Street. , ,Inputinput1.txtInput = {File = "input1.txt"} Output = {File = "output.txt" Format = text} Articles = [ { Name = "" } ] Facts = [ { Name = "Street" } ], :
ResultAddress StreetName Descr 1- 1- sh Dictionaries
. dic.gzt, — , , , .. . . .
. , ̈ . — — :
TAuxDicArticle "" { key = "" | "" | ""}, :
TAuxDicArticle "" { key = {"tomita:address.cxx" type=CUSTOM}}̈ . , , ̈ — . , , , , , ..
TAuxDicArticle "" { key = { mainword=2 agr=gnc_agr} }«» — « », , , . , .
, :
TAuxDicArticle "-" { key = "-" key = "" key = "" lemma = "-" }, , .
kwtype. , , (), , .. ,kwtype.kwset, . :Animals -> Word <kwtype="">; Forest -> Word <kwset=["", ""]>;, ̈ . TAuxDicArticle, , , , . kwtypes.proto. , :
import "base.proto"; import "articles_base.proto"; import "kwtypes_base.proto";̈ . .
message, , . .message surname : TAuxDicArticle {}. .gzt- surnames.gzt, , ̈ surname. , kwtypes.proto, , . , ,
TAuxDicArticlesurname:encoding "utf8"; import "kwtypes.proto"; surname "" { key = "" } surname "" { key = "" } surname "" { key = "" },
import "surnames.gzt";.import "kwtypes.proto";., , , : « -». imeni.cxx. , . . ,
surname. ̈ , . + “” ( ).#encoding "utf8" Initial -> Word<wff=/[-]\./>; Initials -> Initial Initial; FIO -> Initials Word<kwtype=surname>; Imeni ->''<gram=", "> FIO;. :
TAuxDicArticle "" { key = {"tomita:imeni.cxx" type=CUSTOM} }config.proto ( ) , — . , imeni.cxx input2.txt . . , pretty.html , .
, , . :
kwtype, ̈ , ,#include.#include— , , .kwtype. imeni.cxx ̈ , . org.cxx. .#encoding "utf8" OrgDescr -> '' | '' | '';« -».
kwtype, «», imeni.cxx. , ,kwtype— . — ., .
Org_ -> OrgDescr Word<kwtype="">; Org -> Org_ interp (Org.Name);:
TAuxDicArticle "" { key = {"tomita:org.cxx" type=CUSTOM} }fact_types.proto:
message Org: NFactType.TFact { required string Name = 1; }, , ̈ . , “”. , “Org”.
Articles = [ { Name = "" } ] Facts = [ { Name = "Org" } ]pretty.html. « . . ».
? « .. » imeni.cxx. « _..», .. , org.cxx.
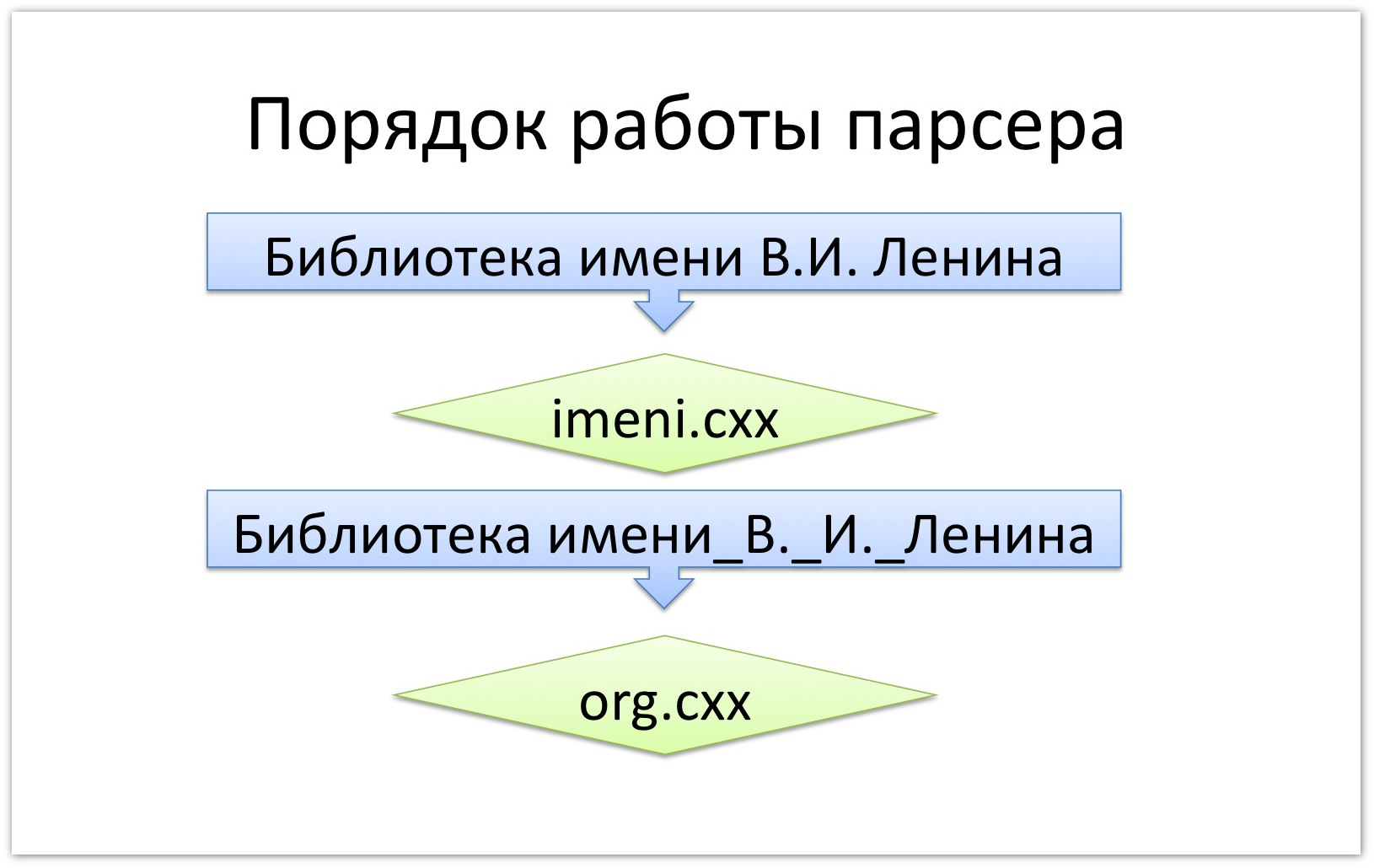
, , (..
kwtype): , . - By type, number and case:
Source: https://habr.com/ru/post/225723/
All Articles