Recoder - another look at the NSI
Over the years, the company usually comes to the fact that many directories on one topic (for example, “Hobby” or “Gender”) are stored in completely unimaginable formats in different systems, preventing effective integration and data exchange.
The traditional approach to solving this problem recommends creating a single version of the Hobby directory and setting up exchange flows into (and from) it for all information systems. We decided to go the other way and create a decentralized open-source NSI - Perekoder.
Want to know exactly what we did and what role Lucene and Apache CXF play in our product?
How is the task of storing directories usually solved?
The IT director decides to stop the species diversity of directories, and the company begins to build a single directory. It will be designed to combine all possible types of corporate data and finally put an end to “patchwork automation” and “historical heritage”.
If we solve the problem, then immediately for everything, right?
')
And no.
They will not write about the terrible drawbacks of centralization in the presentations of large Western companies that really want to sell you multi-million software, and will not say in press releases. But starting such a project, you will embark on a long tedious implementation that will go on for years. Because the entities that you will lead to the same standard have a different nature. And this makes it pointless to unite them in a single system.
Do not believe - see for yourself the table with the data types that are usually found in the company:
In practice, the fastest and most successful implementations occur in those companies that separately solve the problem of inventories, separately - the task of building a directory of counterparties, and somehow they deal with classifiers.
Product information management (PIM) is usually implemented for goods and materials, Customer Data Integration (CDI) is used for contractors, but something interesting happens with classifiers: they are often separately implemented with MDIs and a single version of the truth is formed.
Is it correct to implement the NSI and create a single version of the classifiers? Or you can solve this problem differently?
Is it good to have a single version of the truth for classifiers?
When converting classifiers to a single type, one of the scenarios usually occurs:
In general, a single version of the truth is usually expensive.
In addition, with a single standard, there is always the problem of the “gray zone”. This is the difference between the values in the source systems and the values of the coveted single version of the truth, which was personally confirmed by a specially appointed expert. The presence of the "gray zone" and the need to work with it leads to the emergence of numerous workflows and alternative flows, which is a significant part of the functionality (read the cost) of the NSI.
But also business is not always ready to wait for numerous approvals for years. Therefore, as a result, the data begins to be forwarded “under the table”, using “temporary” recoding (what it is, we will tell below).
A natural question arises: if a single version of the truth costs so much, can we do without it?
It is possible - there are organizations in which the NSIs are not implemented. Looking carefully, you will find in these organizations a lot of small correspondence tables between the “Gender”, “Education” directories, etc. in different systems. They will be stored in Oracle, then on the bus, or even directly in the code for downloads-unloadings and exports-imports. Because correspondence tables are the most natural way to solve a problem, when the same domain is indicated differently for different people or systems.
In other words, you can force all people on earth to speak Esperanto (create a unified version of the truth), or you can invite a Chinese-German medical translator (make a correspondence table) to negotiate Chinese and German doctors.
Therefore, we decided to make a simultaneous translator who understands the language of any system and allows them to agree on the same concepts as part of a business process. We called the correspondence tables transcoding, and the system itself - the recoder.
The main purpose of the recoder is to keep copies of reference books of source systems and transcoding between them.
What can be done using the recoder
Can and should:

Classifier "Customer service program", in which the attributes are for some reason called non-Russian words Description and Full Description
The system is divided into modules to isolate the API, business logic and storage from each other. The IoC binder between the components is the Spring Framework.
Technological scheme of data streams can be represented as follows:
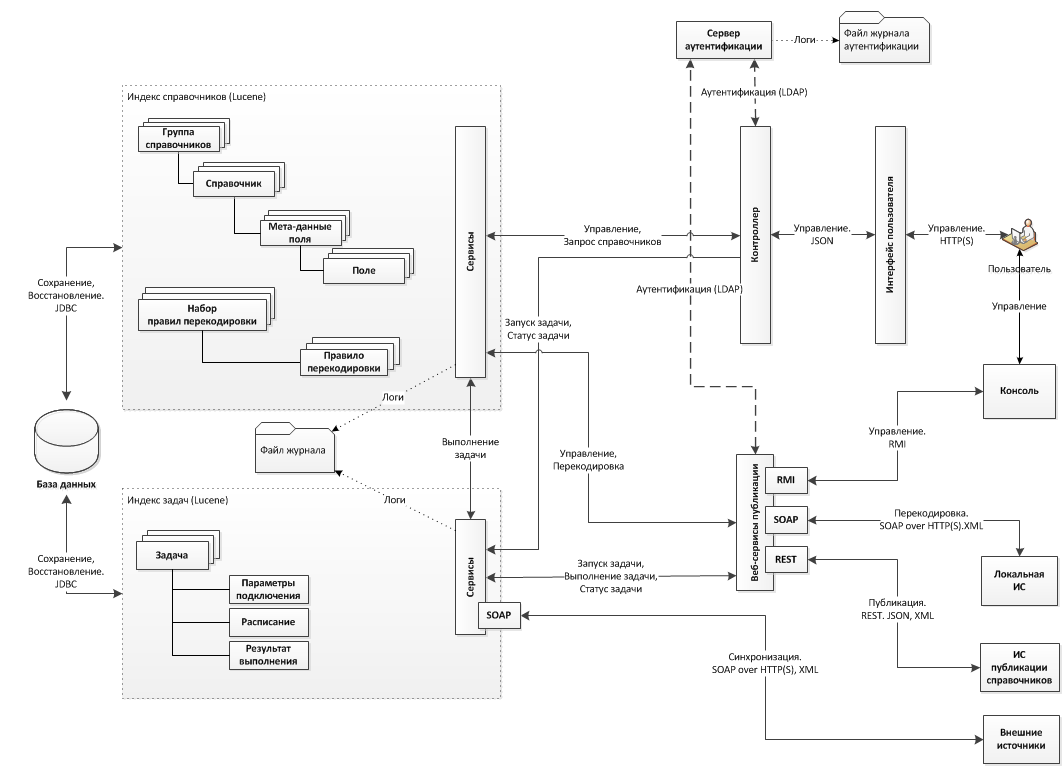
As you can see, services do not interact directly with the database at all. Instead, all the work (read / write) goes with the Lucene index, and the results of write operations are additionally written to the base. What is it done for? Everything is simple: the main task of the system is to find the transcoding as quickly as possible (correspondence between the records in a pair of directories), and such an architecture most effectively copes with this on large amounts of data. Plus, we get a full-text search for all the data "out of the box." Of course, it would be possible to use higher-level solutions, such as Elasticsearch or Solr, but they have their drawbacks, the fight against which is more expensive than writing your own code.
In order to ensure the integrity of information, data is modified in one transaction in the search index and in the database. Moreover, the interfaces are designed so that the business logic of the application knows only about the index, and the DBMS can be replaced with another solution with minimal modifications. In fact, you need to implement a couple of classes and add them to the classpath - everything else will be done by Spring and the class-compiling factories (runtime code compiling).
The framework for SOAP and RESTfull interfaces is Apache CXF, which makes it easy to customize the versioning API (if you suddenly need to change it) and interpose in any phase of processing incoming / outgoing messages.
github.com/hflabs/perecoder
rcd.hflabs.ru/rcd/admin/login
Login: admin
Password: demo
confluence.hflabs.ru/x/RICSCg
We started the implementation of the recoder with several customers.
We welcome your comments on the functionality: what you like, what doesn't, what is not clear.
Well, if this product will be useful to you, it means that we did not waste time writing this article;)
The traditional approach to solving this problem recommends creating a single version of the Hobby directory and setting up exchange flows into (and from) it for all information systems. We decided to go the other way and create a decentralized open-source NSI - Perekoder.
Want to know exactly what we did and what role Lucene and Apache CXF play in our product?
How is the task of storing directories usually solved?
The IT director decides to stop the species diversity of directories, and the company begins to build a single directory. It will be designed to combine all possible types of corporate data and finally put an end to “patchwork automation” and “historical heritage”.
If we solve the problem, then immediately for everything, right?
')
And no.
They will not write about the terrible drawbacks of centralization in the presentations of large Western companies that really want to sell you multi-million software, and will not say in press releases. But starting such a project, you will embark on a long tedious implementation that will go on for years. Because the entities that you will lead to the same standard have a different nature. And this makes it pointless to unite them in a single system.
Do not believe - see for yourself the table with the data types that are usually found in the company:
| What describe | Table, machine, etc. | Physical, legal entities, PE / IP. | Attributes of entities: education, profession, etc. |
| Attribute truth criteria | Objective (there is a real machine on which to look) | Objective (there is a real person or company who can ask everything) | Subjective (expert opinion, which may not be entirely right, or the system) |
| The size | Medium (tens of thousands of units) | Medium or large (hundreds of thousands and millions of records) | Small (thousands of units) |
| Number of attributes | Average (attributes of inventories) | Average (client attributes) | Small (in most cases, the structure type id - name) |
| How do existing objects change over time? | Seldom | Constantly change (change of address, marital status, gender ...) | Unpredictably change depending on the needs of the information system or business process |
In practice, the fastest and most successful implementations occur in those companies that separately solve the problem of inventories, separately - the task of building a directory of counterparties, and somehow they deal with classifiers.
Product information management (PIM) is usually implemented for goods and materials, Customer Data Integration (CDI) is used for contractors, but something interesting happens with classifiers: they are often separately implemented with MDIs and a single version of the truth is formed.
Is it correct to implement the NSI and create a single version of the classifiers? Or you can solve this problem differently?
Is it good to have a single version of the truth for classifiers?
When converting classifiers to a single type, one of the scenarios usually occurs:
- A monster reference book is created that takes into account all the combinations in the source systems. This complex reference book is difficult to modify, requires lengthy approvals, and over time it is slowly being slaughtered.
- It creates a single directory, which contains a stripped-down version of the truth that suits everyone. Who worked in a large company, he knows that the search for "the truth, arranging a swan, cancer and pike" rarely ends successfully, and if it ends, it requires many, many hours of fierce meetings.
In general, a single version of the truth is usually expensive.
In addition, with a single standard, there is always the problem of the “gray zone”. This is the difference between the values in the source systems and the values of the coveted single version of the truth, which was personally confirmed by a specially appointed expert. The presence of the "gray zone" and the need to work with it leads to the emergence of numerous workflows and alternative flows, which is a significant part of the functionality (read the cost) of the NSI.
But also business is not always ready to wait for numerous approvals for years. Therefore, as a result, the data begins to be forwarded “under the table”, using “temporary” recoding (what it is, we will tell below).
Is it possible not to create a single version of the truth?
A natural question arises: if a single version of the truth costs so much, can we do without it?
It is possible - there are organizations in which the NSIs are not implemented. Looking carefully, you will find in these organizations a lot of small correspondence tables between the “Gender”, “Education” directories, etc. in different systems. They will be stored in Oracle, then on the bus, or even directly in the code for downloads-unloadings and exports-imports. Because correspondence tables are the most natural way to solve a problem, when the same domain is indicated differently for different people or systems.
In other words, you can force all people on earth to speak Esperanto (create a unified version of the truth), or you can invite a Chinese-German medical translator (make a correspondence table) to negotiate Chinese and German doctors.
Therefore, we decided to make a simultaneous translator who understands the language of any system and allows them to agree on the same concepts as part of a business process. We called the correspondence tables transcoding, and the system itself - the recoder.
The main purpose of the recoder is to keep copies of reference books of source systems and transcoding between them.
How it all works
- At the beginning of work, the Recoder reads directories from the databases of the source systems and saves their copies to their base for subsequent automatic synchronization. We work with Sybase, MariaDB, Vertica, MS SQL Server, MySQL, Oracle, PostgreSQL.
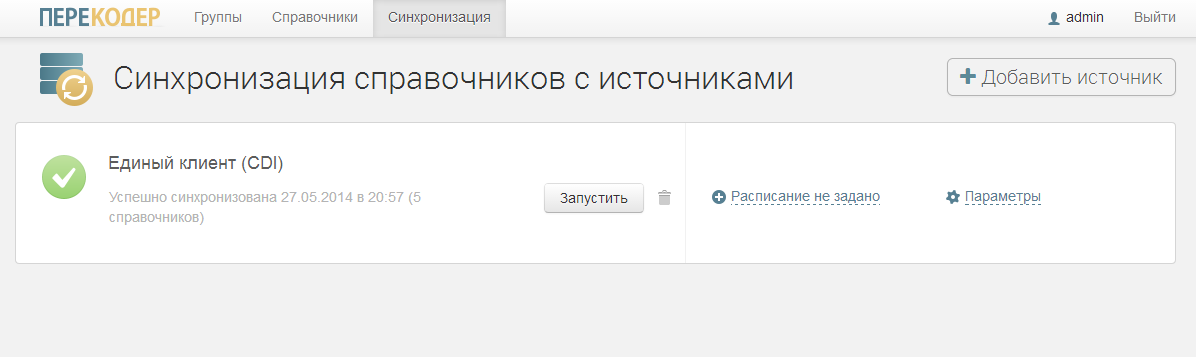
Prufpik - In the recoder interface, the operator sets up the correspondence tables of reference records. For example, if the male sex in one system is entered as “M”, and in the other as “1”, then the operator assigns these two values to the correspondence, creating a transcoding.
- Now, in the process of exchanging information with another system, any system can request the Transcoder via SOAP or REST interface to transfer the value from its classifier to the target system language or translate the received data into its own dialect.
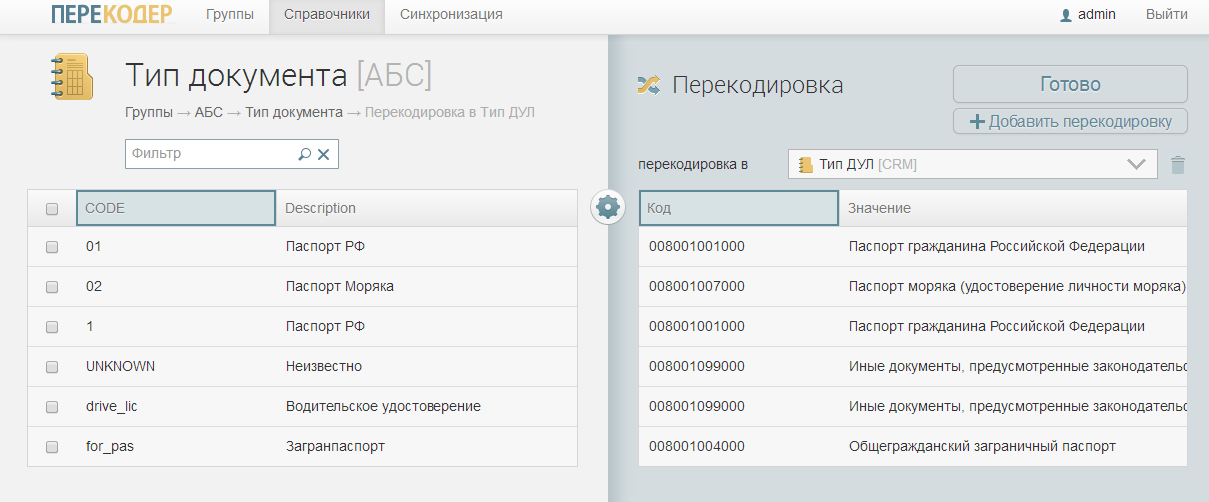
Transcoding from the “Document Type” reference book of a certain banking system (ABS) to the “DUL Type” reference book for CRM. The international passport corresponds to the general civil passport, the driver's license corresponds to other documents. ABS and CRM do not need to integrate with the master directory, everyone is happy. - The recoder is initially designed for a load of up to one thousand recodings per second in order to satisfy all the participants of the information exchange: bus, ETL scripts, servicing real-time procedures, macros in Excel, space station, etc.
What can be done using the recoder
Can and should:
- Manage directories, groups of directories and transcoding (create, edit and delete).
- Configure periodic synchronization of the recoder directories with source systems.
- Perform online transcoding and retrieve source directory values via SOAP and REST interfaces.
- Receive automatic alerts about changes in source directories. If suddenly there is a value for which there is no conversion, SOAP / REST will return an error and notify all interested parties.
Classifier "Customer service program", in which the attributes are for some reason called non-Russian words Description and Full Description
What is under the hood?
The system is divided into modules to isolate the API, business logic and storage from each other. The IoC binder between the components is the Spring Framework.
Technological scheme of data streams can be represented as follows:
As you can see, services do not interact directly with the database at all. Instead, all the work (read / write) goes with the Lucene index, and the results of write operations are additionally written to the base. What is it done for? Everything is simple: the main task of the system is to find the transcoding as quickly as possible (correspondence between the records in a pair of directories), and such an architecture most effectively copes with this on large amounts of data. Plus, we get a full-text search for all the data "out of the box." Of course, it would be possible to use higher-level solutions, such as Elasticsearch or Solr, but they have their drawbacks, the fight against which is more expensive than writing your own code.
In order to ensure the integrity of information, data is modified in one transaction in the search index and in the database. Moreover, the interfaces are designed so that the business logic of the application knows only about the index, and the DBMS can be replaced with another solution with minimal modifications. In fact, you need to implement a couple of classes and add them to the classpath - everything else will be done by Spring and the class-compiling factories (runtime code compiling).
The framework for SOAP and RESTfull interfaces is Apache CXF, which makes it easy to customize the versioning API (if you suddenly need to change it) and interpose in any phase of processing incoming / outgoing messages.
Source
github.com/hflabs/perecoder
Test stand
rcd.hflabs.ru/rcd/admin/login
Login: admin
Password: demo
Documentation
confluence.hflabs.ru/x/RICSCg
What's next
We started the implementation of the recoder with several customers.
We welcome your comments on the functionality: what you like, what doesn't, what is not clear.
Well, if this product will be useful to you, it means that we did not waste time writing this article;)
Source: https://habr.com/ru/post/225469/
All Articles