ABBYY FineReader text recognition (1/2)
Content
The text recognition system in FineReader can be described very simply.
We have a page with text, we parse it into text blocks, then we parse the blocks into separate lines, lines into words, words into letters, we recognize letters, then we collect everything back to the text of the page further down the chain.

')
It looks very simple, but the devil, as usual, is in the details.
Let's talk about the level from the document to the text line some time next time. This is a large system in which there are many of its difficulties. As a kind of introduction, perhaps, you can leave here the following illustration for the string extraction algorithm.

In this article we will begin the story about text recognition from the level of the line and below.
A small warning: the FineReader recognition system is very large and has been constantly updated for many years. To describe this system entirely with all its nuances, firstly, better code, secondly, it will take a lot of space, thirdly, read it . Therefore, we recommend to treat the written below as a kind of very generalized theory behind the practical system. That is, the general ideas and trends in technology are about the same as the truth, but in order to understand in detail what is happening in practice, it is better not to read this article, but to work with us to develop this system.
Linear division graph
So, we have a black and white image of a line of text. In fact, the image is, of course, gray or color, and it becomes black and white after binarization (you also need to write a separate article about binarization, but for now this can be partly helpful).
So, let there be a black and white image of a line of text. It is necessary to divide it into words, and words - into characters for recognition. The basic idea, as usual, is obvious - look for vertical lines of white gaps in the image, and then cluster them across the width: wide gaps are spaces between words, narrow spaces between characters.

The idea is wonderful, but in real life, the width of the spaces can be a very ambiguous indicator, for example, for sloped text or an unsuccessful combination of characters or stuck text.

There are two solutions to the problem, in general. The first solution is to assume some "visible" width of the gaps. A person can practically any text, even in an unfamiliar language, be divided exactly into words, and words into symbols. This is because the brain does not fix the vertical distance between the characters, but a certain apparent volume of empty space between them. The solution is good, we, of course, use it, it only does not always work. For example, the text may be damaged when scanning and some of the necessary gaps may decrease or, conversely, increase greatly.
This leads us to the second solution - the linear division graph. The idea is as follows - if there are several options for dividing a line into words and words into letters, then let's mark all possible division points we could come up with. A piece of the image between the two marked points will be considered a letter (or word) candidate. The linear graph option can be simple if the text is good and there are no problems with the definition of division points or difficult if the image was bad.


Now the challenge. There are many vertices of the graph, you need to find a path from the first vertex to the last, passing through a certain number of intermediate vertices (not necessarily all) with the best quality. We start to think that it reminds. We recall the course of optimal control from the institute, we understand that this is suspiciously similar to the problems of dynamic programming.
Let's think about what we need so that the algorithm for iterating over all the options does not explode.
For each arc in the graph you need to determine its quality. If we work with a graph of linear division of a word into symbols, then each arc in our country is a symbol. In the role of arc quality, we use the confidence of character recognition (how to calculate it - let's talk later). And if we work with GLD at the line level, then each arc of this GLD is a variant of word recognition, which in turn was obtained from a character graph. That is, we need to be able to assess the overall quality of the full path in the linear division graph.
We shall define the quality of the full path in the graph as the sum of the quality of all the arcs of the MINUS penalty for the whole option. Why exactly minus? This gives us the opportunity to quickly assess the maximum possible quality of a path variant by the sum of the quality of the arcs of this path, which means that we will cut off most of the options even before calculating the total quality of the variant.
Thus, for GLD, we arrive at a standard dynamic programming algorithm — we find linear division points, build a path from beginning to end along arcs with the highest quality, calculate the total cost of the constructed version. And then we go through the paths in the FGD in order of decreasing the total quality of the elements with constant updating of the found best option, until we understand that all the raw options are obviously worse than the current best option.
Image hypotheses
Before we go down to the level of recognition of individual words, we have another topic that has not been discussed, the fragment image hypothesis.
The idea is as follows - we have an image of the text with which we are going to work. I really want to process all images in the same way, but the truth is that in the real world, images are all different - they can be obtained from different sources, they can be of different quality, they can be scanned in different ways.
On the one hand, it seems that the variety of possible distortions should be very large, but if you start to understand, only a limited set of possible distortions is found. Therefore, we use the text hypothesis system.
We have a predefined set of possible hypotheses for problem text. For each hypothesis, you need to define:
- A quick way to find out if a given hypothesis is applicable to the current image, and to do so only on the basis of the characteristics of the image, before recognition.
- A method for correcting a specific hypothesis on an image.
- The criterion of the quality of the correctness of the choice of the hypothesis on the basis of image recognition, plus, possibly, recommendations for the following hypotheses.


In the image above you can see the hypotheses for different binarization and contrast of the original image.
As a result, the processing of hypotheses is as follows:
- In the image generate the most appropriate hypothesis.
- Correct the distortion of the selected hypothesis.
- Recognize the resulting image.
- Assess the quality of recognition.
- If the quality of recognition has improved, then assess whether it is necessary to apply new hypotheses to the modified image.
- If the quality has deteriorated, then return to the original image and try to apply some other hypothesis to it.
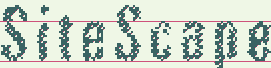
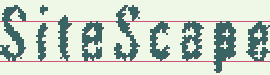
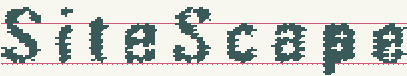
The images show the consistent use of white noise and compressed text hypotheses.
Word quality assessment
Two important topics remained unsolved: the assessment of the overall quality of word recognition and character recognition. Character recognition is a topic in several sections, therefore, we first discuss the assessment of the quality of the recognized word.
So, we have some kind of word recognition. The first thing that comes to mind is to check it with the dictionary and give it a fine if it is not in the dictionary. The idea is good, but not all languages are dictionaries, not all words in the text can be vocabulary (proper names, for example), and if we delve into complexity, not everything in the text can be words in the standard sense of the term.
A little earlier, we said that any marks for the whole word should be negative, so that the DHF brute force works normally. Now it will begin to actively interfere with us, so let's fix that we have a certain predetermined maximum positive evaluation of the word, we give positive bonuses to the word, and we define the final negative penalty as the difference between the collected bonuses and the maximum evaluation.
Ok, let us recognize the phrase “Vasya arrives by flight SU106 at 23.55 07/20/2015”. Of course, we can evaluate the quality of each word here by the general rules, but it will be quite strange. For example, SU106 and Vasya are quite clear words in this line, but it is obvious that the rules of education are different and, in theory, verification should also be different.
From here comes the idea of models. A word model is a kind of generalized description of a specific type of word in a language. We will, of course, have a model of a standard word in a language, but there will also be models of numbers, abbreviations, dates, abbreviations, proper names, URLs, etc.
What do models give us and how to use them normally? In fact, we reverse our word verification system - instead of finding out what it is for a long time, we let each model decide whether this word suits her and how well she evaluates it.

From the very formulation of the problem, our requirements for the model architecture are formed. The model should be able to:
- Quickly say whether or not the word is suitable for her. The standard check includes all checks for allowed character sets for each letter in a word. For example, in a vocabulary word, punctuation should be only at the beginning or at the end, and in the middle of the word the punctuation set is severely limited, and the combination of punctuation is severely limited (super-ability ?!), and in the number model there should basically be numbers except given language of the symbol suffix (10th, 10th).
- To be able to assess the quality of a recognizable word by its own internal logic. For example, a word from a dictionary should be clearly rated higher than just a set of characters.
When assessing the quality of the model, we should not forget that our task as a result is to compare the models with each other, therefore their evaluations should be consistent. A more or less normal way to achieve this is to relate to an assessment of a model as an assessment of the probability of constructing a word using a given model. For example, there are a lot of vocabulary words in ordinary language, and it is easy to get a vocabulary word when it is recognized incorrectly. But to collect a normal, suitable for all the rules of the phone number is much more difficult.
As a result, when recognizing a fragment of a string, we get something like this:
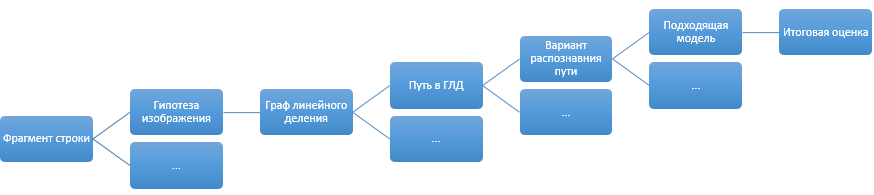
A separate item in the evaluation of recognition options are additional empirical penalties that do not fit into the concept of models or in the assessment of recognition. Say, “LLC Horns and hoofs” and “000 Horns and hoofs” look like two equally normal options (especially if the font 0 (zero) and O (the letter O) are slightly different proportions). But at the same time, it is quite obvious which version of recognition should be correct. For such small specific knowledge of the world, a separate system of rules was made, which can additionally penalize the options that did not like it after the model evaluations.
We'll talk about recognition itself in the next part of this post. Subscribe to the company blog not to miss :)
Source: https://habr.com/ru/post/225215/
All Articles