What do neural networks hide?
The article is a free translation of The Flaw Lurking In Every Deep Neural Net .
A recently published article with an innocuous title is probably the biggest news in the world of neural networks since the invention of the back propagation algorithm . But what is written in it?
The article " Intriguing Properties of Neural Networks " by Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow and Rob Fergus, a team that includes authors from Google’s deep learning project, briefly describes two discoveries in the behavior of neural networks , contrary to what we thought before. And one of them, frankly, is amazing.
The first discovery casts doubt on the assumption that we have so long believed is true that neural networks order data. For a long time it was believed that in multilayer networks at each level, neurons are trained to recognize features for the next layer. Less strong was the assumption that the latter level can recognize essential and usually significant features.
')
The standard way to find out if this is actually the case is to find a set of input data for a particular neuron that maximizes the output value. Whatever the particularity of this set, it is assumed that the neuron responds to it. For example, in a face recognition task, a neuron can react to the presence of an eye or nose in an image. But note - there is no reason why such features should coincide with those that people allocate.
It was found that the peculiarity of an individual neuron can be interpreted as meaningful no more than a random set of neurons. That is, if you randomly select a set of neurons and find images that maximize the output value, these images will be as semantically similar as in the case of a single neuron.
This means that neural networks do not “descramble” data, displaying features on individual neurons, for example, the output layer. The information that the neural network extracts is as distributed among all neurons as it is concentrated in one of them. This is an interesting find, and it leads to another, even more interesting ...
Each neural network has “blind spots” in the sense that there are input data sets that are very close to being classified correctly, which in this case are not recognized correctly.
From the very beginning of the study of neural networks, it was assumed that neural networks are able to make generalizations. That is, if you teach the network to recognize the images of cats using a certain set of their photos, it will be able, provided that it has been trained correctly, to recognize cats that it has not met before.
This assumption included another, even more “obvious” one, according to which if a neural network classifies a cat's photo as a “cat”, then it will also classify a slightly modified version of this image. To create such an image, you need to slightly change the values of some pixels, and as long as these changes are small, people will not notice the difference. Presumably, the computer will not notice it either.
The work of researchers was the invention of the optimization algorithm, which starts with a correctly classified example and tries to find a small change in the input values, which will lead to a false classification. Of course, it is not guaranteed that such a change exists at all - and if the assumption about the sequence of operation of the neural network, mentioned earlier, is true, then the search would not bring results.
However, there are results.
It was proved that for different sets of neural networks and source data it is very likely that such “contradictory examples” can be generated from those that are recognized correctly. Quoting an article:
To be clear, for a person, the original and controversial images look the same, but the network classifies them differently. You may have two photos in which not just two cats are depicted, but even the same cat, from the point of view of a person, but the computer will recognize one correctly and the other will not.

The pictures on the right are classified correctly, the pictures on the left are wrong. In the middle are the differences of two images multiplied by 10 to make the differences visible.
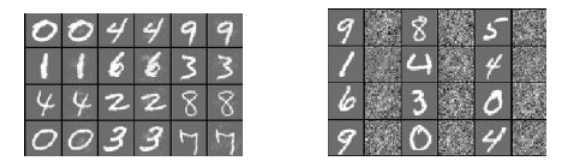
In the left picture, odd columns are classified correctly, and even columns are not. On the right picture, everything is recognized correctly, even the random distortion of the original images presented in even columns. This shows that the changes must be very specific - you need to move in a strictly defined direction in order to find an example of contradiction.
What is even more striking is the kind of universality that seems to unite all these examples. A relatively large proportion of examples are recognized incorrectly by networks trained on common data, but with different parameters (number of layers, regularization or initial coefficients), and networks with the same parameters trained on different data sets.
This is probably the most prominent part of the result: for each correctly classified example, there is another such example, indistinguishable from the original, but classified incorrectly, regardless of which neural network or training sample was used.
Therefore, if you have a photo of a cat, there is a set of small changes that can make the network recognize the cat as a dog - regardless of the network and its training.
Researchers are positive and use conflicting examples to train the network, ensuring its proper operation. They attribute these examples to particularly complex types of training data that can be used to improve the network and its ability to generalize.
However, this discovery seems to be more than just an improved training set.
The first thing you might think about is “Well, what if a cat can be classified as a dog?” . But if you change the situation a little, the question may sound like “What if an unmanned vehicle using a deep neural network does not recognize the pedestrian in front of him and thinks that the road is clear?” .
The consistency and stability of deep neural networks is important for their practical application.
There is also a philosophical question regarding the blind areas mentioned earlier. If the basis of deep neural networks is a biological model, can the result be applied to it? Or, to put it simply, does the human brain contain similar embedded errors? If not, how is it so different from the neural networks trying to copy its work? What is the secret of its stability and consistency?
One explanation may be that this is another manifestation of the curse of dimension . It is known that as the dimension of space grows, the volume of the hypersphere concentrates exponentially on its boundary. Given that the boundaries of solutions are in a very large dimension, it seems logical that the most well-classified examples will be located close to the boundary. In this case, the ability to classify an example is incorrectly very close to the ability to do it correctly - you just need to determine the direction towards the nearest border.
If this explains everything, then it is clear that even the human brain cannot avoid this effect and must somehow cope with it. Otherwise, cats would turn into dogs with alarming regularity.
Neural networks have revealed a new type of instability, and it does not seem that they can make decisions consistently. And instead of “patching holes”, including conflicting examples in training samples, science should investigate and fix the problem. Until this happens, we cannot rely on neural networks where safety is critical ...

A recently published article with an innocuous title is probably the biggest news in the world of neural networks since the invention of the back propagation algorithm . But what is written in it?
The article " Intriguing Properties of Neural Networks " by Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow and Rob Fergus, a team that includes authors from Google’s deep learning project, briefly describes two discoveries in the behavior of neural networks , contrary to what we thought before. And one of them, frankly, is amazing.
The first discovery casts doubt on the assumption that we have so long believed is true that neural networks order data. For a long time it was believed that in multilayer networks at each level, neurons are trained to recognize features for the next layer. Less strong was the assumption that the latter level can recognize essential and usually significant features.
')
The standard way to find out if this is actually the case is to find a set of input data for a particular neuron that maximizes the output value. Whatever the particularity of this set, it is assumed that the neuron responds to it. For example, in a face recognition task, a neuron can react to the presence of an eye or nose in an image. But note - there is no reason why such features should coincide with those that people allocate.
It was found that the peculiarity of an individual neuron can be interpreted as meaningful no more than a random set of neurons. That is, if you randomly select a set of neurons and find images that maximize the output value, these images will be as semantically similar as in the case of a single neuron.
This means that neural networks do not “descramble” data, displaying features on individual neurons, for example, the output layer. The information that the neural network extracts is as distributed among all neurons as it is concentrated in one of them. This is an interesting find, and it leads to another, even more interesting ...
Each neural network has “blind spots” in the sense that there are input data sets that are very close to being classified correctly, which in this case are not recognized correctly.
From the very beginning of the study of neural networks, it was assumed that neural networks are able to make generalizations. That is, if you teach the network to recognize the images of cats using a certain set of their photos, it will be able, provided that it has been trained correctly, to recognize cats that it has not met before.
This assumption included another, even more “obvious” one, according to which if a neural network classifies a cat's photo as a “cat”, then it will also classify a slightly modified version of this image. To create such an image, you need to slightly change the values of some pixels, and as long as these changes are small, people will not notice the difference. Presumably, the computer will not notice it either.
However, it is not.
The work of researchers was the invention of the optimization algorithm, which starts with a correctly classified example and tries to find a small change in the input values, which will lead to a false classification. Of course, it is not guaranteed that such a change exists at all - and if the assumption about the sequence of operation of the neural network, mentioned earlier, is true, then the search would not bring results.
However, there are results.
It was proved that for different sets of neural networks and source data it is very likely that such “contradictory examples” can be generated from those that are recognized correctly. Quoting an article:
For all the networks that we studied, and for each data set we always manage to generate very similar, visually indistinguishable, contradictory examples that are not recognized correctly.
To be clear, for a person, the original and controversial images look the same, but the network classifies them differently. You may have two photos in which not just two cats are depicted, but even the same cat, from the point of view of a person, but the computer will recognize one correctly and the other will not.
The pictures on the right are classified correctly, the pictures on the left are wrong. In the middle are the differences of two images multiplied by 10 to make the differences visible.
In the left picture, odd columns are classified correctly, and even columns are not. On the right picture, everything is recognized correctly, even the random distortion of the original images presented in even columns. This shows that the changes must be very specific - you need to move in a strictly defined direction in order to find an example of contradiction.
What is even more striking is the kind of universality that seems to unite all these examples. A relatively large proportion of examples are recognized incorrectly by networks trained on common data, but with different parameters (number of layers, regularization or initial coefficients), and networks with the same parameters trained on different data sets.
The observations described above suggest that the inconsistency of the examples is something global, and not just the result of retraining .
This is probably the most prominent part of the result: for each correctly classified example, there is another such example, indistinguishable from the original, but classified incorrectly, regardless of which neural network or training sample was used.
Therefore, if you have a photo of a cat, there is a set of small changes that can make the network recognize the cat as a dog - regardless of the network and its training.
What does all this mean?
Researchers are positive and use conflicting examples to train the network, ensuring its proper operation. They attribute these examples to particularly complex types of training data that can be used to improve the network and its ability to generalize.
However, this discovery seems to be more than just an improved training set.
The first thing you might think about is “Well, what if a cat can be classified as a dog?” . But if you change the situation a little, the question may sound like “What if an unmanned vehicle using a deep neural network does not recognize the pedestrian in front of him and thinks that the road is clear?” .
The consistency and stability of deep neural networks is important for their practical application.
There is also a philosophical question regarding the blind areas mentioned earlier. If the basis of deep neural networks is a biological model, can the result be applied to it? Or, to put it simply, does the human brain contain similar embedded errors? If not, how is it so different from the neural networks trying to copy its work? What is the secret of its stability and consistency?
One explanation may be that this is another manifestation of the curse of dimension . It is known that as the dimension of space grows, the volume of the hypersphere concentrates exponentially on its boundary. Given that the boundaries of solutions are in a very large dimension, it seems logical that the most well-classified examples will be located close to the boundary. In this case, the ability to classify an example is incorrectly very close to the ability to do it correctly - you just need to determine the direction towards the nearest border.
If this explains everything, then it is clear that even the human brain cannot avoid this effect and must somehow cope with it. Otherwise, cats would turn into dogs with alarming regularity.
Total
Neural networks have revealed a new type of instability, and it does not seem that they can make decisions consistently. And instead of “patching holes”, including conflicting examples in training samples, science should investigate and fix the problem. Until this happens, we cannot rely on neural networks where safety is critical ...
Source: https://habr.com/ru/post/225095/
All Articles