How to improve user activity segmentation. Yandex Workshop
It is known that user activity provides a variety of useful information for the search engine. In particular, it helps to understand what information the user needs, to highlight his personal preferences, the context of the topic, which the user is currently interested in. Most previous studies on this topic either considered all user actions for a fixed period of time, or divided the activity into parts (sessions) depending on a predetermined period of inactivity (timeout).
Such approaches allow us to distinguish groups of sites that are visited with the same information need. However, it is obvious that the quality of such a simple segmentation is limited, so better quality can be achieved using more complex algorithms. This report is devoted to the problem of automatic separation of user activity into logical segments. Based on the available information, we propose a method for automatically dividing their daily activities into groups based on information needs. I will talk about several segmentation methods and give a comparative analysis of their effectiveness. The proposed algorithms are significantly superior to the methods based on the separation depending on the timeout.
')
User activity in the browser, search engine or on a specific site is a rich source of useful information: the reformulation of requests, navigation before and after the request / visit to the portal. Unfortunately, this information is not structured in any way and is very noisy. The main task is the processing, structuring and cleaning of raw data. I would suggest a method for automatically separating user activity into logically related components.
The user interacts with the search engine and the browser continuously:
It is important to learn to consider these events not only atomically, but also to connect with each other better understanding what moves the user. One event leads another, and if we learn to link them together, we can better understand what drives the user.
In connection with the study of user sessions, several problems arise:
Further, we will need to formulate several definitions and introduce several notation. The protagonist of my story - a browser session - is a sequence of pages visited by the user during the day: D u - (d 1 ....... d n ) . The secondary object — the request session — is a sequence of user-specified queries for one day: Q u - (q 1 ....... q n ) . Vs also want to highlight the logical browser session (and the logical query session) - part of the browser session, consisting of logically related pages, visited with the same information need g :
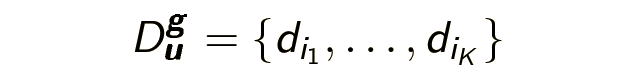
Consider an example of what a user session can be:
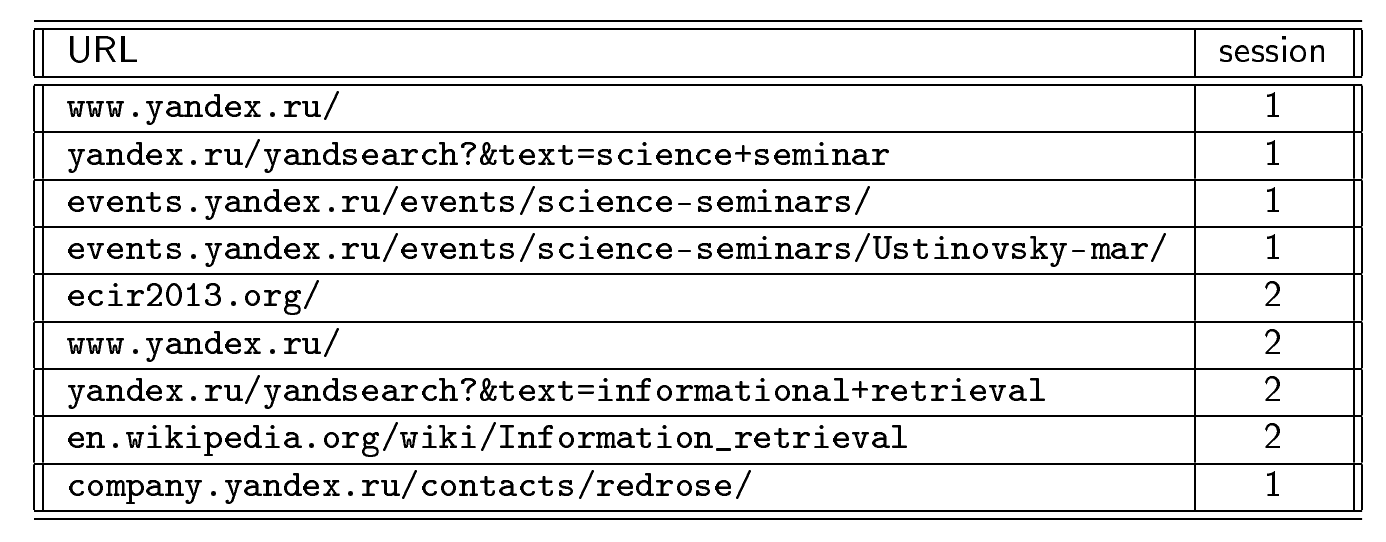
The user enters the search engine page, starts searching for information about scientific seminars, went to the page with a list of all Yandex seminars and learned that on March 28 there will be an interesting report for him and read his announcement. Suddenly, he noticed in the announcement some unknown concept and wanted to see what it was. It follows the link to the site ecir2013.org . At that moment, his information need changed: at the beginning he wanted to see information about the seminars, now he became interested in the conference. Looking at the main page of the conference, he finds another unknown concept - information retrieval. He again goes to the search engine and enters the query [information search] there. In the search, he finds a village page on Wikipedia, reads about it, decides that this topic is interesting to him, and returns to the Yandex portal to see where the seminar will take place, i.e. returns to the original logical session.
Of course, this is an artificial example, but it can be traced to some important features of logical sessions:
Let's make a small digression and see what you can understand by looking at the request sessions: what information about the user can be extracted. Users can ask different queries on the same subject, if you can not immediately find the necessary information. But how will they behave if the answer is not on the first page of the search results, second, third, etc. The graph presents data for the query sessions of different lengths.
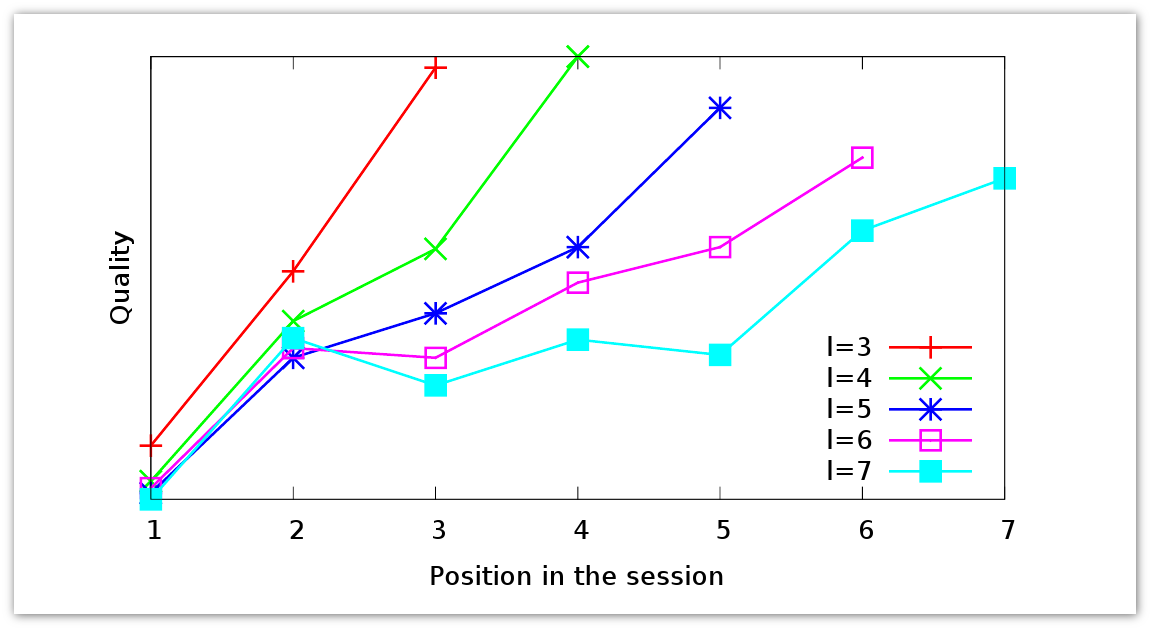
The red request session is three requests long. It can be seen that during the session the quality of the response grows. The user is forming increasingly good answers. The same trend is observed in longer sessions. No matter how long the user has not changed the wording of the request, on average, the quality of the issue improves. The user understands how best to reformulate the query.
As a rule, D u is segmented on the basis of the inactivity period τ (here τ (d) is the moment of discovery d ). d i and d i + 1 belong to one session, respectively, τ (d i + 1 ) - τ (d i ) <τ . This is the most popular and common approach. But it is obvious that it does not work when sessions are interspersed with each other. If the user returns to a topic, from the point of view of this approach, it will already be a new logical session.
The task of logical partitioning of query sessions has already been solved in two papers:
They used different methods and pursued different goals, but the authors of both works argue that their methods can significantly improve the time partition. This motivated me to try to find an algorithm that would work better for browser sessions.
In my research, I decided to raise a few questions:
Raw browser sessions — sequences of pages visited by the user — were used as source data. The segmentation itself is built in two steps:
As a result, we get segmentation:

Consider each of the two steps in more detail. Let's start with the classification. In machine learning, it is always first of all necessary to collect a set of examples. We have marked out with hands a fairly large set of pairs to determine whether they belong to the same logical session. Next, for each evaluation pair ( d, d ' ), we extract the factors.
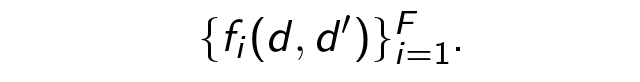
After that we learn the classifier p (d i , d j ) .
As a model for the classifier, we use a decision tree with a logistic loss function. It maximizes the probability of correctly classifying all pairs:
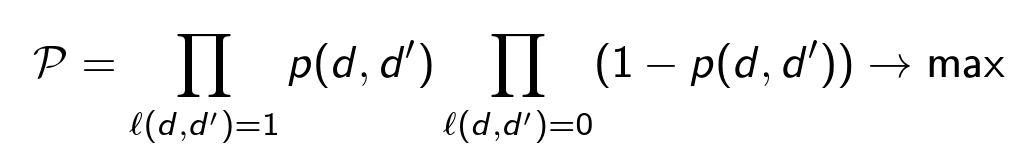
For each pair ( d, d ' ), we extract four types of factors (about 29 in total):
We assume that the classification has been made, and now our goal is to cluster the complete graph, find the partition maximizing the probability (the values of ρ are fixed, the partition changes):
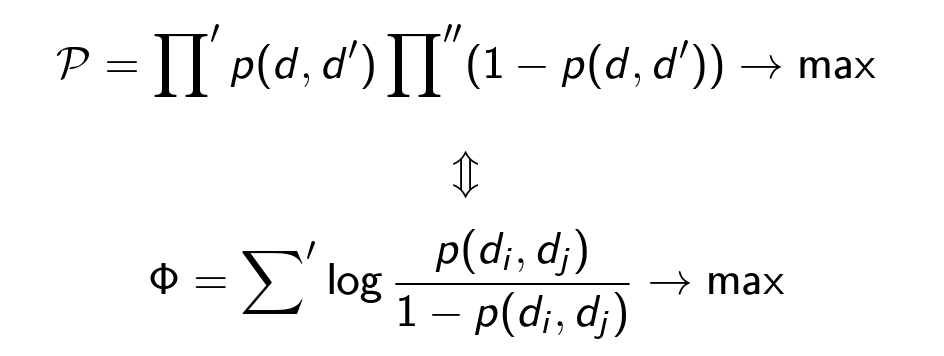
Π '- product over all pairs ( d, d' ) from one cluster;
Σ is the sum over all pairs ( d, d ' ) from different clusters;
Π "- product over all pairs ( d, d ' ) of all clusters.
The statement of the problem looks good, but in this form it turns out to be NP-complete. Those. with a large session size, clustering will be very computationally expensive. Therefore it is necessary to apply various greedy algorithms. When working with greedy algorithms of this type, there is always a balance between speed, quality and area of applicability, which must be selected directly for a specific task. I have broken all the greedy algorithms into two areas of applicability. The first is real-time clustering: each new d document is added to the current cluster ( g 1 , g 2 ) or forms a new ( g new ).
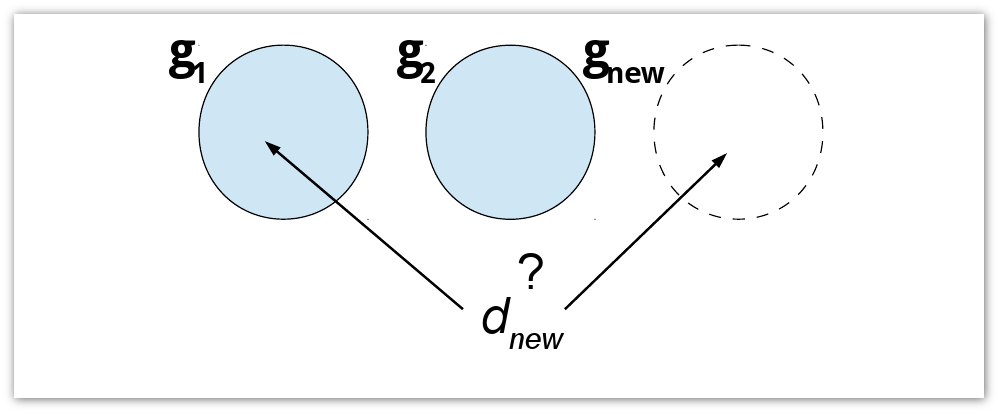
I used three greedy algorithms:
The second type of algorithms works with all the user's daily activity at once, i.e. performs post-clustering. This type is greedy merger . We create N - | D u | clusters. Greedily merge existing clusters, while it is possible to increase Φ .
The complexity of the first algorithm is O (G × N) , where G is the number of segments. All other algorithms have O (N 2 ) complexity .
Anonymized browser logs collected using the toolbar were used as raw data. They contained the addresses of public pages, for each of which the time of the visit, the source of the visit (if the link was followed), the text of the document and the links that the user left them (if it happened) were extracted. For the training sample, each browser session was manually divided by assessors into logical sessions. In total, we had 220 browser logical sessions and 151 thousand pairs for classifier training: 78 thousand from one session and 73 thousand from different ones. The average length of a logical session was 12 pages, and the average number of logical sessions per user per day was 4.4.
The table below shows the quality of time partitioning and classifiers trained on different sets of factors:
There is a method to calculate the contribution of each factor in the process of machine learning. The table below shows the top 10 factors and their contribution.
As we expected, the most important factor is the time between document visits. It is also quite natural that the important role played by the URL and LCS (the length of the common substring URL). Context factors play some role. At the same time there is not a single text factor.
We now turn to experiments in clustering. A measure of the quality of the algorithms is based on the Rand Index . For two segmentations S 1 , S 2 of the set D u, it is equal to the share of equally corresponding pairs of documents:
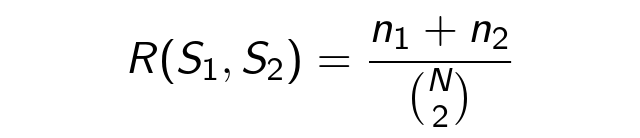
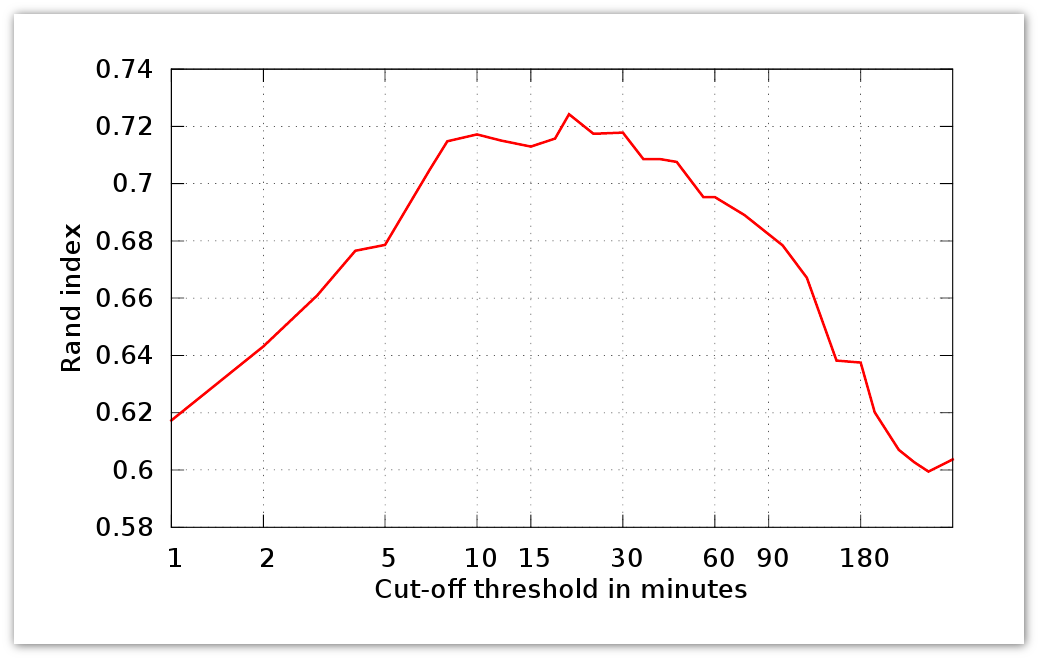
Here n 1 - # pairs from one segment S 1 , S 2 , n 2 - # pairs from different segments S 1 , S 2 , N - # elements in D u . Further, S 1 is an ideal segmentation, and S 2 is an estimated one. R (S 1 , S 2 ) is the accuracy of the corresponding classifier. The graph below shows the Rand Index for a period of τ activity:
Now let's see how the algorithms described above work:
The quality of the classifier corresponding to the greedy merge (0.86) is even higher than that of the original classifier (0.82).
The closest scientific and technical seminar in Yandex will be held on June 10th. It will be devoted to the topic of recommender systems and distributed algorithms .
Such approaches allow us to distinguish groups of sites that are visited with the same information need. However, it is obvious that the quality of such a simple segmentation is limited, so better quality can be achieved using more complex algorithms. This report is devoted to the problem of automatic separation of user activity into logical segments. Based on the available information, we propose a method for automatically dividing their daily activities into groups based on information needs. I will talk about several segmentation methods and give a comparative analysis of their effectiveness. The proposed algorithms are significantly superior to the methods based on the separation depending on the timeout.
')
User activity in the browser, search engine or on a specific site is a rich source of useful information: the reformulation of requests, navigation before and after the request / visit to the portal. Unfortunately, this information is not structured in any way and is very noisy. The main task is the processing, structuring and cleaning of raw data. I would suggest a method for automatically separating user activity into logically related components.
The user interacts with the search engine and the browser continuously:
- sets queries;
- clicks on the documents in the issue;
- requests new pages in the issue;
- moves between pages using links and browser navigation buttons;
- switches between tabs;
- scrolls the pages, leads them with the mouse;
- goes to other search engines.
It is important to learn to consider these events not only atomically, but also to connect with each other better understanding what moves the user. One event leads another, and if we learn to link them together, we can better understand what drives the user.
In connection with the study of user sessions, several problems arise:
- defining the boundaries of logical sessions;
- predicting the next action in the session;
- retrieving session information to assist in the next step;
- simulation of user actions within one session;
- Assessment of hidden data during the session - information need, satisfaction with the session, fatigue.
Further, we will need to formulate several definitions and introduce several notation. The protagonist of my story - a browser session - is a sequence of pages visited by the user during the day: D u - (d 1 ....... d n ) . The secondary object — the request session — is a sequence of user-specified queries for one day: Q u - (q 1 ....... q n ) . Vs also want to highlight the logical browser session (and the logical query session) - part of the browser session, consisting of logically related pages, visited with the same information need g :
Consider an example of what a user session can be:
The user enters the search engine page, starts searching for information about scientific seminars, went to the page with a list of all Yandex seminars and learned that on March 28 there will be an interesting report for him and read his announcement. Suddenly, he noticed in the announcement some unknown concept and wanted to see what it was. It follows the link to the site ecir2013.org . At that moment, his information need changed: at the beginning he wanted to see information about the seminars, now he became interested in the conference. Looking at the main page of the conference, he finds another unknown concept - information retrieval. He again goes to the search engine and enters the query [information search] there. In the search, he finds a village page on Wikipedia, reads about it, decides that this topic is interesting to him, and returns to the Yandex portal to see where the seminar will take place, i.e. returns to the original logical session.
Of course, this is an artificial example, but it can be traced to some important features of logical sessions:
- As a rule, logical sessions are interspersed.
- Some pages participate in several logical sessions.
- User demand is changed before the request is specified.
Let's make a small digression and see what you can understand by looking at the request sessions: what information about the user can be extracted. Users can ask different queries on the same subject, if you can not immediately find the necessary information. But how will they behave if the answer is not on the first page of the search results, second, third, etc. The graph presents data for the query sessions of different lengths.
The red request session is three requests long. It can be seen that during the session the quality of the response grows. The user is forming increasingly good answers. The same trend is observed in longer sessions. No matter how long the user has not changed the wording of the request, on average, the quality of the issue improves. The user understands how best to reformulate the query.
As a rule, D u is segmented on the basis of the inactivity period τ (here τ (d) is the moment of discovery d ). d i and d i + 1 belong to one session, respectively, τ (d i + 1 ) - τ (d i ) <τ . This is the most popular and common approach. But it is obvious that it does not work when sessions are interspersed with each other. If the user returns to a topic, from the point of view of this approach, it will already be a new logical session.
The task of logical partitioning of query sessions has already been solved in two papers:
- P. Boldi et al. The Query-flow Graph: Model and Applications.
- R. Jones et al. Beyond the Session Timeout: Automatic Hierarchical Segmentation in Query Logs.
They used different methods and pursued different goals, but the authors of both works argue that their methods can significantly improve the time partition. This motivated me to try to find an algorithm that would work better for browser sessions.
In my research, I decided to raise a few questions:
- Is it possible to clarify the logical partitioning of query sessions to the level of browser sessions?
- How qualitative is the approach based on the period of inactivity?
- How do different clustering algorithms affect the quality of segmentation?
- What sources of factors are important for logical segmentation?
Method
Raw browser sessions — sequences of pages visited by the user — were used as source data. The segmentation itself is built in two steps:
- Pairwise classification. We predict whether with one goal the user visited a couple of pages ( d i , d j ): we learn the function p (d i , d j ) ∈ [0; 1], estimating the probability that d i , d j belong to one logical session.
- Clustering For different estimates of p (d i , d j ) cluster the complete graph on N vertices d i with edge weights p (d i , d j ) into strongly connected components
As a result, we get segmentation:
Consider each of the two steps in more detail. Let's start with the classification. In machine learning, it is always first of all necessary to collect a set of examples. We have marked out with hands a fairly large set of pairs to determine whether they belong to the same logical session. Next, for each evaluation pair ( d, d ' ), we extract the factors.
After that we learn the classifier p (d i , d j ) .
As a model for the classifier, we use a decision tree with a logistic loss function. It maximizes the probability of correctly classifying all pairs:
For each pair ( d, d ' ), we extract four types of factors (about 29 in total):
- URL based factors.
- Text factors.
- Sessional factors. The time between visits d, d ' , the number of documents between them, whether the link was followed.
- Context generalizations. Same as in the previous three paragraphs, only the calculation for document d " , preceding d ' .
We assume that the classification has been made, and now our goal is to cluster the complete graph, find the partition maximizing the probability (the values of ρ are fixed, the partition changes):
Π '- product over all pairs ( d, d' ) from one cluster;
Σ is the sum over all pairs ( d, d ' ) from different clusters;
Π "- product over all pairs ( d, d ' ) of all clusters.
The statement of the problem looks good, but in this form it turns out to be NP-complete. Those. with a large session size, clustering will be very computationally expensive. Therefore it is necessary to apply various greedy algorithms. When working with greedy algorithms of this type, there is always a balance between speed, quality and area of applicability, which must be selected directly for a specific task. I have broken all the greedy algorithms into two areas of applicability. The first is real-time clustering: each new d document is added to the current cluster ( g 1 , g 2 ) or forms a new ( g new ).
I used three greedy algorithms:
- Maximum credibility of the last page. d g - the last page of the g segment. All p (d g , d new ) <1/2, therefore, we are starting a new session. Otherwise, we add d new to the session with the maximum probability.
- Maximum credibility of all pages. All p (d, d new ) <1/2, therefore we are starting a new session. Otherwise, we add d new to the session containing the document with the maximum probability.
- Greedy addition. Add d new to maximize Φ growth. If Φ always decreases for all g , we start a new segment.
The second type of algorithms works with all the user's daily activity at once, i.e. performs post-clustering. This type is greedy merger . We create N - | D u | clusters. Greedily merge existing clusters, while it is possible to increase Φ .
The complexity of the first algorithm is O (G × N) , where G is the number of segments. All other algorithms have O (N 2 ) complexity .
Experiments
Anonymized browser logs collected using the toolbar were used as raw data. They contained the addresses of public pages, for each of which the time of the visit, the source of the visit (if the link was followed), the text of the document and the links that the user left them (if it happened) were extracted. For the training sample, each browser session was manually divided by assessors into logical sessions. In total, we had 220 browser logical sessions and 151 thousand pairs for classifier training: 78 thousand from one session and 73 thousand from different ones. The average length of a logical session was 12 pages, and the average number of logical sessions per user per day was 4.4.
The table below shows the quality of time partitioning and classifiers trained on different sets of factors:
| A set of factors | Temporary partition | Everything | Without context | No text |
| F-measure | 80% | 83% | 83% | 82% |
| Accuracy | 72% | 82% | 81% | 81% |
There is a method to calculate the contribution of each factor in the process of machine learning. The table below shows the top 10 factors and their contribution.
| Rk | Factor | Glasses |
| one | time between d 1 and d 1 | one |
| 2 | LCS | 0.58 |
| 3 | LCS / length ( url 1 ) | 0.40 |
| four | LCS / length ( url 2 ) | 0.40 |
| five | # pages between d 1 b d 1 | 0.33 |
| 6 | trigram URL match | 0.32 |
| 7 | context LCS / length ( url 1 ) | 0.32 |
| eight | one host | 0.22 |
| 9 | LCS / length ( url 2 ) | 0.20 |
| ten | context LCS | 0.20 |
As we expected, the most important factor is the time between document visits. It is also quite natural that the important role played by the URL and LCS (the length of the common substring URL). Context factors play some role. At the same time there is not a single text factor.
We now turn to experiments in clustering. A measure of the quality of the algorithms is based on the Rand Index . For two segmentations S 1 , S 2 of the set D u, it is equal to the share of equally corresponding pairs of documents:
Here n 1 - # pairs from one segment S 1 , S 2 , n 2 - # pairs from different segments S 1 , S 2 , N - # elements in D u . Further, S 1 is an ideal segmentation, and S 2 is an estimated one. R (S 1 , S 2 ) is the accuracy of the corresponding classifier. The graph below shows the Rand Index for a period of τ activity:
Now let's see how the algorithms described above work:
| Method | Rand index | Complexity |
| Temporal | 0.72 | - |
| Max. credibility last pages | 0.75 | O (N × G) |
| Max. credibility of all pages | 0.79 | O (N 2 ) |
| Greedy add | 0.82 | O (N 2 ) |
| Greedy merger | 0.86 | O (N 2 ) |
The quality of the classifier corresponding to the greedy merge (0.86) is even higher than that of the original classifier (0.82).
findings
- A method for automatic processing of browser logs is proposed, which clarifies the partitioning of query logs.
- We have reduced the segmentation problem to well studied classification and clustering problems.
- Although the temporal approach is quite good, more complex clustering algorithms significantly surpass it.
- Contextual and textual factors are much less important for determining the logical links between pages within the same session than factors based on session data and URL matches.
The closest scientific and technical seminar in Yandex will be held on June 10th. It will be devoted to the topic of recommender systems and distributed algorithms .
Source: https://habr.com/ru/post/224719/
All Articles