Why in search without linguistics can not do?
Today we will talk about the role of linguistics in Internet search. To put this in context, I’ll start by connecting linguists and a large search company, for example, Yandex (more than 5,000 people), Google (more than 50,000 people), Baidu (more than 20,000). ). From a third to half of these people work directly on the search. The linguists within these companies are roughly equally divided between the search and the rest of the directions - news, translation, etc.
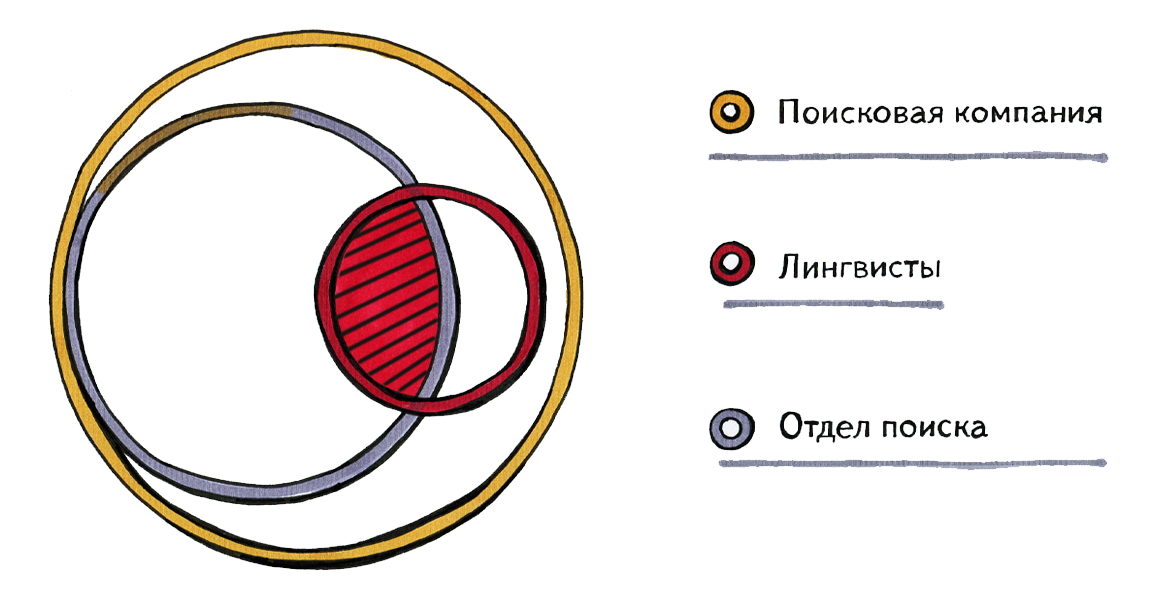
Today I will talk about the part of linguists that intersects with the search. In the diagram, it is indicated by hatching. Perhaps, in Google and other companies, everything is arranged a little differently than in our country, however, the general picture is approximately as follows: linguistics is an important, but not a defining, direction of the work of search companies. Another important addition: in life, of course, the boundaries are vague - it is impossible to say, for example, where linguistics ends and machine learning begins. Every search linguist is a little involved in programming, a little in machine learning.
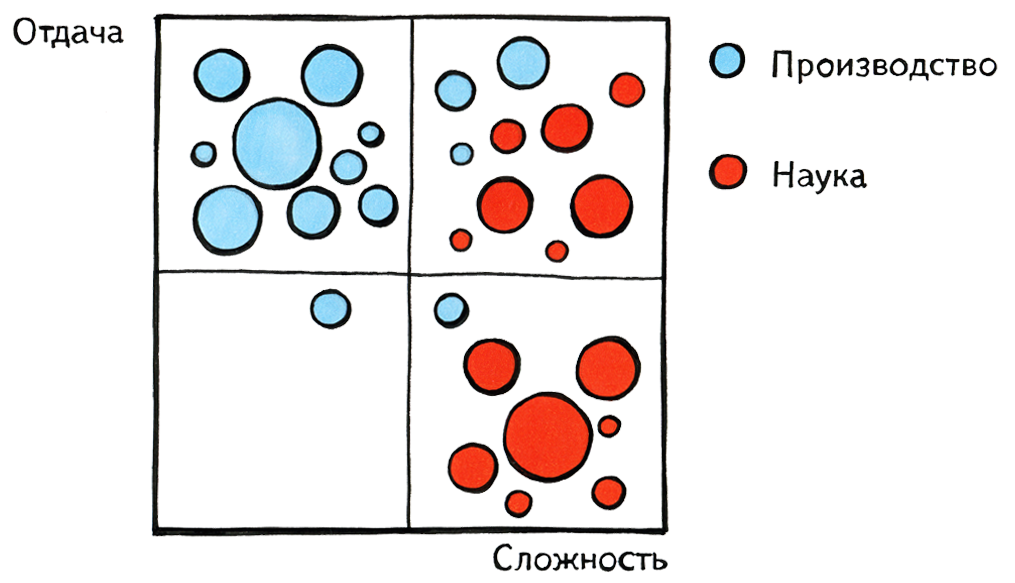
Since there are mainly people associated with science here, I would like to briefly describe the difference between the world of science and the world of production. Here I drew a pseudograph: on the x axis, the complexity of the problems to be solved is shown, on the y axis - the return on these tasks, whether in money or in the aggregate benefit for humanity. People involved in production love to choose for themselves the tasks in the upper left quadrant — simple and high-impact, and people of science — tasks from the right edge, complex and not yet solved by anyone, but with a fairly arbitrary distribution of returns. Somewhere in the upper right quadrant they are found. I would very much like to hope that it is exactly there that the tasks that we are dealing with are located.
')
The last thing I wanted to mention in this introduction: science and production exist on two completely different time scales. To make it clear what I'm talking about, I wrote out a few dates for the emergence of companies, ideas or technologies that are now considered important. Search companies appeared about fifteen years ago, Facebook and Twitter - less than ten. At the same time, the works of Noam Chomsky belong to the 1950s, the “meaning-text” model, if I understand correctly, to the 1960s, latent semantic analysis to the 1980s. By the standards of science, this is quite recently, but, on the other hand, this is a time when it is not that the Internet search, the Internet itself as such has not yet existed. I do not want to say that science has ceased to develop, it just has its own timeline.
We now turn to the topic. To understand the role of linguists in the search, let's first try to invent your own search and check how it works. Here we will understand that this task is not as simple as many think, and we will get acquainted with the data structures that will be useful to us later.
Intuitively, users imagine that modern search engines search for “just” by keywords. The system finds documents in which all the keywords from the request are found, and somehow arranges them. For example, by popularity. Such an approach is sometimes contrasted with a “smart”, “semantic” search, which turns out to be much more qualitative due to the use of some special knowledge. This picture is not very similar to the truth, and in order to understand why, let's try to mentally do a similar “keyword search” and see what it can and cannot find.
Take for clarity, only three documents - informational (excerpt from Wikipedia), the text of the shops and the random anecdote:
There are not three, but three billion such documents in a real search engine, so we cannot afford every time the user sets his request, even just to look at each of them. We need to put them in some kind of data structure that allows you to search faster. In this data structure for each word it is indicated in which documents it appears. For example, from several words of these three documents we get the following index:
The first digit indicates the number of the document in which the word occurs, the second indicates the sentence, and the third indicates the position in it.
Now we will try to answer the user's search query. First request: [grocery stores]. Everything worked, the search found a second document. Take a more complex query: [grocery stores in Moscow]. The search found these words in all documents, and it is not even clear which one of them wins. Request [Moscow Metro]. The word "Moscow" does not occur anywhere, and the word "metro" is in the third document with anecdotes. At the same time in the first document there is the word "Metropolitan". It turns out that in the first case we found what we were looking for, in the second one we found too many, and now we have to organize the found correctly, and in the third we did not find anything useful because we didn’t know that the metro and the metro were It is the same. Here we saw two typical problems of Internet search: completeness and ranking.
It so happens that the user finds a lot of documents, and the search engine shows something like “there were 10 million answers”. This in itself is not a problem, the problem is to organize them correctly and be the first to give the answers that most closely match their request. This is the problem of ranking, the main problem of Internet search. Completeness is also a serious problem. If we do not find the only relevant document for a search query containing the word “metro” just because it does not contain the word “metro”, but there is the word “metro”, this is not very good.
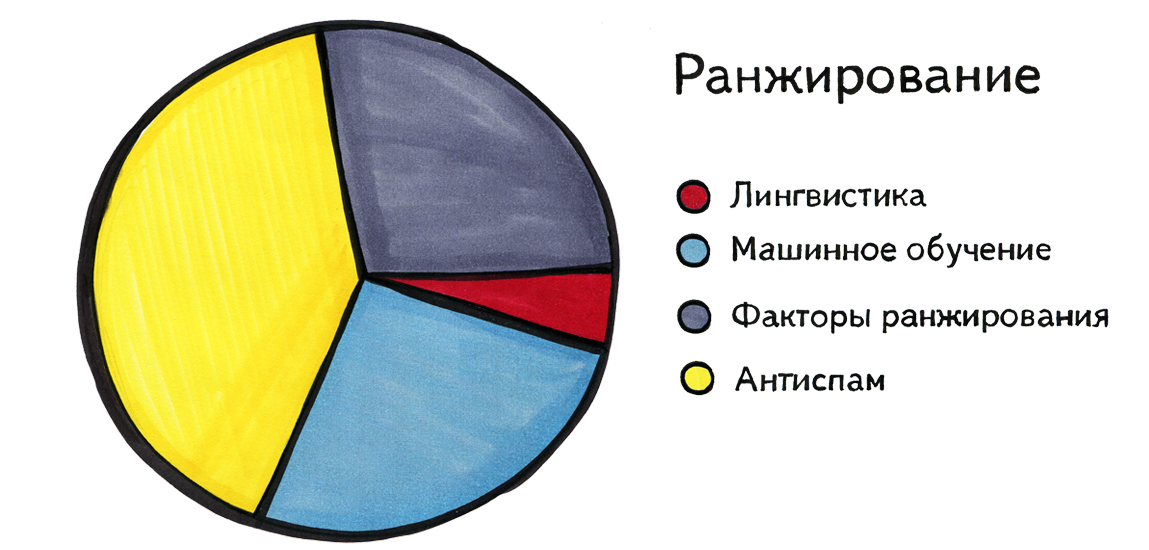
Now consider the role of linguistics in solving these two problems. The diagram below does not contain numbers; here are general feelings: linguistics helps in ranking as long as; so-called ranking factors, machine learning and antispam play an important role in ranking. Now I will explain these terms. What is a "ranking factor"? We can notice that some characteristics of a request, or a document, or a pair of “request – document” clearly should influence the order in which we must present them to the person, but it is not known in advance how exactly and how much. Such characteristics include, for example, the popularity of the document, then, whether all the words of the query are found in the text of the document, and where exactly, how many times and with which keywords are referred to this document, the length of the URL, the number of special characters in it, etc. . “Ranking Factor” is not a common name; in Google, if I am not mistaken, it is called signals .
You can think of several thousands of various similar ranking factors, and the system has the ability to count them for each query for all documents found by this query. Intuitively, we can conclude that such a factor probably should increase the relevance of the document (for example, its popularity), and another, probably, decrease (for example, the number of slashes in the page address). But no man can combine thousands of factors into a single procedure or formula that would work best, so machine learning comes into play. What it is? Special people pre-select some requests and assign estimates to documents that are on each of them. After that, the goal of the machine is to choose a formula that will link the ranking factors so that the result of the calculations using this formula will be as close as possible to the estimates that people have invented. That is, the machine learns to rank as people do.
Another important thing in ranking is antispam. As you know, the amount of spam on the Internet is monstrous. Recently, he rarely catches the eye than a few years ago, but this did not happen by itself, but as a result of the active actions of the anti-spam employees of various companies.
Why linguistics is not very helpful in ranking? Of course, maybe there is no good answer to this question, but the fact is that the industry simply did not wait for some of its genius. But it still seems to me that there is a more substantial reason. It would seem that the deeper the machine understands the meaning of texts and documents and queries, the better it can answer, and it is linguistics that can equip it with a similar deep understanding. But the problem is that life is very diverse, and people ask questions that do not drive in any framework. Any attempt to find some kind of scheme, a comprehensive classification, to build a single ontology of queries, or their universal parser, usually fails.
Now I will show a few examples of real requests, about which even a person stumbles, not to mention a car. They were asked to search for real people, in fact. For example: [dating in Moscow without registration]. It is not entirely clear what registration is meant. But a person who is used to asking queries like [how to assemble a table with his own hands] generates a query [with what he can do with clearing the drainage system]. Often there are requests that even a person is not able to understand, and you need to rank the answers to them.
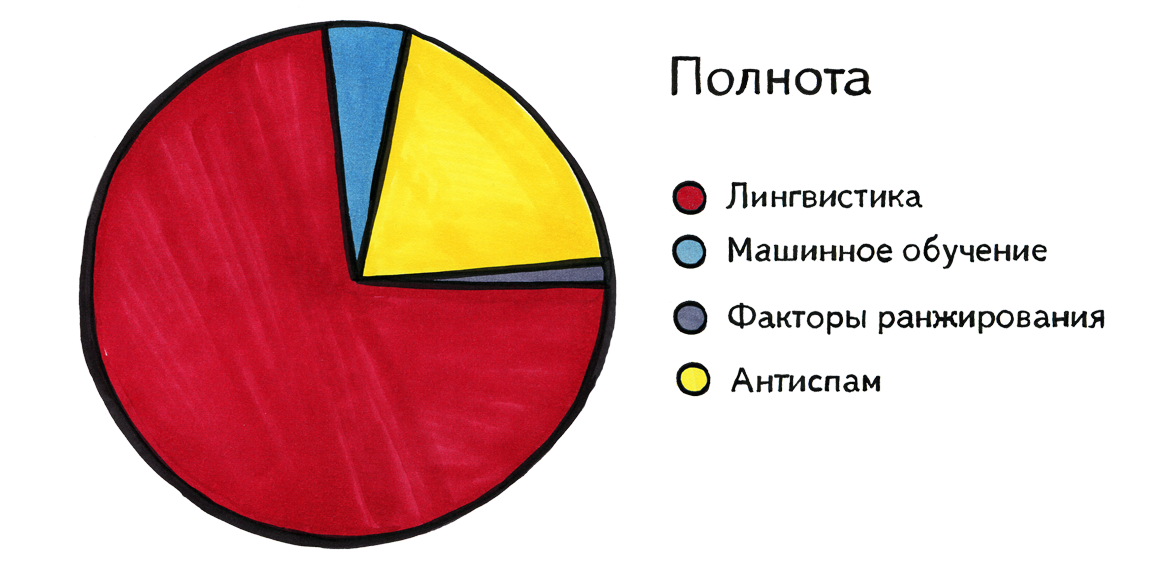
Let us turn to the problem of completeness. There is a striking difference here, because for the most part it is solved by means of linguistics. Some ranking factors can also help. For example, a search engine may include such a rule: if such a ranking factor for a query-document pair has a value above a certain threshold, then show this document on this query, even if not all words were found in it. For example, the request begins with the word "Facebook", and then something completely incomprehensible is written and not found anywhere. And we still show the facebook.com home page in the hope that the user had exactly this in mind, and next to him he wrote, say, the unknown Facebook name in Arabic. And machine learning also somehow affects the completeness, for example, it helps to formulate such rules. But the main role is played by linguistics.
I will give some examples of why completeness cannot be achieved without the use of linguistics. First of all, we need to be able to generate different forms of words, to understand, for example, that “gone” and “gone” are the forms of the same word. You need to know that "Moscow" and "Moscow" are related words, and that the words "surfing" and "surfer" are related to each other, and that the letters "" and "e" are often the same . We need to be able to understand requests in Internet jargon, or written using non-alphabetic characters, and to understand which words of the Russian language correspond to them.
It is important to be able to match words, phrases and texts in different languages. The user can specify the request [Head of the Verkhovna Rada of Ukraine], and in the document of interest to him, the name of this state body is found only in Ukrainian. It would be nice to be able to respond to a query set in one language, with results in other languages - related or not. In fact, the more we look at user requests, the more we understand that any search is a translation from the request language into the document language.
Now let's talk more about how linguists help solve search-related tasks. I will use the concept of a linguistic pyramid, in which text analysis is divided into several levels: lexical (splitting text into words), morphological (changing words), syntactic (combination of words with each other in phrases and sentences), semantic (meaning of words and sentences) and pragmatic (the goal of generating the utterance and its external context, including non-linguistic).

Let's start with the lexical level. What is the word? Search companies in 1995 had to answer this question at least somehow to be able to get started. For example, define a word as a sequence of alphabetic characters, bounded on the left and on the right by spaces or punctuation marks. Unfortunately, this is often incorrect, especially if we speak not about words in the usual sense, but about indivisible pieces of text found on the Internet. Among them, for example, Internet addresses, dates, phone numbers, etc. are common. It is often difficult to answer the question where one word ends and another begins. Here, for example, the amount with the indication of currency is one word or two? We need to somehow decide on this. Currency symbols, phone number formats in different countries, and similar things may seem very far from linguistics, but the problem is that the rough reality affects the most basic things, even the division of text into words.
In addition to the frequently mentioned cases already mentioned - email addresses, phone numbers, dates - there are other examples of complex, non-trivial "words". Here is an example of a phrase that would be convenient to consider in a search in one word: “the plant named after Frunze”. In this case, it would be good to consider the “plant them. Frunze "form of the same" word ". The request [New York] is often written without a hyphen, but this does not turn it into two separate words: it would be wrong to show documents on it, where the words "York" and, say, "New Hampshire" meet separately.
It happens that punctuation and special characters are an important part of a word. The name of the radio station can be written by users: “Europe +”, and the TV channel may be called “1 + 1”. There is even a band in the world, with a wonderful name that no search engine finds in this form: "#####". Similar problems often arise when searching for the names of variables and functions, as well as other requests from programmers. Why it happens? Because someone at the dawn of search engines decided that the characters%, _, # and + will not be considered letters.

It would seem that now we have gained the necessary experience, we know about all these special cases, and we can divide the text into words much more correctly, but the problem is that the search index is ready. If now we change our understanding of what a word is, we will need to make changes to all the programs that work with this index and reindex the entire Internet, that is, billions of documents. This means that any error in lexical analysis is very expensive to correct. So, the lexical analysis of documents should be implemented as correctly as possible from the very first version, and this requires wisdom, which no one else had fifteen years ago.
Let us turn to the morphological analysis. What do we want from him? First of all, we want to know what word forms the dictionary words have. Fortunately, this problem has already been solved for the main languages of the world. The words in them are already divided into parts of speech, declensions, conjugations and similar categories, and we know how they vary in cases, by gender, by time, etc. The situation is worse with proper names: there are many of them, and there are practically no dictionaries of proper names. At the same time, it would be good to know that “Moscow” and “to Moscow” are one and the same thing, it would be good to know how “Lower Sychi” are leaning, not to mention first and last names, of which there are quite a lot. It is especially difficult with the names, and this is an important case: a particular sin of the search engine - if a person is looking for and cannot find himself. In addition, there are words that are not found in any dictionary, and which are constantly changing: the names of brands, organizations, firms. So, you need to be able to automatically assign an unfamiliar word to one of the word-formation models known to us.
Further, we encounter another interesting problem, which is rarely found outside the search, but rarely: which forms of the word are close to each other, and which are far away? For example, if the query specifies the word “to go,” do you need to search for documents using it, where are the words “walking” or “walking”? Most likely, the person making the request meant the word “go” in exactly this form. Another example: dig and swarm. The word “dig” in the query will most likely meet in the context of “how to dig a ditch”, and the word “swarm” can be a form of the word “dig”, “swarm” and the name “Swarm”. Even if it is really a form of the word “dig”, its use in the text, quite possibly, has nothing to do with the user's request. Not the fact that we have to look even for the main form of the word used in the query. For example, the word “houses” was found in the query - do you need to search for documents with the word “house”? TV program "House-2", the magazine "Your House" ...
We are not dealing with a single language, and this makes everything only more complicated. There is, for example, the Ukrainian noun “meta”, from which it is possible to form the forms “methi” and “meta”, which coincide with the Russian forms of the verb “revenge”. It turns out a complete mess. The problem is that the Ukrainian word “meta” is the name of the Ukrainian Internet portal, and therefore can be found in the Russian text. That is, we need to be able to recognize languages and understand the language in which the document is written, and, ideally, every word in this document.
Sometimes, by context or by some other means, it is possible to make a withdrawal of homonymy and understand which word is being spoken about. But you need to understand that this process does not always have one hundred percent accuracy and completeness, and it cannot be implemented without attracting any data about the real world. A computer, for example, is very difficult to understand the phrase “How many goals does Pavlyuchenko have?”: Because to understand that the shape of “heads” comes from the word “goal” and not “head”, you need to know who Pavlyuchenko is. This example stumbles over most homonymy removal algorithms.

A separate topic - synonyms. It is not entirely clear to which level of the linguistic pyramid it refers, because it is close to both semantics and morphology. We can consider synonyms as an extension of morphology: if we believe that a word can occur in a request in one form, and in a found document in another, why not do the same with synonyms. For example, to issue documents with the word “grandmothers” with the word “old women”, in the request “hippopotamus” - in the answer “hippo”, “erysipelas” - “muzzle”, and so on. The question is how to search for them automatically, because you cannot manually make all such pairs.
One way is to look for words that are often found in the same contexts. Here we are faced not so much with linguistic, as with programmer problems. For example, to find all pairs of words that occur in the same contexts, we first need to multiply by itself a matrix, having dimensions of about 1.000.000.000 * 1.000.000.000, in which it is written which word and how often it occurs in what contexts. This is not a trivial operation. Let's say that such amounts of data basically cannot fit on one computer. In addition, I want these calculations to take place as quickly as possible, because in order to achieve the required quality, we need to try out many of its options, which are slightly different from each other.
Most pairs of synonyms do not look like “grandmothers” - “old women”, but consist of words with similar sound. It may not be entirely correct to use the word “synonyms” to designate such pairs, but in the absence of a better one, I will use this term. For example, there are various permissible spellings of the same word, there are transliterations, there are words that can be written both together and separately. Special accounting of such patterns helps to find more synonyms and make it more accurate.
The next problem: synonyms do not really exist, because there are no two words that completely replace each other: “my grandmother” and “my old woman” are completely different things, “Hippo's cat” cannot be replaced with “Hippo cat”, and the word "Erysipelas" in the sense of illness - the word "muzzle". So, synonyms should be context-sensitive, that is, synonymy relations are possible not between a pair of words, but a pair of words in some context . Fully the task of accounting context in synonymy has not yet been solved. Sometimes it is impossible to do without a fairly complex context: in one example II can mean “Second”, and in the other - “Second”. The words "eighty-sixth" can mean both the number 86 and the number 1986.

A separate problem - typos. Is it correct to consider words written with misprints, synonyms of words written correctly, or should they be treated in a special way? There is no unequivocal answer, but, apparently, it is necessary to act differently with typos, for example, to correct the user's error explicitly. Moreover, even the correction of typos in common words is a hell of a difficult task. For example, many correctly written Ukrainian words can be easily mistaken for a typo in a Russian-language query. There are even requests like [hardly or hardly], the meaning of which is completely lost if they correct the spelling. Many surnames of search engines with enviable regularity correct for similar surnames of celebrities, such actions can easily spoil the mood of the user.
We proceed to parse. I was a little cunning when I illustrated the concept of a linguistic pyramid with the help of a trapezium, because in a real search the pyramid does not look like that. The level of parsing is very small and practically nothing is done on it. I have a few suggestions about why this is so. The first is a conflict of data structures. Parsing a tree structure of data with complex links between parts of a sentence, etc. , - . , , , , . , , , . : . , , .
, , . , - – “if”, «», “the”, , , . , . , «» , , , . , - . , [ ] [ ] — . - , , “The The” [ ].

. , - , , . : «» : , , , .. – , . – , . , «», «», «», «». , , . – «» . , «» , . , .
, , :
, , , , - . – - . . – , : , , n- , . , . .

. , , , . , . , , , , , . , «» « ». , , , «» – . , , .
, , , - , . , « » , ; «» , . , , . [] , , .. , , . - .

, , . — , , , . , “sentiment analysis”: , , , . , , , , , - - , - - , , . “rocket science”, . , .
– . [ ] [ ], . «», « ». , , «».
– . , , , , , . , , .
, . , . , , . , , , , , , 10. , : . , . , – , , , .
, . , , . «» , , . ? -, : , « » ( ), « » — ( ), .
– , . . , . , ( , , «» , - , ). . , «» , . , , , .
– , , , . , , – . , , . , « ». , : [ ] ..
, , , , - . , . , , , , , . – . . : , , - , . , .
Hopefully, science will continue to move forward just as slowly and unstoppably.
Today I will talk about the part of linguists that intersects with the search. In the diagram, it is indicated by hatching. Perhaps, in Google and other companies, everything is arranged a little differently than in our country, however, the general picture is approximately as follows: linguistics is an important, but not a defining, direction of the work of search companies. Another important addition: in life, of course, the boundaries are vague - it is impossible to say, for example, where linguistics ends and machine learning begins. Every search linguist is a little involved in programming, a little in machine learning.
Since there are mainly people associated with science here, I would like to briefly describe the difference between the world of science and the world of production. Here I drew a pseudograph: on the x axis, the complexity of the problems to be solved is shown, on the y axis - the return on these tasks, whether in money or in the aggregate benefit for humanity. People involved in production love to choose for themselves the tasks in the upper left quadrant — simple and high-impact, and people of science — tasks from the right edge, complex and not yet solved by anyone, but with a fairly arbitrary distribution of returns. Somewhere in the upper right quadrant they are found. I would very much like to hope that it is exactly there that the tasks that we are dealing with are located.
')
The last thing I wanted to mention in this introduction: science and production exist on two completely different time scales. To make it clear what I'm talking about, I wrote out a few dates for the emergence of companies, ideas or technologies that are now considered important. Search companies appeared about fifteen years ago, Facebook and Twitter - less than ten. At the same time, the works of Noam Chomsky belong to the 1950s, the “meaning-text” model, if I understand correctly, to the 1960s, latent semantic analysis to the 1980s. By the standards of science, this is quite recently, but, on the other hand, this is a time when it is not that the Internet search, the Internet itself as such has not yet existed. I do not want to say that science has ceased to develop, it just has its own timeline.
We now turn to the topic. To understand the role of linguists in the search, let's first try to invent your own search and check how it works. Here we will understand that this task is not as simple as many think, and we will get acquainted with the data structures that will be useful to us later.
Intuitively, users imagine that modern search engines search for “just” by keywords. The system finds documents in which all the keywords from the request are found, and somehow arranges them. For example, by popularity. Such an approach is sometimes contrasted with a “smart”, “semantic” search, which turns out to be much more qualitative due to the use of some special knowledge. This picture is not very similar to the truth, and in order to understand why, let's try to mentally do a similar “keyword search” and see what it can and cannot find.
Take for clarity, only three documents - informational (excerpt from Wikipedia), the text of the shops and the random anecdote:
- Novokosino is a district in the city of Moscow and the metro station of the same name, the end of the Kalininskaya line. It follows the station "Novogireevo".
- Shops "Crossroads." Sale of food. Overview of the range. Addresses of shops. Information for customers.
- Police caught a group of scammers selling diplomas in the subway. “We had to let them go,” said Sergeant Ivanov, Ph.D.
There are not three, but three billion such documents in a real search engine, so we cannot afford every time the user sets his request, even just to look at each of them. We need to put them in some kind of data structure that allows you to search faster. In this data structure for each word it is indicated in which documents it appears. For example, from several words of these three documents we get the following index:
| the shops | 2. 1. 1 |
| products | 2. 2. 2 |
| at | 1. 1. 3, 3. 1 .7 |
| Moscow | 1. 1. 5 |
| underground | 3. 1. 8 |
| sergeant | 3. 2. 9 |
The first digit indicates the number of the document in which the word occurs, the second indicates the sentence, and the third indicates the position in it.
Now we will try to answer the user's search query. First request: [grocery stores]. Everything worked, the search found a second document. Take a more complex query: [grocery stores in Moscow]. The search found these words in all documents, and it is not even clear which one of them wins. Request [Moscow Metro]. The word "Moscow" does not occur anywhere, and the word "metro" is in the third document with anecdotes. At the same time in the first document there is the word "Metropolitan". It turns out that in the first case we found what we were looking for, in the second one we found too many, and now we have to organize the found correctly, and in the third we did not find anything useful because we didn’t know that the metro and the metro were It is the same. Here we saw two typical problems of Internet search: completeness and ranking.
It so happens that the user finds a lot of documents, and the search engine shows something like “there were 10 million answers”. This in itself is not a problem, the problem is to organize them correctly and be the first to give the answers that most closely match their request. This is the problem of ranking, the main problem of Internet search. Completeness is also a serious problem. If we do not find the only relevant document for a search query containing the word “metro” just because it does not contain the word “metro”, but there is the word “metro”, this is not very good.
Now consider the role of linguistics in solving these two problems. The diagram below does not contain numbers; here are general feelings: linguistics helps in ranking as long as; so-called ranking factors, machine learning and antispam play an important role in ranking. Now I will explain these terms. What is a "ranking factor"? We can notice that some characteristics of a request, or a document, or a pair of “request – document” clearly should influence the order in which we must present them to the person, but it is not known in advance how exactly and how much. Such characteristics include, for example, the popularity of the document, then, whether all the words of the query are found in the text of the document, and where exactly, how many times and with which keywords are referred to this document, the length of the URL, the number of special characters in it, etc. . “Ranking Factor” is not a common name; in Google, if I am not mistaken, it is called signals .
You can think of several thousands of various similar ranking factors, and the system has the ability to count them for each query for all documents found by this query. Intuitively, we can conclude that such a factor probably should increase the relevance of the document (for example, its popularity), and another, probably, decrease (for example, the number of slashes in the page address). But no man can combine thousands of factors into a single procedure or formula that would work best, so machine learning comes into play. What it is? Special people pre-select some requests and assign estimates to documents that are on each of them. After that, the goal of the machine is to choose a formula that will link the ranking factors so that the result of the calculations using this formula will be as close as possible to the estimates that people have invented. That is, the machine learns to rank as people do.
Another important thing in ranking is antispam. As you know, the amount of spam on the Internet is monstrous. Recently, he rarely catches the eye than a few years ago, but this did not happen by itself, but as a result of the active actions of the anti-spam employees of various companies.
Why linguistics is not very helpful in ranking? Of course, maybe there is no good answer to this question, but the fact is that the industry simply did not wait for some of its genius. But it still seems to me that there is a more substantial reason. It would seem that the deeper the machine understands the meaning of texts and documents and queries, the better it can answer, and it is linguistics that can equip it with a similar deep understanding. But the problem is that life is very diverse, and people ask questions that do not drive in any framework. Any attempt to find some kind of scheme, a comprehensive classification, to build a single ontology of queries, or their universal parser, usually fails.
Now I will show a few examples of real requests, about which even a person stumbles, not to mention a car. They were asked to search for real people, in fact. For example: [dating in Moscow without registration]. It is not entirely clear what registration is meant. But a person who is used to asking queries like [how to assemble a table with his own hands] generates a query [with what he can do with clearing the drainage system]. Often there are requests that even a person is not able to understand, and you need to rank the answers to them.
Let us turn to the problem of completeness. There is a striking difference here, because for the most part it is solved by means of linguistics. Some ranking factors can also help. For example, a search engine may include such a rule: if such a ranking factor for a query-document pair has a value above a certain threshold, then show this document on this query, even if not all words were found in it. For example, the request begins with the word "Facebook", and then something completely incomprehensible is written and not found anywhere. And we still show the facebook.com home page in the hope that the user had exactly this in mind, and next to him he wrote, say, the unknown Facebook name in Arabic. And machine learning also somehow affects the completeness, for example, it helps to formulate such rules. But the main role is played by linguistics.
I will give some examples of why completeness cannot be achieved without the use of linguistics. First of all, we need to be able to generate different forms of words, to understand, for example, that “gone” and “gone” are the forms of the same word. You need to know that "Moscow" and "Moscow" are related words, and that the words "surfing" and "surfer" are related to each other, and that the letters "" and "e" are often the same . We need to be able to understand requests in Internet jargon, or written using non-alphabetic characters, and to understand which words of the Russian language correspond to them.
It is important to be able to match words, phrases and texts in different languages. The user can specify the request [Head of the Verkhovna Rada of Ukraine], and in the document of interest to him, the name of this state body is found only in Ukrainian. It would be nice to be able to respond to a query set in one language, with results in other languages - related or not. In fact, the more we look at user requests, the more we understand that any search is a translation from the request language into the document language.
Now let's talk more about how linguists help solve search-related tasks. I will use the concept of a linguistic pyramid, in which text analysis is divided into several levels: lexical (splitting text into words), morphological (changing words), syntactic (combination of words with each other in phrases and sentences), semantic (meaning of words and sentences) and pragmatic (the goal of generating the utterance and its external context, including non-linguistic).
Let's start with the lexical level. What is the word? Search companies in 1995 had to answer this question at least somehow to be able to get started. For example, define a word as a sequence of alphabetic characters, bounded on the left and on the right by spaces or punctuation marks. Unfortunately, this is often incorrect, especially if we speak not about words in the usual sense, but about indivisible pieces of text found on the Internet. Among them, for example, Internet addresses, dates, phone numbers, etc. are common. It is often difficult to answer the question where one word ends and another begins. Here, for example, the amount with the indication of currency is one word or two? We need to somehow decide on this. Currency symbols, phone number formats in different countries, and similar things may seem very far from linguistics, but the problem is that the rough reality affects the most basic things, even the division of text into words.
In addition to the frequently mentioned cases already mentioned - email addresses, phone numbers, dates - there are other examples of complex, non-trivial "words". Here is an example of a phrase that would be convenient to consider in a search in one word: “the plant named after Frunze”. In this case, it would be good to consider the “plant them. Frunze "form of the same" word ". The request [New York] is often written without a hyphen, but this does not turn it into two separate words: it would be wrong to show documents on it, where the words "York" and, say, "New Hampshire" meet separately.
It happens that punctuation and special characters are an important part of a word. The name of the radio station can be written by users: “Europe +”, and the TV channel may be called “1 + 1”. There is even a band in the world, with a wonderful name that no search engine finds in this form: "#####". Similar problems often arise when searching for the names of variables and functions, as well as other requests from programmers. Why it happens? Because someone at the dawn of search engines decided that the characters%, _, # and + will not be considered letters.
It would seem that now we have gained the necessary experience, we know about all these special cases, and we can divide the text into words much more correctly, but the problem is that the search index is ready. If now we change our understanding of what a word is, we will need to make changes to all the programs that work with this index and reindex the entire Internet, that is, billions of documents. This means that any error in lexical analysis is very expensive to correct. So, the lexical analysis of documents should be implemented as correctly as possible from the very first version, and this requires wisdom, which no one else had fifteen years ago.
Let us turn to the morphological analysis. What do we want from him? First of all, we want to know what word forms the dictionary words have. Fortunately, this problem has already been solved for the main languages of the world. The words in them are already divided into parts of speech, declensions, conjugations and similar categories, and we know how they vary in cases, by gender, by time, etc. The situation is worse with proper names: there are many of them, and there are practically no dictionaries of proper names. At the same time, it would be good to know that “Moscow” and “to Moscow” are one and the same thing, it would be good to know how “Lower Sychi” are leaning, not to mention first and last names, of which there are quite a lot. It is especially difficult with the names, and this is an important case: a particular sin of the search engine - if a person is looking for and cannot find himself. In addition, there are words that are not found in any dictionary, and which are constantly changing: the names of brands, organizations, firms. So, you need to be able to automatically assign an unfamiliar word to one of the word-formation models known to us.
Further, we encounter another interesting problem, which is rarely found outside the search, but rarely: which forms of the word are close to each other, and which are far away? For example, if the query specifies the word “to go,” do you need to search for documents using it, where are the words “walking” or “walking”? Most likely, the person making the request meant the word “go” in exactly this form. Another example: dig and swarm. The word “dig” in the query will most likely meet in the context of “how to dig a ditch”, and the word “swarm” can be a form of the word “dig”, “swarm” and the name “Swarm”. Even if it is really a form of the word “dig”, its use in the text, quite possibly, has nothing to do with the user's request. Not the fact that we have to look even for the main form of the word used in the query. For example, the word “houses” was found in the query - do you need to search for documents with the word “house”? TV program "House-2", the magazine "Your House" ...
We are not dealing with a single language, and this makes everything only more complicated. There is, for example, the Ukrainian noun “meta”, from which it is possible to form the forms “methi” and “meta”, which coincide with the Russian forms of the verb “revenge”. It turns out a complete mess. The problem is that the Ukrainian word “meta” is the name of the Ukrainian Internet portal, and therefore can be found in the Russian text. That is, we need to be able to recognize languages and understand the language in which the document is written, and, ideally, every word in this document.
Sometimes, by context or by some other means, it is possible to make a withdrawal of homonymy and understand which word is being spoken about. But you need to understand that this process does not always have one hundred percent accuracy and completeness, and it cannot be implemented without attracting any data about the real world. A computer, for example, is very difficult to understand the phrase “How many goals does Pavlyuchenko have?”: Because to understand that the shape of “heads” comes from the word “goal” and not “head”, you need to know who Pavlyuchenko is. This example stumbles over most homonymy removal algorithms.
A separate topic - synonyms. It is not entirely clear to which level of the linguistic pyramid it refers, because it is close to both semantics and morphology. We can consider synonyms as an extension of morphology: if we believe that a word can occur in a request in one form, and in a found document in another, why not do the same with synonyms. For example, to issue documents with the word “grandmothers” with the word “old women”, in the request “hippopotamus” - in the answer “hippo”, “erysipelas” - “muzzle”, and so on. The question is how to search for them automatically, because you cannot manually make all such pairs.
One way is to look for words that are often found in the same contexts. Here we are faced not so much with linguistic, as with programmer problems. For example, to find all pairs of words that occur in the same contexts, we first need to multiply by itself a matrix, having dimensions of about 1.000.000.000 * 1.000.000.000, in which it is written which word and how often it occurs in what contexts. This is not a trivial operation. Let's say that such amounts of data basically cannot fit on one computer. In addition, I want these calculations to take place as quickly as possible, because in order to achieve the required quality, we need to try out many of its options, which are slightly different from each other.
Most pairs of synonyms do not look like “grandmothers” - “old women”, but consist of words with similar sound. It may not be entirely correct to use the word “synonyms” to designate such pairs, but in the absence of a better one, I will use this term. For example, there are various permissible spellings of the same word, there are transliterations, there are words that can be written both together and separately. Special accounting of such patterns helps to find more synonyms and make it more accurate.
The next problem: synonyms do not really exist, because there are no two words that completely replace each other: “my grandmother” and “my old woman” are completely different things, “Hippo's cat” cannot be replaced with “Hippo cat”, and the word "Erysipelas" in the sense of illness - the word "muzzle". So, synonyms should be context-sensitive, that is, synonymy relations are possible not between a pair of words, but a pair of words in some context . Fully the task of accounting context in synonymy has not yet been solved. Sometimes it is impossible to do without a fairly complex context: in one example II can mean “Second”, and in the other - “Second”. The words "eighty-sixth" can mean both the number 86 and the number 1986.
A separate problem - typos. Is it correct to consider words written with misprints, synonyms of words written correctly, or should they be treated in a special way? There is no unequivocal answer, but, apparently, it is necessary to act differently with typos, for example, to correct the user's error explicitly. Moreover, even the correction of typos in common words is a hell of a difficult task. For example, many correctly written Ukrainian words can be easily mistaken for a typo in a Russian-language query. There are even requests like [hardly or hardly], the meaning of which is completely lost if they correct the spelling. Many surnames of search engines with enviable regularity correct for similar surnames of celebrities, such actions can easily spoil the mood of the user.
We proceed to parse. I was a little cunning when I illustrated the concept of a linguistic pyramid with the help of a trapezium, because in a real search the pyramid does not look like that. The level of parsing is very small and practically nothing is done on it. I have a few suggestions about why this is so. The first is a conflict of data structures. Parsing a tree structure of data with complex links between parts of a sentence, etc. , - . , , , , . , , , . : . , , .
, , . , - – “if”, «», “the”, , , . , . , «» , , , . , - . , [ ] [ ] — . - , , “The The” [ ].
. , - , , . : «» : , , , .. – , . – , . , «», «», «», «». , , . – «» . , «» , . , .
, , :
, — . , , . , , . , , samsung.
, , , , - . – - . . – , : , , n- , . , . .
. , , , . , . , , , , , . , «» « ». , , , «» – . , , .
, , , - , . , « » , ; «» , . , , . [] , , .. , , . - .
, , . — , , , . , “sentiment analysis”: , , , . , , , , , - - , - - , , . “rocket science”, . , .
– . [ ] [ ], . «», « ». , , «».
– . , , , , , . , , .
, . , . , , . , , , , , , 10. , : . , . , – , , , .
, . , , . «» , , . ? -, : , « » ( ), « » — ( ), .
– , . . , . , ( , , «» , - , ). . , «» , . , , , .
– , , , . , , – . , , . , « ». , : [ ] ..
, , , , - . , . , , , , , . – . . : , , - , . , .
Hopefully, science will continue to move forward just as slowly and unstoppably.
Source: https://habr.com/ru/post/224579/
All Articles