About source code analysis and automatic generation of exploits
Recently, only lazy has not written about the analysis of source code security. It is understandable, because the guy from Gartner, as suggested to consider the analysis of the source code as a new HYIP a few years ago, still has not given the go-ahead to stop doing this. And, given the current direction of my work (participation in the development of PT Application Inspector , then AI), and the fact that recently there were no valid articles on the topic of source code analysis, it’s somehow even strange that until today of the day there were no dirty details on this burning topic on this blog. Well, correcting.
Actually everything that could be said about our approach to automating the analysis of source code security in AI was already said by Sergey Plekhov and Alexey Moskvin in the report “ Problems of automatic generation of exploits by source code ” on PHDays IV. For those who did not attend the report and did not watch its recording, I highly recommend doing this before reading the article further. However, at the end of the report from Ivan Novikov, aka @ d0znpp , several questions were raised on the topic “what is the case?”, “How does your approach differ from the same RIPS?” And “how do you get entry points then?” In the context of the statement that without deploying an application, it is impossible to obtain external data necessary for building an exploit (such as, for example, the privileged user name and password, routes to entry points, etc.). I want to immediately make a reservation that some terminological confusion takes place here: the name “the problem of automatically deriving sets of attack vectors from the source code” would more accurately reflect the essence of the problems solved during the work on AI. Calling what turns out at the output of AI exploit is really not quite correct. If only because it is cooler than just an exploit in the traditional understanding of this term :) And then I will try to uncover this thought and supplement my colleagues with a more detailed answer to the questions asked by Ivan.
First of all, the case consists in finding flaws in the code and confirming their vulnerability to certain classes of attacks. The task of automatic generation of exploits in this case is reduced to the conclusion of the minimum attack vector, confirming the existence of vulnerability. At the same time, a vector means not a specific HTTP request, but a certain combination of factors leading the system into a state of vulnerability and allowing a successful attack on it. I will say even more: in the general case, it is not possible to express the attack vector in the form of an HTTP request only. First, because this vector may require multiple queries. Secondly (and this is important), because the vector can include conditions on any properties of the environment that cannot be described in the context of an HTTP request. Nevertheless, within the framework of the case under consideration, we must: a) derive all such conditions; b) somehow make them in the results of the analysis. This is what led to such an intricate definition of a vector. I’ll give a simple example (hereinafter, C # code under ASP.NET Web Forms is considered):
')
Obviously, in this case, the vulnerability to the XSS attack depends on the value of the key1 parameter in the configuration file settings.xml. And, if we honestly read it (that is, in fact, rather than symbolically calling the Settings.ReadFromFile ("settings.xml") call and assigning the result to the variable settings), then we will go only along one of two possible ways run, which will inevitably lead us to skip the vulnerability in the event that the key1 parameter in the file is not set to “validkey”. By performing the first call symbolically, we will end up with the following formula, which will be the desired vector:
We can also infer from this and the HTTP exploit:
which, however, is not self-sufficient and depends on the conditions imposed on the environment of the web application.
Obtaining any values from a database, file system or any other external source leads to a simple dilemma: either we get external data and have the opportunity to build full-fledged exploits (where theoretically possible), but skip the potential vulnerabilities due to for loss of execution paths, or we process calls to external sources symbolically and, thereby, cover all possible sets of values and execution paths that may occur as a result of such calls. And since we were faced with the task of not creating a universal attacker-all-powerful device, but rather maximally automating the human routine for analyzing the code security, obtaining vectors in the form of proven logical formulas that require further human work in terms of building full-fledged exploits is preferable to automated functional.
However, situations are possible where without reading external data it really is nowhere: this is defining routes to entry points to a web application if they are defined in external configuration files and not in application code, and connecting additional source code files through their listing in configuration files (relevant for dynamic languages), and a number of similar tasks. But there are no questions here: if it’s necessary, it means that we’ll read with our fingers crossed. Where we can, of course.
Summing up: at the moment, there are no obstacles to teaching AI to read data from the database and use it during the symbolic execution of the analyzed code. However, this will require the deployment of at least a database of a web application on the one hand and will significantly decrease the analyzer’s ability to detect vulnerabilities on the other, without giving any tangible advantages within the framework of the task set before us, which I described above.
As far as I can judge the approach adopted in RIPS, AI'shny - differs slightly more than all. Starting with the fact that RIPS implements classic static-taint-analysis via tagging paths in a data flow graph with emulation of a number of standard library functions, and the AI trip involves building a model (one for each entry point) as a system of logical statements describing the state of the application in each CFG node and the conditions for its achievement, which makes it possible to resolve any paths in it (including ifs, conditional returns, exception handling, etc.) also with partial execution of the real code instead of emulating it, where it gives the best re result compared to symbolic execution. And ending (but not limited to) the fact that RIPS stupidly breaks off on custom filtering functions, while the AI is trying to work with them (and very successfully in most real cases).
Probably better show by example. Let's say we have the following source code fragment [1] :
Obviously, a potentially dangerous operation takes place here (hereinafter PVO - Potentially Vulnerable Operation) - calling the Response.Write method, which writes to the HTTP request response generated by the server. In the first case, the constant “Wrong Key!” Is passed to the method, which is of no interest to us. But in the second, the response is the result of calling the CustomSanitize method with an argument whose value is calculated from the values of the parameters of the received request. But what should they be in order for us to be able to pass a value to str1 sufficient to confirm the possibility of carrying out an XSS attack through the injection of HTML markup elements? Let's look at how the process of finding the answer to this question might look like. [2] .
To begin with, we derive the reachability condition of the second Response.Write. Despite the fact that he himself is not nested in any constructions affecting the control flow, in the preceding blocks of code there is a return from the function common to the whole code, the condition of reachability of which is at the same time the condition of the unattainability of our PVO. It is obvious that the condition for the execution of the operator return is a logical expression: (name == "adm" && key1! = "Validkey"). Therefore, the condition of its unattainability will be the expression: (name! = "Adm" || name == "adm" && key1 == "validkey"). Since this return is the only statement that affects the reachability of the second Response.Write, the last expression will be the condition of the reachability of the PVO.
In fact, the expression (name! = "Adm" || name == "adm" && key1 == "validkey") gives us two mutually exclusive conditions for the formation of the path to the PVO on the control flow graph. Consider the possible values of str1 when executing each of them. When (name! = "Adm"), the variable str1 gets the constant value "Wrong role!", Which definitely cannot lead us to a successful attack. But with (name == "adm" && key1 == "validkey") str1 gets the result of calling the method Encoding.UTF8.GetString with the argument data, which in turn can take two values: new byte [0] with string.IsNullOrEmpty (parm) and Convert.FromBase64String (parm) with! string.IsNullOrEmpty (parm). Throwing away uninteresting ones with t.ch. exploitation of vulnerability values and unwinding the values of all variables up to their taint-sources, we obtain the following formula:
A graphical representation of the execution model built in this case will look like (clickable):
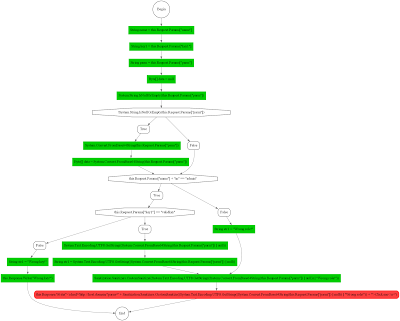
Thus, we already have the values of the request parameters name and key1 and all that remains to be done is to find the Request.Params [“parm”] value, at which the final value of the CustomSanitize expression (Convert.FromBase64String (Request.Params [“parm "])) Will give us exploitation of the vulnerability leading to XSS.
And here a problem arises, which traditional means of statistical analysis cannot cope with. The Convert.FromBase64String method is library and can be described in the analyzer knowledge base as having the inverse function Convert.ToBase64String, from which we can conclude that the result of CustomSanitize should go to the input of Convert.ToBase64String. But what to do with CustomSanitize, which is not a library, is not described anywhere and is a black-black box at this stage of the analysis? It is good if the source code of this method is available to us - in this case, we can “fall through” into its body and continue the symbolic execution of the code in a manner similar to that described above. But what to do if the source is not? The answer was made in the previous sentence: forget for a while about that, our analysis is static and work with this method as with a black box. We have the expression Convert.ToBase64String already output (CustomSanitize (Request.Params ["parm"])), there are many possible XSS vectors (let it be {`<script> alert (0) </ script>`, `' onmouseover = 'a [alert]; a [0] .call (a [1], 1) `and` "onmouseover =" a [alert]; a [0] .apply (a [1], [1]) `}) - so why not declassify this formula by specifying the character variable Request.Params [" parm "] with vector values and directly executing the resulting expression?
Suppose that CustomSanitize only removes angle brackets. Then, as a result of fuzzing, we get three values:
of which the last two seem worthy of consideration as attack vectors. So, we know the full expression passed in as the PVO argument. We know the exact place where the value of the symbol variable Request.Params ["parm"] will fall when it is specified with the values of vectors. What else do we need to choose from these two that vector, the use of which will lead to injections? Those who listened attentively to the webinar " How to develop a secure web application and do not go crazy with it? " Will immediately say that we don’t need anything more :)
So The final result of the analysis of this code is the contextual (defining the values of symbolic variables in the context of the execution of PVO) exploit:
from which it is already possible to deduce and HTTP (defining the requirements for the actual parameters of the HTTP request) exploit:
In AI, if you're interested, it looks like this (clickable):


Of course, in a harsh reality, everything is slightly more complicated: even a vector modified by a filtering function can “shoot”, which, together with the appearance of regular expressions in such functions, makes it necessary to manipulate the state machines describing them instead of constant values; the fact that the input parameter of the query can be inserted into an arbitrary grammatical construction of the output language leads to the need for parsing and / or heuristic deduction of the properties of island languages, etc. etc. But these are already topics for individual (and, probably, slightly more scientific) articles. I note only that within the framework of our task, these problems were also successfully solved.
I deliberately omitted in all examples the issue of getting "/path/to/document.aspx" (i.e. the route to the entry point to the web application), since This task does not have a universal solution and requires a description of the specifics of various frameworks in the analyzer's knowledge base. For ASP.NET Webforms, for example, entry points are handler methods of the so-called. postbacks of web form controls (which requires parsing .aspx files and linking them with the corresponding codebehind files). In ASP.NET MVC, routes are defined through populating the RouteCollection collection directly in the application initialization code. We should not forget about the possibility of appearing in WebConfig sections urlMappings, urlrewritingnet and the like, also affect the routing of HTTP requests to the application. Yes, and the developer does not interfere with the definition of a custom HTTP handler that implements custom routing logic, the reverse of which is an algorithmically unsolvable task. In this case, we have nothing left but to consider as public entry points all public and protected methods in the case of Java / C # or all .php files in the case of PHP, accepting the growth in the likelihood of false-positive on the outside unreachable code. However, I personally have not yet met such .NET applications, but the existing zoo does not inspire PHP frameworks, but it is completely formalized in the analyzer's knowledge base, including the part concerning getting routes to the entry points. Exotics such as the description of routing rules in the database, as is probably clear, we are processing the above-mentioned direct search of all potential entry points (which, by the way, doesn’t give such bad results as it may seem at first glance).
I hope that I still managed to answer the questions posed. But if new ones suddenly appeared, or incomprehensible moments remained - welcome, as they say :)
Actually everything that could be said about our approach to automating the analysis of source code security in AI was already said by Sergey Plekhov and Alexey Moskvin in the report “ Problems of automatic generation of exploits by source code ” on PHDays IV. For those who did not attend the report and did not watch its recording, I highly recommend doing this before reading the article further. However, at the end of the report from Ivan Novikov, aka @ d0znpp , several questions were raised on the topic “what is the case?”, “How does your approach differ from the same RIPS?” And “how do you get entry points then?” In the context of the statement that without deploying an application, it is impossible to obtain external data necessary for building an exploit (such as, for example, the privileged user name and password, routes to entry points, etc.). I want to immediately make a reservation that some terminological confusion takes place here: the name “the problem of automatically deriving sets of attack vectors from the source code” would more accurately reflect the essence of the problems solved during the work on AI. Calling what turns out at the output of AI exploit is really not quite correct. If only because it is cooler than just an exploit in the traditional understanding of this term :) And then I will try to uncover this thought and supplement my colleagues with a more detailed answer to the questions asked by Ivan.
What is the case?
First of all, the case consists in finding flaws in the code and confirming their vulnerability to certain classes of attacks. The task of automatic generation of exploits in this case is reduced to the conclusion of the minimum attack vector, confirming the existence of vulnerability. At the same time, a vector means not a specific HTTP request, but a certain combination of factors leading the system into a state of vulnerability and allowing a successful attack on it. I will say even more: in the general case, it is not possible to express the attack vector in the form of an HTTP request only. First, because this vector may require multiple queries. Secondly (and this is important), because the vector can include conditions on any properties of the environment that cannot be described in the context of an HTTP request. Nevertheless, within the framework of the case under consideration, we must: a) derive all such conditions; b) somehow make them in the results of the analysis. This is what led to such an intricate definition of a vector. I’ll give a simple example (hereinafter, C # code under ASP.NET Web Forms is considered):
')
var settings = Settings.ReadFromFile("settings.xml"); string str1; if (settings["key1"] == "validkey") { Response.Write(Request.Params["parm"]); } else { Response.Write("Wrong key!"); } Obviously, in this case, the vulnerability to the XSS attack depends on the value of the key1 parameter in the configuration file settings.xml. And, if we honestly read it (that is, in fact, rather than symbolically calling the Settings.ReadFromFile ("settings.xml") call and assigning the result to the variable settings), then we will go only along one of two possible ways run, which will inevitably lead us to skip the vulnerability in the event that the key1 parameter in the file is not set to “validkey”. By performing the first call symbolically, we will end up with the following formula, which will be the desired vector:
Settings.ReadFromFile("setings.xml")["key1"] == "validkey" -> {Request.Params["Parm"] = <script>alert(0)</script>} We can also infer from this and the HTTP exploit:
GET http://host.domain/path/to/document.aspx?parm=%3Cscript%3Ealert%280%29%3C%2fscript%3E HTTP/1.1 which, however, is not self-sufficient and depends on the conditions imposed on the environment of the web application.
Obtaining any values from a database, file system or any other external source leads to a simple dilemma: either we get external data and have the opportunity to build full-fledged exploits (where theoretically possible), but skip the potential vulnerabilities due to for loss of execution paths, or we process calls to external sources symbolically and, thereby, cover all possible sets of values and execution paths that may occur as a result of such calls. And since we were faced with the task of not creating a universal attacker-all-powerful device, but rather maximally automating the human routine for analyzing the code security, obtaining vectors in the form of proven logical formulas that require further human work in terms of building full-fledged exploits is preferable to automated functional.
However, situations are possible where without reading external data it really is nowhere: this is defining routes to entry points to a web application if they are defined in external configuration files and not in application code, and connecting additional source code files through their listing in configuration files (relevant for dynamic languages), and a number of similar tasks. But there are no questions here: if it’s necessary, it means that we’ll read with our fingers crossed. Where we can, of course.
Summing up: at the moment, there are no obstacles to teaching AI to read data from the database and use it during the symbolic execution of the analyzed code. However, this will require the deployment of at least a database of a web application on the one hand and will significantly decrease the analyzer’s ability to detect vulnerabilities on the other, without giving any tangible advantages within the framework of the task set before us, which I described above.
How is your approach different from RIPS?
As far as I can judge the approach adopted in RIPS, AI'shny - differs slightly more than all. Starting with the fact that RIPS implements classic static-taint-analysis via tagging paths in a data flow graph with emulation of a number of standard library functions, and the AI trip involves building a model (one for each entry point) as a system of logical statements describing the state of the application in each CFG node and the conditions for its achievement, which makes it possible to resolve any paths in it (including ifs, conditional returns, exception handling, etc.) also with partial execution of the real code instead of emulating it, where it gives the best re result compared to symbolic execution. And ending (but not limited to) the fact that RIPS stupidly breaks off on custom filtering functions, while the AI is trying to work with them (and very successfully in most real cases).
Probably better show by example. Let's say we have the following source code fragment [1] :
string name = Request.Params["name"]; string key1 = Request.Params["key1"]; string parm = Request.Params["parm"]; byte[] data; if (string.IsNullOrEmpty(parm)) { data = new byte[0]; } else { data = Convert.FromBase64String(parm); } string str1; if (name + "in" == "admin") { if (key1 == "validkey") { str1 = Encoding.UTF8.GetString(data); } else { str1 = "Wrong key!"; Response.Write(str1); return; } } else { str1 = "Wrong role!"; } Response.Write("<a href='http://host.domain' onclick='" + CustomSanitize(str1) + "'>Click me</a>"); Obviously, a potentially dangerous operation takes place here (hereinafter PVO - Potentially Vulnerable Operation) - calling the Response.Write method, which writes to the HTTP request response generated by the server. In the first case, the constant “Wrong Key!” Is passed to the method, which is of no interest to us. But in the second, the response is the result of calling the CustomSanitize method with an argument whose value is calculated from the values of the parameters of the received request. But what should they be in order for us to be able to pass a value to str1 sufficient to confirm the possibility of carrying out an XSS attack through the injection of HTML markup elements? Let's look at how the process of finding the answer to this question might look like. [2] .
To begin with, we derive the reachability condition of the second Response.Write. Despite the fact that he himself is not nested in any constructions affecting the control flow, in the preceding blocks of code there is a return from the function common to the whole code, the condition of reachability of which is at the same time the condition of the unattainability of our PVO. It is obvious that the condition for the execution of the operator return is a logical expression: (name == "adm" && key1! = "Validkey"). Therefore, the condition of its unattainability will be the expression: (name! = "Adm" || name == "adm" && key1 == "validkey"). Since this return is the only statement that affects the reachability of the second Response.Write, the last expression will be the condition of the reachability of the PVO.
In fact, the expression (name! = "Adm" || name == "adm" && key1 == "validkey") gives us two mutually exclusive conditions for the formation of the path to the PVO on the control flow graph. Consider the possible values of str1 when executing each of them. When (name! = "Adm"), the variable str1 gets the constant value "Wrong role!", Which definitely cannot lead us to a successful attack. But with (name == "adm" && key1 == "validkey") str1 gets the result of calling the method Encoding.UTF8.GetString with the argument data, which in turn can take two values: new byte [0] with string.IsNullOrEmpty (parm) and Convert.FromBase64String (parm) with! string.IsNullOrEmpty (parm). Throwing away uninteresting ones with t.ch. exploitation of vulnerability values and unwinding the values of all variables up to their taint-sources, we obtain the following formula:
(Request.Params["name"] == "adm" && Request.Params["key1"] == "validkey" && !string.IsNullOrEmpty(Request.Params["parm"])) -> Response.Write("<a href='http://host.domain' onclick='" + CustomSanitize(Convert.FromBase64String(Request.Params["parm"])) + "'>Click me</a>") A graphical representation of the execution model built in this case will look like (clickable):
Thus, we already have the values of the request parameters name and key1 and all that remains to be done is to find the Request.Params [“parm”] value, at which the final value of the CustomSanitize expression (Convert.FromBase64String (Request.Params [“parm "])) Will give us exploitation of the vulnerability leading to XSS.
And here a problem arises, which traditional means of statistical analysis cannot cope with. The Convert.FromBase64String method is library and can be described in the analyzer knowledge base as having the inverse function Convert.ToBase64String, from which we can conclude that the result of CustomSanitize should go to the input of Convert.ToBase64String. But what to do with CustomSanitize, which is not a library, is not described anywhere and is a black-black box at this stage of the analysis? It is good if the source code of this method is available to us - in this case, we can “fall through” into its body and continue the symbolic execution of the code in a manner similar to that described above. But what to do if the source is not? The answer was made in the previous sentence: forget for a while about that, our analysis is static and work with this method as with a black box. We have the expression Convert.ToBase64String already output (CustomSanitize (Request.Params ["parm"])), there are many possible XSS vectors (let it be {`<script> alert (0) </ script>`, `' onmouseover = 'a [alert]; a [0] .call (a [1], 1) `and` "onmouseover =" a [alert]; a [0] .apply (a [1], [1]) `}) - so why not declassify this formula by specifying the character variable Request.Params [" parm "] with vector values and directly executing the resulting expression?
Suppose that CustomSanitize only removes angle brackets. Then, as a result of fuzzing, we get three values:
scriptalert(0)/script 'onmouseover='a[alert];a[0].call(a[1],1) "onmouseover="a[alert];a[0].apply(a[1],[1]) of which the last two seem worthy of consideration as attack vectors. So, we know the full expression passed in as the PVO argument. We know the exact place where the value of the symbol variable Request.Params ["parm"] will fall when it is specified with the values of vectors. What else do we need to choose from these two that vector, the use of which will lead to injections? Those who listened attentively to the webinar " How to develop a secure web application and do not go crazy with it? " Will immediately say that we don’t need anything more :)
So The final result of the analysis of this code is the contextual (defining the values of symbolic variables in the context of the execution of PVO) exploit:
Request.Params["name"] = "adm" Request.Params["key1"] = "validkey" Request.Params["parm"] = "'onmouseover='a[alert];a[0].call(a[1],1)" from which it is already possible to deduce and HTTP (defining the requirements for the actual parameters of the HTTP request) exploit:
GET http://host.domain/path/to/document.aspx?name=adm&key1=validkey&parm=%27onmouseover%3D%27a%5Balert%5D%3Ba%5B0%5D.call%28a%5B1%5D%2C1%29 HTTP/1.1 In AI, if you're interested, it looks like this (clickable):
Of course, in a harsh reality, everything is slightly more complicated: even a vector modified by a filtering function can “shoot”, which, together with the appearance of regular expressions in such functions, makes it necessary to manipulate the state machines describing them instead of constant values; the fact that the input parameter of the query can be inserted into an arbitrary grammatical construction of the output language leads to the need for parsing and / or heuristic deduction of the properties of island languages, etc. etc. But these are already topics for individual (and, probably, slightly more scientific) articles. I note only that within the framework of our task, these problems were also successfully solved.
How do you get entry points?
I deliberately omitted in all examples the issue of getting "/path/to/document.aspx" (i.e. the route to the entry point to the web application), since This task does not have a universal solution and requires a description of the specifics of various frameworks in the analyzer's knowledge base. For ASP.NET Webforms, for example, entry points are handler methods of the so-called. postbacks of web form controls (which requires parsing .aspx files and linking them with the corresponding codebehind files). In ASP.NET MVC, routes are defined through populating the RouteCollection collection directly in the application initialization code. We should not forget about the possibility of appearing in WebConfig sections urlMappings, urlrewritingnet and the like, also affect the routing of HTTP requests to the application. Yes, and the developer does not interfere with the definition of a custom HTTP handler that implements custom routing logic, the reverse of which is an algorithmically unsolvable task. In this case, we have nothing left but to consider as public entry points all public and protected methods in the case of Java / C # or all .php files in the case of PHP, accepting the growth in the likelihood of false-positive on the outside unreachable code. However, I personally have not yet met such .NET applications, but the existing zoo does not inspire PHP frameworks, but it is completely formalized in the analyzer's knowledge base, including the part concerning getting routes to the entry points. Exotics such as the description of routing rules in the database, as is probably clear, we are processing the above-mentioned direct search of all potential entry points (which, by the way, doesn’t give such bad results as it may seem at first glance).
That's all
I hope that I still managed to answer the questions posed. But if new ones suddenly appeared, or incomprehensible moments remained - welcome, as they say :)
- ↑ Immediately make a reservation that the example is unconditionally synthetic and is intended to demonstrate, rather, possible problems in the way of analyzing the code of the average lousy, rather than some real example from the living system. If someone from the readers wants to offer his own version of a code fragment, then it will be possible to consider the analysis process and on it - no question at all
- ↑ A description of the step-by-step execution of the process of analyzing even such a simple code would result in a multipage chain of transformations of uniform logic formulas, therefore the calculations are not given here. Those interested can familiarize themselves with a sufficiently detailed description of the approach and its individual stages in the recording of the report mentioned at the beginning of the article.
Source: https://habr.com/ru/post/224547/
All Articles