A / B testing errors in AirBnB

Today, airbnb has a very interesting post about how they do A / B tests. It seemed to me that the translation of this article would be of interest to Habrielians, since many create their own projects, and the methods of analyzing airbnb as a maximum can be useful, at least they will allow us to think that it would be nice to test the metrics of your product.
Airbnb is an online platform where you can find suggestions for people renting houses and asking people who are looking for a place to stay. We conduct controlled experiments that allow us to make decisions when developing a product, from design to creation of algorithms. This is very important in creating user convenience.
Principles for conducting experiments are simple, but often lead to the detection of unexpected pitfalls. Sometimes experiments stop too fast. Others that do not work on a regular marketplace, for some reason, start working on the specialized type airbnb. We hope that our results will help someone to avoid pitfalls, and this will allow you to make better design, better manage, and conduct more effective experiments in your projects.
Why experiment?
Experiments are a simple way to make a clear interface. It is often unexpectedly difficult - to tell what you do in simple language, and see what happens in the first illustration:
')
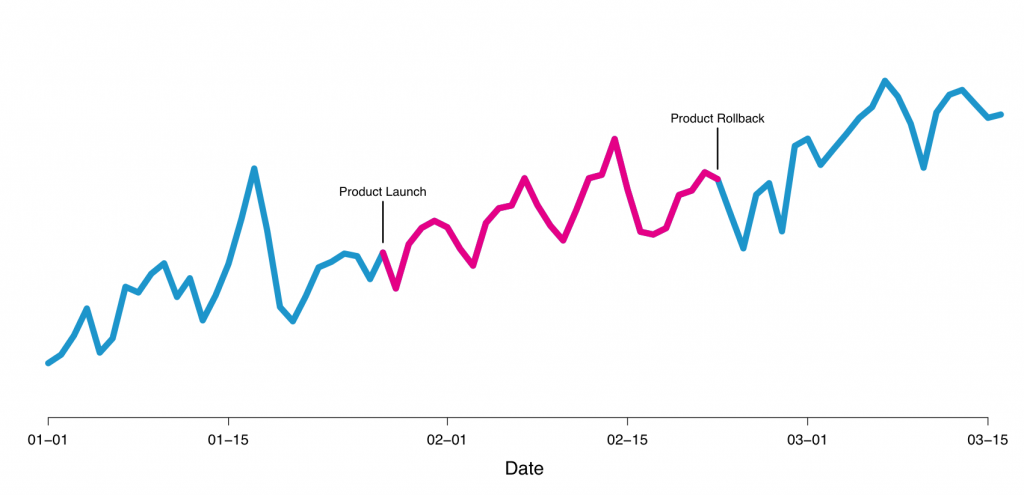
Illustration 1
The outside world greatly changes the product. Users can behave differently depending on the day of the week, time of year, weather (relative to our service, or another tourist project), or learn about the service through advertising, or organically. Controlled experiments isolate the effect on product change while the above-mentioned external factors are controlled. In Figure 2, you can see an example of a new feature that we tested, but which was abandoned. We thought that we would introduce a new way to select a price that would be pleasant to the user, but we received a decrease in conversion, so we abandoned it.
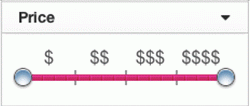
Figure 2 is an example of a new feature that we tested, but refused
When you test single changes of this type, the methodology is usually called A / B testing or split tests. This post does not contain basic information on the use of A / B tests. There are several large companies where you can find similar services. For example, Gertrude , Etsy's Feature , and Facebook's PlanOut ,
Testing in AirBnb
In AirBnB, we created our own A / B framework for testing, in which it is possible to run experiments. There are several special features in our business that are tested more thoroughly than the usual button color changes, which is why we made our own framework.
First, users can browse the site when they are logged in or not logged in, which makes testing quite complex. People often switch between devices (between web and mobile) between bookings. Also, the reservation may take several days, and therefore we must wait for the results. As a result, applications and quick responses from home owners are factors that we also want to control.
There are several variations when booking. First, the visitor uses the search. It then contacts the landlord. Then the landlord confirms the application and then the guest reserves the place. In addition, we have variations that can also lead to bookings in other ways - the guest immediately makes a reservation without contacting the hoster or can make a request for booking immediately. These four are visually shown in Figure 3. We have combined the process of passing these steps and the overall conversion between search and booking, which are our main indicators.

Figure 3 - an example of experiments
How long is it worth experimenting
The biggest source of confusion in online experiments is that you don’t know how long you have to conduct an experiment to get a result. The problem is that when you naively use p-value , as a criterion for stopping the experiment and rely on these results. If you continue to monitor the test and P-value results, then you will most likely see the effect. Another common mistake is to stop the experiment too soon, before the effect becomes visible.
Here is an example of our experiments that we launched. We tested the maximum price value that participates in the filter on the search page, changing it from $ 300 to $ 1000:
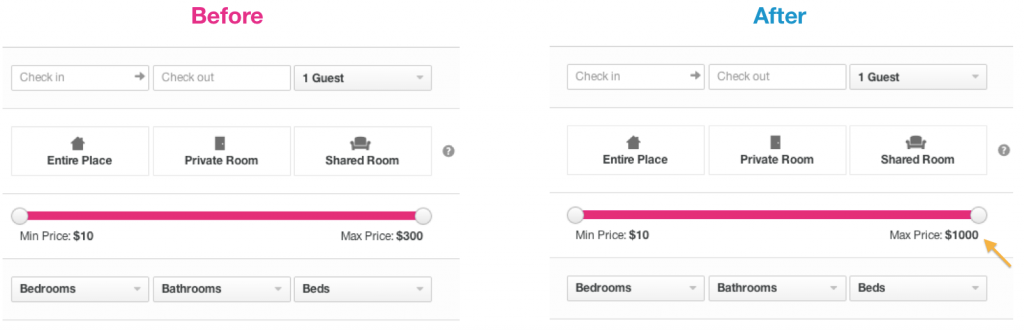
Figure 4 - Example of testing the price in the filter
In Figure 5, we show the time test. The upper graph shows the treatment effect , and the lower graph shows the p-value as a function of time. As you can see, the P-value exceeds 0.05 after 7 days, in which the effect value is 4%. If we stopped the experiment there, we didn’t get significant results that we received when booking. We continued the experiment and reached the moment when the experiment became neutral. The final effect was almost equal to the zero p-value, signaling that only noise remained.
Figure 5 - the result of the dependence of the experiment filter on time
Why didn't we stop the experiment when the p-value was 0.05? It turns out that this does not happen in conventional systems. There are several reasons for this. Users often decide on an order for quite a long time and early orders have too much influence on the beginning of the experiment.
To get the right result, you must perform a statistical test every time you calculate the p-value, and the more you do it, the more likely it is to get the effect.
Please note that people who have worked closely with the site may have noticed that during the launch of the test for the maximum value of the price, the effect was neutral. We have found that certain users who book rather expensive houses do not greatly affect this metric, since they order quickly.
How long should the experiment be run to prevent negative changes? The best practice is to run experiments with minimal effects that allow you to calculate the size of the effect.
There is a moment when an experiment leads to success or failure, even when time has not yet passed. In the case of price filtering, the example that we showed an increase was the first achievement, but the graph did not clearly show this, because the curves did not converge. We found this point very useful when the results may not be entirely stable. This is important for research and development of important metrics, therefore, rather considering a single result with a p-value.
We can use this example to further understand exactly when to stop an experiment. This can be useful if you are doing a lot of experimentation at the same time. Intuition tells you that you must be distrustful of any first results. Therefore, when the results are too low at the beginning - it does not mean anything.
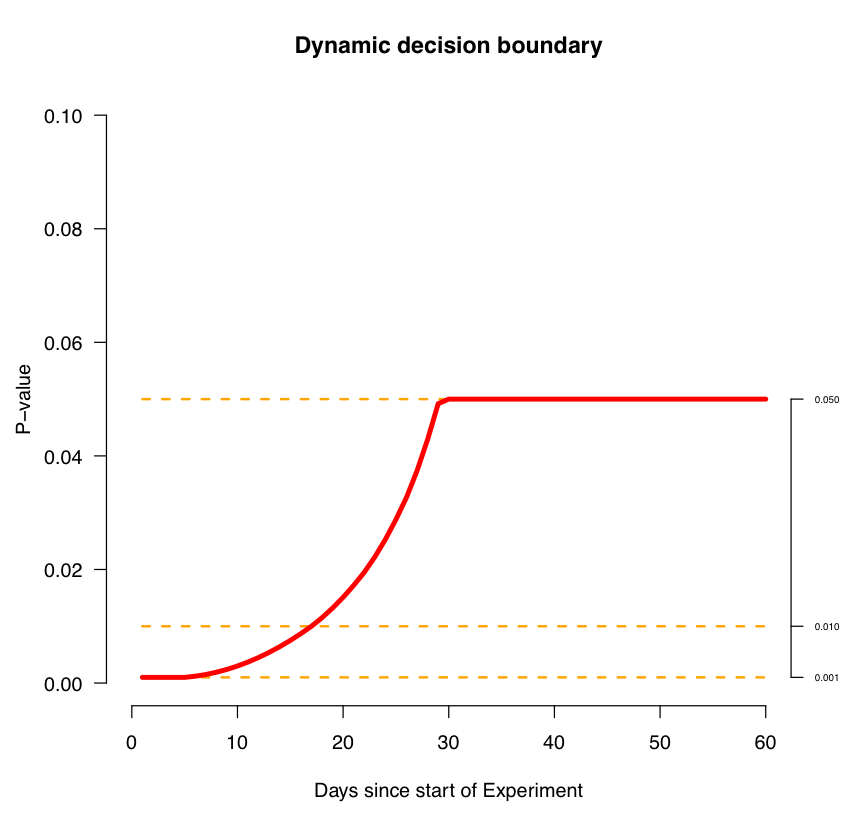
Figure 6
It should be noted that this curve is partly a parameter of our system, which we use in experiments. Your project will have its own values.
The second trap is an analysis of the results in a general context. Basically, the practice of evaluating the success of an experiment is based on a single metric. However, because of this, you can miss a lot of valuable information.
Let's give an example. Last year we spent on the redesign of our search page. Search is a fundamental component of Airbnb. This is the main interface of our product and the most direct way to captivate users of our site. Therefore, it is important to make it right. In Figure 7, you can see the page before and after the changes. The new design contains a larger image size, a larger map showing where the objects are located. You can read about design changes in another post.
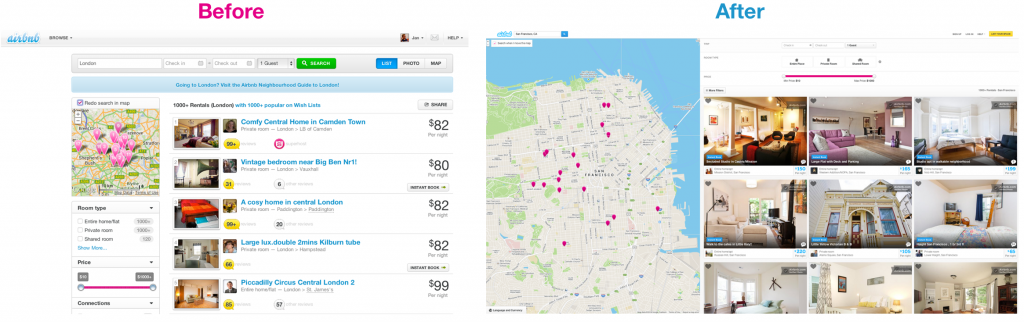
Figure 7
We did a lot of work on this project and we thought and tried to make the design as good as possible, after which we wanted to evaluate our design with the help of an experiment. It was a great temptation to launch the design and show it all at once, so as not to miss the marketing opportunity. However, having gathered the spirit, at first we tested the new design.
After waiting for a sufficient amount of time according to the methodology described above, we got the results. Global metric changes were tiny and the p-value signaled a zero effect. However, we decided to look deeper at the results in order to understand all the causes and effects. We found that the new design was better in most cases, with the exception of Internet Explorer. Then we decided that the new design breaks the ability to click on the older versions of this browser, which greatly influenced the results. When we corrected this, IE began to show close results to other browsers, showing a 2% increase.
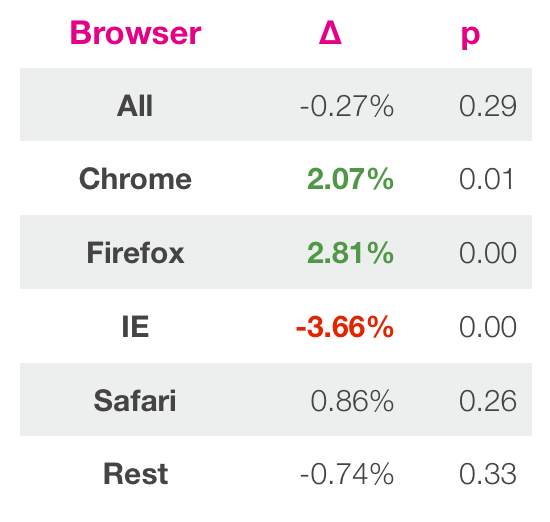
Figure 8
This taught us to be more attentive to testing IE. This example well illustrates the need to understand the testing context. You can get poor results for a variety of reasons, similar to browser version, country, and user type. Ordinary frameworks may simply not reflect some of the specifics that you can discover by manually exploring. You can run the same tests many times, but in the end, you can find a small thing that will lead to a significant effect. The reason for this may be that you run many tests at once, assuming that they all work independently, but this is not the case. One way to achieve this is to lower the p-value to a level at which you decide that the effect is real. Read more about it here.
System should work
The third and final reef today is the assumption that the system is working. You may think that your system is working and experiments are going on. However, the system may not reflect reality. This can happen if the framework is damaged or you use it incorrectly. One of the ways to evaluate the system and its overcurrent is to formulate hypotheses and test them.
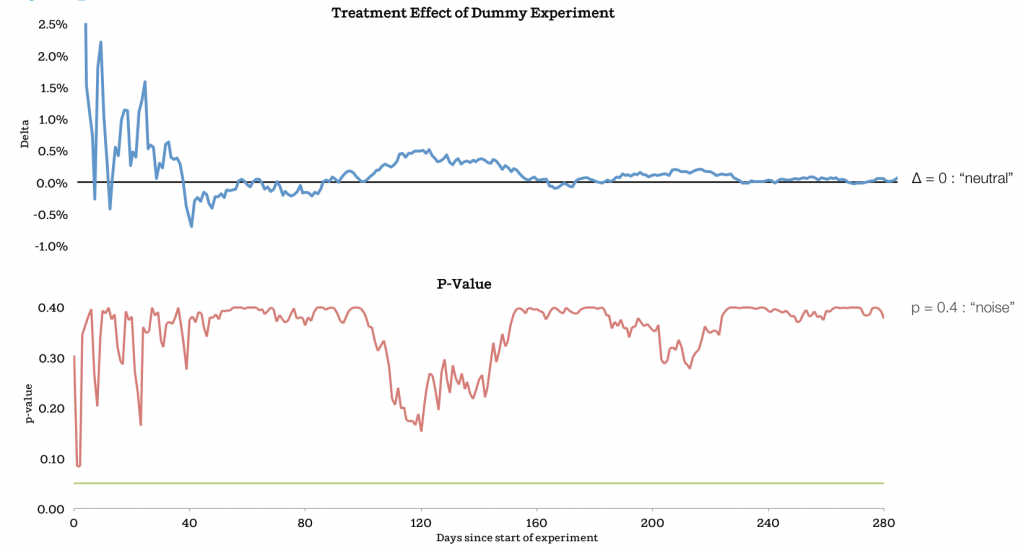
Figure 9
Another way to look at results that may seem too good to be true. When you study results that are similar to these, it is good practice to first study them carefully before you find it true.
The simplest example is when treatment is equal to a control value. This is called A / A or mock experiments. In an ideal world, the system will return neutral results. But what does your system return? We have launched many experiments similar to these (Figure 9) and compare the assumptions with the results. In one case, we launched bogus experiments.
You can see that in experiments where controlled and group treatments with similar sizes, the results look like this.
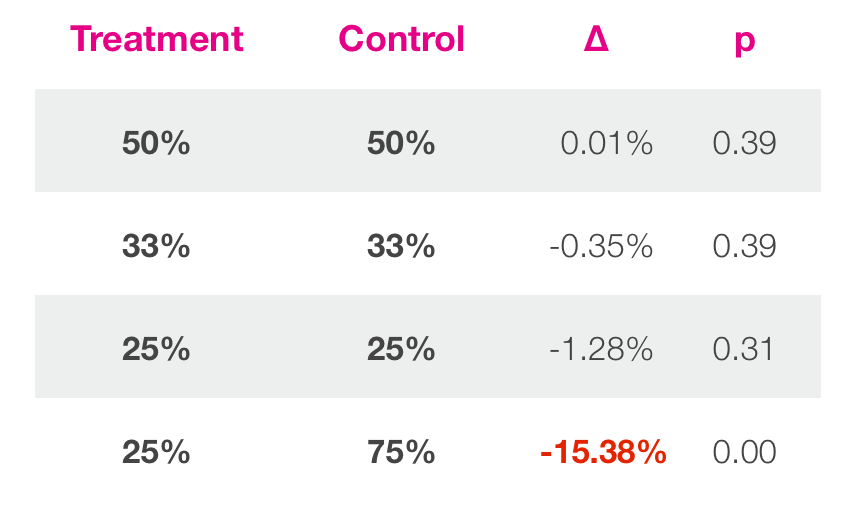
Figure 10
Conclusion
Controlled experiments are a good way to make a decision when developing a product. Let's hope that the lessons shown in this post will help prevent some of the mistakes made during A / B testing.
First, the best way to determine how long you need to continue the experiment to draw conclusions. If the system gives you early results, you can start making a loose assessment or trends should converge. Need to be conservative in this scenario.
It is important to look at the results in their context. Distribute them to meaningful groups and try to understand them more deeply. In general, experiments can be a good discussion on how to improve a product, rather than start aggressively optimizing a product. Optimization is not not possible, but often guided by an opportunistic impulse is not worth it. By focusing on the product, you can discuss and make the right decision.
In the end you need to be on you with your reporting system. If something does not look right or seems too good to be true, then study it. The easiest way to do this is to run mock tests, because any knowledge of how the system behaves will be helpful in understanding the results. In AirBnb, we found enough errors due to this.
[ Source ]
PS Just a week later, a SVOD conference will take place in Silicon Valley, which still has the opportunity to get there;)
Source: https://habr.com/ru/post/224461/
All Articles