Yandex.Translate offline. How computers learned to translate well
Today, an updated Yandex.Translate application for iOS has been released on the App Store. Now it has the possibility of full-text translation in offline mode. Machine translation has gone from mainframes, which occupied entire rooms and floors, to mobile devices that fit in your pocket. Today, full-text statistical machine translation, which previously required enormous resources, has become available to any user of a mobile device — even without connecting to the network. People have long dreamed of a "Babylonian fish" - a versatile compact translator that you can always take with you. And it seems that this dream is gradually starting to come true. Using a suitable opportunity, we decided to prepare a small excursion into the history of machine translation and tell about how this interesting area developed at the junction of linguistics, mathematics and computer science.

“This is all done by the machine”, “The electronic brain translates from Russian to English”, “Robot-bilingual” - such newspaper headlines were seen by readers of the jubilant press on January 8, 1954. A day earlier, on January 7, the IBM 701 science computer took part in the famous Georgetown experiment , translating about sixty Russian phrases into English. "Seven hundred and first" used a dictionary of 250 words and six syntax rules. And, of course, a very carefully selected set of proposals on which testing was conducted. It turned out so convincingly that enthusiastic journalists, with references to scientists, stated that in a few years machine translation would almost completely replace the classic “manual” one.
The Georgetown experiment was one of the first steps in the development of machine translation (and one of the first applications of computers to work with natural language). Then many of the problems of those faced in the future were not so obvious. However, the main problem, ironically, was that it was obvious from the very beginning that the computer was most difficult to work with multiple-valued words. On more or less natural proposals, the system almost completely ceased to cope with the task. The complex multicomponent structure of such systems also created problems: for example, the syntactic analysis did not always work correctly, and the composite word guitar pick (mediator) could be translated as “guitar choice”. Many-valued words were also poorly translated, the meaning of which depended on the context. For example, the text “Little John was looking for his toy box. Finally he found it. The box was in the pen caused (and continues to cause) a lot of difficulties - as the phrase "toy box", translated as "toy box", not "box for toys", and "in the pen", which was translated as "In the handle", and not "in the children's arena." The difficulties were enormous, and as a result in 12 years it was almost impossible to get off the ground. In 1966, the crushing ALPAC report (Automatic Language Processing Advisory Committee) put an end to machine translation research for the next ten years.
')
 In the meantime, the mood after the Georgetown experiment was still very bright and machine translation predicted a great future, the Americans began to seriously think about using the new technology for strategic purposes. What was fully realized in the USSR. At the beginning of 1955, two research groups were created by the USSR Academy of Sciences - at the Steklov Mathematical Institute (an outstanding mathematician and cybernetist Alexey Lyapunov became the head of the group) and at the Institute of Precise Mechanics and Computer Engineering of the USSR Academy of Sciences (headed by mathematician D. Yu Panov). Both groups began with a detailed study of the Georgetown experiment, and already in 1956, Panov published a brochure in which he presented the results of the first experiments on machine translation conducted on the BESM computer. In the same 1956 followed the publication of similar studies at the Institute. Steklov for the authorship of Olga Kulagina and Igor Melchuk, which was published in the September issue of the journal Issues of Linguistics. This publication was accompanied by various introductory articles, and it was here that something interesting was discovered: it turned out that in 1933 a certain Petr Petrovich Troyansky, an Esperantist and one of the co-authors of TSB, had addressed the USSR Academy of Sciences with a draft machine translator and a request to discuss this issue with the linguists of the Academy. Scientists were skeptical of the idea: discussions around the project lasted eleven years, after which the connection with Troyan was suddenly lost, and he allegedly left Moscow.
In the meantime, the mood after the Georgetown experiment was still very bright and machine translation predicted a great future, the Americans began to seriously think about using the new technology for strategic purposes. What was fully realized in the USSR. At the beginning of 1955, two research groups were created by the USSR Academy of Sciences - at the Steklov Mathematical Institute (an outstanding mathematician and cybernetist Alexey Lyapunov became the head of the group) and at the Institute of Precise Mechanics and Computer Engineering of the USSR Academy of Sciences (headed by mathematician D. Yu Panov). Both groups began with a detailed study of the Georgetown experiment, and already in 1956, Panov published a brochure in which he presented the results of the first experiments on machine translation conducted on the BESM computer. In the same 1956 followed the publication of similar studies at the Institute. Steklov for the authorship of Olga Kulagina and Igor Melchuk, which was published in the September issue of the journal Issues of Linguistics. This publication was accompanied by various introductory articles, and it was here that something interesting was discovered: it turned out that in 1933 a certain Petr Petrovich Troyansky, an Esperantist and one of the co-authors of TSB, had addressed the USSR Academy of Sciences with a draft machine translator and a request to discuss this issue with the linguists of the Academy. Scientists were skeptical of the idea: discussions around the project lasted eleven years, after which the connection with Troyan was suddenly lost, and he allegedly left Moscow.
This historical find surprised researchers; research began. It was possible to find the copyright certificate of Troyan on the "mechanized dictionary", which allows you to quickly translate texts simultaneously into several languages. After the next plenary session, at which Lyapunov read a report on this invention, the Academy of Sciences established a special committee to study the contribution of the Trojan. A few years passed and, finally, in 1959, the article “The Translation Machine of P. P. Troyansky: a collection of materials about the machine for translation from one language to another, proposed by P. P. Troyansky in 1933” was published. Belskoy and D. Yu. Panova. Soon the author's certificate was published, from which a very original technological solution of the device was visible.

In the project, the Troyansky machine was a table with an inclined surface, in front of which was attached a camera combined with a typewriter. The keyboard of a typewriter consisted of ordinary keys that allowed encoding morphological and grammatical information. The typewriter tape and camera film were to be connected together and fed in synchronization. On the very surface of the table there should have been a so-called “glossary field” - a freely moving plate with words printed on it. Each of the words was accompanied by translations in three, four or more languages. All words had to be given in their initial form and arranged on a board in such a way that the most frequently used words were closer to the center — like letters on a keyboard. The machine operator had to shift the glossary field and take a picture of the word and its translations, while typing on the typewriter the grammatical and morphological information relating to the word. The result was two tapes: one with words in several languages at once, and the second with grammatical explanations to them. When all the original text was typed in this way, the material went to native speakers - auditors, who had to check two tapes and write texts on them in their own languages. Further, the materials were to be transferred to editors who know both languages. Their task was to bring the text to the literary form.
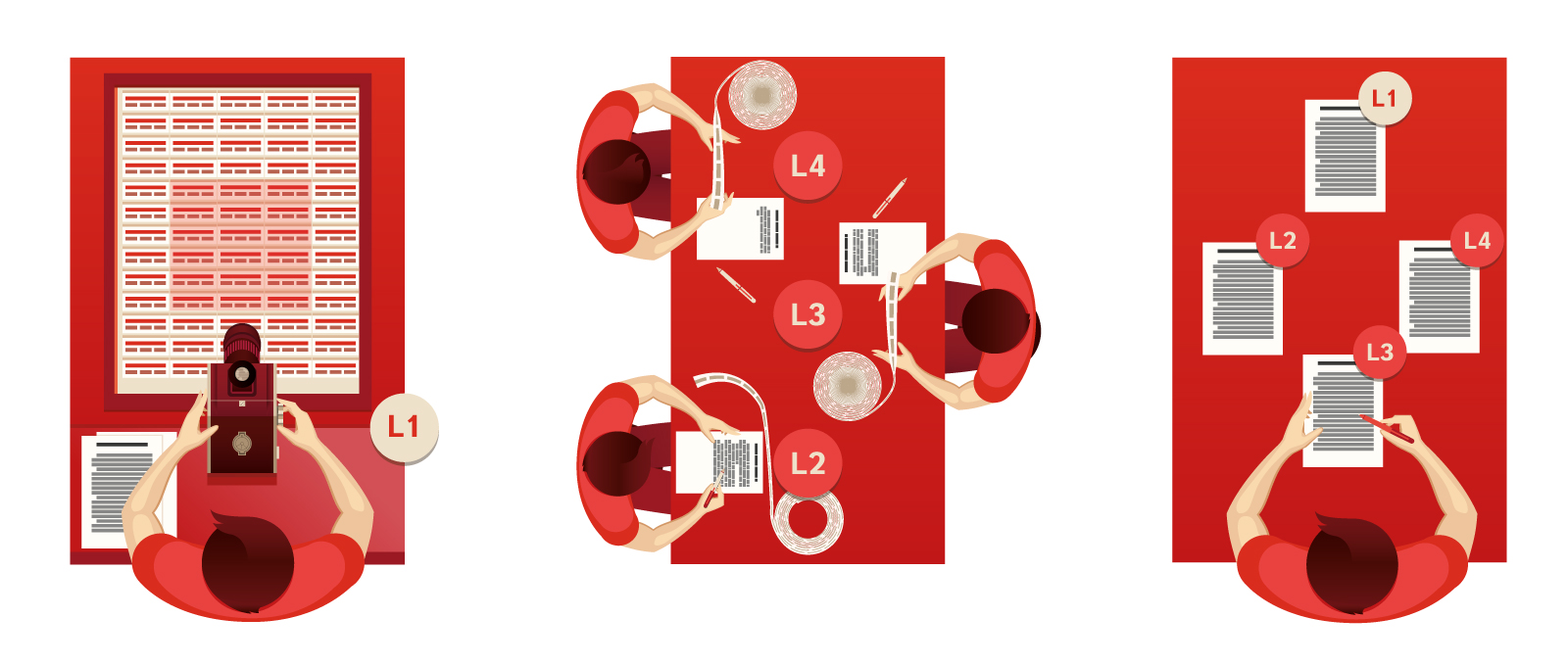
The main idea of the invention is the separation of the translation process into three main stages (by the way, the first and last in modern terminology would be called “pre-editing” and “post-editing”). Interestingly, the most time-consuming processes (coding the source text and synthesizing texts in other languages from this information) require all operators to know their native language.
Thus, the translation was carried out first between the natural language and its logical form, then between the logical forms of the two languages, and then the text in the logical form of the target language was verified and brought to a natural form. Trojan, as a historian of science, undoubtedly knew about the theories of Leibniz and Descartes about the creation of a universal language and translation through interlingua. The proposed technology traces the influence of these theories. Moreover, Troyan was an Esperantist, and built a coding system for grammatical information based on Esperanto grammar (which he was later forced to give up for political reasons).
What is particularly interesting, already in the forties, Troyansky considered the prospects of creating a "powerful transfer device based on modern communication technologies." However, during the lifetime of the ideas of the inventor were met by the academic community with great skepticism and subsequently forgotten. Trojan died in 1950, not very long before it began work on machine translation in the Soviet Union. English machine translation researcher John Hutchins believes that if Trojan’s contribution was not forgotten, the principles of his translation machine would form the basis of the first experiments at BESM, and this would place the inventor in the “fathers” of machine translation along with Warren Weaver. But, unfortunately, the story does not have the subjunctive mood.
Fast forward to forty years in the eighties. After ALPAC, no one except the most desperate enthusiasts had a serious desire to engage in machine translation. However, as is often the case, business has become the engine of progress. At the end of the sixties, the course towards globalization of the world was already evident. International companies faced an urgent need to maintain close trade contacts in several countries at the same time. In the 1980s, the business request for the technology of fast translation of documents and news increased: and here the machine translation was “uncovered”. The European Economic Community, the future European Union, did not lag behind. In 1976, SYSTRAN , the first commercial machine translator in history, was actively used in this organization. In the future, this system became an almost mandatory acquisition of any self-respecting international company: General Motors, Dornier and Aerospatiale. Japan did not stand aside either: the increasing volumes of work with the West were forcing large Japanese corporations to conduct their developments in this area. True, in most cases, they (like Sistran) somehow were variations of rule-based systems, with their well-known “generic” injuries — their inability to work correctly with ambiguous words, homonyms, and idiomatic expressions. Such systems were also very expensive, since creating a dictionary required the work of a large staff of professional linguists, as well as inflexibility — it was quite expensive to adapt to the desired subject area, not to mention the new language. Researchers still preferred to concentrate on systems that used rules, as well as semantic, syntactic and morphological analysis.
 A truly new era of machine translation began in the 1990s. The researchers realized that natural language is very difficult to describe formally, and even more difficult to apply formal descriptions to a living text. It was too difficult and resource-intensive task. It was necessary to look for other ways.
A truly new era of machine translation began in the 1990s. The researchers realized that natural language is very difficult to describe formally, and even more difficult to apply formal descriptions to a living text. It was too difficult and resource-intensive task. It was necessary to look for other ways.
As usual, when the problem seems practically insoluble, it is useful to change the perspective. IBM reappeared on the scene, one of whose research groups developed a statistical machine translation system called Candide. Specialists approached the task of machine translation from the point of view of information theory. The key idea was the concept of the so-called channel with errors (noisy channel). The model of the channel with errors considers the text in language A as encrypted text in any other language B. And the task of the translator is to decrypt this text.
Let's resort to an amusing illustration. Imagine an Englishman who studies French and came to France to practice it. The train arrived in Paris, and our hero needs to find luggage at the station Gare du Nord. After an unsuccessful search, he finally turns to a passer-by and, having thought over the phrase in English, asks him in French if he knows where to find a luggage room. Conceived English phrase as it “distorts” and turns into a phrase in French. Unfortunately, a passerby turns out to be an Englishman, and he knows French quite badly. He recovers the meaning of the phrase, trying to restore with the help of his knowledge of French and an approximate idea of what his interlocutor most likely had in view of - that is, to put it more simply, tries to guess what English phrase he intended.
IBM'ovtsy worked just with the French and English: in the hands of the research group was a huge number of parallel documents from the Canadian government. The researchers built their translation models as follows: they collected probabilities for all combinations of words of a certain length in two languages and probabilities to match each of these combinations to a combination in another language.
Further, the most likely translation of e , say, into English, for, for example, the French phrase f can be defined as:

where E is all English phrases in the model. As the Englishman tried to guess the thoughts of his compatriot, the algorithm tries to find the most frequent phrase in English, which would have at least some relation to what could potentially be conceived when the French phrase was pronounced.
This simple approach proved to be the most effective. IBM'ovtsy did not apply any linguistic rules, and, in fact, in the group almost no one knew the French language. Despite this, Candide worked, and moreover, it worked quite well! The research results and the overall success of the system were a real breakthrough in the field of machine translation. And most importantly, the experience of Candide proved that it is not necessary to have an expensive staff of first-class linguists to draw up translation rules. The development of the Internet has given access to a huge amount of data needed to create large translation models and language. Researchers have focused on the development of translation algorithms, the collection of cases of parallel texts and the alignment of sentences and words in different languages.
In the meantime, statistical machine translation was in the process of industrial development and slowly reached Internet users, the rule-based systems dominated the online translation market. It should be noted here that - the rule-based translation appeared long before the Internet and began to advance into the masses with programs for desktop computers, and, a little later, portable (palm-size and handheld) devices. Versions for online users appeared only in the mid-90s, and Sistran, already familiar to us, was most prevalent. In 1996, it became available to Internet users - the system made it possible to translate small texts online. Shortly after this development, Sistrana began using AltaVista search engine, launching the BabelFish service, which successfully survived in Yahoo until 2012. PROMT-online, which appeared in the form of a web application in 1998 and quickly became popular in runet, used its own technologies, but also worked in the rule-based machine translation paradigm.
The pioneer of statistical online translation Google launched the first version of the Translate service only in 2007, but very quickly gained universal popularity. Now the service offers not only translation for more than 70 languages, but also many useful tools such as error correction, dubbing, etc. ... In its wake comes the not so popular, but quite powerful and actively developing online translator from Microsoft, offering translation for more than 50 languages. In 2011, Yandex.Translate appeared, which now supports more than 40 languages and offers various means of simplifying typing and improving the quality of translation.
 The history of the appearance of Yandex.Transfer began in the summer of 2009, when Yandex began research in the field of statistical machine translation. It all started with experiments with open statistical translation systems, with the development of technologies for searching parallel documents and creating systems for testing and evaluating translation quality. In 2010, we began work on highly efficient translation algorithms and programs for constructing translation models. On March 16, 2011, a public beta version of the Yandex.Translate service was launched with two language pairs: English-Russian and Ukrainian-Russian. In December 2012, a mobile application for the iPhone appeared, after six months a version for Android, and six months later a version for Windows Phone.
The history of the appearance of Yandex.Transfer began in the summer of 2009, when Yandex began research in the field of statistical machine translation. It all started with experiments with open statistical translation systems, with the development of technologies for searching parallel documents and creating systems for testing and evaluating translation quality. In 2010, we began work on highly efficient translation algorithms and programs for constructing translation models. On March 16, 2011, a public beta version of the Yandex.Translate service was launched with two language pairs: English-Russian and Ukrainian-Russian. In December 2012, a mobile application for the iPhone appeared, after six months a version for Android, and six months later a version for Windows Phone.
Here we return to the starting point of the story - the emergence of offline translation. Recall that statistical machine translation was originally designed to work on powerful server platforms with unlimited memory resources. But not so long ago began to move in the opposite direction - the processing of powerful server applications into compact applications for smartphones. Two years ago, the Bing Translator app for Windows Phone learned to work without an internet connection, and in 2013 Google launched the full-text offline translation on the Android platform. Yandex also worked in this direction and now in the Yandex.Translate mobile application for iOS, it became possible to use the offline dictionary, and now the full-text translation. What used to require a floor with a mainframe system, and then a powerful server with dozens of gigabytes of RAM, today fits in a pocket or purse and works autonomously - without accessing a remote server. Such a translator will work where there is no Internet yet - high above the clouds, twenty thousand leagues under the water and even in space.
Summing up, it can be said that tremendous progress has been made in the field of machine translation over the past decades. And although it is still very far from an instant and imperceptible translation from any language of the galaxy, the fact that a huge leap has been made in this area over the past few decades is beyond doubt, one hopes that new generations of machine translation systems will be steadily strive for it.
“This is all done by the machine”, “The electronic brain translates from Russian to English”, “Robot-bilingual” - such newspaper headlines were seen by readers of the jubilant press on January 8, 1954. A day earlier, on January 7, the IBM 701 science computer took part in the famous Georgetown experiment , translating about sixty Russian phrases into English. "Seven hundred and first" used a dictionary of 250 words and six syntax rules. And, of course, a very carefully selected set of proposals on which testing was conducted. It turned out so convincingly that enthusiastic journalists, with references to scientists, stated that in a few years machine translation would almost completely replace the classic “manual” one.
The Georgetown experiment was one of the first steps in the development of machine translation (and one of the first applications of computers to work with natural language). Then many of the problems of those faced in the future were not so obvious. However, the main problem, ironically, was that it was obvious from the very beginning that the computer was most difficult to work with multiple-valued words. On more or less natural proposals, the system almost completely ceased to cope with the task. The complex multicomponent structure of such systems also created problems: for example, the syntactic analysis did not always work correctly, and the composite word guitar pick (mediator) could be translated as “guitar choice”. Many-valued words were also poorly translated, the meaning of which depended on the context. For example, the text “Little John was looking for his toy box. Finally he found it. The box was in the pen caused (and continues to cause) a lot of difficulties - as the phrase "toy box", translated as "toy box", not "box for toys", and "in the pen", which was translated as "In the handle", and not "in the children's arena." The difficulties were enormous, and as a result in 12 years it was almost impossible to get off the ground. In 1966, the crushing ALPAC report (Automatic Language Processing Advisory Committee) put an end to machine translation research for the next ten years.
')
In the meantime, the mood after the Georgetown experiment was still very bright and machine translation predicted a great future, the Americans began to seriously think about using the new technology for strategic purposes. What was fully realized in the USSR. At the beginning of 1955, two research groups were created by the USSR Academy of Sciences - at the Steklov Mathematical Institute (an outstanding mathematician and cybernetist Alexey Lyapunov became the head of the group) and at the Institute of Precise Mechanics and Computer Engineering of the USSR Academy of Sciences (headed by mathematician D. Yu Panov). Both groups began with a detailed study of the Georgetown experiment, and already in 1956, Panov published a brochure in which he presented the results of the first experiments on machine translation conducted on the BESM computer. In the same 1956 followed the publication of similar studies at the Institute. Steklov for the authorship of Olga Kulagina and Igor Melchuk, which was published in the September issue of the journal Issues of Linguistics. This publication was accompanied by various introductory articles, and it was here that something interesting was discovered: it turned out that in 1933 a certain Petr Petrovich Troyansky, an Esperantist and one of the co-authors of TSB, had addressed the USSR Academy of Sciences with a draft machine translator and a request to discuss this issue with the linguists of the Academy. Scientists were skeptical of the idea: discussions around the project lasted eleven years, after which the connection with Troyan was suddenly lost, and he allegedly left Moscow.This historical find surprised researchers; research began. It was possible to find the copyright certificate of Troyan on the "mechanized dictionary", which allows you to quickly translate texts simultaneously into several languages. After the next plenary session, at which Lyapunov read a report on this invention, the Academy of Sciences established a special committee to study the contribution of the Trojan. A few years passed and, finally, in 1959, the article “The Translation Machine of P. P. Troyansky: a collection of materials about the machine for translation from one language to another, proposed by P. P. Troyansky in 1933” was published. Belskoy and D. Yu. Panova. Soon the author's certificate was published, from which a very original technological solution of the device was visible.
In the project, the Troyansky machine was a table with an inclined surface, in front of which was attached a camera combined with a typewriter. The keyboard of a typewriter consisted of ordinary keys that allowed encoding morphological and grammatical information. The typewriter tape and camera film were to be connected together and fed in synchronization. On the very surface of the table there should have been a so-called “glossary field” - a freely moving plate with words printed on it. Each of the words was accompanied by translations in three, four or more languages. All words had to be given in their initial form and arranged on a board in such a way that the most frequently used words were closer to the center — like letters on a keyboard. The machine operator had to shift the glossary field and take a picture of the word and its translations, while typing on the typewriter the grammatical and morphological information relating to the word. The result was two tapes: one with words in several languages at once, and the second with grammatical explanations to them. When all the original text was typed in this way, the material went to native speakers - auditors, who had to check two tapes and write texts on them in their own languages. Further, the materials were to be transferred to editors who know both languages. Their task was to bring the text to the literary form.
The main idea of the invention is the separation of the translation process into three main stages (by the way, the first and last in modern terminology would be called “pre-editing” and “post-editing”). Interestingly, the most time-consuming processes (coding the source text and synthesizing texts in other languages from this information) require all operators to know their native language.
Thus, the translation was carried out first between the natural language and its logical form, then between the logical forms of the two languages, and then the text in the logical form of the target language was verified and brought to a natural form. Trojan, as a historian of science, undoubtedly knew about the theories of Leibniz and Descartes about the creation of a universal language and translation through interlingua. The proposed technology traces the influence of these theories. Moreover, Troyan was an Esperantist, and built a coding system for grammatical information based on Esperanto grammar (which he was later forced to give up for political reasons).
What is particularly interesting, already in the forties, Troyansky considered the prospects of creating a "powerful transfer device based on modern communication technologies." However, during the lifetime of the ideas of the inventor were met by the academic community with great skepticism and subsequently forgotten. Trojan died in 1950, not very long before it began work on machine translation in the Soviet Union. English machine translation researcher John Hutchins believes that if Trojan’s contribution was not forgotten, the principles of his translation machine would form the basis of the first experiments at BESM, and this would place the inventor in the “fathers” of machine translation along with Warren Weaver. But, unfortunately, the story does not have the subjunctive mood.
Fast forward to forty years in the eighties. After ALPAC, no one except the most desperate enthusiasts had a serious desire to engage in machine translation. However, as is often the case, business has become the engine of progress. At the end of the sixties, the course towards globalization of the world was already evident. International companies faced an urgent need to maintain close trade contacts in several countries at the same time. In the 1980s, the business request for the technology of fast translation of documents and news increased: and here the machine translation was “uncovered”. The European Economic Community, the future European Union, did not lag behind. In 1976, SYSTRAN , the first commercial machine translator in history, was actively used in this organization. In the future, this system became an almost mandatory acquisition of any self-respecting international company: General Motors, Dornier and Aerospatiale. Japan did not stand aside either: the increasing volumes of work with the West were forcing large Japanese corporations to conduct their developments in this area. True, in most cases, they (like Sistran) somehow were variations of rule-based systems, with their well-known “generic” injuries — their inability to work correctly with ambiguous words, homonyms, and idiomatic expressions. Such systems were also very expensive, since creating a dictionary required the work of a large staff of professional linguists, as well as inflexibility — it was quite expensive to adapt to the desired subject area, not to mention the new language. Researchers still preferred to concentrate on systems that used rules, as well as semantic, syntactic and morphological analysis.
A truly new era of machine translation began in the 1990s. The researchers realized that natural language is very difficult to describe formally, and even more difficult to apply formal descriptions to a living text. It was too difficult and resource-intensive task. It was necessary to look for other ways.As usual, when the problem seems practically insoluble, it is useful to change the perspective. IBM reappeared on the scene, one of whose research groups developed a statistical machine translation system called Candide. Specialists approached the task of machine translation from the point of view of information theory. The key idea was the concept of the so-called channel with errors (noisy channel). The model of the channel with errors considers the text in language A as encrypted text in any other language B. And the task of the translator is to decrypt this text.
Let's resort to an amusing illustration. Imagine an Englishman who studies French and came to France to practice it. The train arrived in Paris, and our hero needs to find luggage at the station Gare du Nord. After an unsuccessful search, he finally turns to a passer-by and, having thought over the phrase in English, asks him in French if he knows where to find a luggage room. Conceived English phrase as it “distorts” and turns into a phrase in French. Unfortunately, a passerby turns out to be an Englishman, and he knows French quite badly. He recovers the meaning of the phrase, trying to restore with the help of his knowledge of French and an approximate idea of what his interlocutor most likely had in view of - that is, to put it more simply, tries to guess what English phrase he intended.
IBM'ovtsy worked just with the French and English: in the hands of the research group was a huge number of parallel documents from the Canadian government. The researchers built their translation models as follows: they collected probabilities for all combinations of words of a certain length in two languages and probabilities to match each of these combinations to a combination in another language.
Further, the most likely translation of e , say, into English, for, for example, the French phrase f can be defined as:
where E is all English phrases in the model. As the Englishman tried to guess the thoughts of his compatriot, the algorithm tries to find the most frequent phrase in English, which would have at least some relation to what could potentially be conceived when the French phrase was pronounced.
This simple approach proved to be the most effective. IBM'ovtsy did not apply any linguistic rules, and, in fact, in the group almost no one knew the French language. Despite this, Candide worked, and moreover, it worked quite well! The research results and the overall success of the system were a real breakthrough in the field of machine translation. And most importantly, the experience of Candide proved that it is not necessary to have an expensive staff of first-class linguists to draw up translation rules. The development of the Internet has given access to a huge amount of data needed to create large translation models and language. Researchers have focused on the development of translation algorithms, the collection of cases of parallel texts and the alignment of sentences and words in different languages.
In the meantime, statistical machine translation was in the process of industrial development and slowly reached Internet users, the rule-based systems dominated the online translation market. It should be noted here that - the rule-based translation appeared long before the Internet and began to advance into the masses with programs for desktop computers, and, a little later, portable (palm-size and handheld) devices. Versions for online users appeared only in the mid-90s, and Sistran, already familiar to us, was most prevalent. In 1996, it became available to Internet users - the system made it possible to translate small texts online. Shortly after this development, Sistrana began using AltaVista search engine, launching the BabelFish service, which successfully survived in Yahoo until 2012. PROMT-online, which appeared in the form of a web application in 1998 and quickly became popular in runet, used its own technologies, but also worked in the rule-based machine translation paradigm.
The pioneer of statistical online translation Google launched the first version of the Translate service only in 2007, but very quickly gained universal popularity. Now the service offers not only translation for more than 70 languages, but also many useful tools such as error correction, dubbing, etc. ... In its wake comes the not so popular, but quite powerful and actively developing online translator from Microsoft, offering translation for more than 50 languages. In 2011, Yandex.Translate appeared, which now supports more than 40 languages and offers various means of simplifying typing and improving the quality of translation.
The history of the appearance of Yandex.Transfer began in the summer of 2009, when Yandex began research in the field of statistical machine translation. It all started with experiments with open statistical translation systems, with the development of technologies for searching parallel documents and creating systems for testing and evaluating translation quality. In 2010, we began work on highly efficient translation algorithms and programs for constructing translation models. On March 16, 2011, a public beta version of the Yandex.Translate service was launched with two language pairs: English-Russian and Ukrainian-Russian. In December 2012, a mobile application for the iPhone appeared, after six months a version for Android, and six months later a version for Windows Phone.Here we return to the starting point of the story - the emergence of offline translation. Recall that statistical machine translation was originally designed to work on powerful server platforms with unlimited memory resources. But not so long ago began to move in the opposite direction - the processing of powerful server applications into compact applications for smartphones. Two years ago, the Bing Translator app for Windows Phone learned to work without an internet connection, and in 2013 Google launched the full-text offline translation on the Android platform. Yandex also worked in this direction and now in the Yandex.Translate mobile application for iOS, it became possible to use the offline dictionary, and now the full-text translation. What used to require a floor with a mainframe system, and then a powerful server with dozens of gigabytes of RAM, today fits in a pocket or purse and works autonomously - without accessing a remote server. Such a translator will work where there is no Internet yet - high above the clouds, twenty thousand leagues under the water and even in space.
Summing up, it can be said that tremendous progress has been made in the field of machine translation over the past decades. And although it is still very far from an instant and imperceptible translation from any language of the galaxy, the fact that a huge leap has been made in this area over the past few decades is beyond doubt, one hopes that new generations of machine translation systems will be steadily strive for it.
Source: https://habr.com/ru/post/224445/
All Articles