Twitter has transferred the entire base of tweets to six universities since 2006
Every day, 500 million messages are posted on Twitter. Such an array of information with personal data is a real gold mine for data mining. On the basis of tweets, scientists study patterns in human behavior, social connections, the spread of infectious diseases, risk factors for the human body, and much more, writes the June issue of Scientific American.
For example, researchers from Microsoft have developed an algorithm that, based on the content of a pregnant woman’s tweets, determines the risk of developing postpartum depression. The US Geological Survey tracks tweets to determine the epicenter of an earthquake .
Until now, scientists have been forced to work with a very limited sample of data. The only way to search all tweets was to access the standard Twitter API, and it gives access to only 1% of all messages.
')
But now Twitter has turned to the scientific community. In February, the company announced that it would provide them with a complete base for analysis with all messages, starting in 2006.
In April, Twitter announced it had received more than 1,300 applications from 60+ countries for access to the database for scientific purposes, with more than half of requests coming from outside the United States. After selecting candidates, the company selected six universities from four countries, which agreed to provide information.
Although only selected universities have access, this is still very positive news. In the future, the base will become available to a wider circle of researchers, which may lead to an explosive growth in the number of scientific works based on data mining tweets. With more data, scientists can track more complex and specific patterns. In the end, the base can get into open access.
True, a number of questions inevitably arise. For example, will Twitter get any rights to the results of scientific research? Do I need to ask users for permission to use their data for data mining?
To agree on the nuances in advance, a group of scientists from the Polytechnic University of Virginia proposed the Rules for the ethical use of Twitter data, under which everyone who is going to use data from Twitter can subscribe. Among other things, the rules contain a ban on the publication of user names and nicknames, as well as the requirement to openly declare research objectives. The authors of the document believe that it is important to agree on such rules before a large number of scientific papers made using this database appear in print.
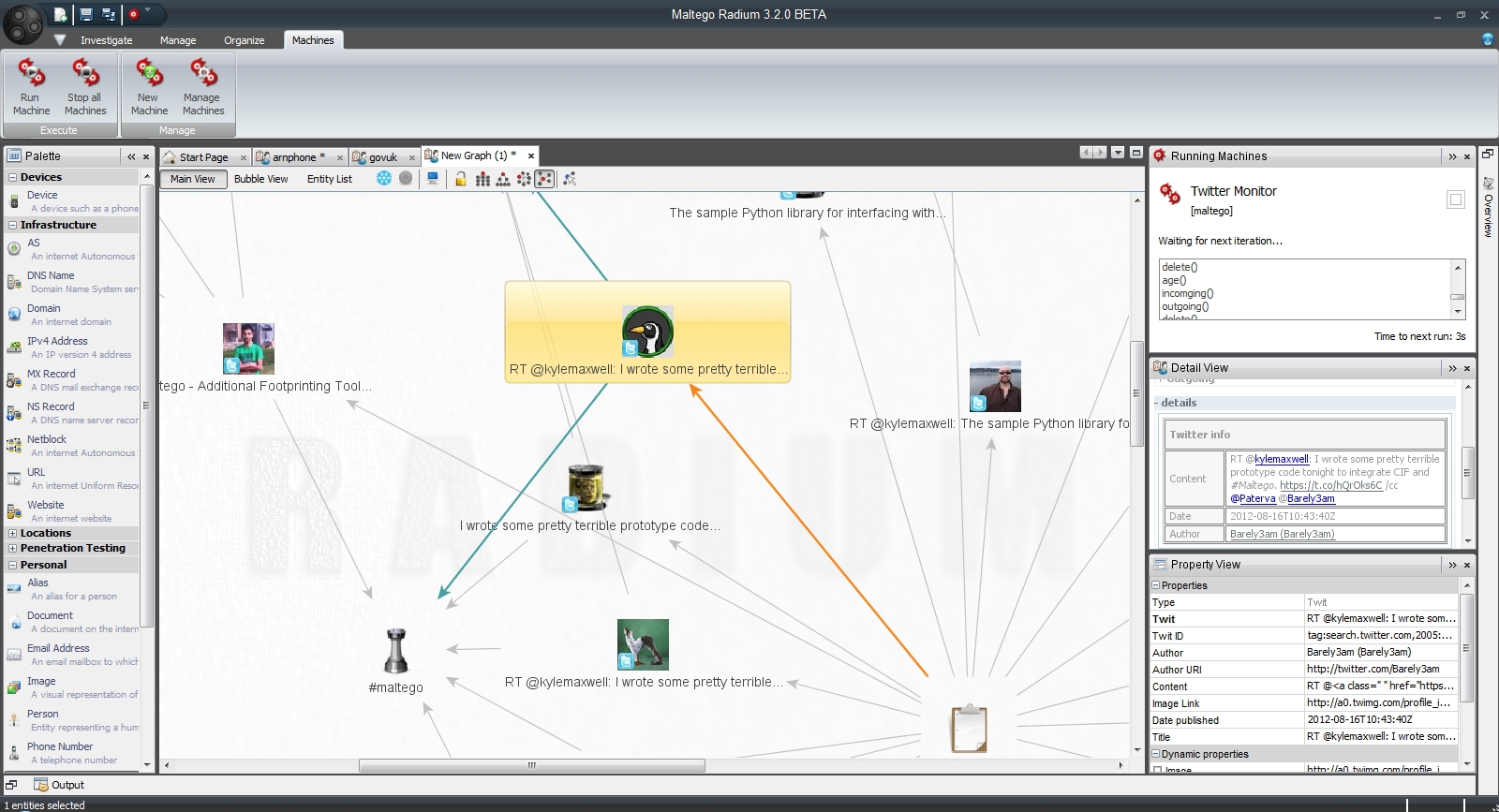
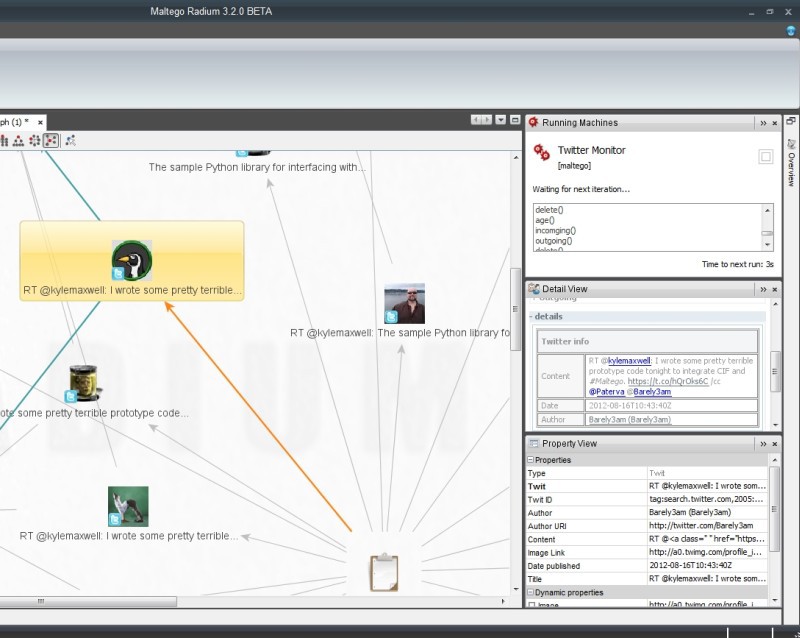
Maltego program
It should be added that software tools have already been developed that directly contradict the Rules of ethical use of Twitter data, namely, they automatically collect data about specific users and organizations. Among such programs are Maltego and Creepy .
Source: https://habr.com/ru/post/224307/
All Articles