In search of the perfect network: OpenFlow and all-all-all
Hello, dear readers,
In this post, we will talk about our search for the perfect network solution for cloud infrastructure and why we decided to stay with OpenFlow.

')
The concept of the cloud is inextricably linked with two abstractions - guaranteed quality of resources and their mutual isolation. Consider how these concepts are applied to the network device in the cloud solution. The isolation of resources implies the following:
Guaranteed quality of resources is QoS in the general sense, that is, providing the required bandwidth and the required response within the cloud network. Further - a detailed analysis of the implementation of the above concepts in cloud infrastructures.
Optimizing routes in such a way as to maximize network link capabilities (in other words, finding the maximum min-cut sum [ 4 ] for all pairs of interacting endpoints, taking into account their weights, that is, QoS priorities), is considered the most difficult task in distributed networks . IGPs designed to solve this problem are generally not flexible enough - traffic can be sorted only on the basis of pre-allocated QoS tags, and you should not think about dynamic analysis and redistribution of traffic. For OpenFlow, since the tools for analyzing individual traffic elements are an integral part of the protocol, solving this problem is quite simple - it is enough to build a correctly working classifier of individual streams [ 5 , 6 ]. Another undoubted advantage of OpenFlow in this case is that in the centralized calculation of the forwarding strategy it is possible to take into account many additional parameters that are simply not included in any of the IGP standards.
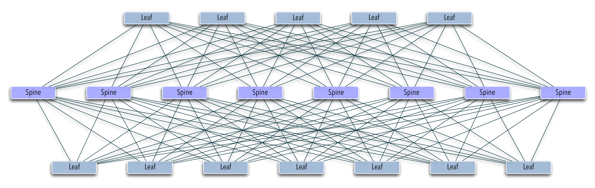
Designing a network even for a small data center with heterogeneous content (simultaneously holding multiple retail users without physically linking a group of machines to a rack), leads to the task of building distributed L2-over-L3 networks (overlay networks) [ 7 ] using one of the existing mechanisms for the inability to technically place tens of thousands of virtual hosts into one broadcast segment in the usual way. These technologies allow to “unload” the logic of forwarding, since the equipment now operates with tags corresponding to groups of hosts instead of individual addresses in private (and, possibly, public) segments of user networks. For cheapness and comparative ease of implementation, there is a binding at least to a network equipment manufacturer and ultimate non-determinism — apart from detailing, all overlay protocols provide a trained switch inside a separate label, which can cause difficulties in optimizing traffic within the overlay segment, due to “decoupling” third-level routing protocols and mechanisms of the overlay itself. Choosing OpenFlow, we reduce all traffic management to one level of decision making - the network controller. Overlays or replacing their own mechanism can certainly play the same role in reducing the volume of rules in switch aggregators (spine in the picture below), and the optimization of traffic direction on ToR switches (leaf) will occur based on an arbitrary set of metrics, unlike from simple balancing (as, for example, in ECMP).
The OpenFlow standard in the first commercially available version, 1.0, became available as part of iron switches more than a year ago, but this version had several architectural limitations that prevented mass adoption, and the most problematic of them was the lack of multiple consecutive tables for processing, that is, one rule corresponded exactly one pair of interacting end points, without taking into account additional matches [ 8 ]. Using OpenFlow 1.0 in a proactive way (that is, creating all the necessary rules in advance) would lead to a quadratic increase in the number of rules from the number of interacting hosts, as shown in the picture below.

A partial way out of the situation is the use of the learning switch mechanism — that is, the reactive operation of the OpenFlow switch, when the rules are requested every time they do not match any switch already placed in the forwarding table, and after a certain TTL are removed from the switch. The removal strategy can be either “hard” —deletion after a specified period of time after the rule is set, or “soft” - deletion occurs only in the absence of activity for a given period of time “inside” of a specific flow. At the time we started using OF, none of the open software controllers supported the new versions, the above-mentioned pursuit of the flexibility of the management approach focused precisely on the 1.0 standard. The learning switch model justifies itself at a significant number of loads, only applications like counters that generate hundreds and thousands of unique requests per second at the switch level become an unavoidable obstacle for it, it is also subject to a fast spoofing attack — a client that generates packets with unique IP / MAC identifiers, as a minimum, it is able to render the switch of the level of the computation node in idle state, and if you do not take care of restricting PACKET_IN (messages for processing the flow for the controller), then the whole segment nt network.
After all the elements of our network (based on the OpenVSwitch) received an update sufficient to use the 1.3 standard, we immediately switched to it, unloading the controllers and ensuring the forward forwarding performance increase (for recalculation by the average pps) by one and a half or two orders of magnitude, account of the transition to proactive flow for the vast amount of traffic. The need for a distributed analysis of traffic (without pumping the entire volume through the selected classifier nodes with a classic firewall) leaves room for reactive flow - by them we analyze unusual traffic.
Today's support for OpenFlow standards by manufacturers of affordable network equipment ToR in whitebox format [ 9 ] is currently limited to solutions based on Windriver (Intel), Cumulus (Dell) and Debian in Pica8 switches, all other vendors either provide switches of a higher price category or abuse own incompatible extensions / mechanisms. For historical reasons, we use Pica8 as ToR switches, but the policy of the manufacturer who has converted the GPL distribution to a paid subscription greatly limits the scope of potential interaction. Today, Intel ONS or Dell open platforms (based on Trident II ), at a very modest price (<10K $ for 4 * 40G + 48 * 10G), allow you to manage the traffic of several tens of thousands of virtual machines on the scale of an industrial rack with 1-6 TB memory using OpenFlow (1.3+).
Looking back, I would point out additional advantages of such a development - immersion into the problems of program-defined subnets and expansion of one’s own ecosystem. Using OpenFlow for traffic management and Ceph software storage for high data availability allows you to declare yourself as an implementation of a software-defined datacenter , although there is still a lot of work ahead on the path to the ideal.
Thanks for attention!
[one]. libvirt - nwfilter
[2]. NICE
[3]. Openstack neutron
[four]. Max-flow / Min-cut
[five]. B4 - WAN Google Network on OpenFlow
[6]. Detailed analysis of one of the QoS-oriented TE algorithms
[7]. Good article about overlay networks
[eight]. OF: 1.0 vs 1.3 table match
[9]. Why whitebox switches are good for you
In this post, we will talk about our search for the perfect network solution for cloud infrastructure and why we decided to stay with OpenFlow.
')
Introduction
The concept of the cloud is inextricably linked with two abstractions - guaranteed quality of resources and their mutual isolation. Consider how these concepts are applied to the network device in the cloud solution. The isolation of resources implies the following:
- anti-spoofing
- allocation of private network segment,
- public segment filtering to minimize external influences.
Guaranteed quality of resources is QoS in the general sense, that is, providing the required bandwidth and the required response within the cloud network. Further - a detailed analysis of the implementation of the above concepts in cloud infrastructures.
Traffic isolation
- Anti-spoofing using iptables / ebtables or static rules in OpenVSwitch: the cheapest solution, but inconvenient in practice - if linux bridge rules are created using the nwfilter mechanism in libvirt and automatically tightened when the virtual machine starts, for ovs orchestration you will have to monitor the start time and check or update the relevant rules in the switch. Adding or deleting an address or migrating a virtual machine in both cases turns into a non-trivial task shifted to orchestration logic. At the time of launching our service in public use, we used exactly nwfilter [ 1 ], but were forced to switch to OpenFlow 1.0 due to the lack of flexibility of the solution as a whole. It is also worth mentioning a rather exotic method of outbound traffic filtering using netlink for technologies that bypass the host network stack (macvtap / vf), which was not accepted into the core at the time, despite the high commercial demand.
- Anti-spoofing using rack-level rules (ToR switch) when transferring virtual machine ports to it using one of the traffic tunneling mechanisms directly from virtual machine interfaces (see the image below). As advantages of such a solution, it is possible to note the concentration of logic on the switch == no need for its “spreading” in software switches of computational nodes. The traffic route between the machines of the same computation node will always pass through the switch, which may not always be convenient.
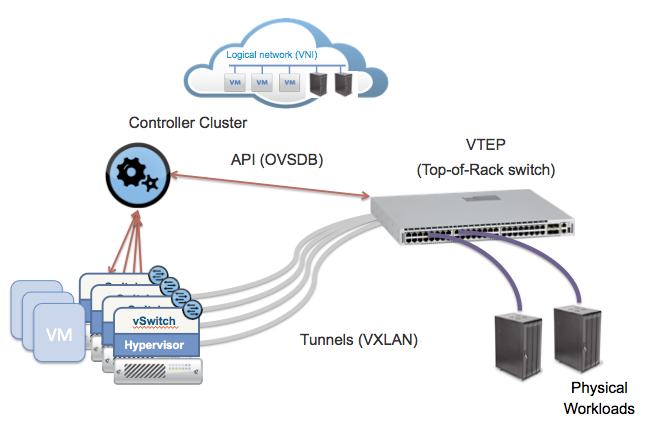
ToR filtering © networkheresy
- Anti-spoofing when checking fields in an OpenFlow network — when all switches, physical and virtual, are connected to a group of controllers that ensure, in addition to redirecting and transforming traffic fields everywhere, it is cleared at the level of a software switch of a compute node. This is the most complex and most flexible of all possible options, since absolutely all the logic, starting from sending datagrams inside an ordinary switch, will be transferred to the controller. Incomplete or inconsistent rules can lead either to a violation of connectivity, or to a violation of isolation, therefore systems with a large percentage of reactive (dynamically defined upon request from a switch) rules should be tested using frameworks like NICE [ 2 ].
- Selection of a network segment is a solution practiced in large homogeneous structures, while the virtual machine group is assigned either to physical machines (and physical switch ports) or to any type of encapsulation tag (vlan / vxlan / gre). The filtering boundary is located at the junction of the L2 segment, in other words, a segment is allocated a subnet or set of subnetworks and the impossibility of replacing them is determined by routing in the higher-level infrastructure, for example, OpenStack Neutron without the Nova hybrid driver [ 3 ]. This approach does not represent a deep theoretical interest, but it has a wide practical prevalence inherited from the pre-virtualization epoch.
Traffic management
Optimizing routes in such a way as to maximize network link capabilities (in other words, finding the maximum min-cut sum [ 4 ] for all pairs of interacting endpoints, taking into account their weights, that is, QoS priorities), is considered the most difficult task in distributed networks . IGPs designed to solve this problem are generally not flexible enough - traffic can be sorted only on the basis of pre-allocated QoS tags, and you should not think about dynamic analysis and redistribution of traffic. For OpenFlow, since the tools for analyzing individual traffic elements are an integral part of the protocol, solving this problem is quite simple - it is enough to build a correctly working classifier of individual streams [ 5 , 6 ]. Another undoubted advantage of OpenFlow in this case is that in the centralized calculation of the forwarding strategy it is possible to take into account many additional parameters that are simply not included in any of the IGP standards.
Designing a network even for a small data center with heterogeneous content (simultaneously holding multiple retail users without physically linking a group of machines to a rack), leads to the task of building distributed L2-over-L3 networks (overlay networks) [ 7 ] using one of the existing mechanisms for the inability to technically place tens of thousands of virtual hosts into one broadcast segment in the usual way. These technologies allow to “unload” the logic of forwarding, since the equipment now operates with tags corresponding to groups of hosts instead of individual addresses in private (and, possibly, public) segments of user networks. For cheapness and comparative ease of implementation, there is a binding at least to a network equipment manufacturer and ultimate non-determinism — apart from detailing, all overlay protocols provide a trained switch inside a separate label, which can cause difficulties in optimizing traffic within the overlay segment, due to “decoupling” third-level routing protocols and mechanisms of the overlay itself. Choosing OpenFlow, we reduce all traffic management to one level of decision making - the network controller. Overlays or replacing their own mechanism can certainly play the same role in reducing the volume of rules in switch aggregators (spine in the picture below), and the optimization of traffic direction on ToR switches (leaf) will occur based on an arbitrary set of metrics, unlike from simple balancing (as, for example, in ECMP).
Two-level spine-leaf
Openflow
The OpenFlow standard in the first commercially available version, 1.0, became available as part of iron switches more than a year ago, but this version had several architectural limitations that prevented mass adoption, and the most problematic of them was the lack of multiple consecutive tables for processing, that is, one rule corresponded exactly one pair of interacting end points, without taking into account additional matches [ 8 ]. Using OpenFlow 1.0 in a proactive way (that is, creating all the necessary rules in advance) would lead to a quadratic increase in the number of rules from the number of interacting hosts, as shown in the picture below.
Comparison of 1.0 and 1.3 © Broadcom Corp
A partial way out of the situation is the use of the learning switch mechanism — that is, the reactive operation of the OpenFlow switch, when the rules are requested every time they do not match any switch already placed in the forwarding table, and after a certain TTL are removed from the switch. The removal strategy can be either “hard” —deletion after a specified period of time after the rule is set, or “soft” - deletion occurs only in the absence of activity for a given period of time “inside” of a specific flow. At the time we started using OF, none of the open software controllers supported the new versions, the above-mentioned pursuit of the flexibility of the management approach focused precisely on the 1.0 standard. The learning switch model justifies itself at a significant number of loads, only applications like counters that generate hundreds and thousands of unique requests per second at the switch level become an unavoidable obstacle for it, it is also subject to a fast spoofing attack — a client that generates packets with unique IP / MAC identifiers, as a minimum, it is able to render the switch of the level of the computation node in idle state, and if you do not take care of restricting PACKET_IN (messages for processing the flow for the controller), then the whole segment nt network.
After all the elements of our network (based on the OpenVSwitch) received an update sufficient to use the 1.3 standard, we immediately switched to it, unloading the controllers and ensuring the forward forwarding performance increase (for recalculation by the average pps) by one and a half or two orders of magnitude, account of the transition to proactive flow for the vast amount of traffic. The need for a distributed analysis of traffic (without pumping the entire volume through the selected classifier nodes with a classic firewall) leaves room for reactive flow - by them we analyze unusual traffic.
About the present
Today's support for OpenFlow standards by manufacturers of affordable network equipment ToR in whitebox format [ 9 ] is currently limited to solutions based on Windriver (Intel), Cumulus (Dell) and Debian in Pica8 switches, all other vendors either provide switches of a higher price category or abuse own incompatible extensions / mechanisms. For historical reasons, we use Pica8 as ToR switches, but the policy of the manufacturer who has converted the GPL distribution to a paid subscription greatly limits the scope of potential interaction. Today, Intel ONS or Dell open platforms (based on Trident II ), at a very modest price (<10K $ for 4 * 40G + 48 * 10G), allow you to manage the traffic of several tens of thousands of virtual machines on the scale of an industrial rack with 1-6 TB memory using OpenFlow (1.3+).
Looking back, I would point out additional advantages of such a development - immersion into the problems of program-defined subnets and expansion of one’s own ecosystem. Using OpenFlow for traffic management and Ceph software storage for high data availability allows you to declare yourself as an implementation of a software-defined datacenter , although there is still a lot of work ahead on the path to the ideal.
Thanks for attention!
Links
[one]. libvirt - nwfilter
[2]. NICE
[3]. Openstack neutron
[four]. Max-flow / Min-cut
[five]. B4 - WAN Google Network on OpenFlow
[6]. Detailed analysis of one of the QoS-oriented TE algorithms
[7]. Good article about overlay networks
[eight]. OF: 1.0 vs 1.3 table match
[9]. Why whitebox switches are good for you
Source: https://habr.com/ru/post/224211/
All Articles