What language can you learn by asking questions to the search engine? Yandex Workshop
The languages in which Internet search users compose their search queries have appeared before our eyes. Lexically, they are poorly distinguishable from more familiar languages, for example, Russian or English, and at the beginning of their existence coincided with their parent languages. But the languages of search queries quickly moved away from the parent and got their own sets of idioms, syntax, and even special "parts of speech." The small size and simplicity of their grammars, as well as the opportunity to study the full set of sentences generated in such languages, make them ideal model objects for testing language learning models.
I did a little research on the query language in which users turn to Yandex search, and based on it I prepared a report. As it often happens, there are more questions than answers. However, the results were quite interesting.
')
I would also like to thank Elena Gruntova for one of the main ideas for research and assistance in preparing the report.
We begin not entirely with the language of search queries, but with the problem of mastering the language and why it is so important for linguistics, cognitive science, and any thinking person may be interested. The problem is that we do not fully understand how children so quickly master a fairly complex conceptual and grammatical apparatus, build up vocabulary at a level at which we still cannot teach a machine to understand natural language. Mysteriousness of the process of mastering the language, people realized in the time of Plato, and even earlier. Throughout this time, two main directions dominate disputes: nativism and empiricism. The nativists believe that in mastering the language, most of the information in our brain is already “protected” in some way, and the empirists claim that we receive most of the information in the learning process based on our own experience.
One of the ideas inherent in nativism is that all natural languages have the same set of features - universals. Nativism also insists on the argument of poverty stimulus, which is designed to explain why a large amount of innate knowledge in mastering the language can not do. It is estimated that by the time the child goes to school, his vocabulary totals about two thousand words. This means that from the moment of birth, he learned one or two new words a day. Each of them he hears no more than a few times, but this is enough for him to understand how these words are modified, combined with each other, to distinguish animate objects from inanimate objects, etc.
When you try to repeat it in machine form in the form of some kind of algorithm that could learn languages at least with a share of the same efficiency, there are some difficulties. First, such a solver is limited by the fact that it receives only positive examples at its entrance, phrases that are permitted by the grammar of the language, and no refutations are received. In addition, some algorithmic constraints are imposed on an algorithm that could simulate language learning. In particular, we cannot afford to sort through all context-free grammars, which would suit all the examples known to us, and choose the simplest. We are not allowed to do this by the fact that this task is NP-complete.
Let's go directly to the query language. My idea is that this is a simpler linguistic object than a full-fledged natural language, but not a trivial set of words. He has his own structure, his developmental logic, and the logic of studying this language by a human being somewhat reminiscent of the logic of studying natural language.
We can observe how the requests of the person who just started using the search engine are gradually changing. There are two strategies: the first queries can consist of naming a single object, or they represent a well-formed and grammatically correct phrase in Russian. After some time, people notice that certain constructions lead them to communicative success. They see that the car has understood them, they achieve the desired result. Other designs do not work. For example, long phrases written in consistent Russian are often not understood by the machine. The user begins to bring their requests to successful designs, to adopt them from other users (including through the sadst). He notes that if at the end of the query you add the magic words “free download”, the machine understands it better, after which he can start adding these words anywhere, even if they do not matter for a particular query.
As is customary in academic linguistics, I will further denote asterisks statements that are unacceptable from the point of view of the grammar of the language being studied. In square brackets are traditionally search queries. Consider three examples:
The second option is valid both in the Russian language and in the query language, the first one is valid only in the query language, and the third one is unacceptable in both, although the agreement is better there than in the first one. We have statistics on the prevalence of queries, and in those cases where we put an asterisk and say that the option is prohibited in the query language, it is understood that such forms of queries are extremely rare.
The Russian version of the query language does not coincide with the usual Russian language, although its lexical composition is almost identical. It appeared around 1997 and has been developing quite actively since then. If at the very beginning the average query length was 1.2 words, then by 2013 this figure had already reached 3.5 words.
Another argument in favor of perceiving the query language as a full-fledged linguistic object is Zipf's law . In natural languages, the nth word in frequency of usage has a frequency of usage roughly proportional to 1 / n. And this dependence is especially clearly visible if we place the graph on a double logarithmic scale. We see that words in the language of questions ideally fall on a straight line with an inclination of 45 degrees, which according to Zipf’s law is a sign of natural language:
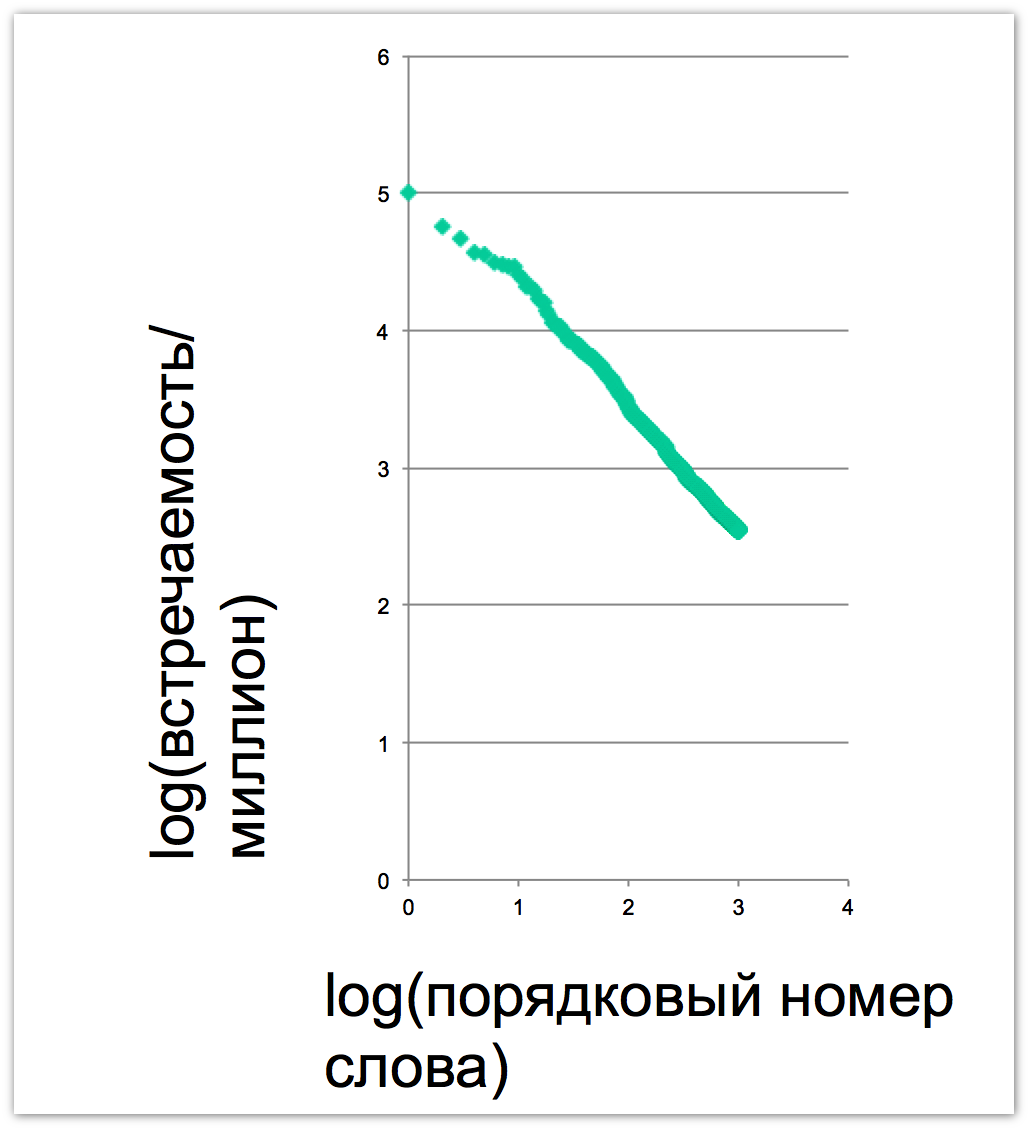
If we compare the vocabulary entropy (that is, how many bits we need on average to describe the occurrence of each next word) of the Russian language and the query language, then for the first one this figure will be about 11 bits (using the examples of L. N. Tolstoy), for the second - about 12. That is. The vocabulary of all people who ask about 4 times more than Tolstoy’s vocabulary. At the same time, it is obvious that the language of requests from the point of view of communications is quite a strange language, since with its help, people do not communicate with each other, but turn to a search engine. Accordingly, the pragmatics of statements are always the same, so the share of some constructions will differ markedly. For example, the proportion of verbs in the query language in the query language is 5.4%, and in Russian - 17.5%. The fact is that they are used with a different function, usually verbs that reflect the user's intention: “download”, “watch”, “listen”. So if you look at the share of the 10 most frequent among all the verbs, then it will be much higher - 46% against 11.4% in Russian. Grammatically, the language is much simpler, since the average phrase length in it does not exceed four words. These are not even full-fledged sentences, but statements. The question arises, is it then possible to speak of the syntax of the query language at all? We think it is possible. In confirmation of this, we consider some examples in which we will see that in the query language we can see constructions that are not typical for the Russian language, but are often found in others, for example, in Japanese.
So far, it is not very clear what happens in the first two queries, but we clearly see that in the third position we have the traditional nominal group, agreed on the genitive case. Now consider the verb group:
We have one object - the “Kruds family trailer”, with which we want to perform a certain action - “watch”. Then we have a language construct, which practically does not occur in Russian - topicalization. It is very common, for example, in Japanese. There you can display a topic - what is being said - bring it to the top of the sentence. In the query language, it is also possible to conduct a topization:
If we assume that this is exactly what is happening, and not some bag of words that people shuffle at random, then we can naturally assume that other constructions should be prohibited. And indeed it is. Constructions that are no worse than the four of the ones we quoted above never occur or are very rare:
We can assume that our hypothesis about topicalization was confirmed, and we will try to figure out what happens in the first two queries about kittens:
It seems that the first query is the original structure, and the second is another example of topicalization.
Having a large body of language, it is possible to evaluate its assimilation statistically using simple tests. The body of the query language is huge simply by its nature. Every day, hundreds of millions of search queries come to Yandex. Correspondingly, corpses for billions of sentences can be taken almost from the air. This allows us not only to evaluate computational models, but also to compare them with each other until the statistical significance of the difference is reached, etc. Let's come up with the simplest task that will help us assess whether the algorithm or model has learned the language and how well. For example, the task of recovering the missing word:
The idea is that in one hundred percent of cases this task cannot be solved, but the better someone has mastered the language, the more percent of cases he will solve this problem. And if we have enough examples, no matter how much the difference between the tested, we can still see it and ensure that it is statistically significant. When working with natural languages, this is most often impossible due to the limited shells.
How can a model be constructed that tries to recover words in this way? The simplest option is N-grams, when we take a sequence of words and say that the probability of the next word in the chain depends only on some previous ones. Then we estimate the probability and substitute this word. Such N-grams can give us the opportunity to restore the previous word, followed by a trace or a word in the middle:
This is not a very interesting model. In fact, we just remembered what constructions are in a language and by no means explicitly generalize anything. It is obvious that a machine that uses only such templates without generalization will be much less proficient in speaking than a machine that applies more complex rules. As such rules we will try to choose the same patterns, in which some words are replaced with sets of different words. For example, we can note that if after the phrase “falcon and *” there are words denoting a book context (file format names, the word “read” or “author”), then the word “swallow” is likely to be omitted.
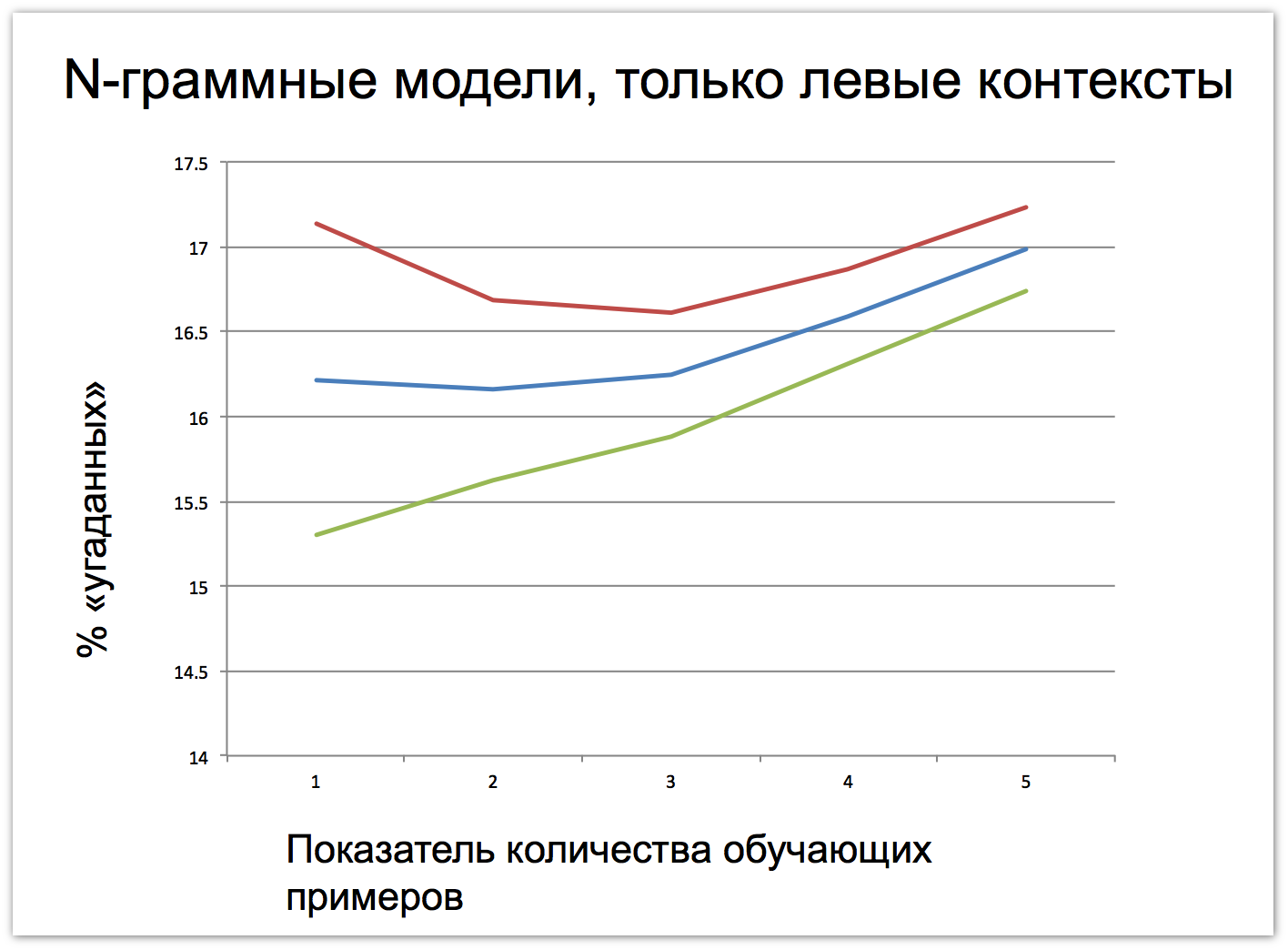
We can also study the level of “knowledge” of a language depending on the number of teaching examples: 3100 phrases, 6200 phrases, 12,400 phrases, 24,800 phrases, 41,000 phrases. The upper bound roughly corresponds to the number of phrases that a child hears in the first two years of life. Potentially, it can be traced exactly when the curve will be bent and new information will cease to arrive. But with 41,000 phrases even on the graphs of N-gram models, it can be seen that the movement does not stop. The blue color on the graph indicates how many percent of the words the model guesses on the tests, and the red and blue marks the intervals of 3Σ. Interestingly, the contexts to the left of the guessing word help define it one percent better. And if you use the right and left contexts simultaneously, the percentage of guessing increases by ten percent.

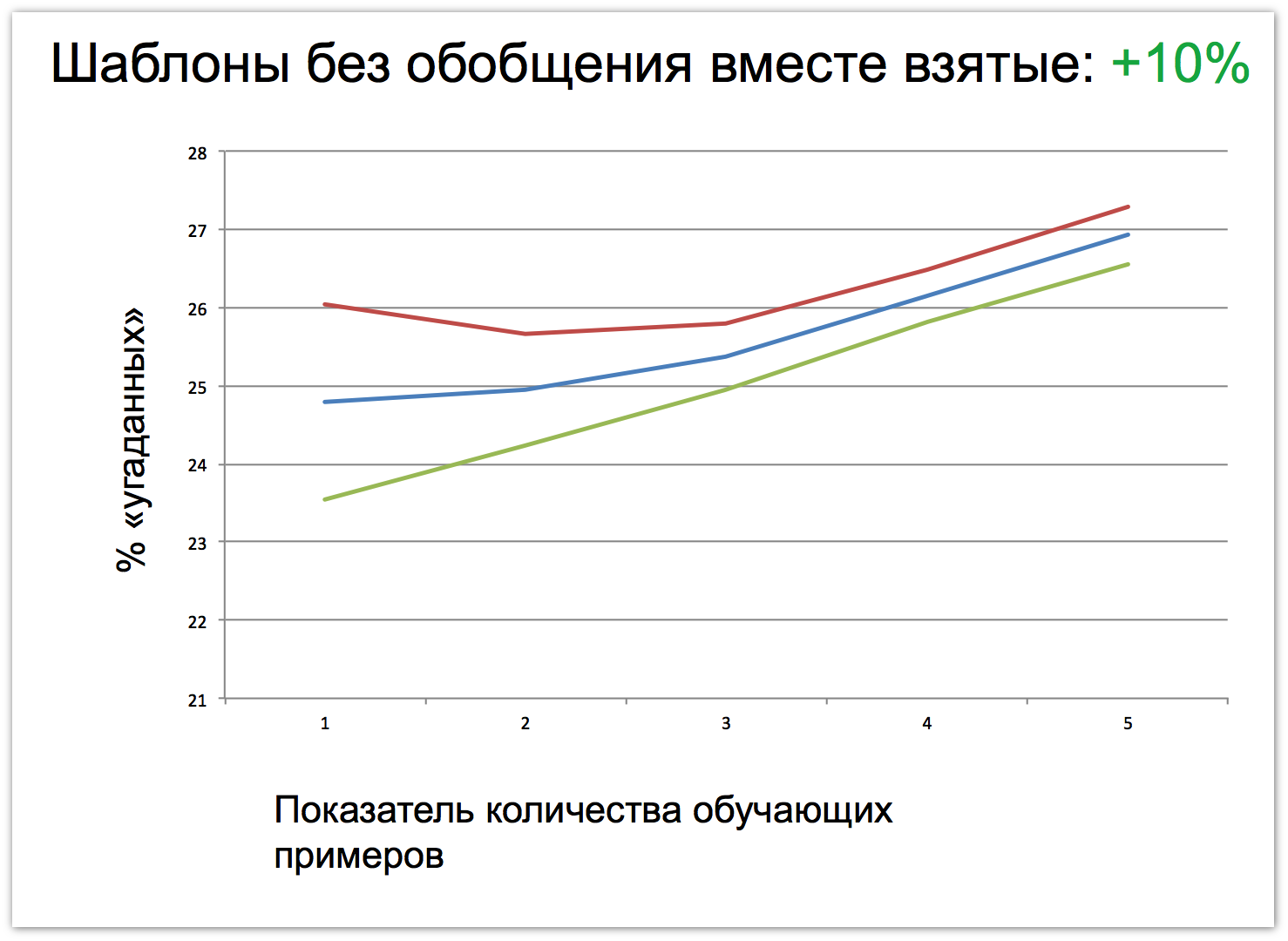
The next breakthrough should happen when we start using generalized patterned constructions. As candidates for this role, we choose two different types: grammatical and context-conceptual. We in Yandex have a wonderful tool - a lemmer. He can tell each word about his lemma and how he came from this lemma to the current form. allows you to determine the initial form of any word. Thus, we can add grammatical context:
In the case of context-sensitive templates, we can try to generalize some sets of words. For example, we can distinguish X as some set of words and phrases for which the expressions [X tuning] and [X price] are valid:
Then the question arises whether it is possible to derive as much information as it is contained in grammes, only from contexts? It would be just fine if we knew that it is possible not to mark parts of speech and not separate grammatical patterns from semantic patterns, but simply to reduce everything to a single conceptual type. If we add generic patterns that use all the available grammar, we get a result that guarantees an increase of 0.2 percent. This is quite ridiculous compared to what we saw above, but it is here somewhere that we are rapidly running into the very ceiling that is very difficult to pierce. But it is he who corresponds to the understanding of the language to which everyone aspires. Context-conceptual templates allow you to achieve an even smaller result - 0.04%. It turns out that the answer to our question is negative: there is more information in the grammes. However, the question of whether it is possible to derive the same information with the help of some stronger generalizations remains open. We did not use the fact that the word forms of the same word are very similar to each other, and the suffixes of different word forms with the same gramme often resemble each other. Is it possible, using such generalizations, to output information equivalent in its strength for solving a test problem only from word usage? And if so, how to formalize this algorithm?
A new linguistic object has grown before our eyes. It is simpler than ordinary natural language. He has one clear goal of communication, the same pragmatist. In addition, we know his complete statistics on word usage, which is pure fiction for any natural language. At the same time, it is still complex enough to remain interesting and lead us to some thoughts about the structure of "real" languages. Many questions still await their researchers:
I did a little research on the query language in which users turn to Yandex search, and based on it I prepared a report. As it often happens, there are more questions than answers. However, the results were quite interesting.
')
I would also like to thank Elena Gruntova for one of the main ideas for research and assistance in preparing the report.
We begin not entirely with the language of search queries, but with the problem of mastering the language and why it is so important for linguistics, cognitive science, and any thinking person may be interested. The problem is that we do not fully understand how children so quickly master a fairly complex conceptual and grammatical apparatus, build up vocabulary at a level at which we still cannot teach a machine to understand natural language. Mysteriousness of the process of mastering the language, people realized in the time of Plato, and even earlier. Throughout this time, two main directions dominate disputes: nativism and empiricism. The nativists believe that in mastering the language, most of the information in our brain is already “protected” in some way, and the empirists claim that we receive most of the information in the learning process based on our own experience.
One of the ideas inherent in nativism is that all natural languages have the same set of features - universals. Nativism also insists on the argument of poverty stimulus, which is designed to explain why a large amount of innate knowledge in mastering the language can not do. It is estimated that by the time the child goes to school, his vocabulary totals about two thousand words. This means that from the moment of birth, he learned one or two new words a day. Each of them he hears no more than a few times, but this is enough for him to understand how these words are modified, combined with each other, to distinguish animate objects from inanimate objects, etc.
When you try to repeat it in machine form in the form of some kind of algorithm that could learn languages at least with a share of the same efficiency, there are some difficulties. First, such a solver is limited by the fact that it receives only positive examples at its entrance, phrases that are permitted by the grammar of the language, and no refutations are received. In addition, some algorithmic constraints are imposed on an algorithm that could simulate language learning. In particular, we cannot afford to sort through all context-free grammars, which would suit all the examples known to us, and choose the simplest. We are not allowed to do this by the fact that this task is NP-complete.
Let's go directly to the query language. My idea is that this is a simpler linguistic object than a full-fledged natural language, but not a trivial set of words. He has his own structure, his developmental logic, and the logic of studying this language by a human being somewhat reminiscent of the logic of studying natural language.
We can observe how the requests of the person who just started using the search engine are gradually changing. There are two strategies: the first queries can consist of naming a single object, or they represent a well-formed and grammatically correct phrase in Russian. After some time, people notice that certain constructions lead them to communicative success. They see that the car has understood them, they achieve the desired result. Other designs do not work. For example, long phrases written in consistent Russian are often not understood by the machine. The user begins to bring their requests to successful designs, to adopt them from other users (including through the sadst). He notes that if at the end of the query you add the magic words “free download”, the machine understands it better, after which he can start adding these words anywhere, even if they do not matter for a particular query.
As is customary in academic linguistics, I will further denote asterisks statements that are unacceptable from the point of view of the grammar of the language being studied. In square brackets are traditionally search queries. Consider three examples:
- [Eastern music to listen to online]
- [listen online oriental music]
- * [Eastern music to listen to online]
The second option is valid both in the Russian language and in the query language, the first one is valid only in the query language, and the third one is unacceptable in both, although the agreement is better there than in the first one. We have statistics on the prevalence of queries, and in those cases where we put an asterisk and say that the option is prohibited in the query language, it is understood that such forms of queries are extremely rare.
The Russian version of the query language does not coincide with the usual Russian language, although its lexical composition is almost identical. It appeared around 1997 and has been developing quite actively since then. If at the very beginning the average query length was 1.2 words, then by 2013 this figure had already reached 3.5 words.
Another argument in favor of perceiving the query language as a full-fledged linguistic object is Zipf's law . In natural languages, the nth word in frequency of usage has a frequency of usage roughly proportional to 1 / n. And this dependence is especially clearly visible if we place the graph on a double logarithmic scale. We see that words in the language of questions ideally fall on a straight line with an inclination of 45 degrees, which according to Zipf’s law is a sign of natural language:
If we compare the vocabulary entropy (that is, how many bits we need on average to describe the occurrence of each next word) of the Russian language and the query language, then for the first one this figure will be about 11 bits (using the examples of L. N. Tolstoy), for the second - about 12. That is. The vocabulary of all people who ask about 4 times more than Tolstoy’s vocabulary. At the same time, it is obvious that the language of requests from the point of view of communications is quite a strange language, since with its help, people do not communicate with each other, but turn to a search engine. Accordingly, the pragmatics of statements are always the same, so the share of some constructions will differ markedly. For example, the proportion of verbs in the query language in the query language is 5.4%, and in Russian - 17.5%. The fact is that they are used with a different function, usually verbs that reflect the user's intention: “download”, “watch”, “listen”. So if you look at the share of the 10 most frequent among all the verbs, then it will be much higher - 46% against 11.4% in Russian. Grammatically, the language is much simpler, since the average phrase length in it does not exceed four words. These are not even full-fledged sentences, but statements. The question arises, is it then possible to speak of the syntax of the query language at all? We think it is possible. In confirmation of this, we consider some examples in which we will see that in the query language we can see constructions that are not typical for the Russian language, but are often found in others, for example, in Japanese.
- [photo kittens]
- [photo kittens]
- * [kittens photo]
So far, it is not very clear what happens in the first two queries, but we clearly see that in the third position we have the traditional nominal group, agreed on the genitive case. Now consider the verb group:
- [watch trailer family kruds]
- [family kruds trailer to watch]
We have one object - the “Kruds family trailer”, with which we want to perform a certain action - “watch”. Then we have a language construct, which practically does not occur in Russian - topicalization. It is very common, for example, in Japanese. There you can display a topic - what is being said - bring it to the top of the sentence. In the query language, it is also possible to conduct a topization:
- [family kruds trailer to watch]
- [family kruds watch trailer]
If we assume that this is exactly what is happening, and not some bag of words that people shuffle at random, then we can naturally assume that other constructions should be prohibited. And indeed it is. Constructions that are no worse than the four of the ones we quoted above never occur or are very rare:
- * [trailer watch family kruds]
- * [watch family kruds trailer]
We can assume that our hypothesis about topicalization was confirmed, and we will try to figure out what happens in the first two queries about kittens:
- [kittens photo]
- [photo kittens]
It seems that the first query is the original structure, and the second is another example of topicalization.
Computational Models
Having a large body of language, it is possible to evaluate its assimilation statistically using simple tests. The body of the query language is huge simply by its nature. Every day, hundreds of millions of search queries come to Yandex. Correspondingly, corpses for billions of sentences can be taken almost from the air. This allows us not only to evaluate computational models, but also to compare them with each other until the statistical significance of the difference is reached, etc. Let's come up with the simplest task that will help us assess whether the algorithm or model has learned the language and how well. For example, the task of recovering the missing word:
- [in the forest * she-tree in the forest she grew]
- [mp3 * free and without registration]
The idea is that in one hundred percent of cases this task cannot be solved, but the better someone has mastered the language, the more percent of cases he will solve this problem. And if we have enough examples, no matter how much the difference between the tested, we can still see it and ensure that it is statistically significant. When working with natural languages, this is most often impossible due to the limited shells.
How can a model be constructed that tries to recover words in this way? The simplest option is N-grams, when we take a sequence of words and say that the probability of the next word in the chain depends only on some previous ones. Then we estimate the probability and substitute this word. Such N-grams can give us the opportunity to restore the previous word, followed by a trace or a word in the middle:
- [... download without * ...] => registration
- [... * princess pencil] => draw
- [... damn * druon] => kings
This is not a very interesting model. In fact, we just remembered what constructions are in a language and by no means explicitly generalize anything. It is obvious that a machine that uses only such templates without generalization will be much less proficient in speaking than a machine that applies more complex rules. As such rules we will try to choose the same patterns, in which some words are replaced with sets of different words. For example, we can note that if after the phrase “falcon and *” there are words denoting a book context (file format names, the word “read” or “author”), then the word “swallow” is likely to be omitted.
We can also study the level of “knowledge” of a language depending on the number of teaching examples: 3100 phrases, 6200 phrases, 12,400 phrases, 24,800 phrases, 41,000 phrases. The upper bound roughly corresponds to the number of phrases that a child hears in the first two years of life. Potentially, it can be traced exactly when the curve will be bent and new information will cease to arrive. But with 41,000 phrases even on the graphs of N-gram models, it can be seen that the movement does not stop. The blue color on the graph indicates how many percent of the words the model guesses on the tests, and the red and blue marks the intervals of 3Σ. Interestingly, the contexts to the left of the guessing word help define it one percent better. And if you use the right and left contexts simultaneously, the percentage of guessing increases by ten percent.
The next breakthrough should happen when we start using generalized patterned constructions. As candidates for this role, we choose two different types: grammatical and context-conceptual. We in Yandex have a wonderful tool - a lemmer. He can tell each word about his lemma and how he came from this lemma to the current form. allows you to determine the initial form of any word. Thus, we can add grammatical context:
- [(S, im, u) * torrent] => download
- [instruction * (S, dates, units)] => by
In the case of context-sensitive templates, we can try to generalize some sets of words. For example, we can distinguish X as some set of words and phrases for which the expressions [X tuning] and [X price] are valid:
- [knocking * X], allowable [X tuning] and [X price] => engine
Then the question arises whether it is possible to derive as much information as it is contained in grammes, only from contexts? It would be just fine if we knew that it is possible not to mark parts of speech and not separate grammatical patterns from semantic patterns, but simply to reduce everything to a single conceptual type. If we add generic patterns that use all the available grammar, we get a result that guarantees an increase of 0.2 percent. This is quite ridiculous compared to what we saw above, but it is here somewhere that we are rapidly running into the very ceiling that is very difficult to pierce. But it is he who corresponds to the understanding of the language to which everyone aspires. Context-conceptual templates allow you to achieve an even smaller result - 0.04%. It turns out that the answer to our question is negative: there is more information in the grammes. However, the question of whether it is possible to derive the same information with the help of some stronger generalizations remains open. We did not use the fact that the word forms of the same word are very similar to each other, and the suffixes of different word forms with the same gramme often resemble each other. Is it possible, using such generalizations, to output information equivalent in its strength for solving a test problem only from word usage? And if so, how to formalize this algorithm?
Results
A new linguistic object has grown before our eyes. It is simpler than ordinary natural language. He has one clear goal of communication, the same pragmatist. In addition, we know his complete statistics on word usage, which is pure fiction for any natural language. At the same time, it is still complex enough to remain interesting and lead us to some thoughts about the structure of "real" languages. Many questions still await their researchers:
- What are the “parts of speech” in it?
- Is it possible to build a full parser for it?
- What natural languages does it look like?
- How is it developing?
Source: https://habr.com/ru/post/223957/
All Articles