Natural language processing in the task of monitoring campaigning
In this article, we will look at the process of developing a method of controlling election campaigning in the Rostov regional segment of online media using natural language processing and machine learning.
I will also focus on the features and nuances, because the task was quite specialized: it was necessary to single out agitation, and if it could break the law, promptly notify the Electoral Commission. Looking ahead to say that I successfully coped with the task.
In the task of developing a methodology for controlling election campaigning in the Rostov regional segment of Internet media, the following developments are used from several related areas of knowledge:
When creating electronic archives of documents for campaign publications of Internet media, the task of streamlining the information array arises, when documents that are close according to certain informative criteria are grouped into groups called categories, rubrics, collections, clusters, stories, etc.
The intellectual system monitored the election campaign in the Rostov regional segment of the Internet media during the election of deputies of the legislative assembly of the Rostov region of the fifth convocation [1].
The system automatically found and downloaded electronic publications from the regional media sites. After this, intellectual processing of text arrays was performed according to a specially developed algorithm. The algorithm, using linguistic attributes that identify campaign publications, awarded points to each publication. A publication containing campaigning for or against a candidate has a score of at least 10. A publication containing campaigning for or against a candidate and potentially violating the law in force has a score of at least 20.
Reports were generated by the system daily. The report was contained in the xlsx file and opened in any program that works with spreadsheets.
')
The main result of the automated classification system is as follows: the system did not detect campaign publications in the Rostov regional segment of online media hosted by candidates and electoral associations participating in the elections of deputies of the Legislative Assembly of the Rostov Region of 08.09.2013. During the reporting period, the indicators of the monitoring system are as follows:
To develop a method of intellectual processing of data in natural language for the purposes of controlling election campaigning in the Rostov regional segment of online media, the following classification task is set using machine learning in a deductive way:
There are many categories (classes, tags)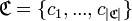 . When processing media publications with texts on campaign issues, four classes are distinguished:
. When processing media publications with texts on campaign issues, four classes are distinguished:
There are many documents, a set of tested publications of Internet media for which it is necessary to determine the class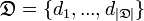 . Unknown target function
. Unknown target function 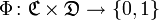 . Necessary to build a classifier
. Necessary to build a classifier 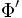 as close as possible to
as close as possible to  .
.
There is some initial collection of markup documents.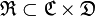 for which the values are known - A set of authentic campaign publications. The collection is divided into "training" and "test" parts. The first is used to train the classifier, the second is to independently verify the quality of its work.
for which the values are known - A set of authentic campaign publications. The collection is divided into "training" and "test" parts. The first is used to train the classifier, the second is to independently verify the quality of its work.
The qualifier can produce an exact answer.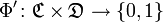 or degree of similarity . The degree of similarity is the percentage of correctly classified documents.
or degree of similarity . The degree of similarity is the percentage of correctly classified documents.
For processing the “training” sample, the so-called “naive” (simplified) Bayes algorithm was chosen. From the point of view of learning speed, stability on various data and ease of implementation, the "naive" Bayes algorithm surpasses almost all known efficient classification algorithms [3].
The algorithm is trained by determining the relative frequencies of the values of all the attributes of the input data with fixed values of the class attributes. Classification is done by applying the Bayes rule to calculate the conditional probability of each class for the vector of input attributes. The input vector is assigned to the class, the conditional probability of which, for a given value of the input attributes, is maximal. The “naivety” of the algorithm consists in the assumption that the input attributes are conditionally (for each value of the class) independent of each other. This assumption is very strong, and, in many cases, wrongful, which makes the fact of classification efficiency using the “naive” Bayes algorithm rather unexpected.
The advantage of the naive Bayes classifier is the small amount of training data needed to evaluate the parameters required for classification.
At the heart of NBC (Naïve Bayes Classifier) is the Bayes theorem.
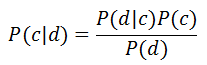
Where,
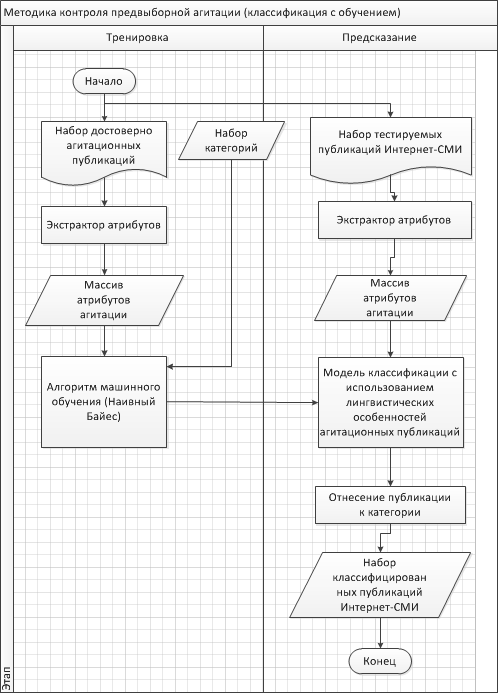
Figure 1. Model of agitation control method
Figure 1 illustrates the algorithm and model of a campaign control campaign that implements machine learning by the Naive Bayes classifier and a specially developed linguistic model of campaign publication, supplementing and refining the result produced by it.
Consider the stages of the model.
1. Indexing documents. At the first stage, an automated collection of Internet media publications and their accumulation in a DBMS for further processing is performed.
2. Construction and training of the classifier.
2.1 Training An array of agitation attributes is distinguished from the array of reliably agitational publications. The naive Bayes classifier allows to identify the most informative attributes and modify them to take into account the context.
2.2 Prediction. In the process of “predicting” the set of tested publications of Internet media is associated with an array of attributes. In the process of solving the research task of creating a method for monitoring election campaigns in the Rostov regional segment of the Internet media, a linguistic model of campaign publications has been developed. The model complements the results of the work of the machine learning module on a training set of campaign publications, adding to the assessment the special linguistic attributes of election campaigning and the rules described below [5].
3. Assessment of the quality of classification. As a result, the technique provides at the output of a qualitatively marked array of Internet media publications.
Let us consider the program component of the complex of means for controlling campaigning in the Rostov regional segment of the Internet media. It uses the following library set:
Regular expressions (PBs) are essentially a tiny programming language, embedded in the Python language and accessible through the re module. Using it, the rules are specified for the set of possible strings to be checked; This set may contain words, phrases, numbers, or email addresses. It also uses the ability to use regular expressions to modify a string or break it into parts for automatic processing of long lists of candidates and parties. As a result of the work of the automatic Bayes classifier, a set of special language constructs (patterns) in the form of bigrams (two words) was obtained.
The software package for controlling campaigning in the Rostov regional segment of the Internet media also includes the function of viewing the most informative attributes. Listing 1 shows 5 such attributes (hereinafter, fragments of program code are presented). For each attribute, a frequency response is available, indicating how one or another attribute is “successful” in the definition of the propaganda text. For example, if a combination of the candidate’s last name is found in the text and any form of the word “vote”, the classifier concludes that this text has a probability of almost 26 chances for one to be campaigning (in percentage expression 96.1%).
Listing 1. Result of the work of the Bayes classifier: found two words and the corresponding probability of agitation.
It is worthwhile to examine in more detail the results of the automatic classifier in order to understand whether it is capable of comprehensively solving the problem of identifying the four classes listed earlier in the problem statement: agitation without violations, agitation with violation of the law, informational publication. After analyzing the results of the classifier, it was revealed that he copes well with the task of separating propaganda publications from informational, that is, those that describe the work of various officials, events or speeches at reports and conferences. In this case, the main task of monitoring is to identify publications with campaigning, potentially violating the law, and this task is more complex. The automation of the Bayes classifier does not cope well with this task: the main reason is the complexity of the Russian language constructs, as well as the presence of emotionally colored phrases, metaphors, allegories, hints that are often used in campaign texts. Thus, the accuracy of determining whether a violation of the law is present needs to be enhanced with additional attributes.
As a result of scientific research, a linguistic model of election campaigning was carried out during the election campaign. Each of the linguistic attributes of the model is included in it with a weighting factor reflecting the importance of a linguistic construct. Thus, the model is a sum of products, a polynomial of the nth degree, according to the number of attributes:
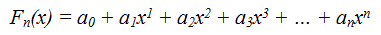
or in abbreviated form:
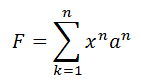
where an - fixed coefficients (points) of importance of the attribute,
x - variable, how many times in the text there is a combination of agitation linguistic attributes.
The model includes a set of special attributes that are linguistic constructions that are automatically found by the developed hardware and software system [1]:
The basis of the model is a complete set of potential candidates whose names will appear in the campaign text in the nominative or other case. Hereinafter, for a brief description of the meeting surname, the designation <surname> will be used, for the party <party>.
In the software implementation, the basic mention of candidates and parties is implemented as follows:
Listing 2. Fragment of the program function: search for mentioning candidates and parties.
A feature of the model is the point system: each publication for each special attribute found in the text is assigned a certain number of points an. For example, if the text mentions a candidate, the publication immediately gets 10 points as a threshold value. If the publication also contains a reference to the Legislative Assembly, the total number of points is 12. Thus, by the number of points it is easy to judge about the potential probability of finding a violation of the law in the publication: if the publication has scored less than 10 points, it is highly likely that it is informational, it contains attributes of political texts, but the contribution of each attribute is not great: 1 or 2 points. In case a publication gains more than 12 points, its content should be analyzed more carefully, since in addition to the candidate's name, it also contains campaign attributes. Almost guaranteed campaigns were publications that had 17 or more points, but in each of them the system found references and an indication of compliance with the legislation on elections to the Legislative Assembly of the Rostov Region.
Let us describe the productive models of tactics used in agitation texts, and also list the most frequent special linguistic constructs that implement these tactics, which were implemented in the classifier's program code [4]:
Linguistic construct "self-presentation". The use of folklore elements of the language - sayings “you can’t make the stone chambers righteous”, “gifts love otdarka”, “gift awaits the gift” - demonstrate the candidate’s community with the audience (simple people), the ability to think the same way as she, to speak one language.
Linguistic construct "motivation". The move is popular: the status quo does not suit me (as well as the voters). I intend to change it as follows: 1) I am going to the Duma, because it must change. 2) Because there should appear people who will raise difficult questions, make the thought work for society ... ”
Linguistic construct "promise". This linguistic construct allows you to automatically find "promises" in the texts. In combination with a set of names of potential candidates, the use of the construct looks like this: I promise, I will, I intend (a), I will, I guarantee, I swear> + <<surname>
Linguistic construct "attraction of authority." “Authoritative opinion” is a powerful tool for influencing the audience. In the role of authority (an influential, respected person - [6, p. 15]) are the individuals, to whose opinion the “object of influence” listens. This linguistic construct allows you to automatically find support structures and lobbying in texts.
Linguistic construct "insult". The strategy of discrediting is the so-called "down strategy". It is aimed at political competitors and is used to destroy the positive image or to emphasize the existing negative image of the "opponent".
The linguistic construct "the legitimacy of agitation." Special attributes are used to automatically verify the fact of payment for publication in the media. The main markers are references to the Legislative Assembly in various funds and an indication of the sources from which payment was made for publication, listing 4.
Listing 4. Fragment of software function: search for mentioning the fact of payment.
Linguistic construct "metaphorical image." As in artistic speech, metaphorization in political discourse is based on analogies, here are particularly characteristic analogies of specific topics related:
with war and struggle (strike, win the battle),
play (make a move, win a game, put on the map, bluff, save trumps),
sports (dragging a rope, get a knockout, put on both shoulder blades),
by hunting (driving into a trap, pointing to a false mark), by a mechanism (levers of power),
the body (growing pains, sprouts of democracy, internal recovery of the city),
theater (play a major role, be a puppet, extra, prompter, come to the fore) and others.
In the campaign materials, you can see the “standard set” of metaphors: “I followed in the footsteps of that”, “passed the entire career ladder”, “it is necessary to put a barrier ...”, “the fate of the city (country) in your hands”. This linguistic construct allows you to automatically find metaphorical images in the texts. In combination with a set of names of potential candidates, the use of the construct looks like this: <metaphorical image> + <surname>
Linguistic construct "role myth." Universal basis of political texts. Roles are popular: “fighter”, “patron”, “servant of the people”, “master”, “economic manager”, etc. The success of a move largely depends on how well the role will meet the expectations of the audience. Example: Alexey Khrustalev knows firsthand about the fight against corruption. He is at war with her as an editor of the Rostov Week, as a deputy of the City Duma. Threats addressed to him repeatedly. And recently, a car was blown up to him - for the attention. But Alexei Khrustalev did not become a deserter, he continues the war against corruption and is fighting for victory in the election of deputies to the Legislative Assembly. This linguistic construct allows you to automatically find the "roles" of candidates in campaign texts.
The main conclusion of the monitoring was a statement of fact: most of the publications contained texts of electoral (or electoral) subjects, but did not have a sufficient number of special linguistic attributes. Publications that scored the maximum number of points, as a rule, were informational. They covered the work of a candidate in his post or contained general summary information about elections, statistics on elections, parties.
The campaign control software package was recommendatory, that is, it promptly informed the competent structures about the situation in the Rostov regional segment of the Internet media, ensuring respect for law and order in the network during the elections of deputies to the Legislative Assembly of the Rostov Region of 08.09.2013.
Soon we will launch the Graph Grail startup with the “Big Data” code slogan in the intellectual analysis of social networks. ” If the topic of natural language processing, graphs and Big data is interesting to you - welcome!
Literature
I will also focus on the features and nuances, because the task was quite specialized: it was necessary to single out agitation, and if it could break the law, promptly notify the Electoral Commission. Looking ahead to say that I successfully coped with the task.
In the task of developing a methodology for controlling election campaigning in the Rostov regional segment of Internet media, the following developments are used from several related areas of knowledge:
- automated text processing (text mining),
- natural language processing
- machine learning.
When creating electronic archives of documents for campaign publications of Internet media, the task of streamlining the information array arises, when documents that are close according to certain informative criteria are grouped into groups called categories, rubrics, collections, clusters, stories, etc.
The intellectual system monitored the election campaign in the Rostov regional segment of the Internet media during the election of deputies of the legislative assembly of the Rostov region of the fifth convocation [1].
The system automatically found and downloaded electronic publications from the regional media sites. After this, intellectual processing of text arrays was performed according to a specially developed algorithm. The algorithm, using linguistic attributes that identify campaign publications, awarded points to each publication. A publication containing campaigning for or against a candidate has a score of at least 10. A publication containing campaigning for or against a candidate and potentially violating the law in force has a score of at least 20.
Reports were generated by the system daily. The report was contained in the xlsx file and opened in any program that works with spreadsheets.
')
The main result of the automated classification system is as follows: the system did not detect campaign publications in the Rostov regional segment of online media hosted by candidates and electoral associations participating in the elections of deputies of the Legislative Assembly of the Rostov Region of 08.09.2013. During the reporting period, the indicators of the monitoring system are as follows:
- Number of media resources: 60
- The number of candidates for deputies: 1161
- Total number of publications analyzed: more than 5000
- Number of suspicious publications found during the entire monitoring period that could potentially violate the law: 5
- Number of publications found that significantly violate election law: 0
To develop a method of intellectual processing of data in natural language for the purposes of controlling election campaigning in the Rostov regional segment of online media, the following classification task is set using machine learning in a deductive way:
There are many categories (classes, tags)
. When processing media publications with texts on campaign issues, four classes are distinguished:- Campaign publication that violates the law
- Campaign publication that does not violate the law
- Non-agitation information paper
- Publication for which no class is defined (definition error)
There are many documents, a set of tested publications of Internet media for which it is necessary to determine the class
. Unknown target function . Necessary to build a classifier as close as possible to .There is some initial collection of markup documents.
for which the values are known - A set of authentic campaign publications. The collection is divided into "training" and "test" parts. The first is used to train the classifier, the second is to independently verify the quality of its work.The qualifier can produce an exact answer.
or degree of similarity . The degree of similarity is the percentage of correctly classified documents.For processing the “training” sample, the so-called “naive” (simplified) Bayes algorithm was chosen. From the point of view of learning speed, stability on various data and ease of implementation, the "naive" Bayes algorithm surpasses almost all known efficient classification algorithms [3].
The algorithm is trained by determining the relative frequencies of the values of all the attributes of the input data with fixed values of the class attributes. Classification is done by applying the Bayes rule to calculate the conditional probability of each class for the vector of input attributes. The input vector is assigned to the class, the conditional probability of which, for a given value of the input attributes, is maximal. The “naivety” of the algorithm consists in the assumption that the input attributes are conditionally (for each value of the class) independent of each other. This assumption is very strong, and, in many cases, wrongful, which makes the fact of classification efficiency using the “naive” Bayes algorithm rather unexpected.
The advantage of the naive Bayes classifier is the small amount of training data needed to evaluate the parameters required for classification.
At the heart of NBC (Naïve Bayes Classifier) is the Bayes theorem.
Where,
- P (c | d) is the probability that the document d belongs to the class c, that is what we need to calculate;
- P (d | c) is the probability to meet document d among all documents of class c;
- P (c) is the unconditional probability of meeting a class c document in the body of documents;
- P (d) is the unconditional probability of document d in the body of documents.
Figure 1. Model of agitation control method
Figure 1 illustrates the algorithm and model of a campaign control campaign that implements machine learning by the Naive Bayes classifier and a specially developed linguistic model of campaign publication, supplementing and refining the result produced by it.
Consider the stages of the model.
1. Indexing documents. At the first stage, an automated collection of Internet media publications and their accumulation in a DBMS for further processing is performed.
2. Construction and training of the classifier.
2.1 Training An array of agitation attributes is distinguished from the array of reliably agitational publications. The naive Bayes classifier allows to identify the most informative attributes and modify them to take into account the context.
2.2 Prediction. In the process of “predicting” the set of tested publications of Internet media is associated with an array of attributes. In the process of solving the research task of creating a method for monitoring election campaigns in the Rostov regional segment of the Internet media, a linguistic model of campaign publications has been developed. The model complements the results of the work of the machine learning module on a training set of campaign publications, adding to the assessment the special linguistic attributes of election campaigning and the rules described below [5].
3. Assessment of the quality of classification. As a result, the technique provides at the output of a qualitatively marked array of Internet media publications.
Let us consider the program component of the complex of means for controlling campaigning in the Rostov regional segment of the Internet media. It uses the following library set:
- Natural Language Processing Library Natural Language Toolkit (NLTK) [2]
- library for processing regular expressions (re)
- corps reliably propaganda materials (materials)
- random variable library
Regular expressions (PBs) are essentially a tiny programming language, embedded in the Python language and accessible through the re module. Using it, the rules are specified for the set of possible strings to be checked; This set may contain words, phrases, numbers, or email addresses. It also uses the ability to use regular expressions to modify a string or break it into parts for automatic processing of long lists of candidates and parties. As a result of the work of the automatic Bayes classifier, a set of special language constructs (patterns) in the form of bigrams (two words) was obtained.
The software package for controlling campaigning in the Rostov regional segment of the Internet media also includes the function of viewing the most informative attributes. Listing 1 shows 5 such attributes (hereinafter, fragments of program code are presented). For each attribute, a frequency response is available, indicating how one or another attribute is “successful” in the definition of the propaganda text. For example, if a combination of the candidate’s last name is found in the text and any form of the word “vote”, the classifier concludes that this text has a probability of almost 26 chances for one to be campaigning (in percentage expression 96.1%).
classifier.show_most_informative_features(5) Most Informative Features suffix(4) = ('', '') agitacia : ne_agitacia = 25.9 : 1.0 suffix(4) = ('', '') agitacia : ne_agitacia = 17.0 : 1.0 suffix(2) = ('', '') agitacia : ne_agitacia= 11.5 : 1.0 suffix(1) = ('', '') ne_agitacia : agitacia = 6.3 : 1.0 suffix(2) = ('', '') ne_agitacia : agitacia = 4.4 : 1.0 Listing 1. Result of the work of the Bayes classifier: found two words and the corresponding probability of agitation.
It is worthwhile to examine in more detail the results of the automatic classifier in order to understand whether it is capable of comprehensively solving the problem of identifying the four classes listed earlier in the problem statement: agitation without violations, agitation with violation of the law, informational publication. After analyzing the results of the classifier, it was revealed that he copes well with the task of separating propaganda publications from informational, that is, those that describe the work of various officials, events or speeches at reports and conferences. In this case, the main task of monitoring is to identify publications with campaigning, potentially violating the law, and this task is more complex. The automation of the Bayes classifier does not cope well with this task: the main reason is the complexity of the Russian language constructs, as well as the presence of emotionally colored phrases, metaphors, allegories, hints that are often used in campaign texts. Thus, the accuracy of determining whether a violation of the law is present needs to be enhanced with additional attributes.
As a result of scientific research, a linguistic model of election campaigning was carried out during the election campaign. Each of the linguistic attributes of the model is included in it with a weighting factor reflecting the importance of a linguistic construct. Thus, the model is a sum of products, a polynomial of the nth degree, according to the number of attributes:
or in abbreviated form:
where an - fixed coefficients (points) of importance of the attribute,
x - variable, how many times in the text there is a combination of agitation linguistic attributes.
The model includes a set of special attributes that are linguistic constructions that are automatically found by the developed hardware and software system [1]:
- calls to vote for a candidate, candidates, list, lists of candidates or against him (them);
- expression of preference for any candidate, electoral association, in particular, indicating for which candidate, for which list of candidates, for which electoral association the voter will vote (except for the case of publishing (publicizing) the results of the public opinion poll);
- a description of the possible consequences in the event that a candidate is elected or is not elected, this or that list of candidates will be allowed or not allowed for the distribution of deputy mandates;
- dissemination of information in which information about any candidate (any candidates), electoral association in combination with positive or negative comments prevail;
- dissemination of information about the activities of the candidate, not related to his professional activities or the performance of his official (official) duties;
- activities contributing to the creation of a positive or negative attitude of the voters towards the candidate, the electoral association that nominated the candidate, the list of candidates.
- note about the payment of material in the Internet media.
The basis of the model is a complete set of potential candidates whose names will appear in the campaign text in the nominative or other case. Hereinafter, for a brief description of the meeting surname, the designation <surname> will be used, for the party <party>.
In the software implementation, the basic mention of candidates and parties is implemented as follows:
if re.search(re.compile('\b(?:%s)\b' + '|'.join(map(re.escape, kandidats_all))), corpus.raw(fileid)): dict_features[fileid][' '] = 10 else: dict_features[fileid][' '] = 0 if re.search(re.compile('\b(?:%s)\b' + '|'.join(map(re.escape, partii_all))), corpus.raw(fileid)): dict_features[fileid][' '] = 1 else: dict_features[fileid][' '] = 0 Listing 2. Fragment of the program function: search for mentioning candidates and parties.
A feature of the model is the point system: each publication for each special attribute found in the text is assigned a certain number of points an. For example, if the text mentions a candidate, the publication immediately gets 10 points as a threshold value. If the publication also contains a reference to the Legislative Assembly, the total number of points is 12. Thus, by the number of points it is easy to judge about the potential probability of finding a violation of the law in the publication: if the publication has scored less than 10 points, it is highly likely that it is informational, it contains attributes of political texts, but the contribution of each attribute is not great: 1 or 2 points. In case a publication gains more than 12 points, its content should be analyzed more carefully, since in addition to the candidate's name, it also contains campaign attributes. Almost guaranteed campaigns were publications that had 17 or more points, but in each of them the system found references and an indication of compliance with the legislation on elections to the Legislative Assembly of the Rostov Region.
Let us describe the productive models of tactics used in agitation texts, and also list the most frequent special linguistic constructs that implement these tactics, which were implemented in the classifier's program code [4]:
Linguistic construct "self-presentation". The use of folklore elements of the language - sayings “you can’t make the stone chambers righteous”, “gifts love otdarka”, “gift awaits the gift” - demonstrate the candidate’s community with the audience (simple people), the ability to think the same way as she, to speak one language.
Linguistic construct "motivation". The move is popular: the status quo does not suit me (as well as the voters). I intend to change it as follows: 1) I am going to the Duma, because it must change. 2) Because there should appear people who will raise difficult questions, make the thought work for society ... ”
Linguistic construct "promise". This linguistic construct allows you to automatically find "promises" in the texts. In combination with a set of names of potential candidates, the use of the construct looks like this: I promise, I will, I intend (a), I will, I guarantee, I swear> + <<surname>
Linguistic construct "attraction of authority." “Authoritative opinion” is a powerful tool for influencing the audience. In the role of authority (an influential, respected person - [6, p. 15]) are the individuals, to whose opinion the “object of influence” listens. This linguistic construct allows you to automatically find support structures and lobbying in texts.
Linguistic construct "insult". The strategy of discrediting is the so-called "down strategy". It is aimed at political competitors and is used to destroy the positive image or to emphasize the existing negative image of the "opponent".
The linguistic construct "the legitimacy of agitation." Special attributes are used to automatically verify the fact of payment for publication in the media. The main markers are references to the Legislative Assembly in various funds and an indication of the sources from which payment was made for publication, listing 4.
if re.search(r'( )|([--][--][--] [--] [--])', corpus.raw(fileid), re.IGNORECASE): dict_features[fileid][' '] = 2 else: dict_features[fileid][' '] = 0 if re.search(r'([--][--][--] [--][--])', corpus.raw(fileid), re.IGNORECASE): dict_features[fileid][' '] = 2 else: dict_features[fileid][' '] = 0 Listing 4. Fragment of software function: search for mentioning the fact of payment.
Linguistic construct "metaphorical image." As in artistic speech, metaphorization in political discourse is based on analogies, here are particularly characteristic analogies of specific topics related:
with war and struggle (strike, win the battle),
play (make a move, win a game, put on the map, bluff, save trumps),
sports (dragging a rope, get a knockout, put on both shoulder blades),
by hunting (driving into a trap, pointing to a false mark), by a mechanism (levers of power),
the body (growing pains, sprouts of democracy, internal recovery of the city),
theater (play a major role, be a puppet, extra, prompter, come to the fore) and others.
In the campaign materials, you can see the “standard set” of metaphors: “I followed in the footsteps of that”, “passed the entire career ladder”, “it is necessary to put a barrier ...”, “the fate of the city (country) in your hands”. This linguistic construct allows you to automatically find metaphorical images in the texts. In combination with a set of names of potential candidates, the use of the construct looks like this: <metaphorical image> + <surname>
Linguistic construct "role myth." Universal basis of political texts. Roles are popular: “fighter”, “patron”, “servant of the people”, “master”, “economic manager”, etc. The success of a move largely depends on how well the role will meet the expectations of the audience. Example: Alexey Khrustalev knows firsthand about the fight against corruption. He is at war with her as an editor of the Rostov Week, as a deputy of the City Duma. Threats addressed to him repeatedly. And recently, a car was blown up to him - for the attention. But Alexei Khrustalev did not become a deserter, he continues the war against corruption and is fighting for victory in the election of deputies to the Legislative Assembly. This linguistic construct allows you to automatically find the "roles" of candidates in campaign texts.
The main conclusion of the monitoring was a statement of fact: most of the publications contained texts of electoral (or electoral) subjects, but did not have a sufficient number of special linguistic attributes. Publications that scored the maximum number of points, as a rule, were informational. They covered the work of a candidate in his post or contained general summary information about elections, statistics on elections, parties.
The campaign control software package was recommendatory, that is, it promptly informed the competent structures about the situation in the Rostov regional segment of the Internet media, ensuring respect for law and order in the network during the elections of deputies to the Legislative Assembly of the Rostov Region of 08.09.2013.
Soon we will launch the Graph Grail startup with the “Big Data” code slogan in the intellectual analysis of social networks. ” If the topic of natural language processing, graphs and Big data is interesting to you - welcome!
Literature
- Federal law of 12.06.2002 N 67-FZ (as amended on 07.05.2013) “On basic guarantees of electoral rights and the right to participate in a referendum of citizens of the Russian Federation”.
- Bird Steven. Natural Language Processing with Python. [Text] - O'Reilly Media Inc, 2009. - ISBN 0-596-51649-5
- Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Draft. [Text] Cambridge University Press. - 2009.
- Communicative strategies and tactics of agitation text and their stylistic representation, [Electronic resource] Abstract, www.userdocs.ru/informatika/8383/index.html?page=5 Access mode: free. - Title from the screen. - Yaz. rus
- "The system of automated construction of the social network graph" Engineering Bulletin of the Don, 2012. №4. [Electronic resource] ivdon.ru/magazine/archive/n4p2y2012/1428 Access mode: free. - Title from the screen. - Yaz. rus
- Explanatory dictionary of the Russian language in 4 vols. // ed. D.N. Ushakov. - M., 2000.
Source: https://habr.com/ru/post/223377/
All Articles