Lock-free stack for Windows

Windows does not like to love. However, often, the phrase: “I did not read the book of the writer, but I condemn it” describes this situation very well. Despite the ingrained contempt for the "Wind", some things in it are implemented very well, and we would like to write about one of them. Some fragments of WinAPI, although they were implemented for a long time, for various reasons, and often unfairly, fell out of sight of a wide audience.
This article will discuss the implementation of the lock-free stack implementation in the OS and the comparison of its performance with cross-platform counterparts.
So, for a long time already in WinAPI there is an implementation of a non-blocking stack based on a single -linked list ( Interlocked Singly Linked Lists ), which is abbreviated SLIST. Implemented initialization operations of such a list and stack primitives on it. Without going into details of the implementation of its SList, Microsoft merely indicates that it uses some kind of non-blocking algorithm to implement atomic synchronization, increase performance, and problems with locks.
Non-blocking, simply-connected lists can be implemented independently, and Maxim Khizhinsky ( khizmax ) has already written about this in detail in his monumental cycle of articles on lock-free algorithms on Habré, in particular, in many details. However, prior to Windows 8, there was no 128-bit CAS operation, which sometimes created problems when implementing such algorithms in 64-bit applications. Slist, therefore, helps to solve this problem.
Implementation
The features of the SList implementation include the memory alignment requirement for list items along the MEMORY_ALLOCATION_ALIGNMENT boundary. However, similar requirements are made for other interlocked operations in WinAPI. For us, this means having aligned_malloc / aligned_free when working with list item memory.
')
Another feature is the requirement that the pointer to the next list item of the SLIST_ENTRY type be located at the very beginning of the structure: to our own fields.
The following is the implementation of a C ++ template that wraps the native WinAPI functions for working with a SList:
C ++ Template Code
template<typename T> class SList { public: SList() { // Let Windows initialize an SList head m_stack_head = (PSLIST_HEADER)_aligned_malloc(sizeof(SLIST_HEADER), MEMORY_ALLOCATION_ALIGNMENT); InitializeSListHead(m_stack_head); //UPD: 22.05.2014, thx to @gridem } ~SList() { clear(); _aligned_free(m_stack_head); } bool push(const T& obj) { // Allocate an SList node node* pNode = alloc_node(); if (!pNode) return false; // Call the object's copy constructor init_obj(&pNode->m_obj, obj); // Push the node into the stack InterlockedPushEntrySList(m_stack_head, &pNode->m_slist_entry); return true; } bool pop(T& obj) { // Pop an SList node from the stack node* pNode = (node*)InterlockedPopEntrySList(m_stack_head); if (!pNode) return false; // Retrieve the node's data obj = pNode->m_obj; // Call the destructor free_obj(&pNode->m_obj); // Free the node's memory free_node(pNode); return true; } void clear() { for (;;) { // Pop every SList node from the stack node* pNode = (node*)InterlockedPopEntrySList(m_stack_head); if (!pNode) break; // Call the destructor free_obj(&pNode->m_obj); // Free the node's memory free_node(pNode); } } private: PSLIST_HEADER m_stack_head; struct node { // The SList entry must be the first field SLIST_ENTRY m_slist_entry; // User type follows T m_obj; }; node* alloc_node() { return (node*)_aligned_malloc(sizeof(node), MEMORY_ALLOCATION_ALIGNMENT); } void free_node(node* pNode) { _aligned_free(pNode); } T* init_obj(T* p, const T& init) { return new (static_cast<void*>(p)) T(init); } void free_obj(T* p) { p->~T(); } }; Performance test
To test the algorithm, a standard test with "manufacturers" and "consumers" was used. However, in addition to each test run, we varied the number of threads of type consumer and type of producer. At the same time, the total number of tasks also changed, since each “producer”, under the conditions of the test, always produces the same number of tasks (iterations) equal to 1 million, in this case. Thus, with the number of threads of the producer type equal to N, the total number of jobs was N * 1M.
SList test code
class test { private: static UMS::SList<int64_t> stack; public: static const char* get_name() { return "MS SList"; } static void producer(void) { for (int i = 0; i != iterations; ++i) { if (!stack.push(++producer_count)) return; } } static void consumer(void) { int64_t value; while (WaitForSingleObject(hEvtDone, 10) != WAIT_OBJECT_0) { while (stack.pop(value)) { ++consumer_count; } } while (stack.pop(value)) { ++consumer_count; } } }; To ensure that consumer workflows do not “thresh” at idle and do not freeze in guaranteed sleep, we used Event synchronization objects of Windows type, so that “consumers” clean up the stack after the “manufacturers” have finished their work. The “consumers” start simultaneously with the “producers”, and by the time the “producers” stop and we activate the hEvtDone event, they already have time to sort out part of the tasks from the stack.
Below is the function that calls our test with the required number of threads:
So we call the test
template<typename T> void run_test(int producers, // Number of producer threads int consumers // Number of consumer threads ) { using namespace std; boost::thread_group producer_threads, consumer_threads; // Initiate a timer to measure performance boost::timer::cpu_timer timer; cout << T::get_name() << "\t" << producers << "\t" << consumers << "\t"; // Reset the counters after the previous test producer_count = consumer_count = 0; done = false; ResetEvent(hEvtDone); // Start all the producer threads with a given thread proc for (int i = 0; i != producers; ++i) producer_threads.create_thread(T::producer); // Start all the consumer threads with a given thread proc for (int i = 0; i != consumers; ++i) consumer_threads.create_thread(T::consumer); // Waiting for the producers to complete producer_threads.join_all(); done = true; SetEvent(hEvtDone); // Waiting for the consumers to complete consumer_threads.join_all(); // Report the time of execution auto nanoseconds = boost::chrono::nanoseconds(timer.elapsed().user + timer.elapsed().system); auto seconds = boost::chrono::duration_cast<boost::chrono::milliseconds>(nanoseconds); auto time_per_item = nanoseconds.count() / producer_count; cout << time_per_item << "\t" << seconds.count() << endl; } The test was run under the following conditions:
- OS: Windows 8 64-bit
- CPU: 4x Intel Core i7-3667U @ 2.00GHz
- RAM: 8GB
- Compiler: Microsoft C / C ++ Optimizing Compiler Version 18.00.21005.1
- Configuration: Release, Static Runtime (/ MT), Optimize Speed (/ Ox), x64 Architecture
- boost: version 1.55
- libcds: version 1.5.0
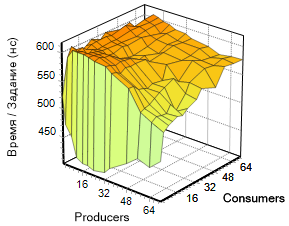
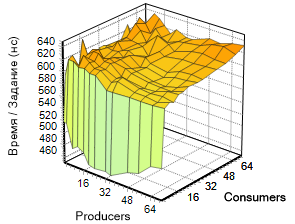
Variations of parameters in two dimensions (consumers, producers) give us the function t (p, c), whose graph is shown in the image on the left.
In order not to have the eyes count the number of zeros in the results, instead of counting the number of tasks per second, we give the time to perform one task in nanoseconds, calculated as the total test time divided by the total number of tasks. The lower this value, the faster the algorithm works.
The number of threads of each type varied in sequence:
int NumThreads[] = { 2, 4, 8, 12, 16, 20, 24, 32, 36, 48, 56, 64, 72 }; Pay attention to this surface. Significant acceleration of the algorithm is noticeable with a small number of consumers (the area of the graph is colored in green). A further increase in the number of streams of both types does not lead to a noticeable change in the speed of work, although it can be seen that the indicator is somewhat “floating” in a narrow corridor, but the graph retains a soothing orange tone.
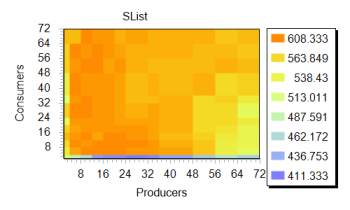
If we consider the same chart in a different version, this border is visible even more clearly. In the image on the right, the fertile blue-green band is very clearly distinguishable, marking the entire region with four “consumers” and an arbitrary number of “producers”, which, by the way, coincides with the number of nuclei in the experiment. Further, it will be shown that other implementations demonstrate similar dynamics. This suggests the similarity of the algorithm used by Microsoft with that used in third-party libraries.
It is gratifying to see that the lock-free approach shines here in all its glory: it is difficult to imagine 72 (+72) streams, with 1 million tasks each hanging in the lock. However, articles about lock-free usually begin with this.
Comparison
An identical test was run on the same computer for the other two implementations of non-blocking containers taken from well-known libraries (boost :: lockfree and libcds) in the following cycle:
int NumThreads[] = { 2, 4, 8, 12, 16, 20, 24, 32, 36, 48, 56, 64, 72 }; for (int p : NumThreads) for (int c : NumThreads) { run_test<lf::boost::test>(p, c); run_test<lf::slist::test>(p, c); run_test<lf::libcds::test>(p, c); } Despite some similarity of implementations, the following are the tests performed for these libraries and the results of each of them.
Boost.Lockfree library
This library is part of the boost relatively recently. It consists of three containers: a queue, a stack, and a ring buffer. Use their classes, as always convenient. There is documentation and even examples.
Below is the code for a similar test using boost :: stack.
Boost test
class test { private: static ::boost::lockfree::stack<int64_t> stack; public: static const char* get_name() { return "boost::lockfree"; } static void producer(void) { for (int i = 0; i != iterations; ++i) { while (!stack.push(++producer_count)); } } static void consumer(void) { int64_t value; while (WaitForSingleObject(hEvtDone, 10)!=WAIT_OBJECT_0) { while (stack.pop(value)) { ++consumer_count; } } while (stack.pop(value)) { ++consumer_count; } } }; We present the results of this test in the form of graphs:
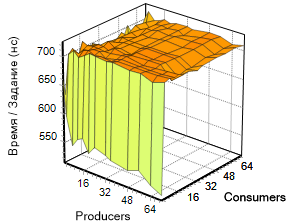
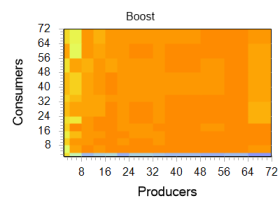
Libcds library
This library is often referenced by khizmax in its articles. Regardless of its consumer qualities, it seemed to us somewhat cumbersome and poorly documented (most of the information was found here in Habré). In addition, in each stream where their lock-free containers are used, you need to attach your thread to their “engine” (probably because of TLS?), Then do it detach and still need to initialize Hazard Pointer somewhere.
Despite the inconceivable number of implemented lock-free containers, for every taste, this library can hardly be called beautiful - you need to get used to it.
Below is the code for a similar test using cds :: container :: TreiberStack:
Libcds test
class xxxstack : public cds::container::TreiberStack<cds::gc::HP, int64_t> { public: cds::gc::HP hzpGC; xxxstack() { cds::Initialize(0); } }; class test { private: static xxxstack stack; public: static const char* get_name() { return "libcds tb"; } static void producer(void) { // Attach the thread to libcds infrastructure cds::threading::Manager::attachThread(); for (int i = 0; i != iterations; ++i) { //int value = ++producer_count; while (!stack.push(++producer_count)); } // Detach thread when terminating cds::threading::Manager::detachThread(); } static void consumer(void) { // Attach the thread to libcds infrastructure cds::threading::Manager::attachThread(); int64_t value; while (WaitForSingleObject(hEvtDone, 10) != WAIT_OBJECT_0) { while (stack.pop(value)) { ++consumer_count; } } while (stack.pop(value)) { ++consumer_count; } // Detach thread when terminating cds::threading::Manager::detachThread(); } }; We present the results of this test in the form of graphs:
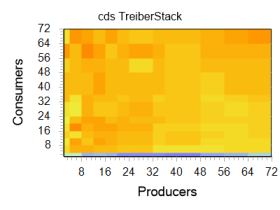
Performance comparison
Despite the fact that SList is a native solution, and the other two are “almost” cross-platform, we believe that the comparison given below is valid, since all the tests were conducted under the same conditions and demonstrate the behavior of libraries under these conditions.

Due to the linear increase in the number of tasks in the test as the number of threads increases, the full implementation of all the options takes a decent amount of time. To stabilize the result, three passes were performed, so the results presented to you above are averaging between three runs.
From the above three-dimensional graphs, it is noticeable that the diagonal (the values of the arguments {p = c}) looks almost a straight line, so for a visual comparison of the three libraries we made a selection of results based on this criterion.
On the left shows what we did.
It can be seen that boost loses to the two other implementations, although it demonstrates greater resistance to changes in input parameters.
The implementations on libcds and SList differ not so much, but throughout the input interval.
findings
It must be admitted that this time Microsoft has created a very good implementation (albeit of only one container), which can successfully compete with algorithms from well-known libraries. Although the implementation described is not cross-platform, it can be useful for Windows application developers.
Download the archive with the source code of the Visual Studio project here.
Used materials
Picture at the beginning of the article
MSDN description slist
Boost.lockfree library
Libcds library
Lock-free data structures. Stack evolution
SList implementation details
UPD:
At the request of mickey99, we had another test: this time I had to take an ordinary std :: stack, access to which was breasted with the usual std :: mutex.
Mutex test
class test { private: static std::stack<int64_t> stack; static std::mutex lock; public: static const char* get_name() { return "mutex"; } static void producer(void) { for (int i = 0; i != iterations; ++i) { lock.lock(); stack.push(++producer_count); lock.unlock(); } } static void consumer(void) { int64_t value; while (WaitForSingleObject(hEvtDone, 10) != WAIT_OBJECT_0) { lock.lock(); if (!stack.empty()) { value = stack.top(); stack.pop(); ++consumer_count; } lock.unlock(); } bool isEmpty = false; while (!isEmpty) { lock.lock(); if (!(isEmpty = stack.empty())) { value = stack.top(); stack.pop(); ++consumer_count; } lock.unlock(); } } }; Let's say right away: it took a long, long time to wait Then the number of tasks per stream was reduced from 1 million to 100K, which, of course, led to not so accurate results (this probably is not required with such numbers), and the set for the number of input streams was changed so that there were fewer points to calculate :
int NumThreads[] = { 2, 4, 8, 16, 32, 64}; Here are the results:

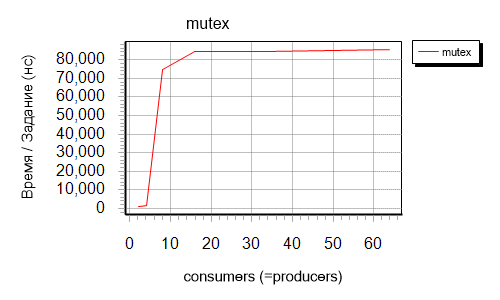
The result is quite indicative: already in the presence of more than 4 streams of any type, the voltage dramatically increases by orders of magnitude. This line is difficult to display on the schedule for the first three. Probably it will be clearer with a logarithmic scale.
Source: https://habr.com/ru/post/223361/
All Articles