Analysis of implicit user preferences. Scientific and Technical Workshop in Yandex
The analysis of implicit user preferences expressed in links and the duration of page views is the most important factor in ranking documents in search results or, for example, showing advertisements and recommending news. Click analysis algorithms are well studied. But is it possible to find out something else about the individual preferences of a person, using more information about his behavior on the site? It turns out that the trajectory of the mouse movement allows you to find out which parts of the document you are viewing are interested in the user.
This issue was devoted to a study conducted by me, Mikhail Ageev , together with Dmitry Lagun and Evgeny Agishtein at Emory Intelligent Information Access Lab of the University of Emory.
')
We studied data collection methods and algorithms for analyzing user behavior by mouse movements, as well as the possibilities of using these methods in practice. They allow you to significantly improve the formation of snippets (annotations) of documents in search results. The work with the description of these algorithms was awarded the Best Paper Shortlisted Nominee diploma at the 2013 ACM SIGIR international conference. Later I presented a report on the results of the work done in the framework of scientific and technical seminars in Yandex. His summary you will find under the cut.
Snippets are the most important part of any search engine. They help users search for information, and the usability of a search engine depends on their quality. A good snippet should be readable, should show the parts of the document that match the user's request. Ideally, the snippet should contain a direct answer to the user's question or an indication that the answer is in the document.
The general principle is that the query text is matched with the text of the document, which highlights the most relevant sentences containing the query words or query extensions. The formula for calculating the most relevant fragments takes into account matches with the query. The density of the text, the location of the text, the structure of the document is taken into account. However, for highly relevant documents that pop up at the top of the search results, textual factors are often not enough. The text may repeatedly contain words from the query, and it is impossible to determine which parts of the text answer the user's question based on textual information only. Therefore, additional factors are required.
When viewing the page, the user's attention is distributed unevenly. The focus is on those fragments that contain the desired information.
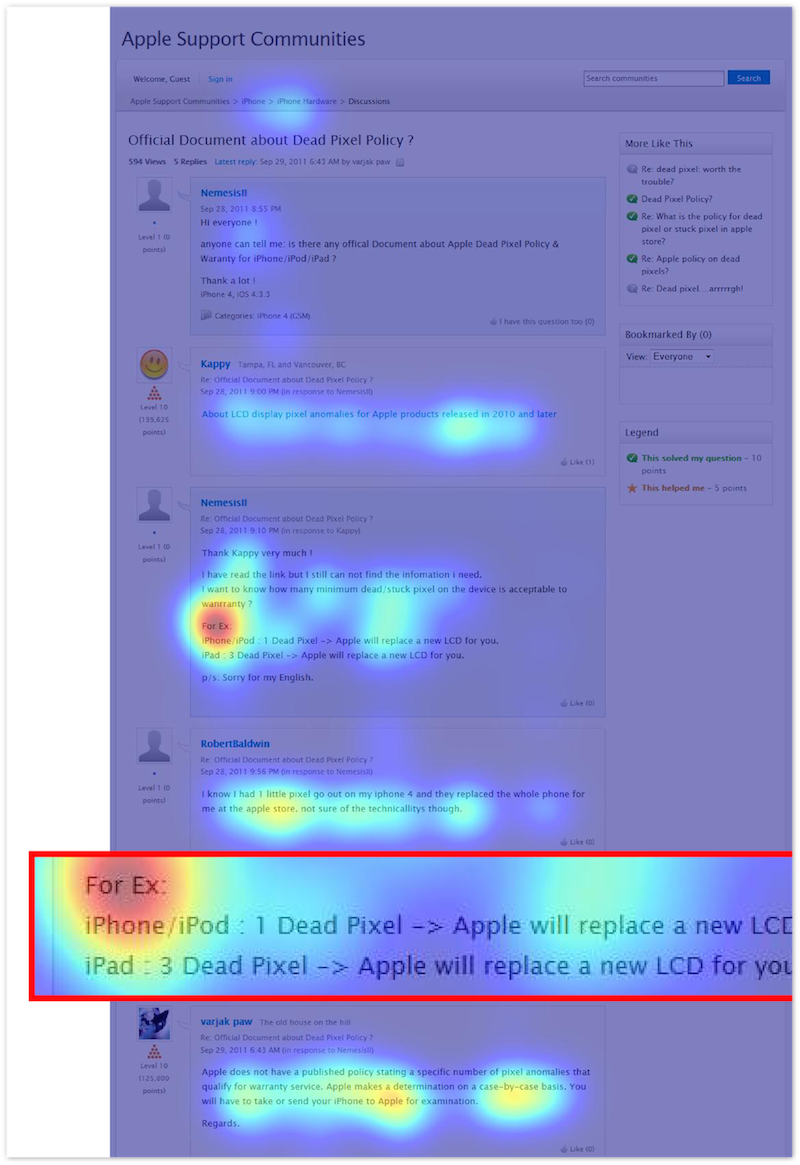
We conducted experiments using equipment that monitors the movement of the eye pupil with an accuracy of several dozen pixels. Here is an example of the distribution of the thermal map of the user's pupil's trajectory, which looked for the answer to the question of how many dead pixels should be on the iPad 3 so that it can be replaced under warranty. He enters a query [how many dead pixels ipad 3 replace], which leads him to the Apple Community Forums page with a similar question. On the page, the words from the request are encountered many times, however, the user focuses on the fragment that actually contains the answer, as can be seen on the heat map.
If we could track and analyze the movements of the pupils of a larger number of users, we could only select ideal snippets for various requests based on this data. The problem is that the users do not have the means for light tracking, so you need to look for other ways to obtain the necessary information.
When browsing web documents, users usually make mouse movements that scroll pages. In their article of 2010, K. Guo and E. Agishtein note that along the trajectory, it is possible to predict the movement of the eye pupil with an accuracy of 150 pixels and a fullness of 70%.
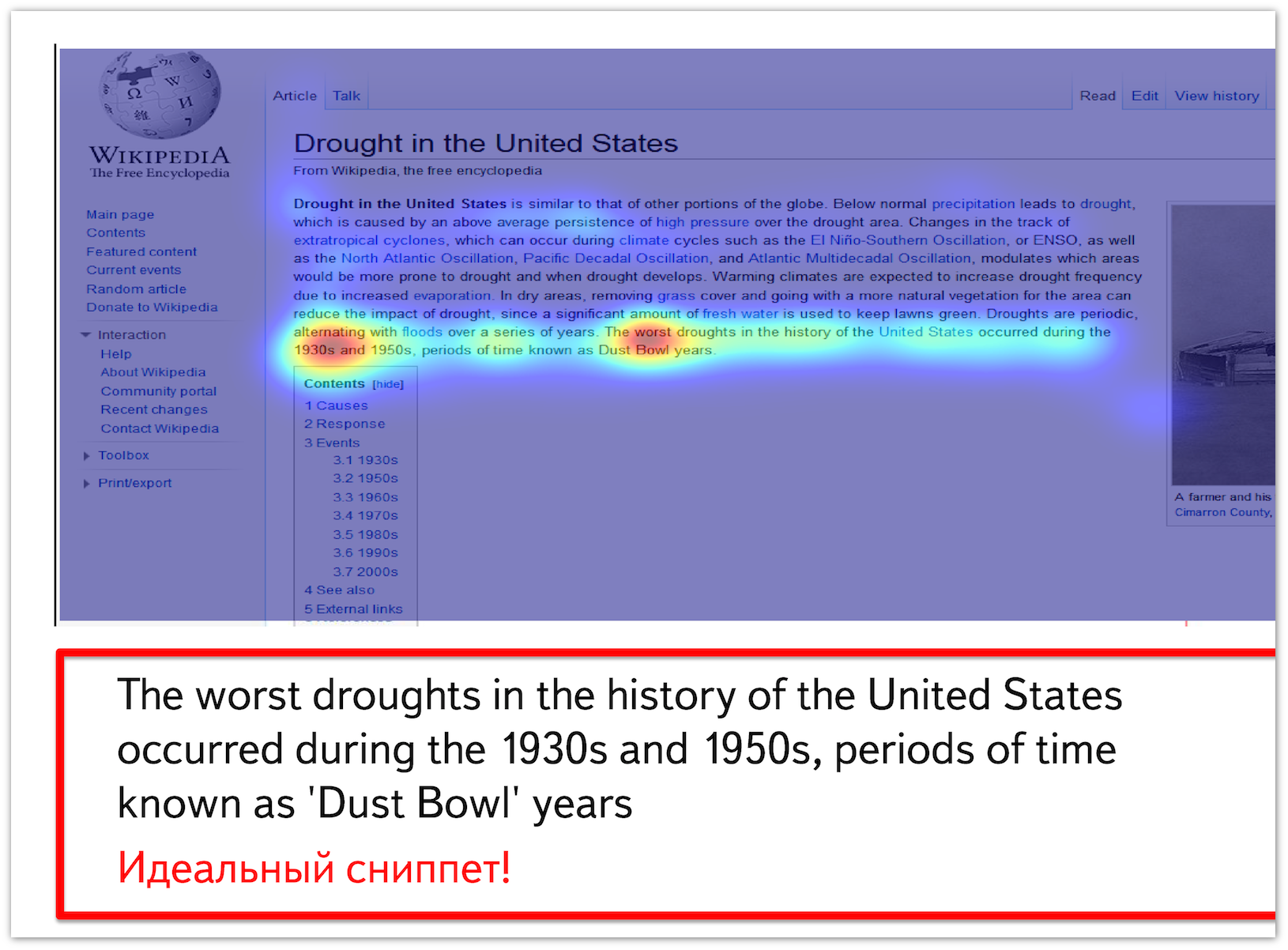
Below is a thermal map of mouse movements when viewing a document found on the query [worst drought in US]. It can be seen that the greatest activity can be traced precisely on a fragment containing information about the strongest droughts in the United States; it is from this that the perfect snippet can be formed.
The idea of our study is that data on mouse movements can be collected using the JavaScript API that works in most browsers. By user behavior, we can predict which fragments contain relevant information for the request, and then use this data to improve the quality of the snippets. In order to implement and test this idea, you need to solve several problems. First, you need to understand how to collect realistic and fairly large-scale data on user behavior behind the search results page. Secondly, you need to learn from the mouse movements to determine the fragments most interesting to the user. Users have different habits: some like to select a readable text or just hover the mouse on it, others open the document and read it from top to bottom, occasionally flipping it down. In this case, users may have different browsers and input devices. In addition, the amount of data on mouse movements is two orders of magnitude higher than the amount of data on clicks. There is also the task of combining behavioral factors with traditional textual ones.
To collect data, we used the infrastructure developed by us in 2011. The main idea is to create a game like Yandex search cup. The player is set a goal for a limited time using the search engine to find the answer to the question on the Internet. The player finds the answer and sends it to us along with the URL of the page where it was found. Selection of participants takes place through Amazon Mechanical Turk. Each game consists of 12 questions. For participation in a game of about forty minutes, a guaranteed payment of $ 1 is assumed. Another one dollar get 25% of the best players. This is a fairly cheap way to collect data, which at the same time provides a wide variety of users from all over the world. Questions were taken on sites Wiki.answers.com, Yahoo! Answers and the like. The main condition was the lack of ready-made answers on these sites themselves. At the same time, the questions should not be too simple, but have a clear short answer that can be found on the Internet. To cut off robots and unscrupulous participants, it was necessary to implement several stages of testing the quality of the results. First, there is a captcha at the entrance to the system, secondly, the user needs to answer 1-2 trivial questions, and third, the user must perform the task using our proxy server, thanks to which we can verify that he really asked questions to the search engine and visited the page with the answer.
Using standard modules for the Apache HTTP server mod_proxy_html and mod_sed, we implemented proxying of all calls to search services. The user came to our page, saw the familiar search engine interface, but all the links there were replaced with ours. By clicking on such a link, the user got to the desired page, but our JavaScript code that tracks behavior has already been embedded in it.
When logging there is a small problem: the position of the mouse is represented by coordinates in the browser window, and the coordinates of the text in it depend on the screen resolution, version and settings. We need an exact binding precisely to the text. Accordingly, we need to calculate the coordinates of each word on the client and store this information on the server.
The results of the experiments were the following data:
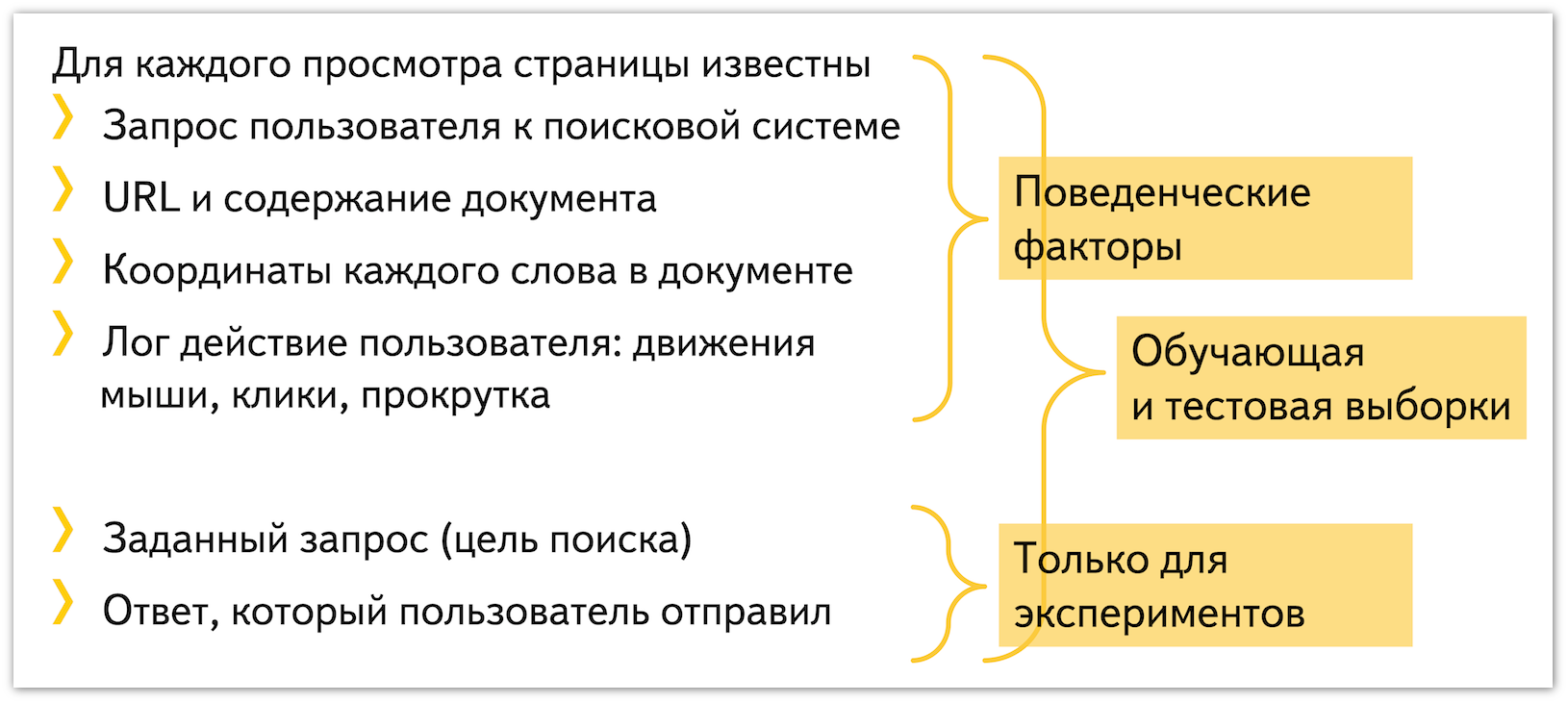
From a statistical point of view, the data is as follows:

The code and collected data are freely available at this link .
To select snippets, the text is divided into fragments of five words. For each fragment, six behavioral factors are identified:
With the help of machine learning, all these six factors are rolled into one number — the probability of a fragment's interestingness. But first we need to create a training set. At the same time, we do not know for certain what really interested the reader, what he read, and where he found the answer. But we can take as positive examples fragments that overlap with the user's response, and all other fragments as negative examples. This training set is inaccurate and incomplete, but it is quite enough for learning the algorithm and improving the quality of snippets.
The first experiment is to test the adequacy of our model. We have trained an algorithm for predicting the interestingness of a fragment on one set of pages and apply it to another set. The graph on the x-axis shows the predicted probability of the fragment interestingness, and on the y-axis the average value of the fragment intersection measure with the user’s response:
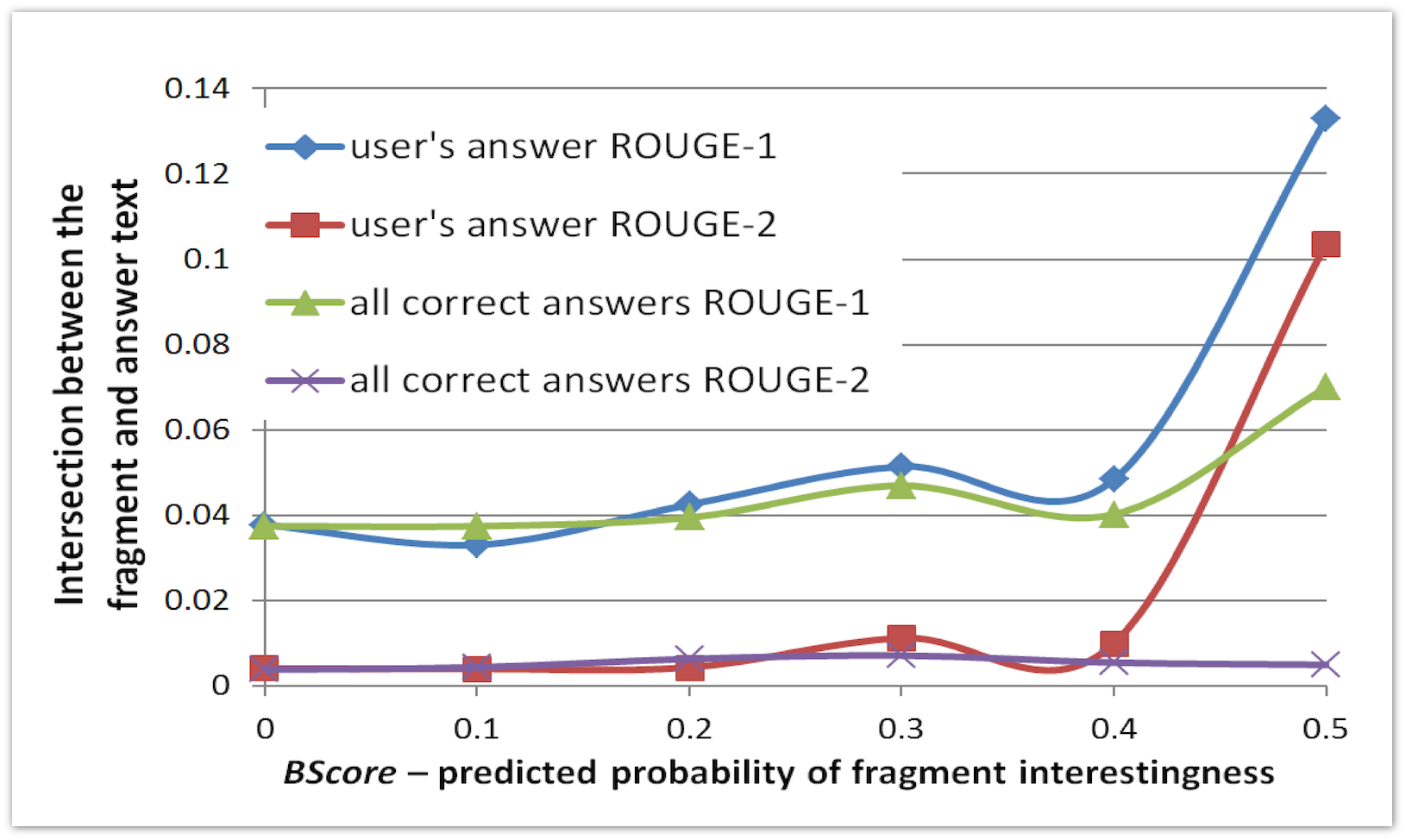
We see that if the algorithm is to a large extent certain that the fragment is good, then this fragment has a large intersection with the user's response.
When building a machine learning method, the most important factors were DispMiddleTime (the time during which a fragment of text was visible on the screen) and MouseOverTime (the time during which the mouse cursor was over a fragment of text).
So, we can determine which fragments interested the user. How can we use this to improve snippets? As a starting point, we implemented a modern algorithm for generating snippets, published by researchers from Yahoo! in 2008. For each sentence, a set of textual factors is computed and a machine learning method is constructed to predict the quality of the fragment in terms of snippet extraction using assessment assessments on a scale {0,1}. Then several machine learning methods are compared: SVM , ranking SVM and GBDT . We added more factors and expanded the rating scale to {0,1,2,3,4,5}. For the formation of a snippet, one to four sentences are selected from the best set. Fragments are selected using a greedy algorithm that collects fragments with total best weight.
We use the following set of textual factors:
Now that we have a fragment weight in terms of textual relevance, we need to combine it with the fragment interestingness factor calculated from the user's behavior. We use a simple linear combination of factors, and the weight λ in the formula for calculating the quality of a fragment is the weight of behavior.

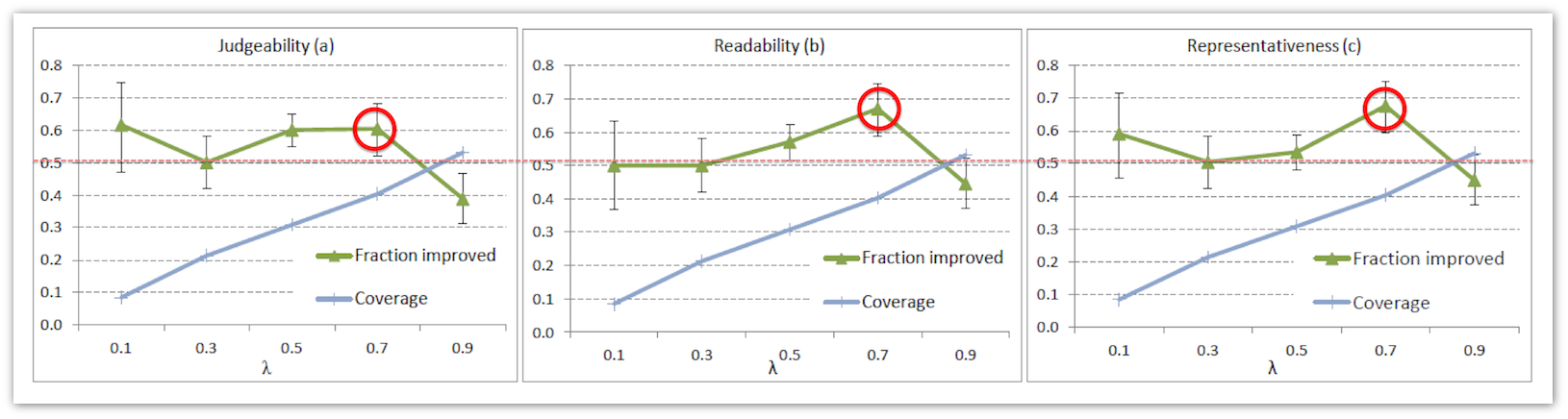
We need to choose the right weight λ. There are two extremes: if the value of λ is too small, then the behavior is not taken into account and the snippets are different from the baseline, if the value of λ is too large, there is a risk that we will lose as snippets. To select λ, we conduct an experiment with the choice of five values from zero to one {0.1.0.3.0.5.0.7.0.9}. To compare the experiments, we scored assessors who compared snippets in pairs according to three criteria:
The graphs below show the proportions of pairs of snippets in which the behavioral algorithm showed an improvement in quality for three criteria and five values of λ. For each of the values of λ, assessors gave a different number of assessments, and different numbers of snippets differ in quality. Therefore, the confidence intervals for each of λ are somewhat different. We see that for λ = 0.7 we get a statistically significant improvement in the quality of the snippet for each of the criteria. Coverage for these snippets is also quite large: 40% of snippets with regard to behavior differ from the baseline.
Firstly, experiments were conducted on informational questions, when the user searches for the text of the answer in documents. However, there are other types of user intent: for example, commercial, navigation. For such requests, behavioral factors may cause interference, or require another way of accounting. Secondly, according to the experiment, we assume that page views are grouped by information need. In our experiments, all users for each pair of document request were looking for the same thing. Therefore, we aggregate data for all users, calculating the average value of the fragment weight for all users. In the real world, users can ask the same query and view the same document for different purposes. And for each request we need to group users by intent in order to be able to apply these methods and aggregate these behaviors. And thirdly, to introduce this technology into a real system, you need to find a way to collect data on user behavior. There are already browser plugins, ad networks and visitor counters that collect data on user clicks. Their functionality can be expanded by adding the ability to collect data on mouse movements.
Among other uses of the method are the following:
After the report, a session of questions and answers took place, which can be viewed on video .
This issue was devoted to a study conducted by me, Mikhail Ageev , together with Dmitry Lagun and Evgeny Agishtein at Emory Intelligent Information Access Lab of the University of Emory.
')
We studied data collection methods and algorithms for analyzing user behavior by mouse movements, as well as the possibilities of using these methods in practice. They allow you to significantly improve the formation of snippets (annotations) of documents in search results. The work with the description of these algorithms was awarded the Best Paper Shortlisted Nominee diploma at the 2013 ACM SIGIR international conference. Later I presented a report on the results of the work done in the framework of scientific and technical seminars in Yandex. His summary you will find under the cut.
Snippets are the most important part of any search engine. They help users search for information, and the usability of a search engine depends on their quality. A good snippet should be readable, should show the parts of the document that match the user's request. Ideally, the snippet should contain a direct answer to the user's question or an indication that the answer is in the document.
The general principle is that the query text is matched with the text of the document, which highlights the most relevant sentences containing the query words or query extensions. The formula for calculating the most relevant fragments takes into account matches with the query. The density of the text, the location of the text, the structure of the document is taken into account. However, for highly relevant documents that pop up at the top of the search results, textual factors are often not enough. The text may repeatedly contain words from the query, and it is impossible to determine which parts of the text answer the user's question based on textual information only. Therefore, additional factors are required.
When viewing the page, the user's attention is distributed unevenly. The focus is on those fragments that contain the desired information.
We conducted experiments using equipment that monitors the movement of the eye pupil with an accuracy of several dozen pixels. Here is an example of the distribution of the thermal map of the user's pupil's trajectory, which looked for the answer to the question of how many dead pixels should be on the iPad 3 so that it can be replaced under warranty. He enters a query [how many dead pixels ipad 3 replace], which leads him to the Apple Community Forums page with a similar question. On the page, the words from the request are encountered many times, however, the user focuses on the fragment that actually contains the answer, as can be seen on the heat map.
If we could track and analyze the movements of the pupils of a larger number of users, we could only select ideal snippets for various requests based on this data. The problem is that the users do not have the means for light tracking, so you need to look for other ways to obtain the necessary information.
When browsing web documents, users usually make mouse movements that scroll pages. In their article of 2010, K. Guo and E. Agishtein note that along the trajectory, it is possible to predict the movement of the eye pupil with an accuracy of 150 pixels and a fullness of 70%.
Below is a thermal map of mouse movements when viewing a document found on the query [worst drought in US]. It can be seen that the greatest activity can be traced precisely on a fragment containing information about the strongest droughts in the United States; it is from this that the perfect snippet can be formed.
The idea of our study is that data on mouse movements can be collected using the JavaScript API that works in most browsers. By user behavior, we can predict which fragments contain relevant information for the request, and then use this data to improve the quality of the snippets. In order to implement and test this idea, you need to solve several problems. First, you need to understand how to collect realistic and fairly large-scale data on user behavior behind the search results page. Secondly, you need to learn from the mouse movements to determine the fragments most interesting to the user. Users have different habits: some like to select a readable text or just hover the mouse on it, others open the document and read it from top to bottom, occasionally flipping it down. In this case, users may have different browsers and input devices. In addition, the amount of data on mouse movements is two orders of magnitude higher than the amount of data on clicks. There is also the task of combining behavioral factors with traditional textual ones.
How to collect data
To collect data, we used the infrastructure developed by us in 2011. The main idea is to create a game like Yandex search cup. The player is set a goal for a limited time using the search engine to find the answer to the question on the Internet. The player finds the answer and sends it to us along with the URL of the page where it was found. Selection of participants takes place through Amazon Mechanical Turk. Each game consists of 12 questions. For participation in a game of about forty minutes, a guaranteed payment of $ 1 is assumed. Another one dollar get 25% of the best players. This is a fairly cheap way to collect data, which at the same time provides a wide variety of users from all over the world. Questions were taken on sites Wiki.answers.com, Yahoo! Answers and the like. The main condition was the lack of ready-made answers on these sites themselves. At the same time, the questions should not be too simple, but have a clear short answer that can be found on the Internet. To cut off robots and unscrupulous participants, it was necessary to implement several stages of testing the quality of the results. First, there is a captcha at the entrance to the system, secondly, the user needs to answer 1-2 trivial questions, and third, the user must perform the task using our proxy server, thanks to which we can verify that he really asked questions to the search engine and visited the page with the answer.
Using standard modules for the Apache HTTP server mod_proxy_html and mod_sed, we implemented proxying of all calls to search services. The user came to our page, saw the familiar search engine interface, but all the links there were replaced with ours. By clicking on such a link, the user got to the desired page, but our JavaScript code that tracks behavior has already been embedded in it.
When logging there is a small problem: the position of the mouse is represented by coordinates in the browser window, and the coordinates of the text in it depend on the screen resolution, version and settings. We need an exact binding precisely to the text. Accordingly, we need to calculate the coordinates of each word on the client and store this information on the server.
The results of the experiments were the following data:
From a statistical point of view, the data is as follows:
The code and collected data are freely available at this link .
Prediction of fragments that interested users
To select snippets, the text is divided into fragments of five words. For each fragment, six behavioral factors are identified:
- The duration of the cursor over the fragment;
- The duration of the cursor next to the fragment (± 100px);
- The average speed of the mouse over the fragment;
- The average speed of the mouse next to the fragment;
- Show time of the fragment in the visible part of the viewing window (scrollabar);
- The time the fragment is displayed in the middle of the viewport.
With the help of machine learning, all these six factors are rolled into one number — the probability of a fragment's interestingness. But first we need to create a training set. At the same time, we do not know for certain what really interested the reader, what he read, and where he found the answer. But we can take as positive examples fragments that overlap with the user's response, and all other fragments as negative examples. This training set is inaccurate and incomplete, but it is quite enough for learning the algorithm and improving the quality of snippets.
The first experiment is to test the adequacy of our model. We have trained an algorithm for predicting the interestingness of a fragment on one set of pages and apply it to another set. The graph on the x-axis shows the predicted probability of the fragment interestingness, and on the y-axis the average value of the fragment intersection measure with the user’s response:
We see that if the algorithm is to a large extent certain that the fragment is good, then this fragment has a large intersection with the user's response.
When building a machine learning method, the most important factors were DispMiddleTime (the time during which a fragment of text was visible on the screen) and MouseOverTime (the time during which the mouse cursor was over a fragment of text).
Improving snippets based on behavioral analysis
So, we can determine which fragments interested the user. How can we use this to improve snippets? As a starting point, we implemented a modern algorithm for generating snippets, published by researchers from Yahoo! in 2008. For each sentence, a set of textual factors is computed and a machine learning method is constructed to predict the quality of the fragment in terms of snippet extraction using assessment assessments on a scale {0,1}. Then several machine learning methods are compared: SVM , ranking SVM and GBDT . We added more factors and expanded the rating scale to {0,1,2,3,4,5}. For the formation of a snippet, one to four sentences are selected from the best set. Fragments are selected using a greedy algorithm that collects fragments with total best weight.
We use the following set of textual factors:
- Exact match;
- Number of query words and synonyms found (3 factors);
- BM25- like (4 factors);
- The distance between the query words (3 factors);
- The length of the sentence;
- Position in the document;
- Readability: the number of punctuation marks, headwords, various words (9 factors).
Now that we have a fragment weight in terms of textual relevance, we need to combine it with the fragment interestingness factor calculated from the user's behavior. We use a simple linear combination of factors, and the weight λ in the formula for calculating the quality of a fragment is the weight of behavior.
We need to choose the right weight λ. There are two extremes: if the value of λ is too small, then the behavior is not taken into account and the snippets are different from the baseline, if the value of λ is too large, there is a risk that we will lose as snippets. To select λ, we conduct an experiment with the choice of five values from zero to one {0.1.0.3.0.5.0.7.0.9}. To compare the experiments, we scored assessors who compared snippets in pairs according to three criteria:
- Representativeness: which snippet better reflects the document compliance with the query? You must read the document before answering the question.
- Readability: which snippet is better written, easier to read?
- Judjeability: which of the snippets best helps to find the relevant answer and decide whether to click on the link?
The graphs below show the proportions of pairs of snippets in which the behavioral algorithm showed an improvement in quality for three criteria and five values of λ. For each of the values of λ, assessors gave a different number of assessments, and different numbers of snippets differ in quality. Therefore, the confidence intervals for each of λ are somewhat different. We see that for λ = 0.7 we get a statistically significant improvement in the quality of the snippet for each of the criteria. Coverage for these snippets is also quite large: 40% of snippets with regard to behavior differ from the baseline.
Basic assumptions and limitations of the considered approach
Firstly, experiments were conducted on informational questions, when the user searches for the text of the answer in documents. However, there are other types of user intent: for example, commercial, navigation. For such requests, behavioral factors may cause interference, or require another way of accounting. Secondly, according to the experiment, we assume that page views are grouped by information need. In our experiments, all users for each pair of document request were looking for the same thing. Therefore, we aggregate data for all users, calculating the average value of the fragment weight for all users. In the real world, users can ask the same query and view the same document for different purposes. And for each request we need to group users by intent in order to be able to apply these methods and aggregate these behaviors. And thirdly, to introduce this technology into a real system, you need to find a way to collect data on user behavior. There are already browser plugins, ad networks and visitor counters that collect data on user clicks. Their functionality can be expanded by adding the ability to collect data on mouse movements.
Among other uses of the method are the following:
- Improved Click Model by predicting P (Examine | Click = 0). If we only track clicks, then we can’t say with certainty why the user didn’t click on the link in the search results. He could read the snippet, and decide that the document is irrelevant, or he simply did not see the document. With the use of mouse tracking, this problem disappears, and we can significantly improve the prediction of the relevance of the document.
- Behavior of users on mobile devices.
- Classification of mouse movements by intent. If you complicate the model, you can learn to distinguish random mouse movements from intentional ones, when the user really helps himself to read with the cursor. In addition, you can take into account moments of inactivity as one of the additional signs of interest of the fragment.
After the report, a session of questions and answers took place, which can be viewed on video .
Source: https://habr.com/ru/post/223121/
All Articles