Moving from MongoDB Full Text to ElasticSearch
In my last post , with the Google Chrome extension for Likeastore , I mentioned the fact that we started using ElasticSeach as a search index. It was ElasticSeach that gave a fairly good performance and quality of search, after which it was decided to release an extension to chrome.
In this post, I’ll tell you that using MongoDB + ElasticSeach, there is a very effective NoSQL solution, and how to switch to ElasticSearch if you already have MongoDB.
Search functionality, the essence of our application. The ability to find something quickly among thousands of our likes was what we started this project for.
We had no deep knowledge of the theory of full-text search, and as the first approach we decided to try MongoDB Full Text Search. Despite the fact that in version 2.4 full text is an experimental feature, it worked pretty well. Therefore, for some time we left it, switching to more urgent tasks.
')
Time passed and the database grew. The collection on which we carry out the indexation began to type a certain size. Starting from the size of 2 million documents, I began to notice a general decline in application performance. This manifested itself in the form of a long opening of the first page, and an extremely slow search.
All this time I have been looking at specialized search storages like ElasticSearch , Solr or Shpinx . But as it often happens in a startup, until “thunder breaks out, the peasant will not overwrite”.
Thunder "struck" 2 weeks ago, after the publication on one of the resources, we experienced a sharp increase in traffic and greater user activity. New Relic sent scary letters stating that the application was not responding, and his own attempts to open the application showed that the patient was more likely alive than dead, but everything worked extremely slowly.
A quick analysis showed that most HTTP requests fall off from 504, after the calls to MongoDB. We are hosted on MongoHQ, but when we tried to open the monitoring console, nothing came of it. The base was loaded to the very limit. After the console was still able to open, I saw that Locked% went to the sky-high 110-140% and kept there, not going to go down.
The service that collects user likes, makes quite a few inserts, and each such insert entails a re-calculation of the full-text index, this is an expensive operation, and reaching certain restrictions (including server resources), we simply rested against it limit.
Data collection had to be disabled, the full-text index was deleted. After the restart, the Locked index service did not exceed 0.7%, but if the user tried to search for something, we had to respond with an inconvenient “sorry, search is on maintenance” ...
I decided to see what Elastic is, having tried it on my car. For that kind of experiments, there has always been (there is, and I hope will be) vagrant .
ElasticSeach is written in Java, and requires proper runtime.
Then you can check whether everything is fine by running
Elastic itself is extremely easy to install. I recommend installing from a Debian package, because in this form it is easier to configure it to run as a service and not as a process.
After that, it's ready to launch,
Having opened the browser and having followed the link, we receive approximately such answer.
Full deployment takes about 10 minutes.
ElasticSearch is an interface built on top of Lucene technology. It is without exaggeration the most complex technology, honed over the years, in which thousands of labor hours of high-end engineers were invested. Elastic makes this technology available to mere mortals, and does it very well.
I find some parallels, between Elastic and CounchDB - also HTTP API, also schemaless, same document orientation.
After a quick installation, I spent a lot of time reading the manual , looking at the relevant vidos , until I realized how to save the document in the index and how to run the simplest search query.
At this point, I used a naked curl, just as shown in the documentation.
But for a long time to train "on cats" is not interesting. I dumped the MongoDB production base, and now I had to transfer my entire collection from MongoDB to the ElasticSearch index.
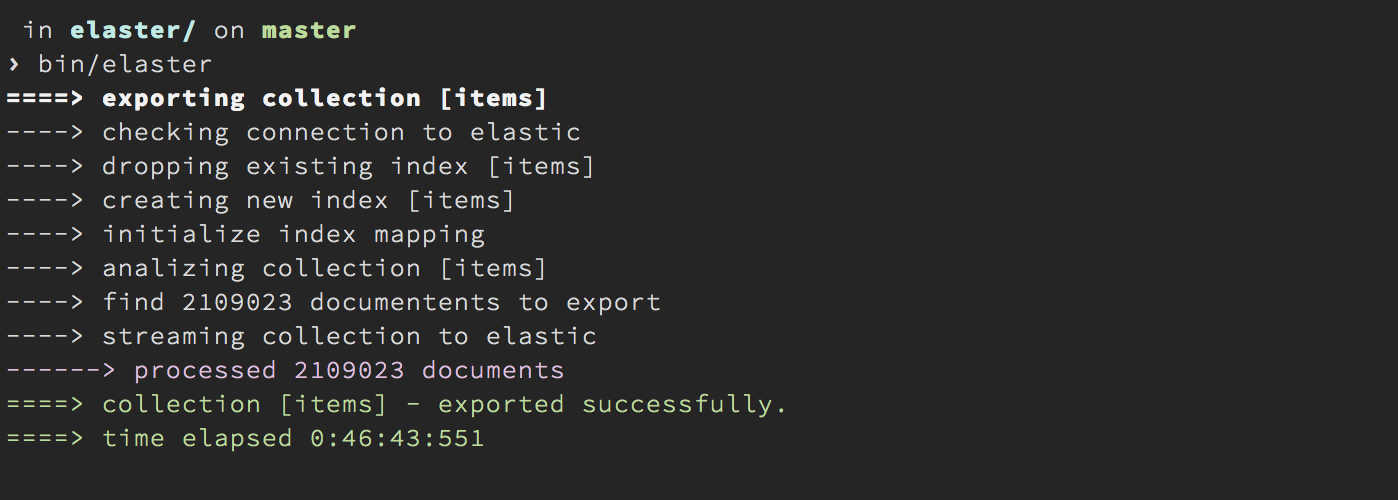
For this migration, I made a small tool - elaster . Elaster, this is a node.js application that streams a given MongoDB collection into ElasticSearch, by creating the necessary index preliminarily and initializing it with a mapping.
This process is not very fast (there are a couple of ideas, to improve elaster), but after about 40 minutes, all the entries from MongoDB were in ElasticSearch, you can try searching.
Query DSL , a query language for Elastic. Syntax is just JSON, but to make an effective request is experience, practice and knowledge. I confess, honestly, I haven't reached them yet, so my first attempt looked like this:
This is a filtered query, with paging, for issuing results for a single user. When I tried to run it, I was amazed at how cool Elastic was. The query execution time is 30-40ms, and even without some tweaks, I was pleased with the results of the issue!
In addition, ElightSeach includes the Hightligh API to highlight the results. Expanding the request to this type
The response to it (the hit object) will contain a nested highlight object, with an HTML ready for use on the front end, which makes it possible to do something like this,

After the basic search has earned, it is necessary to make so that all new data that comes to MongoDB (as the main repository) will “flow” into ElasticSearch.
For this, there are special plug-ins, so-called. rivers. There are a lot of them, for different databases. For MongoDB, the most widely used is here .
River for MongoDB works on the principle of monitoring oplog from a local database, and transforming oplog events into ElasticSeach commands. In theory, everything is simple. In practice, I did not manage to get this plugin with MongoHQ (most likely the problem of the crippling nature of my hands, because the Internet is full of descriptions of successful uses).
But in my case, it turned out to be much easier to go the other way. Since I have only one collection in which there is only insert and find, it was easier for me to modify the application code, so that immediately after insert ʻand in MongoDB, I make a bulk command in ElasticSeach.
Function saveToElastic
I do not exclude that in more complex scenarios the use of the river will be more justified.
After the local experiment was completed, it was necessary to deploy all this in production.
To do this, I created a new droplet on Digital Ocean (2 CPU, 2 GB, 40 GB SDD) and in fact spent with it all the manipulations described above - install ElasticSeach, install node.js and git, install elaster and start data migration.
As soon as the new instance was raised and initialized with data, I restarted the data collection services and the Likeastore API, already with the code modified under Elastic. Everything worked very smoothly and there were no surprises in the production.
To say that I am satisfied with the transition to ElasticSearch is to say nothing. This is really one of the few technologies that works out of the box.
Elastic opened the possibility of creating an extension to the browser for quick search, as well as the possibility of creating an advanced search (by date, content type, etc.)
However, I am still a complete noob, in this technology. The feedback that we received since the transition to Elastic and the release of the expansion clearly indicates that improvements are needed. If someone is ready to share their experience, I will be very happy.
MongoDB is finally breathing freely, Locked% stays at 0.1% and does not seek upwards, which makes the application truly responsive.
If you are still using MongoDB Full Text, I hope this post will inspire you to switch to ElasticSeach.
In this post, I’ll tell you that using MongoDB + ElasticSeach, there is a very effective NoSQL solution, and how to switch to ElasticSearch if you already have MongoDB.
A bit of history
Search functionality, the essence of our application. The ability to find something quickly among thousands of our likes was what we started this project for.
We had no deep knowledge of the theory of full-text search, and as the first approach we decided to try MongoDB Full Text Search. Despite the fact that in version 2.4 full text is an experimental feature, it worked pretty well. Therefore, for some time we left it, switching to more urgent tasks.
')
Time passed and the database grew. The collection on which we carry out the indexation began to type a certain size. Starting from the size of 2 million documents, I began to notice a general decline in application performance. This manifested itself in the form of a long opening of the first page, and an extremely slow search.
All this time I have been looking at specialized search storages like ElasticSearch , Solr or Shpinx . But as it often happens in a startup, until “thunder breaks out, the peasant will not overwrite”.
Thunder "struck" 2 weeks ago, after the publication on one of the resources, we experienced a sharp increase in traffic and greater user activity. New Relic sent scary letters stating that the application was not responding, and his own attempts to open the application showed that the patient was more likely alive than dead, but everything worked extremely slowly.
A quick analysis showed that most HTTP requests fall off from 504, after the calls to MongoDB. We are hosted on MongoHQ, but when we tried to open the monitoring console, nothing came of it. The base was loaded to the very limit. After the console was still able to open, I saw that Locked% went to the sky-high 110-140% and kept there, not going to go down.
The service that collects user likes, makes quite a few inserts, and each such insert entails a re-calculation of the full-text index, this is an expensive operation, and reaching certain restrictions (including server resources), we simply rested against it limit.
Data collection had to be disabled, the full-text index was deleted. After the restart, the Locked index service did not exceed 0.7%, but if the user tried to search for something, we had to respond with an inconvenient “sorry, search is on maintenance” ...
We try ElasticSeach locally
I decided to see what Elastic is, having tried it on my car. For that kind of experiments, there has always been (there is, and I hope will be) vagrant .
ElasticSeach is written in Java, and requires proper runtime.
> sudo apt-get update > sudo apt-get install openjdk-6-jre > sudo add-apt-repository ppa:webupd8team/java > sudo apt-get install oracle-java7-installer Then you can check whether everything is fine by running
> java --version Elastic itself is extremely easy to install. I recommend installing from a Debian package, because in this form it is easier to configure it to run as a service and not as a process.
> wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.1.1.deb > dpkg -i elasticsearch-1.1.1.deb After that, it's ready to launch,
> sudo update-rc.d elasticsearch defaults 95 10 > sudo /etc/init.d/elasticsearch start Having opened the browser and having followed the link, we receive approximately such answer.
{ "ok" : true, "status" : 200, "name" : "Xavin", "version" : { "number" : "1.1.1", "build_hash" : "36897d07dadcb70886db7f149e645ed3d44eb5f2", "build_timestamp" : "2014-05-05T12:06:54Z", "build_snapshot" : false, "lucene_version" : "4.5.1" }, "tagline" : "You Know, for Search" } Full deployment takes about 10 minutes.
Now you need to save and search.
ElasticSearch is an interface built on top of Lucene technology. It is without exaggeration the most complex technology, honed over the years, in which thousands of labor hours of high-end engineers were invested. Elastic makes this technology available to mere mortals, and does it very well.
I find some parallels, between Elastic and CounchDB - also HTTP API, also schemaless, same document orientation.
After a quick installation, I spent a lot of time reading the manual , looking at the relevant vidos , until I realized how to save the document in the index and how to run the simplest search query.
At this point, I used a naked curl, just as shown in the documentation.
But for a long time to train "on cats" is not interesting. I dumped the MongoDB production base, and now I had to transfer my entire collection from MongoDB to the ElasticSearch index.
For this migration, I made a small tool - elaster . Elaster, this is a node.js application that streams a given MongoDB collection into ElasticSearch, by creating the necessary index preliminarily and initializing it with a mapping.
This process is not very fast (there are a couple of ideas, to improve elaster), but after about 40 minutes, all the entries from MongoDB were in ElasticSearch, you can try searching.
Creating a search query
Query DSL , a query language for Elastic. Syntax is just JSON, but to make an effective request is experience, practice and knowledge. I confess, honestly, I haven't reached them yet, so my first attempt looked like this:
function fullTextItemSearch (user, query, paging, callback) { if (!query) { return callback(null, { data: [], nextPage: false }); } var page = paging.page || 1; elastic.search({ index: 'items', from: (page - 1) * paging.pageSize, size: paging.pageSize, body: { query: { filtered: { query: { 'query_string': { query: query }, }, filter: { term: { user: user.email } } } } } }, function (err, resp) { if (err) { return callback(err); } var items = resp.hits.hits.map(function (hit) { return hit._source; }); callback(null, {data: items, nextPage: items.length === paging.pageSize}); }); } This is a filtered query, with paging, for issuing results for a single user. When I tried to run it, I was amazed at how cool Elastic was. The query execution time is 30-40ms, and even without some tweaks, I was pleased with the results of the issue!
In addition, ElightSeach includes the Hightligh API to highlight the results. Expanding the request to this type
elastic.search({ index: 'items', from: (page - 1) * paging.pageSize, size: paging.pageSize, body: { query: { filtered: { query: { 'query_string': { query: query }, }, filter: { term: { user: user.email } } }, }, highlight: { fields: { description: { }, title: { }, source: { } } } } The response to it (the hit object) will contain a nested highlight object, with an HTML ready for use on the front end, which makes it possible to do something like this,
Modification of the application code
After the basic search has earned, it is necessary to make so that all new data that comes to MongoDB (as the main repository) will “flow” into ElasticSearch.
For this, there are special plug-ins, so-called. rivers. There are a lot of them, for different databases. For MongoDB, the most widely used is here .
River for MongoDB works on the principle of monitoring oplog from a local database, and transforming oplog events into ElasticSeach commands. In theory, everything is simple. In practice, I did not manage to get this plugin with MongoHQ (most likely the problem of the crippling nature of my hands, because the Internet is full of descriptions of successful uses).
But in my case, it turned out to be much easier to go the other way. Since I have only one collection in which there is only insert and find, it was easier for me to modify the application code, so that immediately after insert ʻand in MongoDB, I make a bulk command in ElasticSeach.
async.waterfall([ readUser, executeConnector, findNew, saveToMongo, saveToEleastic, saveState ], function (err, results) { }); Function saveToElastic
var commands = []; items.forEach(function (item) { commands.push({'index': {'_index': 'items', '_type': 'item', '_id': item._id.toString()}}); commands.push(item); }); elastic.bulk({body: commands}, callback); I do not exclude that in more complex scenarios the use of the river will be more justified.
Unfolding in production
After the local experiment was completed, it was necessary to deploy all this in production.
To do this, I created a new droplet on Digital Ocean (2 CPU, 2 GB, 40 GB SDD) and in fact spent with it all the manipulations described above - install ElasticSeach, install node.js and git, install elaster and start data migration.
As soon as the new instance was raised and initialized with data, I restarted the data collection services and the Likeastore API, already with the code modified under Elastic. Everything worked very smoothly and there were no surprises in the production.
results
To say that I am satisfied with the transition to ElasticSearch is to say nothing. This is really one of the few technologies that works out of the box.
Elastic opened the possibility of creating an extension to the browser for quick search, as well as the possibility of creating an advanced search (by date, content type, etc.)
However, I am still a complete noob, in this technology. The feedback that we received since the transition to Elastic and the release of the expansion clearly indicates that improvements are needed. If someone is ready to share their experience, I will be very happy.
MongoDB is finally breathing freely, Locked% stays at 0.1% and does not seek upwards, which makes the application truly responsive.
If you are still using MongoDB Full Text, I hope this post will inspire you to switch to ElasticSeach.
Source: https://habr.com/ru/post/223109/
All Articles