Hadoop and Automation: Part 3
Well, Habrazhiteli, it's time to summarize a series of articles ( part 1 and part 2 ) on my adventure with automating the deployment of the Hadoop cluster.

My project is almost ready, it remains only to test the process and you can notch yourself on the fuselage.
In this article I will talk about raising the “driving force” of our cluster - Slaves , and also summarize and provide useful links to the resources that I used throughout my project. Perhaps someone seemed to have scant articles on the source code and implementation details, so at the end of the article I will provide a link to Github
Well, out of habit, at the very beginning I will give an architectural scheme that I managed to deploy to the cloud.
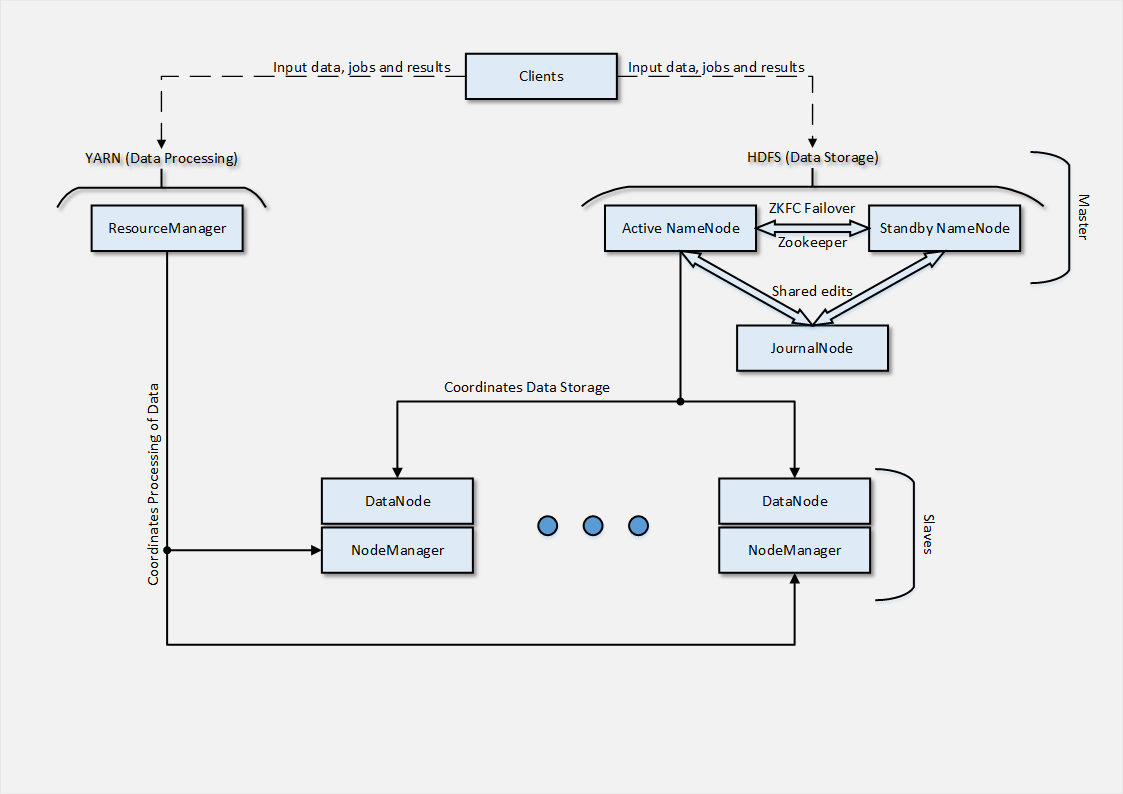
In our case, given the test character of the run, only 2 Slave nodes were used, but in real conditions there would be dozens. Further, I will briefly describe how their deployment was organized.
As you might guess from the architecture - the Slave- node consists of 2 parts , each of which is responsible for the actions related to parts of the Masters architecture. A DataNode is the point of interaction between a Slave node and a NameNode , which coordinates distributed data storage .
The DataNode process connects to the service on the NameNode- node, after which Clients can handle file operations directly to the DataNode- nodes. It is also worth noting that DataNode nodes communicate with each other in the case of data replication , which in turn allows us to avoid using RAID arrays, since The replication mechanism is already programmed.
The DataNode deployment process is quite simple:
As a result, if all the data is correct and the configuration is applied, you can see the added Slave- nodes on the NameNode- nodes web interface. This means that the DataNode node is now available for file operations related to distributed data storage. Copy the file to HDFS and see for yourself.
The NodeManager , in turn, is responsible for interacting with the ResourceManager , which manages the tasks and resources available to perform them. The deployment process of NodeManager is similar to the process in the case of DataNode , with the difference in the name of the package for installation and service ( hadoop-yarn-nodemanager ).
After successfully completing the deployment of Slaves nodes, you can consider our cluster ready. It is worth paying attention to the files that set environment variables (hadoop_env, yarn_env, etc.) - the data in the variables must correspond to the real values in the cluster. Also, you should pay attention to the accuracy of the values of the variables, which indicate the domain names and ports on which a particular service is running.
How can we test the performance of the cluster? The most accessible option is to start a task from one of the Clients nodes. For example, like this:
where hadoop-mapreduce-examples-2.2.0.jar is the name of the file with the task description (available in the base installation), pi indicates the type of task (MapReduce Task in this case), and 2 and 5 are responsible for the distribution of the tasks ( more details - here ).
After all the calculations, the result will be output to the terminal with statistics and the result of the calculations, or the creation of an output file with data output there (the nature of the data and the output format depend on the task described in the .jar file).
<End />
')
These are the clusters and cakes, dear Habrazhiteli . At this stage - I do not pretend to the ideality of this solution, since there are still stages of testing and making improvements / edits to the cookbook code. I wanted to share my experience, describe another approach to the deployment of the Hadoop cluster - the approach is not the easiest and most orthodox, I would say. But it is in such unconventional conditions - steel is tempered. My final goal is a modest analogue of the Amazon MapReduce service, for our private cloud.
I very much welcome advice from everyone who will pay attention to this series of articles (special thanks to ffriend , who paid attention and asked questions, some of which led me to new ideas).
As promised, here is a list of materials that, along with my colleagues, helped to bring the project to an acceptable form:
- Detailed documentation on HDP distribution kit - docs.hortonworks.com
- Fathers Wiki , Apache Hadoop - wiki.apache.org/hadoop
- Documentation from them - hadoop.apache.org/docs/current
- A little outdated (in terms of) article-description of the architecture - here
- A good tutorial in 2 parts - here
- Adapted translation from martsen tutorial - habrahabr.ru/post/206196
- Community cookbook " Hadoop ", on the basis of which I made my project - Hadoop cookbook
- In the end - my humble project as it is (ahead of the update) - GitHub
Thank you all for your attention! Comments are welcome! If I can help with something - please contact! Until new meetings.
UPD. Added the link to article on Habré, translation of tutorial.
My project is almost ready, it remains only to test the process and you can notch yourself on the fuselage.
In this article I will talk about raising the “driving force” of our cluster - Slaves , and also summarize and provide useful links to the resources that I used throughout my project. Perhaps someone seemed to have scant articles on the source code and implementation details, so at the end of the article I will provide a link to Github
Well, out of habit, at the very beginning I will give an architectural scheme that I managed to deploy to the cloud.
In our case, given the test character of the run, only 2 Slave nodes were used, but in real conditions there would be dozens. Further, I will briefly describe how their deployment was organized.
Deploying Slaves Nodes
As you might guess from the architecture - the Slave- node consists of 2 parts , each of which is responsible for the actions related to parts of the Masters architecture. A DataNode is the point of interaction between a Slave node and a NameNode , which coordinates distributed data storage .
The DataNode process connects to the service on the NameNode- node, after which Clients can handle file operations directly to the DataNode- nodes. It is also worth noting that DataNode nodes communicate with each other in the case of data replication , which in turn allows us to avoid using RAID arrays, since The replication mechanism is already programmed.
The DataNode deployment process is quite simple:
- Installing prerequisites in the form of Java ;
- Adding repositories with packages of Hadoop distribution;
- Creating the backbone of the directories needed to install the DataNode ;
- Generating configuration files based on the template and cookbook attributes
- Installing Distribution Packages ( hadoop-hdfs-datanode )
- Starting the DataNode process by
service hadoop-hdfs-datanode start; - Register the status of the deployment process.
As a result, if all the data is correct and the configuration is applied, you can see the added Slave- nodes on the NameNode- nodes web interface. This means that the DataNode node is now available for file operations related to distributed data storage. Copy the file to HDFS and see for yourself.
The NodeManager , in turn, is responsible for interacting with the ResourceManager , which manages the tasks and resources available to perform them. The deployment process of NodeManager is similar to the process in the case of DataNode , with the difference in the name of the package for installation and service ( hadoop-yarn-nodemanager ).
After successfully completing the deployment of Slaves nodes, you can consider our cluster ready. It is worth paying attention to the files that set environment variables (hadoop_env, yarn_env, etc.) - the data in the variables must correspond to the real values in the cluster. Also, you should pay attention to the accuracy of the values of the variables, which indicate the domain names and ports on which a particular service is running.
How can we test the performance of the cluster? The most accessible option is to start a task from one of the Clients nodes. For example, like this:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 5 where hadoop-mapreduce-examples-2.2.0.jar is the name of the file with the task description (available in the base installation), pi indicates the type of task (MapReduce Task in this case), and 2 and 5 are responsible for the distribution of the tasks ( more details - here ).
After all the calculations, the result will be output to the terminal with statistics and the result of the calculations, or the creation of an output file with data output there (the nature of the data and the output format depend on the task described in the .jar file).
<End />
')
These are the clusters and cakes, dear Habrazhiteli . At this stage - I do not pretend to the ideality of this solution, since there are still stages of testing and making improvements / edits to the cookbook code. I wanted to share my experience, describe another approach to the deployment of the Hadoop cluster - the approach is not the easiest and most orthodox, I would say. But it is in such unconventional conditions - steel is tempered. My final goal is a modest analogue of the Amazon MapReduce service, for our private cloud.
I very much welcome advice from everyone who will pay attention to this series of articles (special thanks to ffriend , who paid attention and asked questions, some of which led me to new ideas).
Links to materials
As promised, here is a list of materials that, along with my colleagues, helped to bring the project to an acceptable form:
- Detailed documentation on HDP distribution kit - docs.hortonworks.com
- Fathers Wiki , Apache Hadoop - wiki.apache.org/hadoop
- Documentation from them - hadoop.apache.org/docs/current
- A little outdated (in terms of) article-description of the architecture - here
- A good tutorial in 2 parts - here
- Adapted translation from martsen tutorial - habrahabr.ru/post/206196
- Community cookbook " Hadoop ", on the basis of which I made my project - Hadoop cookbook
- In the end - my humble project as it is (ahead of the update) - GitHub
Thank you all for your attention! Comments are welcome! If I can help with something - please contact! Until new meetings.
UPD. Added the link to article on Habré, translation of tutorial.
Source: https://habr.com/ru/post/223021/
All Articles