Consensus in distributed systems. Paxos
Recently, in scientific publications, an algorithm for reaching consensus in distributed systems called Paxos has been increasingly mentioned. Among such publications, a number of works by Google employees ( Chubby , Megastore , Spanner ) have already been partially covered in Habré , WANdisco , Ceph, and other systems architecture. At the same time, the Paxos algorithm itself is considered difficult to understand , although it is based on elementary principles.
In this article I will try to correct this situation and tell about this algorithm in an understandable language, as the author of the algorithm Leslie Lamport once tried to do .
First you need to understand the problem that this algorithm solves. To do this, imagine a distributed information processing system, which is a cluster of x86 servers. If for one server the probability of failure is small and often when introducing simple systems it can be neglected, then for a server cluster the probability of failure of one of the servers becomes several times larger: MTBF for one of the N servers is N times less than MTBF for one server. Add to this the unreliability of the network in the form of network equipment failure and packet loss, hard drive failures, server software failures at the OS level and applications. According to Google , for a cluster of 1,800 machines, they talk about 1,000 server failures during the first year of cluster operation, that is, 3 failures per day - and that does not include hard drive failures, network and power problems, etc. As a result, if you do not lay out fault tolerance in the software of a distributed system, we get a system in which each of the above problems leads to system failure.
Therefore, the task of achieving a consensus is the task of obtaining a consistent value by a group of participants in a situation where individual participants may fail, provide incorrect information by them, and distort the transmitted values by the data transmission medium. In general, the scenarios of the abnormal functioning of the components of distributed systems can be divided into two classes:
Second-class errors are much more difficult to detect and correct. In general, Leslie Lamport proved that in order to fix the Byzantine problem in N nodes, the distributed system must consist of at least 3N + 1 nodes and must implement a special consensus algorithm. Fault tolerance at this level is required for the most part in systems whose critical operation is extremely high (for example, in the tasks of the space industry).
')
In cluster computing, fault tolerance is usually understood as system resilience to complete component failures. To achieve consensus in such systems, the Paxos algorithm is used. The algorithm was proposed by Leslie Lamport in the 90s of the last century and named after the Greek island of Paxos with a fictional system of organization of the work of parliament. To achieve consensus, this algorithm requires that at least N + 1 nodes function in a system of 2N + 1 nodes, these N + 1 nodes are called “quorum”
The essence of the algorithm in the interaction of agents with the following roles:
The basic Paxos algorithm consists of the following steps:
1a Prepare ("offer"). In this phase, the proposer generates an “offer” with the sequence number N and sends it to all acceptors. For each of the following "sentences" number N must be greater than the previously selected
1b. Promise ("promise"). Each acceptor receives an "offer" with the sequence number N and the value V. If the number of the “offer” is more than all accepted by the acceptor, he is obliged to respond to this message with a “promise” not to take more than “offers” with a sequence number less than N. If this acceptor has already accepted any "offer", it must return the number N i of this "offer" and the accepted value V i , otherwise it returns an empty value
2a. Accept! ("to accept"). If the proposer received “promises” from the acceptor quorum, it considers the request as ready for further processing. In the event that the values of N i and V i also come from the “promises” from the acceptor, the proposer chooses V equal to the value of V i “promises” with the maximum N i . Then the proposer sends a request to “accept” to all acceptors, which contains the values of N and V
2b. Accepted ("accepted"). When the acceptor receives a “accept” message with N and V values, it accepts it only if it has not previously “promised” to accept offers with numbers strictly greater than N. Otherwise, it takes the value and responds with the message “accepted” to all learner
The learner’s task is simple - get the message “accepted” with a V value and remember it.
An example of the functioning of the algorithm:
What happens if one of the components of a distributed system fails?
Disclaimer Acceptor:
Learner failure:
Proposer failure:
In case of failure of the proposer, the system should select a new proposer, usually this is done by voting after the timeout expires, waiting for the return of the old proposer. In case, after choosing a new proposer, the old one comes back to life, a conflict may arise between the leaders, which may lead to a system loop:
As an example of implementation, I’ll give a slightly modified python code from one of the github repositories :
Literature:
In this article I will try to correct this situation and tell about this algorithm in an understandable language, as the author of the algorithm Leslie Lamport once tried to do .
First you need to understand the problem that this algorithm solves. To do this, imagine a distributed information processing system, which is a cluster of x86 servers. If for one server the probability of failure is small and often when introducing simple systems it can be neglected, then for a server cluster the probability of failure of one of the servers becomes several times larger: MTBF for one of the N servers is N times less than MTBF for one server. Add to this the unreliability of the network in the form of network equipment failure and packet loss, hard drive failures, server software failures at the OS level and applications. According to Google , for a cluster of 1,800 machines, they talk about 1,000 server failures during the first year of cluster operation, that is, 3 failures per day - and that does not include hard drive failures, network and power problems, etc. As a result, if you do not lay out fault tolerance in the software of a distributed system, we get a system in which each of the above problems leads to system failure.
Therefore, the task of achieving a consensus is the task of obtaining a consistent value by a group of participants in a situation where individual participants may fail, provide incorrect information by them, and distort the transmitted values by the data transmission medium. In general, the scenarios of the abnormal functioning of the components of distributed systems can be divided into two classes:
- Complete component failure. This class of problems is characterized by the fact that such a failure leads to the unavailability of one of the components of the distributed system (or network segmentation, in the event of a switch failure). This class of problems includes: server failure, storage system failure, switch failure, operating system failure, application failure;
- Byzantine mistake. Characterized by the fact that the system node continues to function, but it may return incorrect information. Suppose, when using RAM without ECC, it can lead to reading out incorrect data from memory, errors in network equipment can lead to packet damage, etc.
Second-class errors are much more difficult to detect and correct. In general, Leslie Lamport proved that in order to fix the Byzantine problem in N nodes, the distributed system must consist of at least 3N + 1 nodes and must implement a special consensus algorithm. Fault tolerance at this level is required for the most part in systems whose critical operation is extremely high (for example, in the tasks of the space industry).
')
In cluster computing, fault tolerance is usually understood as system resilience to complete component failures. To achieve consensus in such systems, the Paxos algorithm is used. The algorithm was proposed by Leslie Lamport in the 90s of the last century and named after the Greek island of Paxos with a fictional system of organization of the work of parliament. To achieve consensus, this algorithm requires that at least N + 1 nodes function in a system of 2N + 1 nodes, these N + 1 nodes are called “quorum”
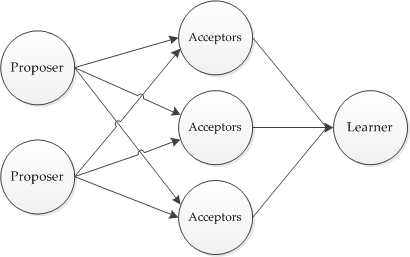
The essence of the algorithm in the interaction of agents with the following roles:
- Client - a distributed system client that can send a request and get an answer to it.
- Proposer is a component of the distributed system responsible for organizing the voting process
- Acceptor - a component of a distributed system that has the right to vote for accepting or rejecting a specific proposal from Proposer
- Learner - a component of the system that remembers the decision
The basic Paxos algorithm consists of the following steps:
1a Prepare ("offer"). In this phase, the proposer generates an “offer” with the sequence number N and sends it to all acceptors. For each of the following "sentences" number N must be greater than the previously selected
1b. Promise ("promise"). Each acceptor receives an "offer" with the sequence number N and the value V. If the number of the “offer” is more than all accepted by the acceptor, he is obliged to respond to this message with a “promise” not to take more than “offers” with a sequence number less than N. If this acceptor has already accepted any "offer", it must return the number N i of this "offer" and the accepted value V i , otherwise it returns an empty value
2a. Accept! ("to accept"). If the proposer received “promises” from the acceptor quorum, it considers the request as ready for further processing. In the event that the values of N i and V i also come from the “promises” from the acceptor, the proposer chooses V equal to the value of V i “promises” with the maximum N i . Then the proposer sends a request to “accept” to all acceptors, which contains the values of N and V
2b. Accepted ("accepted"). When the acceptor receives a “accept” message with N and V values, it accepts it only if it has not previously “promised” to accept offers with numbers strictly greater than N. Otherwise, it takes the value and responds with the message “accepted” to all learner
The learner’s task is simple - get the message “accepted” with a V value and remember it.
An example of the functioning of the algorithm:
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | |<---------X--X--X | | Promise(1,{Va,Vb,Vc}) | X--------->|->|->| | | Accept!(1,Vn=last(Va,Vb,Vc)) | |<---------X--X--X------>|->| Accepted(1,Vn) |<---------------------------------X--X Response | | | | | | | What happens if one of the components of a distributed system fails?
Disclaimer Acceptor:
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | | | | ! | | !! FAIL !! | |<---------X--X | | Promise(1,{null,null, null}) | X--------->|->| | | Accept!(1,V) | |<---------X--X--------->|->| Accepted(1,V) |<---------------------------------X--X Response | | | | | | Since in the system there are 3 node asseptors, one of them is allowed to fail, since the quorum in this case is equal to twoLearner failure:
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | |<---------X--X--X | | Promise(1,{null,null,null}) | X--------->|->|->| | | Accept!(1,V) | |<---------X--X--X------>|->| Accepted(1,V) | | | | | | ! !! FAIL !! |<---------------------------------X Response | | | | | | Proposer failure:
Client Proposer Acceptor Learner | | | | | | | X----->| | | | | | Request | X------------>|->|->| | | Prepare(1) | |<------------X--X--X | | Promise(1,{null, null, null}) | | | | | | | | | | | | | | !! Leader fails during broadcast !! | X------------>| | | | | Accept!(1,Va) | ! | | | | | | | | | | | | !! NEW LEADER !! | X--------->|->|->| | | Prepare(2) | |<---------X--X--X | | Promise(2,{null, null, null}) | X--------->|->|->| | | Accept!(2,V) | |<---------X--X--X------>|->| Accepted(2,V) |<---------------------------------X--X Response | | | | | | | In case of failure of the proposer, the system should select a new proposer, usually this is done by voting after the timeout expires, waiting for the return of the old proposer. In case, after choosing a new proposer, the old one comes back to life, a conflict may arise between the leaders, which may lead to a system loop:
Client Leader Acceptor Learner | | | | | | | X----->| | | | | | Request | X------------>|->|->| | | Prepare(1) | |<------------X--X--X | | Promise(1,{null,null,null}) | ! | | | | | !! LEADER FAILS | | | | | | | !! NEW LEADER (knows last number was 1) | X--------->|->|->| | | Prepare(2) | |<---------X--X--X | | Promise(2,{null,null,null}) | | | | | | | | !! OLD LEADER recovers | | | | | | | | !! OLD LEADER tries 2, denied | X------------>|->|->| | | Prepare(2) | |<------------X--X--X | | Nack(2) | | | | | | | | !! OLD LEADER tries 3 | X------------>|->|->| | | Prepare(3) | |<------------X--X--X | | Promise(3,{null,null,null}) | | | | | | | | !! NEW LEADER proposes, denied | | X--------->|->|->| | | Accept!(2,Va) | | |<---------X--X--X | | Nack(3) | | | | | | | | !! NEW LEADER tries 4 | | X--------->|->|->| | | Prepare(4) | | |<---------X--X--X | | Promise(4,{null,null,null}) | | | | | | | | !! OLD LEADER proposes, denied | X------------>|->|->| | | Accept!(3,Vb) | |<------------X--X--X | | Nack(4) | | | | | | | | ... and so on ... To prevent this, in the practical implementation of the algorithm, each proposer has a sequence number and when choosing a new proposer, this number is incremented by one. None of acceptor accepts messages from the old proposer.As an example of implementation, I’ll give a slightly modified python code from one of the github repositories :
class Proposer (object): # 1a. proposal_id ( "N") # "" acceptor def prepare(self): self.promises_rcvd = 0 self.proposal_id = self.next_proposal_number self.next_proposal_number += 1 self.messenger.send_prepare(self.proposal_id) # 2a. "". - . "" # acceptor - . # "" , "" def recv_promise(self, proposal_id, prev_accepted_id, prev_accepted_value): if proposal_id != self.proposal_id: return if prev_accepted_id > self.last_accepted_id: self.last_accepted_id = prev_accepted_id if prev_accepted_value is not None: self.proposed_value = prev_accepted_value self.promises_rcvd += 1 if self.promises_rcvd == self.quorum_size: if self.proposed_value is not None: self.messenger.send_accept(self.proposal_id, self.proposed_value) class Acceptor (object): # 1b. Acceptor "" proposer. , , # . , # ( ) "" def recv_prepare(self, proposal_id): if proposal_id == self.promised_id: self.messenger.send_promise(proposal_id, self.accepted_id, self.accepted_value) elif proposal_id > self.promised_id: self.promised_id = proposal_id self.messenger.send_promise(proposal_id, self.accepted_id, self.accepted_value) # 2b. "". , # "" def recv_accept_request(self, from_uid, proposal_id, value): if proposal_id >= self.promised_id: self.promised_id = proposal_id self.accepted_id = proposal_id self.accepted_value = value self.messenger.send_accepted(proposal_id, self.accepted_value) class Learner (object): # 3. Learner "", def recv_accepted(self, from_uid, proposal_id, accepted_value): self.final_value = accepted_value self.messenger.on_resolution( proposal_id, accepted_value ) Literature:
Source: https://habr.com/ru/post/222825/
All Articles