How can trust sociological research?
 The reason for writing this article was this study, which was discussed earlier .
The reason for writing this article was this study, which was discussed earlier .With my higher technical education and love of exact sciences and especially mathematics, I appreciate and respect those theories that are applicable in life and provide practical benefits (contrary to the popular belief that relativity does not have a relation to everyday life, systems and firing rockets on the scale of the whole planet). Let us from this point of view look at this part of the statistics as opinion polls. Now they are very fashionable.
We will try to look at it with the eyes of a person who is far from formulas.
Intuitive understanding
We have a village where 100 people live. We want to find out how the inhabitants of this village relate to the construction of their chemical. factory. For this you need to interview all 100 people - right? From them 20% against, 40% all the same, 40% for:
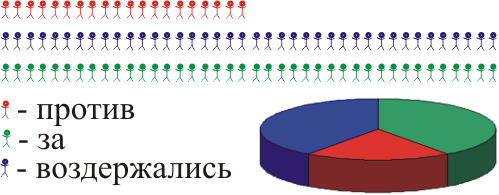
But here - you will not interrogate all inhabitants, you will not know. Let's then poll some part - at least half.
')
You can do this: divide all the villagers into some groups: for example, freelancers who are employed and not-working. From each group, we take several people and get a representative sample :
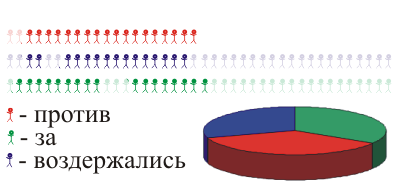
Or let us act differently: they dispersed at random who they caught, and they caught him. They counted half of the village - and order, got a probabilistic sample :

You can do it more elegantly: we select some streets with a random number generator and go there. You can even divide the quotas of residents. In general, we act by methods of improbable sampling :
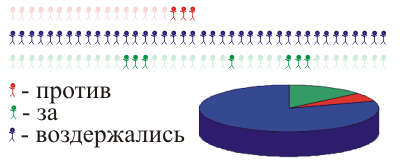
So all the same - residents "for", "abstain" or "against" ???
In this case, it is more or less obvious. But this is because we know the full result. If we survey more than half of the inhabitants, then we can also claim for relatively real knowledge. Or we can interview a small number of randomly selected residents many times - so that in total we survey several times more residents than there are in the village.
The general problem of opinion polls
In any survey, you need to be sure that you interviewed those you need. For example, in the case of a survey of the sexiest women in the world, it is not so terrible to make a mistake. But in any important matter - for example, the election of the president of the country - it is very important to sift out those who live there, mentally healthy and at least alive, from all those who did not fall into this category. You also need to be sure that everyone has voted for himself once.
The second problem is the number of people who need to be interviewed. If we take an average European country of 10 million people, then 1% is 100,000 people. Such a survey to conduct a paper method is almost impossible.
Immediately reservations: paper hard, but easier than electronic . But immediately there is a big problem of screening out those who are needed in the survey, and who are not needed.
On the other hand, a reliable paper survey of such (and much larger) population can be carried out, but it requires tremendous effort. A classic example is sociological polls called “referendum”, “presidential elections”.
Poll from the Levada Center
And now back to the real survey , which is commented on here :
The survey was conducted on April 25-28, 2014 for a representative all-Russian sample of urban and rural population among 1602 people aged 18 years and older in 130 settlements of 45 regions of the country. Distribution of answers is given as a percentage of the total number of respondents, together with data from previous surveys. The statistical error of these studies does not exceed 3.4%
What do I understand out of here?
- They polled 1602 people. Its population according to the results of the all-Russian census of 2010 is 142 856 536 people. We divide 1602 by 142856536 and we get - 1.1 * 10 -5 . This is 0.001%. So, according to a survey of 0.001% of Russians, a conclusion is made for all Russians .
- We take into account that we interviewed people over 18 years old. According to the same results, residents up to 19 years old make 28,026,172 people, or 19.6%. Well, subtract the children: divide 1620 by 114 830 364. The result has changed: 1.4 * 10 -5 . This is 0.0014%. Is the difference significant?
- The survey was conducted in 130 locations. Judging by the results of the 2010 all-Russian census of Russia , there are 1,100 cities in it, 1,285 PGTs and 153,124 rural settlements - a total of 155,509 settlements. We divide 130 by 155 509 and get 8.4 * 10 -4 . This is 0.083%. So, according to a survey of 0.083% of settlements, a conclusion is made for all settlements of Russia .
- The survey was conducted in 45 regions. Today it is 85 regions (here Russia included the Crimea). Divide 45 by 85 and get 52%. So, according to a survey of half of the regions of Russia, a conclusion is made for all regions .
- "Statistical error ..." - which one ? What about?
What conclusions follow here? I think this is obvious ...
Is it that the Levada Center is so
What are some other problems?
I will not repeat much - read an excellent article on this topic. For starters, take a look at the schedule from the article that shows the number of private and public schools in the United States:
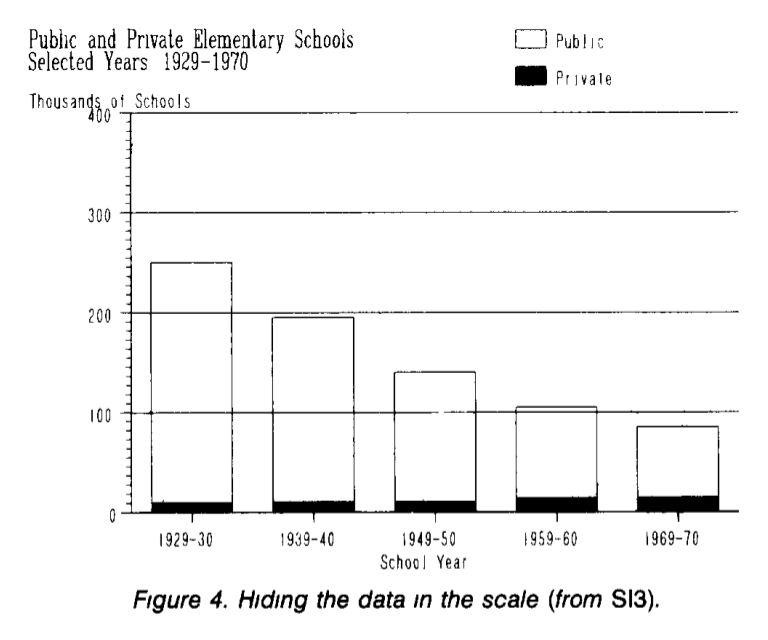
From the graph it is clear that there are fewer and fewer public schools, and there are no more private ones ... Stop! We look carefully - and there are more private ones, black ones! We look at the graph, where the number of private schools is shown separately:
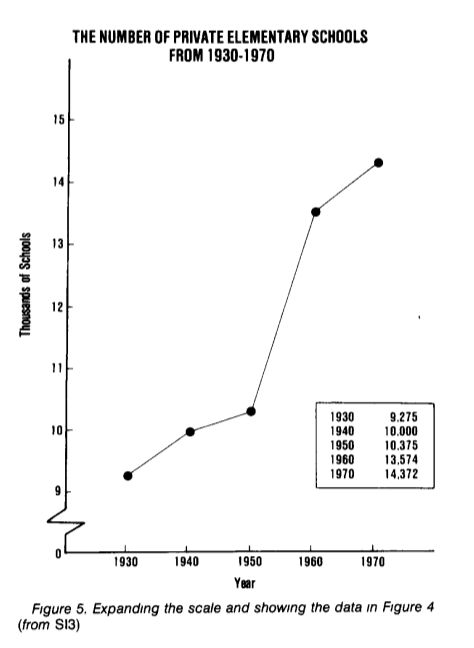
Beautiful, yes?
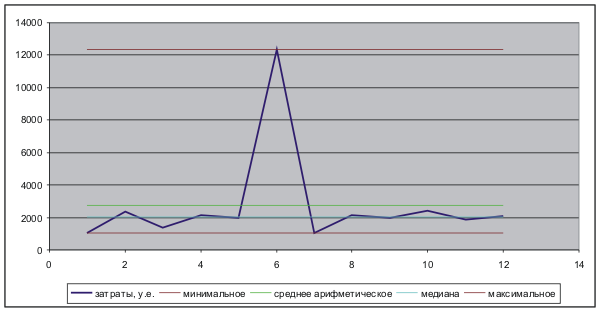
Now a small example from personal life. Suppose I keep statistics on my expenses. For the year I have made such expenses:
| month | costs, w. e. |
|---|---|
| January | 1047 |
| February | 2354 |
| March | 1358 |
| April | 2123 |
| May | 1984 |
| June | 12346 |
| July | 1023 |
| August | 2136 |
| September | 1986 |
| October | 2431 |
| November | 1856 |
| December | 2113 |
I want to have a deferred amount that will help me if my income drops sharply. I decided to analyze the table and decide the following year: how much should I postpone so that on average I have enough? First of all, I look at the minimum - July, 1023. Then I look at the very maximum - June, 12346. So, should I take the arithmetic average of the minimum and maximum? I will receive (1023 +12346) / 2 = 6684. Does this reflect my expenses? Terribly exaggerated.
Let's see it differently - take the arithmetic average of all months - we get 2729. Does this reflect my expenses? Every month I spent less money, except that I spent much more in June. Exaggerated.
Recall the median : roughly speaking, in the probability distribution it will be in the middle. In this case, it is 2049. In half the case, I spent less, in half more. Closest to the real situation. The question is - have you often met in sociological polls as a result of a median?
The negative point of calculating the median is that it is more difficult to count than the arithmetic average. Yeah, but in the age of n-core processors in the phone, this argument sounds strange .
The graph reflects this reasoning.
findings
I think everyone will decide for himself. Personally, I realized that opinion polls do not reflect real public opinion . Unfortunately…
Source: https://habr.com/ru/post/222773/
All Articles