Hadoop and Automation: Part 2
Hello!

I continue my “merry” series of articles devoted to getting to know Hadoop and automating the deployment of a cluster.
In the first part, I briefly described what needed to be achieved, what cluster architecture to build and what the Hadoop cluster is from an architectural point of view. Also, I considered, probably, the simplest part of the cluster - Clients , which is responsible for setting tasks, providing data for calculations and getting results.
Now it's time to talk about the part of the cluster architecture, which is Masters - namely, HDFS and YARN .
Let me give you another example of the architecture that was to be deployed in a private cloud. It was intended solely for test needs, the actual data load was not provided.
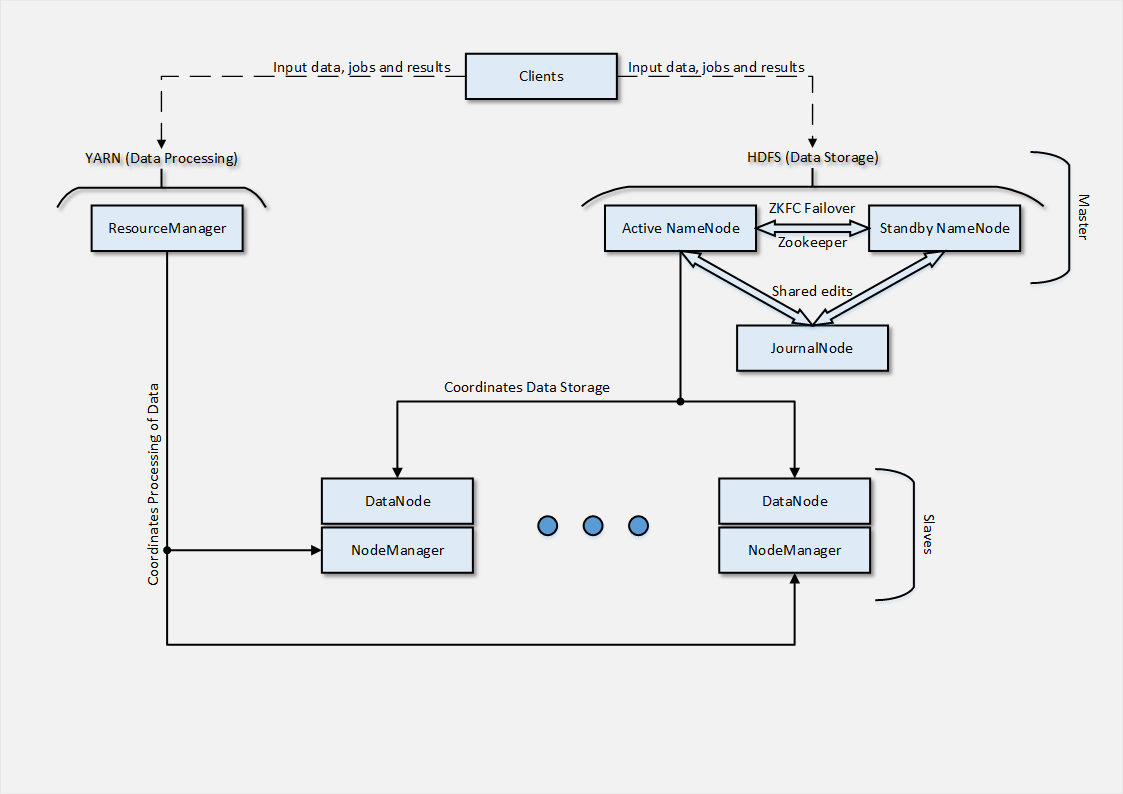
So, it was assumed that we will have 2 nodes responsible for the NameNode- role, between which HA + Failover is configured based on Zookeeper . NameNode, in turn, is responsible for coordinating the data in our distributed HDFS file system. NameNode own the directory tree and monitor the files distributed across our cluster. By themselves, NameNode nodes do not store data, because for this role we have slaves .
JournalNode , in turn, is necessary for us if we implement High Availability based on QJM (Quorum Journal Manager), the essence of which is that dedicated virtual machines ( JournalNode ) are used to synchronize between Active and Stanbdy NameNode , which contain lists of changes in HDFS. The logs of these changes are available to both NameNode, respectively, in any case of failover, we achieve synchronization of our NameNode- nodes.
Another high availability option is using NFS / NAS . The essence is approximately the same - there is a storage " mounted " on the network, in which all so-called ones are written. shared edits , mentioned changes logs in HDFS .
In our case, YARN is responsible for 1 node - the ResourceManager , which manages tasks, calculations, distributes computing resources between tasks, and is also responsible for accepting and setting tasks for execution.
')
<Lyrical digression>
It should be noted that initially the idea of automating the deployment process of the Hadoop cluster looked quite exotic, in view of the rather “gentle” nature of it (although it may be my personal experience ...). What I mean? During automation, it turned out that the slightest deviation from the documentation led to a large number of questions or to the identification of problems previously documented in JIRA by the developers of Hadoop distributions.
In a word, cookbook turned out to be not the closest to the " best practices " in my understanding, since it contains a fair amount of Bash code, execute resources, and only occasionally (where possible) uses Ruby DSL and Chef resources .
Also, the idea that there is Apache Ambari , the native Hadoop cluster management system, was haunted . But again - this is not our method, and I wanted to understand the process without the help of third-party software.
</ Lyrical digression>
The time has come to dig deeper into the deployment process and the cookbook code, which will be responsible for automating the cluster deployment process.
I mentioned in the first article that the cookbook I wrote was based on Community practices , around which I created a wrapper. In fact, not everything went smoothly, because in the community cookbook version available at the time of my work start - there were several problems, sometimes very annoying - a typo, the wrong team and other trifles (we must pay tribute to the developer, who very quickly responded to my modest contribution and standing questions).
In fact, the achievements of the community were an excellent foundation for starting work, adding some solutions if possible.
Well, I started with the NameNode deployment and the HA + Failover mechanism. This process for Linux nodes can be described as follows:
Starting the processes necessary for NameNode to function consisted of the following steps:
After Chef has successfully worked on 2 nodes , following these steps, you can begin the installation verification process. There are several verification options that are best used:
A successful result is a bunch of 2 nodes , one of which takes on the role of Active NameNode , the other - Standby NameNode ; between the nodes ( znode ) a Zookeeper control is installed, which is able to conduct a failover process; access to the Slave nodes and the file system (the deployment of the Slave will be discussed in the next article).
As already mentioned, the high availability of our cluster can be achieved in 2 ways - using NFS / NAS or a dedicated JournalNode node.
In the case of NFS / NAS , all we need is to be able to “mount” the storage over the network to our NameNode. The storage should be available 24/7 (highly desirable), accessible with low latency, and also respond quickly to read / write operations over the network.
In the case of using JournalNode , it is necessary to select the node on which the JournalNode package is installed from the Hadoop distribution. For the configuration in the basic version, there are 2 parameters: dfs.journalnode.http-address — the parameter that indicates the FQDN and the port on which the JournalNode service is running ); dfs.journalnode.edits.dir - directory in which logs of events occurring in HDFS are added.
The YARN cluster part is represented in our ResourceManager architecture as a node that works with tasks and resources for their execution. The process of deploying this node looks simpler than NameNode :
To verify successful deployment, you can do the following:
That's about my part Masters . At the end of the next article, I plan to highlight a section in which I will describe the minimum cluster settings that are REQUIRED to run. Also, in the next article, I will publish links to my modest project and useful documentation, which I used in the process of creating it.
Thank you all for your attention! Comments and especially amendments are very welcome!
I continue my “merry” series of articles devoted to getting to know Hadoop and automating the deployment of a cluster.
In the first part, I briefly described what needed to be achieved, what cluster architecture to build and what the Hadoop cluster is from an architectural point of view. Also, I considered, probably, the simplest part of the cluster - Clients , which is responsible for setting tasks, providing data for calculations and getting results.
Now it's time to talk about the part of the cluster architecture, which is Masters - namely, HDFS and YARN .
Let me give you another example of the architecture that was to be deployed in a private cloud. It was intended solely for test needs, the actual data load was not provided.
So, it was assumed that we will have 2 nodes responsible for the NameNode- role, between which HA + Failover is configured based on Zookeeper . NameNode, in turn, is responsible for coordinating the data in our distributed HDFS file system. NameNode own the directory tree and monitor the files distributed across our cluster. By themselves, NameNode nodes do not store data, because for this role we have slaves .
JournalNode , in turn, is necessary for us if we implement High Availability based on QJM (Quorum Journal Manager), the essence of which is that dedicated virtual machines ( JournalNode ) are used to synchronize between Active and Stanbdy NameNode , which contain lists of changes in HDFS. The logs of these changes are available to both NameNode, respectively, in any case of failover, we achieve synchronization of our NameNode- nodes.
Another high availability option is using NFS / NAS . The essence is approximately the same - there is a storage " mounted " on the network, in which all so-called ones are written. shared edits , mentioned changes logs in HDFS .
In our case, YARN is responsible for 1 node - the ResourceManager , which manages tasks, calculations, distributes computing resources between tasks, and is also responsible for accepting and setting tasks for execution.
')
Deploy HDFS
<Lyrical digression>
It should be noted that initially the idea of automating the deployment process of the Hadoop cluster looked quite exotic, in view of the rather “gentle” nature of it (although it may be my personal experience ...). What I mean? During automation, it turned out that the slightest deviation from the documentation led to a large number of questions or to the identification of problems previously documented in JIRA by the developers of Hadoop distributions.
In a word, cookbook turned out to be not the closest to the " best practices " in my understanding, since it contains a fair amount of Bash code, execute resources, and only occasionally (where possible) uses Ruby DSL and Chef resources .
Also, the idea that there is Apache Ambari , the native Hadoop cluster management system, was haunted . But again - this is not our method, and I wanted to understand the process without the help of third-party software.
</ Lyrical digression>
The time has come to dig deeper into the deployment process and the cookbook code, which will be responsible for automating the cluster deployment process.
I mentioned in the first article that the cookbook I wrote was based on Community practices , around which I created a wrapper. In fact, not everything went smoothly, because in the community cookbook version available at the time of my work start - there were several problems, sometimes very annoying - a typo, the wrong team and other trifles (we must pay tribute to the developer, who very quickly responded to my modest contribution and standing questions).
In fact, the achievements of the community were an excellent foundation for starting work, adding some solutions if possible.
Well, I started with the NameNode deployment and the HA + Failover mechanism. This process for Linux nodes can be described as follows:
- Installing prerequisites in the form of Java ;
- Adding repositories with packages of Hadoop distribution;
- Creating the backbone of the directories needed to install NameNode ;
- Generating configuration files based on the template and cookbook attributes
- Installing distribution packages (hdfs-namenode, zookeeper-server, etc)
- Exchange ssh-keys between NameNode (required for controlled failover );
- Depending on the role of the node ( Active / Standby ) - starting processes for cluster operation (hereinafter - more);
- Register the status of the deployment process.
Starting the processes necessary for NameNode to function consisted of the following steps:
- chown directories related to Hadoop components (for example, the NameNode HDFS installation directories) is a very important step, because in most cases leads to problems;
hdfs namenode -format, which formats and initializes the directory specified as dfs.namenode.name.dir ;service zookeeper-server start- start the zookeeper server used during failoverhdfs zkfc -formatZK- creates a znode (Zookeeper Data Node, in other words - a participant in the failover process);$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config /etc/hadoop/conf.chef/ --script hdfs start namenode"- to start the Active NameNode process
orhdfs namenode -bootstrapStandby- to run the Standby NameNode process on the node;$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config /etc/hadoop/conf.chef/ start zkfc- to start the ZooKeeper Failover Controller process;node.set['hadoop_services']['already_namenode'] = true— sets the status of the process, Ruby is the code that sets the attribute value of the node attribute.
After Chef has successfully worked on 2 nodes , following these steps, you can begin the installation verification process. There are several verification options that are best used:
- Open the NameNode DFS Health web page, accessible by default at the following address - FQDN: 50070 - which provides information about the role of the node ( Active or Standby ), available Slaves , as well as various system information and logs;
- Using the jps utility (provided in the Hadoop distribution and analogous to ps ), the output of which must include the NameNode , DFSZKFailoverController and QuorumPeerMain processes ;
- Launching local
hdfs haadmin -healthCheckandhdfs haadmin -getServiceState, the result of which, according to the stunt, is shown on the web page in a more detailed format; - To verify the failover process, you can call a controlled failover mechanism as follows:
hdfs haadmin -failover, as a result of which NameNode nodes should switch to Active / Standby roles.
A successful result is a bunch of 2 nodes , one of which takes on the role of Active NameNode , the other - Standby NameNode ; between the nodes ( znode ) a Zookeeper control is installed, which is able to conduct a failover process; access to the Slave nodes and the file system (the deployment of the Slave will be discussed in the next article).
As already mentioned, the high availability of our cluster can be achieved in 2 ways - using NFS / NAS or a dedicated JournalNode node.
In the case of NFS / NAS , all we need is to be able to “mount” the storage over the network to our NameNode. The storage should be available 24/7 (highly desirable), accessible with low latency, and also respond quickly to read / write operations over the network.
In the case of using JournalNode , it is necessary to select the node on which the JournalNode package is installed from the Hadoop distribution. For the configuration in the basic version, there are 2 parameters: dfs.journalnode.http-address — the parameter that indicates the FQDN and the port on which the JournalNode service is running ); dfs.journalnode.edits.dir - directory in which logs of events occurring in HDFS are added.
Deploying YARN
The YARN cluster part is represented in our ResourceManager architecture as a node that works with tasks and resources for their execution. The process of deploying this node looks simpler than NameNode :
- Installing prerequisites in the form of Java ;
- Adding repositories with packages of Hadoop distribution;
- Creating the backbone of the directories needed to install NameNode ;
- Generating configuration files based on the template and cookbook attributes
- Installing distribution packages ( hadoop-yarn-resourcemanager )
- Starting the ResourceManager process by
service hadoop-yarn-resourcemanager start; - Register the status of the deployment process.
To verify successful deployment, you can do the following:
- Open the ResourceManager web page, accessible, by default, at the following address - FQDN: 8088 - which provides data on available Slaves , as well as various information about the tasks and resources allocated for their execution;
- Using the jps utility (provided in the Hadoop distribution and analogous to ps ), in the output of which the ResourceManager process must be present;
That's about my part Masters . At the end of the next article, I plan to highlight a section in which I will describe the minimum cluster settings that are REQUIRED to run. Also, in the next article, I will publish links to my modest project and useful documentation, which I used in the process of creating it.
Thank you all for your attention! Comments and especially amendments are very welcome!
Source: https://habr.com/ru/post/222653/
All Articles