Hadoop and Automation: Part 1
Hello colleagues!

For the last couple of weeks I have been working on an interesting (from my point of view) occupation, which was the creation of Hadoop-as-a-Service solutions for our company's private cloud. First of all, I was wondering what kind of beast Hadoop is , why so often now are heard the combinations of the words Big Data and Hadoop . For me, familiarity with Hadoop began with a clean slate. Of course, I was not a Big Data expert and was not, therefore, I went into the point as much as was necessary to understand the processes in the context of cluster deployment automation.
My work was facilitated by the fact that the task was formulated quite clearly - there is a cluster architecture , there is a Hadoop distribution kit , there is a Chef automation tool. It remained only to get acquainted with the process of installing and configuring parts of the cluster, as well as options for its use. Further in the articles I will try to simplifyly describe the cluster architecture, the purpose of the parts thereof, as well as the configuration and launch process.
What did I need to get in the end? Such a scheme with architecture was available to me.
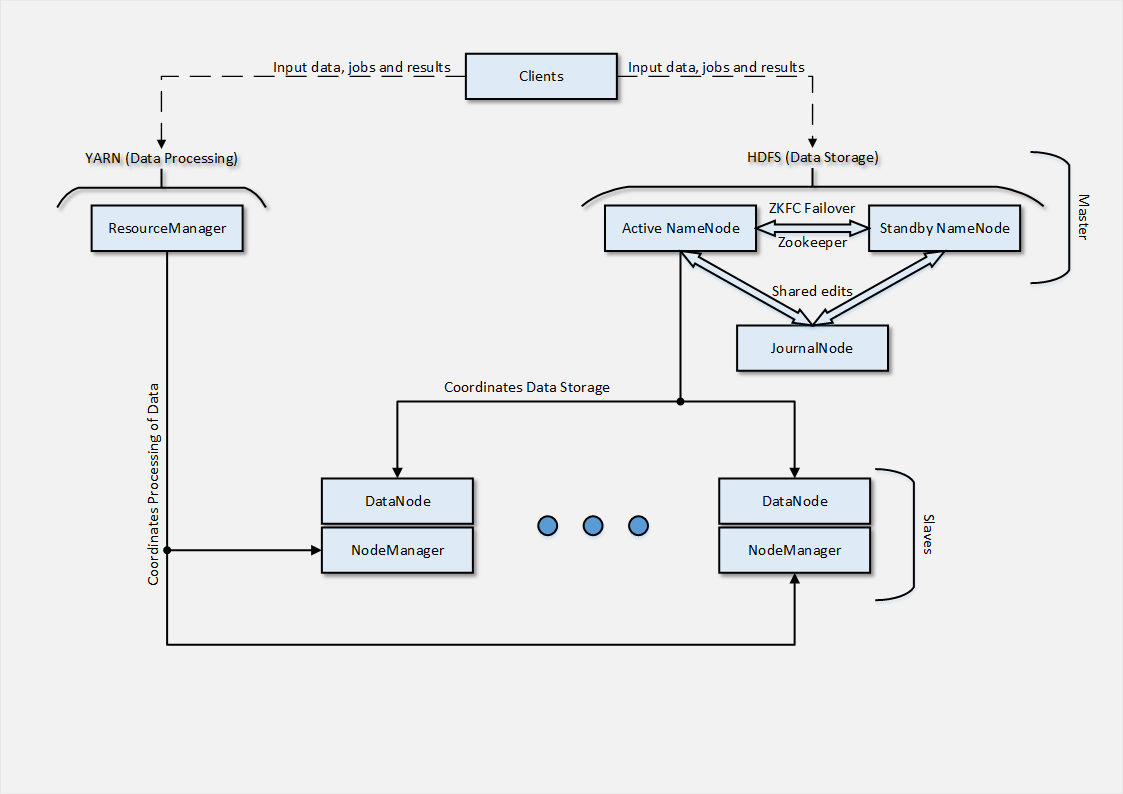
As I understood later, the simple architecture of a bare cluster (without Hbase , Hive , Pig and other third-party products related to Hadoop ) is quite simple. But, at first glance, everything was incomprehensible. Well, Google to help, and that's what turned out in the end ...
Hadoop cluster can be divided into 3 parts: Masters , Slaves and Clients .
Masters control the two main functions of the cluster — data allocation and calculations / processing associated with this data.
HDFS is responsible for data placement - Hadoop Distributed File System - presented in our architecture NameNode and JournalNode .
YARN , also known as MapReduce v.2 , is responsible for coordinating the assignment of tasks and conducting distributed computing.
')
Slaves do all the dirty work, they are the ones who receive and perform tasks related to calculations. Each slave consists of HDFS parts ( DataNode ) and YARN parts ( NodeManager ), respectively. Each part is responsible for the corresponding function, whether it is distributed data storage or distributed computing.
And finally, Clients , such kings of a cluster, who do nothing but submitting data and tasks to the cluster, as well as getting results .
Hadoop is written in Java , so any component requires its presence. The interaction between parts of the cluster is hidden in the depths of the Java classes , but only a part of the cluster settings is available to us by making the necessary settings in the right place.
By default, the configuration files are in the path / etc / hadoop / conf and are parameters that can be reassigned in a cluster:
Accordingly, for our automation process, not only an automated installation is necessary, but also the ability to change and create this configuration without actually editing it on the nodes.
The cluster was deployed on Ubuntu using HortonWorks (HDP) distribution kit version 2.0. *.
To create the cluster, 1 virtual machine was allocated for each part of the Masters , 1 Clients virtual machine and 2 virtual machines as Slaves .
When writing a wrapper cookbook, I used the ideas of the Community , namely this project by Chris Gianelloni , who turned out to be a very active developer who quickly responded to the bugs found in the cookbook -e. This cookbook provided the ability to install various parts of the Hadoop cluster, the basic cluster configuration by setting the cookbook attributes and generating configuration files based on them, as well as verifying that there is enough configuration to start the cluster.
Clients are virtual machines that provide data and tasks for the Hadoop cluster, as well as capture the results of distributed computing.
After adding records about HortonWorks repo to the Ubuntu repositories, various deb packages collected for various parts of the cluster became available.
We were, in this case, interested in the hadoop-client package, the installation of which was carried out as follows:
Simply? It doesn't get any simpler, thanks to colleagues from HortonWorks , who saved system administrators from having to build Hadoop from source.
The configuration for Clients is not needed, they are based on the configuration for Masters / Slaves (how the process of creating configuration files based on attributes is implemented in the next article ).
As a result, after the installation is completed, we will be able to send tasks for our cluster. Jobs are described in .jar files using the Hadoop classes. I will try to describe examples of starting tasks at the end of a series of articles, when our cluster will be fully operational.
The results of the cluster are added to the directories specified when starting the task or in the configuration files.
What should happen next? Further, after we send the task to our cluster, our Masters must receive the task (YARN) and files (HDFS) necessary to accomplish it, and carry out the process of distribution of the resources received by Slaves . In the meantime, we have neither Masters nor Slaves . It is about the detailed process of installing and configuring these parts of the cluster that I want to talk about in further articles.
Part 1 came out in a lightweight, introductory part in which I described what I needed to do and which path I chose to complete the task.
Further parts will be more full of code and aspects of starting and configuring a Hadoop cluster.
Comments about inaccuracies and errors in the description are welcome, I clearly have something to learn in the field of Big Data .
Thank you all for your attention!
For the last couple of weeks I have been working on an interesting (from my point of view) occupation, which was the creation of Hadoop-as-a-Service solutions for our company's private cloud. First of all, I was wondering what kind of beast Hadoop is , why so often now are heard the combinations of the words Big Data and Hadoop . For me, familiarity with Hadoop began with a clean slate. Of course, I was not a Big Data expert and was not, therefore, I went into the point as much as was necessary to understand the processes in the context of cluster deployment automation.
My work was facilitated by the fact that the task was formulated quite clearly - there is a cluster architecture , there is a Hadoop distribution kit , there is a Chef automation tool. It remained only to get acquainted with the process of installing and configuring parts of the cluster, as well as options for its use. Further in the articles I will try to simplifyly describe the cluster architecture, the purpose of the parts thereof, as well as the configuration and launch process.
Cluster architecture
What did I need to get in the end? Such a scheme with architecture was available to me.
As I understood later, the simple architecture of a bare cluster (without Hbase , Hive , Pig and other third-party products related to Hadoop ) is quite simple. But, at first glance, everything was incomprehensible. Well, Google to help, and that's what turned out in the end ...
Hadoop cluster can be divided into 3 parts: Masters , Slaves and Clients .
Masters control the two main functions of the cluster — data allocation and calculations / processing associated with this data.
HDFS is responsible for data placement - Hadoop Distributed File System - presented in our architecture NameNode and JournalNode .
YARN , also known as MapReduce v.2 , is responsible for coordinating the assignment of tasks and conducting distributed computing.
')
Slaves do all the dirty work, they are the ones who receive and perform tasks related to calculations. Each slave consists of HDFS parts ( DataNode ) and YARN parts ( NodeManager ), respectively. Each part is responsible for the corresponding function, whether it is distributed data storage or distributed computing.
And finally, Clients , such kings of a cluster, who do nothing but submitting data and tasks to the cluster, as well as getting results .
Hadoop is written in Java , so any component requires its presence. The interaction between parts of the cluster is hidden in the depths of the Java classes , but only a part of the cluster settings is available to us by making the necessary settings in the right place.
By default, the configuration files are in the path / etc / hadoop / conf and are parameters that can be reassigned in a cluster:
- hadoop-env.sh and yarn-env.sh - contains specific settings of environment variables, it is here that it is recommended to make settings for paths and options required by Hadoop ;
- core-site.xml - contains values that can be reassigned instead of the default values for the cluster, such as the root file system address, specifying different directories for Hadoop , etc .;
- hdfs-site.xml - contains settings for HDFS , namely for NameNode , DataNode , JournalNode , as well as for Zookeeper , such as domain names and ports on which this or that service is running, or directories needed to save distributed data;
- yarn-site.xml - contains settings for YARN , namely for ResourceManager and NodeManager , such as domain names and ports on which a particular service is running, resource allocation settings for processing, etc .;
- mapred-site.xml - contains the configuration for MapReduce jobs, as well as settings for the JobHistory MapReduce server;
- log4j.properties - contains the configuration of the logging process using the Apache Commons Logging framework ;
- hadoop-metrics.properties - indicates where Hadoop will send its metrics, be it a file or a monitoring system;
- hadoop-policy.xml - Security and ACL settings for the cluster;
- capacity-scheduler.xml - settings for CapacityScheduler, which is responsible for scheduling tasks and setting them in the execution queue, as well as distributing cluster resources by queues;
Accordingly, for our automation process, not only an automated installation is necessary, but also the ability to change and create this configuration without actually editing it on the nodes.
The cluster was deployed on Ubuntu using HortonWorks (HDP) distribution kit version 2.0. *.
To create the cluster, 1 virtual machine was allocated for each part of the Masters , 1 Clients virtual machine and 2 virtual machines as Slaves .
When writing a wrapper cookbook, I used the ideas of the Community , namely this project by Chris Gianelloni , who turned out to be a very active developer who quickly responded to the bugs found in the cookbook -e. This cookbook provided the ability to install various parts of the Hadoop cluster, the basic cluster configuration by setting the cookbook attributes and generating configuration files based on them, as well as verifying that there is enough configuration to start the cluster.
Automate the deployment of Clients
Clients are virtual machines that provide data and tasks for the Hadoop cluster, as well as capture the results of distributed computing.
After adding records about HortonWorks repo to the Ubuntu repositories, various deb packages collected for various parts of the cluster became available.
We were, in this case, interested in the hadoop-client package, the installation of which was carried out as follows:
package "hadoop-client" do action :install end Simply? It doesn't get any simpler, thanks to colleagues from HortonWorks , who saved system administrators from having to build Hadoop from source.
The configuration for Clients is not needed, they are based on the configuration for Masters / Slaves (how the process of creating configuration files based on attributes is implemented in the next article ).
As a result, after the installation is completed, we will be able to send tasks for our cluster. Jobs are described in .jar files using the Hadoop classes. I will try to describe examples of starting tasks at the end of a series of articles, when our cluster will be fully operational.
The results of the cluster are added to the directories specified when starting the task or in the configuration files.
What should happen next? Further, after we send the task to our cluster, our Masters must receive the task (YARN) and files (HDFS) necessary to accomplish it, and carry out the process of distribution of the resources received by Slaves . In the meantime, we have neither Masters nor Slaves . It is about the detailed process of installing and configuring these parts of the cluster that I want to talk about in further articles.
Part 1 came out in a lightweight, introductory part in which I described what I needed to do and which path I chose to complete the task.
Further parts will be more full of code and aspects of starting and configuring a Hadoop cluster.
Comments about inaccuracies and errors in the description are welcome, I clearly have something to learn in the field of Big Data .
Thank you all for your attention!
Source: https://habr.com/ru/post/222485/
All Articles