Synchronize MySQL + Git structure
To synchronize project files, history management, we use version control systems, for example, Git. However, when I had a question about controlling the versions of the structure of the MySQL base, it was not possible to find a satisfying solution.
I note, in many frameworks and ORM, there are necessary out-of-the-box mechanisms - migration, versioning, etc. But for the native work with MySQL - you have to do everything with pens. And the idea came to try to create an automatic system for tracking changes.
I wanted to change the database structure on the development-server, automatically update it on the production-server, and also see the history of all changes in Git, since it was already used to control the code. And so everything is free and easy!
For this, it is necessary to receive information on all change requests (CREATE, ALTER, DROP).
MySQL supports 3 ways of logging: error logs (error logs), logs of all requests (general logs), and logs of slow queries (slow logs).
I have not used the first option yet, but there are ideas (details below). Now about the other two options.
Logs can be written either to mysql tables or to files. The format of the log files is rather inconvenient and I decided to use tables.
Attention, since we are talking about ALL mysql logs, this solution should only be used on a dev server without loading MySQL!
')
The important point is the definition of the database to which the query goes, since it is in the SQL text of the query itself - this information may not be available.
It turned out that the general log writes only the stream number of the server, and in order to determine the database, we would have to search for an entry for this stream with an indication of the database used. In addition, the logs contain information about connecting and disconnecting to the server.
Mysql.general_log structure

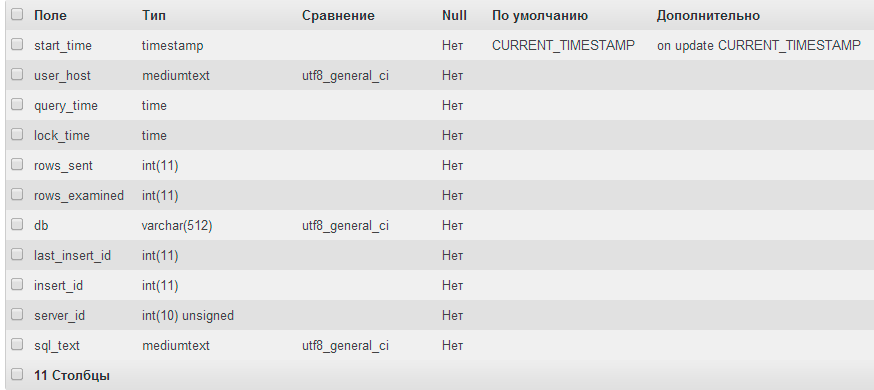
But in slow_log, everything that was needed was found: firstly, the logs contain only information about queries, and secondly, the name of the database is remembered, in the context of which there are queries.
Mysql.slow_log structure
Setting up slow log to record all requests is very simple in my.cnf
log_slow_admin_statements is needed to record ALTER requests.
So, we need to constantly take all requests, select from them requests to change the structure of the database and clean up all the others.
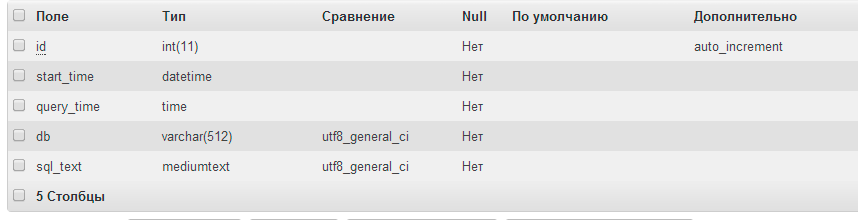
The mysql.slow_log table does not contain a key field, and it cannot be locked (and therefore partially delete records). Therefore, we will create a table that will suit us.
Structure change_structure_log
For the rotation of logs a small procedure:
And you can add it to the MySQL scheduler:
So, we have a table with all requests to change the structure. Now we will write a small script for its processing. I will not use any particular language (I personally write in PHP, but because of the large number of dependencies in the code, it makes no sense to lay out the code).
So:
1. We loop through all the records in the change_structure_log table.
2. For sql_text regular we pull out the database name, if it is, for example
3. If the request does not specify the name db - use it from the db field.
4. Write to the project folder with Git all the records of the corresponding databases. For example, 20140508150500.sql.log. For queries without a database, at the beginning write use $ DB;
5. Delete all processed records.
So, we have new files in the project folder with requests to change the database, now we can commit them as usual in our Git client.
Next, on the production server, we write a script that tracks the appearance of new files and executes them in mysql. So, when updating the git repository on a production server together with the code, we change the database to the state on the dev server.
Upd. Also (at the tip of DsideSPb ) you can use the hook for Git post-checkout, which will allow you to iterate on the update continuous and without external listeners.
At once I will say that this solution is quite primitive and does not support many of the functions of Git. However, based on it, we can do more cool things: by changing specific tables — for example, automatically changing the files of our ORM.
Or automatically create Yaml schemes - using any MySQL client without additional plug-ins to it.
It is also possible, for example, to track data changes in specific tables without changing the database structure itself (triggers, etc.), which can be useful for different CMS.
PS If we also want to learn about slow queries - we can integrate it into our system, for this we need to remove the filter from the procedure and in our script make a query for slow queries and save them.
I note, in many frameworks and ORM, there are necessary out-of-the-box mechanisms - migration, versioning, etc. But for the native work with MySQL - you have to do everything with pens. And the idea came to try to create an automatic system for tracking changes.
Task
I wanted to change the database structure on the development-server, automatically update it on the production-server, and also see the history of all changes in Git, since it was already used to control the code. And so everything is free and easy!
For this, it is necessary to receive information on all change requests (CREATE, ALTER, DROP).
Solution start
MySQL supports 3 ways of logging: error logs (error logs), logs of all requests (general logs), and logs of slow queries (slow logs).
I have not used the first option yet, but there are ideas (details below). Now about the other two options.
Logs can be written either to mysql tables or to files. The format of the log files is rather inconvenient and I decided to use tables.
Attention, since we are talking about ALL mysql logs, this solution should only be used on a dev server without loading MySQL!
')
The important point is the definition of the database to which the query goes, since it is in the SQL text of the query itself - this information may not be available.
CREATE TABLE /*DB_NAME.*/TABLE_NAME It turned out that the general log writes only the stream number of the server, and in order to determine the database, we would have to search for an entry for this stream with an indication of the database used. In addition, the logs contain information about connecting and disconnecting to the server.
Mysql.general_log structure
But in slow_log, everything that was needed was found: firstly, the logs contain only information about queries, and secondly, the name of the database is remembered, in the context of which there are queries.
Mysql.slow_log structure
Setting up slow log to record all requests is very simple in my.cnf
log-output=TABLEslow_query_log = 1long_query_time = 0log_slow_admin_statements = 1log_slow_admin_statements is needed to record ALTER requests.
Log processing
So, we need to constantly take all requests, select from them requests to change the structure of the database and clean up all the others.
The mysql.slow_log table does not contain a key field, and it cannot be locked (and therefore partially delete records). Therefore, we will create a table that will suit us.
Structure change_structure_log
For the rotation of logs a small procedure:
USE mysql; DELIMITER $$ CREATE PROCEDURE `change_structure_log_rotate`() BEGIN -- Definition start drop table if exists slow_log_copy; CREATE TABLE slow_log_copy LIKE slow_log; RENAME TABLE slow_log TO slow_log_old, slow_log_copy TO slow_log; insert into change_structure_log (start_time,query_time,sql_text, db) select start_time, query_time, sql_text,db from slow_log_old where sql_text like "ALTER%" OR sql_text like "CREATE%" OR sql_text like "DROP%"; drop table slow_log_old; -- Definition end END $$ And you can add it to the MySQL scheduler:
CREATE EVENT `event_archive_mailqueue` ON SCHEDULE EVERY 5 MINUTE STARTS CURRENT_TIMESTAMP ON COMPLETION NOT PRESERVE ENABLE COMMENT '' DO call change_structure_log_rotate(); So, we have a table with all requests to change the structure. Now we will write a small script for its processing. I will not use any particular language (I personally write in PHP, but because of the large number of dependencies in the code, it makes no sense to lay out the code).
So:
1. We loop through all the records in the change_structure_log table.
2. For sql_text regular we pull out the database name, if it is, for example
^ALTER\s+TABLE\s+(?:(?:ONLINE|OFFLINE)\s+)?(?:(?:IGNORE)\s+)?(?:([^\s\.]+)\.\s*)?([^\s\.]+)3. If the request does not specify the name db - use it from the db field.
4. Write to the project folder with Git all the records of the corresponding databases. For example, 20140508150500.sql.log. For queries without a database, at the beginning write use $ DB;
5. Delete all processed records.
So, we have new files in the project folder with requests to change the database, now we can commit them as usual in our Git client.
Next, on the production server, we write a script that tracks the appearance of new files and executes them in mysql. So, when updating the git repository on a production server together with the code, we change the database to the state on the dev server.
Upd. Also (at the tip of DsideSPb ) you can use the hook for Git post-checkout, which will allow you to iterate on the update continuous and without external listeners.
At once I will say that this solution is quite primitive and does not support many of the functions of Git. However, based on it, we can do more cool things: by changing specific tables — for example, automatically changing the files of our ORM.
Or automatically create Yaml schemes - using any MySQL client without additional plug-ins to it.
It is also possible, for example, to track data changes in specific tables without changing the database structure itself (triggers, etc.), which can be useful for different CMS.
PS If we also want to learn about slow queries - we can integrate it into our system, for this we need to remove the filter from the procedure and in our script make a query for slow queries and save them.
Source: https://habr.com/ru/post/221979/
All Articles