Number Recognition: A to 9
Already a couple of times on Habré, there were discussions on how number recognition works now. But articles where different approaches to recognition of numbers would be shown, on Habré so far were not. So here we try to figure out how it all works. And then, if the article is of interest, we will continue and lay out a working model that can be explored.

One of the key parameters for creating a recognition system is the hardware used for photographing. The more powerful and better the lighting system, the better the camera, the more likely it is to recognize the number. A good infrared (IR) floodlight can illuminate even the dust and dirt on the room, overshadow all the interfering factors. I think someone received a similar "letter of happiness", where, apart from the number, nothing is visible.

')
The better the shooting system, the more reliable the result. The best algorithm without a good shooting system is useless: you can always find a number that is not recognized. Here are two completely different frames:

This article deals with the software part, and the emphasis is on the case when the number is poorly visible and distorted (just taken “with hands” by any camera).
• Preliminary number search - detection of the area containing the number
• Number normalization - determination of exact number boundaries, normalization of a contrast
• Text recognition - reading all that was found in the normalized image
This is the basic structure. Of course, in a situation where the number is linearly located and well lit, and you have an excellent text recognition algorithm at your disposal, the first two points will disappear. In some algorithms, the number search and its normalization can be combined.
The most obvious way to select a number is to search for a rectangular contour. It works only in situations where there is a clearly readable circuit, not obstructed, with a sufficiently high resolution and with a smooth boundary.

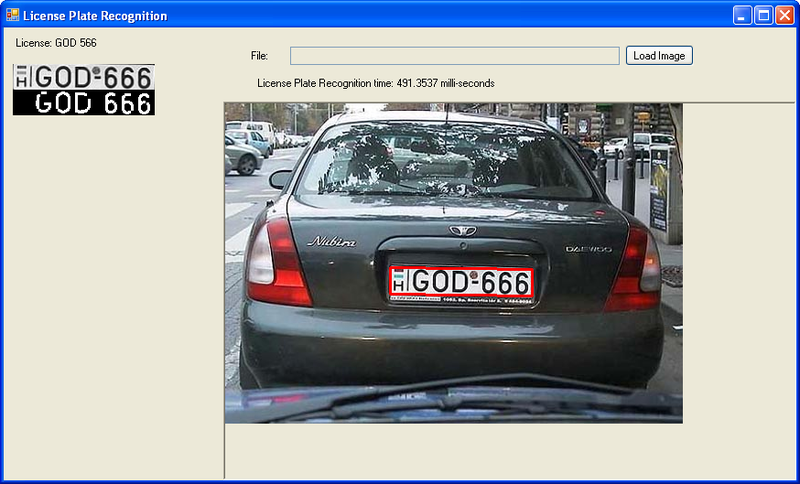
The image is filtered to find the boundaries, after which all found contours are selected and analyzed . Almost all student work with image processing is done in this way. There are plenty of examples in the internet. It works poorly, but at least somehow.
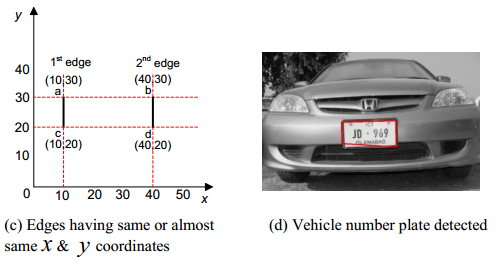
Much more interesting, more stable and more practical is the approach where only a part of it is analyzed from the frame. Outlines are selected, after which all vertical lines are searched. For any two straight lines, located close to each other, with a slight shift along the y axis, with the correct ratio of the distance between them to their length, the hypothesis that the number is located between them is considered. In essence, this approach is similar to the simplified HOG method.
One of the most popular methods of the approach is the analysis of image histograms ( 1 , 2 ). The approach is based on the assumption that the frequency response of a region with a number is different from the frequency response of a neighborhood.


Borders are highlighted on the image (highlighting the high-frequency spatial components of the image). The image is projected on the y axis (sometimes on the x axis). The maximum received projection can coincide with the location of the room.
This approach has a significant disadvantage - the machine must be comparable in size to the frame size, since the background may contain inscriptions or other detailed objects.
What is the disadvantage of all previous methods? In the fact that on real, mud-stained rooms there are neither pronounced boundaries nor pronounced statistics. Below are a couple of examples of such numbers. And, I must say, for Moscow, such examples are not the worst options.


The best methods, although not often used, are methods based on different classifiers. For example, the well- trained Haar cascade works well. These methods allow you to analyze the area for the presence in it of the characteristic number of relations, points or gradients. The method based on a specially synthesized transformation seems to me the most beautiful. True, I have not tried it, but, at first glance, it should work stably.
Such methods allow you to find not just a number, but a number in difficult and unusual conditions. The same cascade of Haar for the base collected in the winter in the center of Moscow produced about 90% of the correct number detection and 2-3% of the false capture. No single algorithm for detecting boundaries or histograms can produce such quality detection in such bad images.
Many methods in real algorithms directly or indirectly rely on the presence of number boundaries. Even if the borders are not used when detecting the number, they can be used in further analysis.
Unexpectedly, for statistical algorithms, even a relatively clean room in a chrome (light) frame on a white car can be a difficult case, since it occurs far less often than dirty numbers and may not occur a sufficient number of times during training.
Most of the above algorithms do not accurately detect the number and require further clarification of its position, as well as improving the quality of the image. For example, in this case, you need to rotate and trim the edges:

When only the neighborhood of the number is left, the selection of borders starts to work much better, since all the long horizontal lines that could be distinguished will be the borders of the number.
The simplest filter capable of distinguishing such direct ones is the Hough transform:

Huff's transformation allows you to quickly select two main lines and crop the image on them:

And it is better to improve the contrast of the resulting image in one way or another. Strictly speaking, it is necessary to strengthen the region of spatial frequencies that we are interested in:

After turning, we have a horizontal number with inaccurately defined left and right edges. It is not necessary to precisely cut off the excess now; it is enough to just cut the letters in the number and work with them.
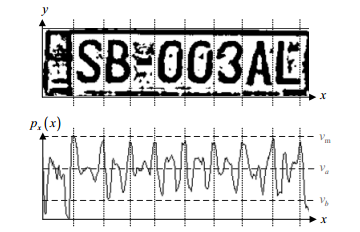
(The picture already has a binarization operation, i.e., some rule of dividing pixels into two classes has been used. When dividing a number into characters, this operation is not at all necessary, and it can be harmful in the future).
Now it suffices to find the maxima of the horizontal diagram, these will be the intervals of letters. Especially if we expect a certain number of characters and the distance between the characters will be approximately the same, then the division into letters according to the histogram will work perfectly.
It remains only to cut out the existing letters and go into the procedure for their recognition.
If the numbers are significantly contaminated, periodic maxima may simply not show up when broken into characters, although the symbols themselves may be quite readable visually.
Horizontal number boundaries are not always a good reference point. Numbers can be bent regularly (Mercedes C-class), can be gently recessed into an improper almost square depression for a number on American cars. And the upper limit of the rear room is simply often covered with body elements.
Naturally, to take into account all such problems - this is the task for serious number recognition systems.
The task of recognizing text or individual characters (optical character recognition, OCR) is, on the one hand, difficult and, on the other, completely classical. There are many algorithms for its solution, some of which have reached perfection . But, on the other hand, the best algorithms are not in the public domain. Of course there are Tesseract OCR and several of its analogues, but these algorithms do not solve all problems. In general, text recognition methods can be divided into two classes: structural methods based on morphology and contour analysis, dealing with a binarized image, and raster methods based on direct image analysis. It often uses a combination of structural and raster methods.
Firstly, in any case in Russia, a standard font is used in car numbers. It is just a gift for an automatic character recognition system. 90% of the OCR effort is spent on handwriting.
Secondly, the dirt.
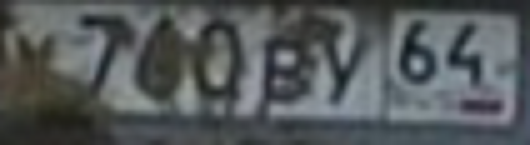
This is where the absolute majority of the known methods of character recognition have to be thrown away, especially if the image is binarized along the way to check the connectedness of areas, the separation of characters.
It is an open source software that automatically recognizes both a single letter and text immediately. Tesseract is convenient because it is for any operating system, it works stably and is easily trained. But he works very badly with obscure, broken, dirty and deformed text. When I tried to make it recognize the numbers - on the strength of only 20-30% of the numbers from the database were recognized correctly. The most clean and straight. Although, of course, when using ready-made libraries, something depends on the radius of curvature of the hands.
A very easy to understand character recognition method, which, despite its primitiveness, can often defeat not the most successful implementations of SVM or neural network methods.
It works as follows:
1) we pre-record a decent number of images of real characters already correctly divided into classes with their own eyes and hands
2) enter the measure of the distance between the characters (if the image is binarized, then the XOR operation will be optimal)
3) then, when we try to recognize a character, we alternately calculate the distance between it and all the characters in the database. Among the k nearest neighbors there may be representatives of various classes. Naturally, the representatives of which class are more among the neighbors; a recognizable symbol should be attributed to that class.
In theory, if you write a very large base with examples of symbols taken from different angles, lighting, with all possible scuffing, then K-nearest is all that is needed. But then you need to very quickly calculate the distance between the images, and, therefore, binarize it and use XOR. But then in the case of dirty or worn rooms there will be problems. Binarization changes the symbol completely unpredictably.
The method has one very important advantage: it is simple and transparent, which means it can be easily debugged and tuned to the optimal result. In many cases it is very important to understand how your algorithm works.
Often the methods used in image recognition are based on empirical approaches. But no one forbids the use of the mathematical apparatus of probability theory, which was simply polished in the tasks of signal detection in radar systems. The font on the car room is known to us; camera noise or dust on the room can with a stretch be called Gaussian. There is some uncertainty about the location of the symbol and its slope, but these parameters can be iterated. If we leave the image not binarized, then the signal amplitude, i.e., the brightness of the symbol, is still unknown to us.
I really do not want to go into a strict solution of this problem within the framework of the article. In fact, all the same, it all comes down to the operation of calculating the covariance of the input signal with a hypothetical one (taking into account the specified displacements and turns):
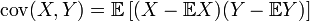
X is the input signal, Y is the hypothesis. The designation E is the mathematical expectation.
If you need to choose from different symbols, then the hypotheses for rotation and offset are constructed for each symbol. If we know for sure that the input image contains a symbol, then the maximum of the covariance of all the hypotheses will determine the symbol, its displacement and slope. Here, of course, there is the problem of the proximity of images of various characters ("p" and "c", "o" and "c", etc.). The simplest is to enter for each character a weight matrix of coefficients.
Sometimes these methods are called "template-matching", which fully reflects their essence. We set samples - we compare the input image with samples. If there is any uncertainty in the parameters, then either we look through all the possible options, or we use adaptive approaches , though here we already have to know and understand mathematics.
Advantages of the method:
- a predictable and well-studied result, if the noise at least corresponds to the chosen model;
- if the font is set strictly, as in our case, it is able to discern a highly dusty / dirty / worn symbol.
Disadvantages:
- computationally very expensive.
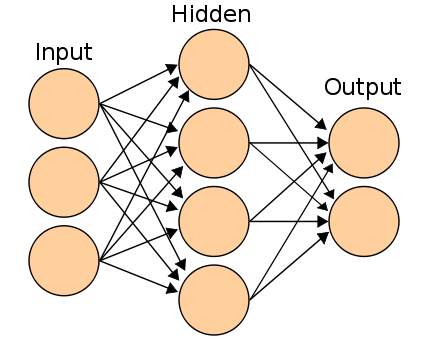
About artificial neural networks on Habré a lot has already been written. Now they are divided into two generations:
- classic 2-3-layer neural networks, learning by gradient methods with back propagation of errors (3-layer neural network is shown in the figure);
- the so-called deep-learning neural networks and convolutional networks.
The second generation of neural networks has been winning the last 7 years at various image recognition competitions, producing a slightly better result than the rest of the methods.
There is an open database of handwritten numbers images. The table of results very clearly demonstrates the evolution of various methods, including algorithms based on neural networks.
It is also worth noting that the simplest one-layer or two-layer (question of terminology) network , which in its essence is no different from the template-matching approaches, works great for printed fonts.
Advantages of the method:
- with proper setup and training it can work better than other known methods;
- with a large training array of data resistant to distortion of characters.
Disadvantages:
- the most difficult for the described methods;
- diagnosis of abnormal behavior in multilayer networks is simply impossible.
The article reviewed the basic recognition methods, their typical glitches and errors. Perhaps this will help you to make your number a little more readable when traveling around the city, or vice versa.
I also hope that I managed to show the complete absence of magic in the number recognition problem. Everything is absolutely clear and intuitive. It is absolutely not a terrible task for a student’s course work in the relevant specialty.
And a few days later ZlodeiBaal will lay out a small number recognition by numbers, based on our work on which this article was written. She can be tormented.
ZY All the numbers that are given in the article are extracted from Google and Yandex by simple queries.
1) ALGORITHMIC AND MATHEMATICAL PRINCIPLES OF AUTOMATIC NUMBER PLATE RECOGNITION SYSTEMS ONDREJ MARTINSKY - review article.
2) A holographic approach to the recognition of numbers.
3) Fatih Porikli, Tekin Kocak - Robust License Plate Detection Using the Covariance Descriptor in Neural Network Framework - a neural network approach when searching for a number
4) Saqib Rasheed, Asad Naeem and Omer Ishaq - Automated Number Plate Recognition Using Hough Lines and Template Matching - Search for numbers through HOG descriptors of vertical lines
5) Survey of Methods for Character Recognition Suruchi G. Dedgaonkar, Anjali A. Chandavale, Ashok M. Sapkal - a small overview article on the recognition of beeches and numbers
7) Tutorial " The basis of the theory of image processing ", Krasheninnikov V. R.
Software VS Iron
One of the key parameters for creating a recognition system is the hardware used for photographing. The more powerful and better the lighting system, the better the camera, the more likely it is to recognize the number. A good infrared (IR) floodlight can illuminate even the dust and dirt on the room, overshadow all the interfering factors. I think someone received a similar "letter of happiness", where, apart from the number, nothing is visible.
')
The better the shooting system, the more reliable the result. The best algorithm without a good shooting system is useless: you can always find a number that is not recognized. Here are two completely different frames:
This article deals with the software part, and the emphasis is on the case when the number is poorly visible and distorted (just taken “with hands” by any camera).
Algorithm structure
• Preliminary number search - detection of the area containing the number
• Number normalization - determination of exact number boundaries, normalization of a contrast
• Text recognition - reading all that was found in the normalized image
This is the basic structure. Of course, in a situation where the number is linearly located and well lit, and you have an excellent text recognition algorithm at your disposal, the first two points will disappear. In some algorithms, the number search and its normalization can be combined.
Part 1: Pre-Search Algorithms
Analysis of boundaries and shapes, contour analysis
The most obvious way to select a number is to search for a rectangular contour. It works only in situations where there is a clearly readable circuit, not obstructed, with a sufficiently high resolution and with a smooth boundary.
The image is filtered to find the boundaries, after which all found contours are selected and analyzed . Almost all student work with image processing is done in this way. There are plenty of examples in the internet. It works poorly, but at least somehow.
Analysis of only part of the boundary
Much more interesting, more stable and more practical is the approach where only a part of it is analyzed from the frame. Outlines are selected, after which all vertical lines are searched. For any two straight lines, located close to each other, with a slight shift along the y axis, with the correct ratio of the distance between them to their length, the hypothesis that the number is located between them is considered. In essence, this approach is similar to the simplified HOG method.
Histogram analysis of regions
One of the most popular methods of the approach is the analysis of image histograms ( 1 , 2 ). The approach is based on the assumption that the frequency response of a region with a number is different from the frequency response of a neighborhood.
Borders are highlighted on the image (highlighting the high-frequency spatial components of the image). The image is projected on the y axis (sometimes on the x axis). The maximum received projection can coincide with the location of the room.
This approach has a significant disadvantage - the machine must be comparable in size to the frame size, since the background may contain inscriptions or other detailed objects.
Statistical analysis, classifiers
What is the disadvantage of all previous methods? In the fact that on real, mud-stained rooms there are neither pronounced boundaries nor pronounced statistics. Below are a couple of examples of such numbers. And, I must say, for Moscow, such examples are not the worst options.
The best methods, although not often used, are methods based on different classifiers. For example, the well- trained Haar cascade works well. These methods allow you to analyze the area for the presence in it of the characteristic number of relations, points or gradients. The method based on a specially synthesized transformation seems to me the most beautiful. True, I have not tried it, but, at first glance, it should work stably.
Such methods allow you to find not just a number, but a number in difficult and unusual conditions. The same cascade of Haar for the base collected in the winter in the center of Moscow produced about 90% of the correct number detection and 2-3% of the false capture. No single algorithm for detecting boundaries or histograms can produce such quality detection in such bad images.
Weakness
Many methods in real algorithms directly or indirectly rely on the presence of number boundaries. Even if the borders are not used when detecting the number, they can be used in further analysis.
Unexpectedly, for statistical algorithms, even a relatively clean room in a chrome (light) frame on a white car can be a difficult case, since it occurs far less often than dirty numbers and may not occur a sufficient number of times during training.
Part 2: normalization algorithms
Most of the above algorithms do not accurately detect the number and require further clarification of its position, as well as improving the quality of the image. For example, in this case, you need to rotate and trim the edges:
Rotate room to horizontal orientation
When only the neighborhood of the number is left, the selection of borders starts to work much better, since all the long horizontal lines that could be distinguished will be the borders of the number.
The simplest filter capable of distinguishing such direct ones is the Hough transform:
Huff's transformation allows you to quickly select two main lines and crop the image on them:
Contrast increase
And it is better to improve the contrast of the resulting image in one way or another. Strictly speaking, it is necessary to strengthen the region of spatial frequencies that we are interested in:
Lettering
After turning, we have a horizontal number with inaccurately defined left and right edges. It is not necessary to precisely cut off the excess now; it is enough to just cut the letters in the number and work with them.
(The picture already has a binarization operation, i.e., some rule of dividing pixels into two classes has been used. When dividing a number into characters, this operation is not at all necessary, and it can be harmful in the future).
Now it suffices to find the maxima of the horizontal diagram, these will be the intervals of letters. Especially if we expect a certain number of characters and the distance between the characters will be approximately the same, then the division into letters according to the histogram will work perfectly.
It remains only to cut out the existing letters and go into the procedure for their recognition.
Weak spots
If the numbers are significantly contaminated, periodic maxima may simply not show up when broken into characters, although the symbols themselves may be quite readable visually.
Horizontal number boundaries are not always a good reference point. Numbers can be bent regularly (Mercedes C-class), can be gently recessed into an improper almost square depression for a number on American cars. And the upper limit of the rear room is simply often covered with body elements.
Naturally, to take into account all such problems - this is the task for serious number recognition systems.
Part 3: character recognition algorithms
The task of recognizing text or individual characters (optical character recognition, OCR) is, on the one hand, difficult and, on the other, completely classical. There are many algorithms for its solution, some of which have reached perfection . But, on the other hand, the best algorithms are not in the public domain. Of course there are Tesseract OCR and several of its analogues, but these algorithms do not solve all problems. In general, text recognition methods can be divided into two classes: structural methods based on morphology and contour analysis, dealing with a binarized image, and raster methods based on direct image analysis. It often uses a combination of structural and raster methods.
Differences from the standard OCR task
Firstly, in any case in Russia, a standard font is used in car numbers. It is just a gift for an automatic character recognition system. 90% of the OCR effort is spent on handwriting.
Secondly, the dirt.
This is where the absolute majority of the known methods of character recognition have to be thrown away, especially if the image is binarized along the way to check the connectedness of areas, the separation of characters.
Tesseract ocr
It is an open source software that automatically recognizes both a single letter and text immediately. Tesseract is convenient because it is for any operating system, it works stably and is easily trained. But he works very badly with obscure, broken, dirty and deformed text. When I tried to make it recognize the numbers - on the strength of only 20-30% of the numbers from the database were recognized correctly. The most clean and straight. Although, of course, when using ready-made libraries, something depends on the radius of curvature of the hands.
K-nearest
A very easy to understand character recognition method, which, despite its primitiveness, can often defeat not the most successful implementations of SVM or neural network methods.
It works as follows:
1) we pre-record a decent number of images of real characters already correctly divided into classes with their own eyes and hands
2) enter the measure of the distance between the characters (if the image is binarized, then the XOR operation will be optimal)
3) then, when we try to recognize a character, we alternately calculate the distance between it and all the characters in the database. Among the k nearest neighbors there may be representatives of various classes. Naturally, the representatives of which class are more among the neighbors; a recognizable symbol should be attributed to that class.
In theory, if you write a very large base with examples of symbols taken from different angles, lighting, with all possible scuffing, then K-nearest is all that is needed. But then you need to very quickly calculate the distance between the images, and, therefore, binarize it and use XOR. But then in the case of dirty or worn rooms there will be problems. Binarization changes the symbol completely unpredictably.
The method has one very important advantage: it is simple and transparent, which means it can be easily debugged and tuned to the optimal result. In many cases it is very important to understand how your algorithm works.
Correlation
Often the methods used in image recognition are based on empirical approaches. But no one forbids the use of the mathematical apparatus of probability theory, which was simply polished in the tasks of signal detection in radar systems. The font on the car room is known to us; camera noise or dust on the room can with a stretch be called Gaussian. There is some uncertainty about the location of the symbol and its slope, but these parameters can be iterated. If we leave the image not binarized, then the signal amplitude, i.e., the brightness of the symbol, is still unknown to us.
I really do not want to go into a strict solution of this problem within the framework of the article. In fact, all the same, it all comes down to the operation of calculating the covariance of the input signal with a hypothetical one (taking into account the specified displacements and turns):
X is the input signal, Y is the hypothesis. The designation E is the mathematical expectation.
If you need to choose from different symbols, then the hypotheses for rotation and offset are constructed for each symbol. If we know for sure that the input image contains a symbol, then the maximum of the covariance of all the hypotheses will determine the symbol, its displacement and slope. Here, of course, there is the problem of the proximity of images of various characters ("p" and "c", "o" and "c", etc.). The simplest is to enter for each character a weight matrix of coefficients.
Sometimes these methods are called "template-matching", which fully reflects their essence. We set samples - we compare the input image with samples. If there is any uncertainty in the parameters, then either we look through all the possible options, or we use adaptive approaches , though here we already have to know and understand mathematics.
Advantages of the method:
- a predictable and well-studied result, if the noise at least corresponds to the chosen model;
- if the font is set strictly, as in our case, it is able to discern a highly dusty / dirty / worn symbol.
Disadvantages:
- computationally very expensive.
Neural networks
About artificial neural networks on Habré a lot has already been written. Now they are divided into two generations:
- classic 2-3-layer neural networks, learning by gradient methods with back propagation of errors (3-layer neural network is shown in the figure);
- the so-called deep-learning neural networks and convolutional networks.
The second generation of neural networks has been winning the last 7 years at various image recognition competitions, producing a slightly better result than the rest of the methods.
There is an open database of handwritten numbers images. The table of results very clearly demonstrates the evolution of various methods, including algorithms based on neural networks.
It is also worth noting that the simplest one-layer or two-layer (question of terminology) network , which in its essence is no different from the template-matching approaches, works great for printed fonts.
Advantages of the method:
- with proper setup and training it can work better than other known methods;
- with a large training array of data resistant to distortion of characters.
Disadvantages:
- the most difficult for the described methods;
- diagnosis of abnormal behavior in multilayer networks is simply impossible.
Conclusion
The article reviewed the basic recognition methods, their typical glitches and errors. Perhaps this will help you to make your number a little more readable when traveling around the city, or vice versa.
I also hope that I managed to show the complete absence of magic in the number recognition problem. Everything is absolutely clear and intuitive. It is absolutely not a terrible task for a student’s course work in the relevant specialty.
And a few days later ZlodeiBaal will lay out a small number recognition by numbers, based on our work on which this article was written. She can be tormented.
ZY All the numbers that are given in the article are extracted from Google and Yandex by simple queries.
Literature
1) ALGORITHMIC AND MATHEMATICAL PRINCIPLES OF AUTOMATIC NUMBER PLATE RECOGNITION SYSTEMS ONDREJ MARTINSKY - review article.
2) A holographic approach to the recognition of numbers.
3) Fatih Porikli, Tekin Kocak - Robust License Plate Detection Using the Covariance Descriptor in Neural Network Framework - a neural network approach when searching for a number
4) Saqib Rasheed, Asad Naeem and Omer Ishaq - Automated Number Plate Recognition Using Hough Lines and Template Matching - Search for numbers through HOG descriptors of vertical lines
5) Survey of Methods for Character Recognition Suruchi G. Dedgaonkar, Anjali A. Chandavale, Ashok M. Sapkal - a small overview article on the recognition of beeches and numbers
7) Tutorial " The basis of the theory of image processing ", Krasheninnikov V. R.
Source: https://habr.com/ru/post/221891/
All Articles