Automatic text category detection
Introduction
In previous articles on organizing data in the form of a rubricator ( Using a graph as a basis for creating a rubricator and Problems underlying any creator of rubricators ), general ideas on organizing a rubricator were described. In this article I will describe one of the possible algorithms for automatically determining the subject of the text on the basis of a previously prepared graph-rubricator. At the same time, I consciously avoid complex formulas in order to convey the idea underlying the algorithm as simply as possible.
Preparation of rubricator data
To begin with, we will decide on the form in which we will prepare the data for the rubricator.
- 1. A rubricator is a graph, not a tree.
- 2. The text, the subject of which is determined, can be assigned to several headings simultaneously.
- 3. For each correlation with the rubric, the accuracy coefficient for determining the rubric is indicated.
- 4. The subject of the text is determined for each text separately, and does not depend on how the rubrics of other texts were defined earlier.
The last paragraph needs a little explanation. The independence of the definition of the subject matter of the text is very good when no subsequent sorting of results is required. When texts are simply classified or not. But if there are several texts in the rubric, it will probably be necessary to sort them by the criterion of the best hit in the rubric. In this article, this question is omitted for clarity.
Algorithm for determining the subject of the text, briefly
We describe the rubricator. We extract from the text under study the keywords described in the rubricator. As a result of the extraction, we get pieces of a broken and most often disconnected graph. We use a wave (or any other, if desired) algorithm to “pull out” the extracted pieces of the graph to the top of “everything”. We analyze and display the results.
Algorithm for determining the subject of the text, in detail
The creation of the rubricator has been described in detail in previous articles. At this stage, we believe that we have a lined graph rubricator, the leaf elements of which contain keywords, and the nodal rubrics.
We search the entire set of keywords of the rubricator in the text under study. Since there are many words that need to be found, I recommend for a specific implementation to refer to the algorithms for quickly finding arrays of strings in the text. For starters give links to the most popular of them:
Aho - Corasic Algorithm
The algorithm is characterized by a rather complex logic of building a tree and processing "returns", there are many examples of implementation. On Habré was a good description of this algorithm .
Rabin-Karp algorithm. A distinctive feature of the algorithm is effective work with very large sets of words.
In principle, reading the descriptions of the two proposed above algorithms, it is easy to come up with their own implementation based on them, which can take into account some additional conditions. For example, the requirement of case sensitivity to text, morphology, etc.
After the key words used in the description of the rubricator are extracted from the text under study, you can proceed directly to the definition of the subject of the text.
')
Wave
In the rubricator there is a “all” peak. Also there are keywords found in the text. The goal of this stage is to find a path from each found keyword for the vertex “everything”.
For the keyword "sand", the path to the root of the rubricator will look like this:
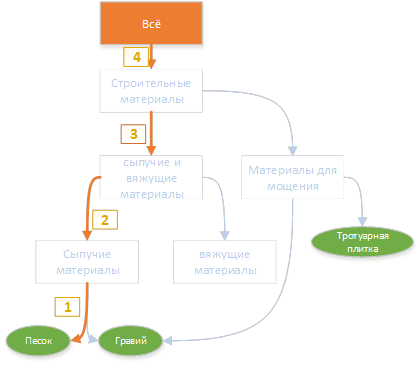
Similarly, the paths to the top are constructed for all the words found at the previous step.
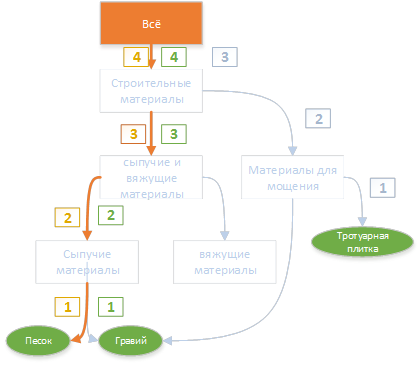
As a result of this construction for each keyword is the path to the top.
Subject definition
Let us now consider how the rubric was automatically determined by the example of the article: “ How to lay paving slabs? ". A person, even without reading the article, can assume that we will talk about possible ways of laying tiles and related materials and technologies.
Let's check how the automatic rubric definition for this article will work.
We begin, traditionally, with the keywords found in the article and having a mapping in the rubricator.
In the figure, the mark “heading” means that this element of the rubricator is not a sheet. This allows you to "combine" the name of the rubric and the keyword describing it.
The most popular word in the article “ How to lay paving slabs?” Is “paving slabs”, which was to be expected.
Below is the part of the rubricator that was involved in the example:
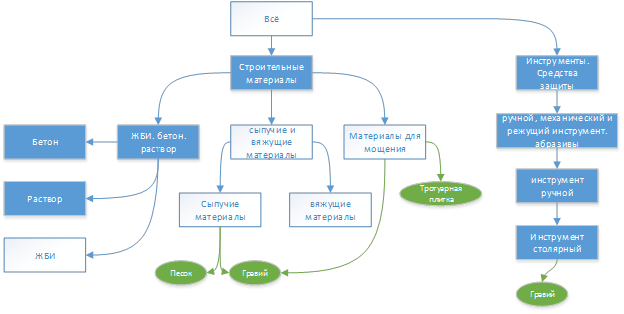
For example, it is shown that the key word “gravel” is assigned to two headings, and the key word “paving slabs” is only to one. Also, the headings, whose names are not found in the text, are highlighted by the light background. (Remember that a keyword and heading may have the same name. Details in previous articles.)
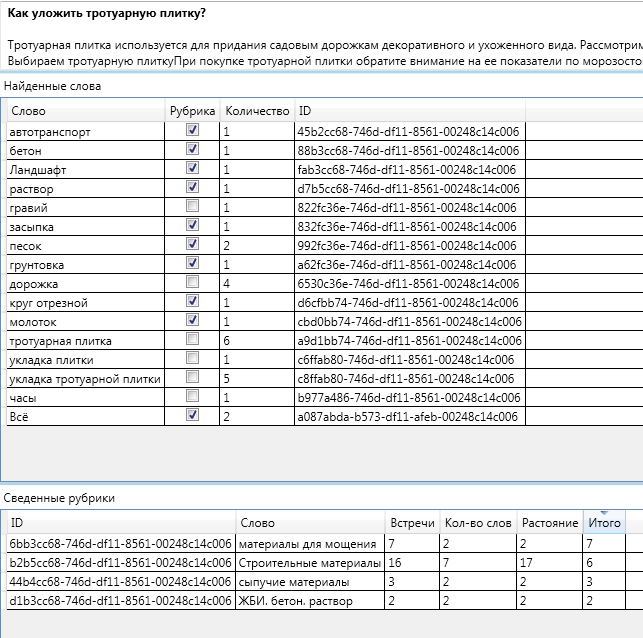
Now let's look at the rubrics to which the article was assigned:

The first rubric to which this article belongs is the “Paving materials” rubric.
In the figure, the highlighted line is a rubric with totals and below is a label with data for each word.
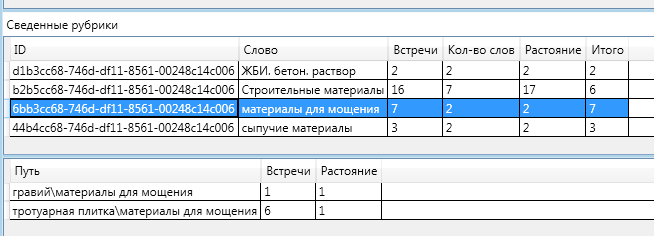
The final grade for this category is 7. This is the highest grade. From this rubric in the text 2 words met, 7 times at a total distance of 2. I recall that the distance between two vertices of the graph is the number of edges in the shortest path.
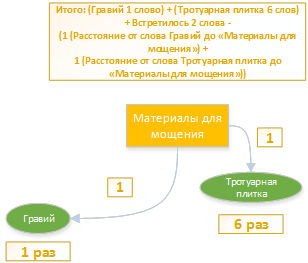
Namely, the text met the words "gravel" - once. And the key word "paving slabs" 6 times. Both of these words are affiliated with the paving materials category.
Total: (Gravel 1 word) + (Paving slabs 6 words) + 2 words met - (1 (Distance from the word Gravel to "Materials for paving") +
1 (Distance from the word Paving slabs to "Materials for paving"))
For the sake of completeness, I will give a diagram of the information in the remaining headings:
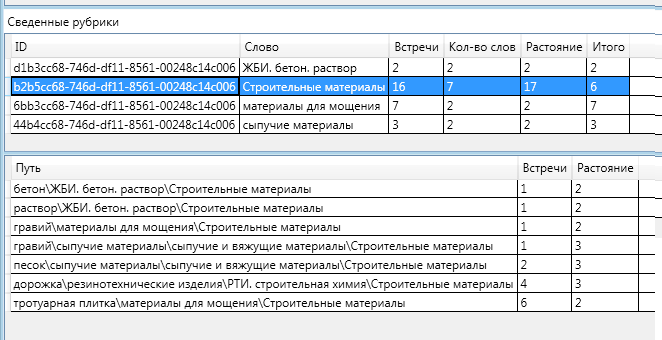
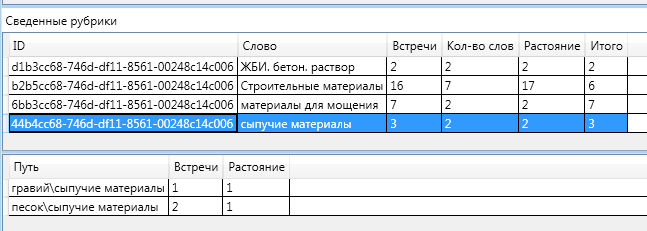
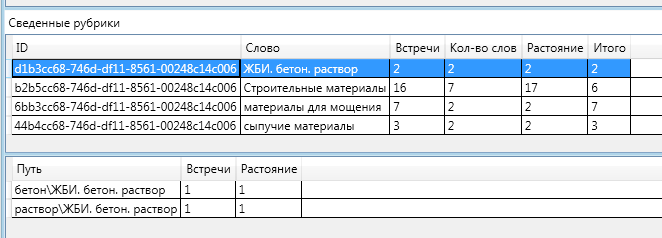
It is interesting to note the fact that “on the way” to the section “Construction materials” there were two rubrics: “bulk materials” and “bulk and binding materials”. One of them fell into the final definition, and the other did not.
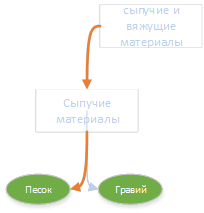
Sand and gravel together can be attributed to the heading "Bulk materials". "Bulk materials" can be attributed to the "Bulk and binder materials." The distance to the more general (upper) rubric is greater than the distance to the more specific (lower) one, according to the formula for calculating the relevance of "Total", is very small (up to negative).
Formula
The formula for determining the column “total” in the table is as follows:
Total = "Meetings" + "Number of words" - "Distance"
Meetings - the total number of keywords found.
Word Count - How many different words were found.
Distance - the total distance from each word to the selected rubric.
And this formula is far from a fundamental postulate. And, for sure, it can be improved, equipped with additional elements, etc. (I propose to discuss this in the comments).
Looking ahead, I want to note that when developing this system, we specifically tried to avoid any explicitly specified coefficients, so as not to get lost in the intricacies of fine tuning.
Growth points
At its core, the rubricator cannot immediately be composed uniformly. Certainly, some of his section will be more developed than others. This can lead to a “skew” of the graph and to an increase in the distance from the “leaves at the vertex” in one part and a significant decrease in the other. This imbalance can negatively affect the "correct" calculation of the distance in the graph. Here you can try to take into account the number of children at each node of the graph.

The second interesting idea to optimize the process of determining the subject of the text is the idea of selectively defining topics for different sections of the text, followed by a composition of the results.
The idea is based on the fact that, as a rule, at the beginning of any article there is an “introduction” section abounding with a variety of keywords, the subsequent sections clarify the idea of the article, which makes it possible to classify each individual chapter more reliably.
As others do
It is interesting to see what the same example looks like in other online topics definition services.
The site http://www.linkfeedator.ru/index.php?task=tematika gives the following result:

Website: http://sm.ashmanov.com/demo/

findings
The topic of automatic categorization-rubrication of texts is very relevant for search engines, and systems for processing and extracting knowledge. I hope that this article will be useful not only for those who are just beginning to learn automatic classification technologies, but also for those who have eaten more than one dog.
Thanks
I express my gratitude to those who read the first two articles and shared feedback, as well as personally to Andrei Benkov for his help in obtaining beautiful tables with numbers.
Source: https://habr.com/ru/post/221853/
All Articles