Explanation http2
The other day, Daniel Stenberg, one of the participants in the HTTPbis IETF group, which is developing the http2 protocol, published an extremely interesting document “http2 explained” on his blog. A small 26-page PDF document in a very accessible language tells about the prerequisites and details for implementing the http2 protocol.
It seems to me that today it is one of the best explanations of what the http2 protocol is, why it is needed, how it will affect web development and what future the Internet is facing in connection with its appearance. I think that all people involved in web development and web building information will be useful, because it is expected that the http2 standard will be adopted as early as June of this year after the final meeting of the HTTPbis group in New York.
Many modern browsers to some extent support the latest version of the draft http2, so you can expect that after a short period of time (weeks) after the adoption of the standard, all customers will support it. Many large Internet companies such as Google, Facebook and Twitter are already testing their web services to work with http2.
Therefore, in order not to one day suddenly find yourself in a world that works on a protocol about which you only heard something with the edge of your ear and have no idea what it is and how it works, I advise you to look at this document. Personally, I was under the impression that I made a Russian translation ( Update: the translation is now available directly in this article ). Please, if you find inaccuracies in translation or typographical errors, report. I hope that as a result, the document will be as clear and useful as possible to a large circle of people.
')
History, Protocol, Implementation, and Future
daniel.haxx.se/http2
This is a document that describes http2 from a technical and protocol level. It originally appeared as a presentation that I presented in Stockholm in April 2014. I have since received many questions about the content of the presentation from people who could not attend the event, so I decided to convert it into a full document with details and proper explanations.
At the time of writing (April 28, 2014), the final specification of http2 is not complete and not released. The current version of the draft is called draft-12 , but we expect to see at least one more version before http2 is complete. This document describes the current situation, which may or may not change in the final specification. All errors in this document - my own, which appeared through my fault. Please report them to me and I will release an update with corrections.
The version of this document is 1.2.
My name is Daniel Stenberg and I work at Mozilla. I have been involved in open source software and networks for more than twenty years in various projects. I’m probably best known as the main curl and libcurl developer. For many years, I was involved in the IETF HTTPbis working group and worked on both HTTP 1.1 support, to meet the latest requirements, and work on http2 standardization.
Email: daniel@haxx.se
Twitter: @bagder
Web: daniel.haxx.se
Blog: daniel.haxx.se/blog
If you find typos, omissions, errors and obvious lies in this document, please send me a corrected version of the paragraph and I will release a corrected version. I will properly mark everyone who helped! I hope that in time it will turn out to make the text better.
This document is available at daniel.haxx.se/http2
This document is licensed under the Creative Commons Attribution 4.0 license: creativecommons.org/licenses/by/4.0

HTTP 1.1 has become a protocol that is truly used for everything on the Internet. Huge investments were made in protocols and infrastructure, which are now deriving profit from this. It got to the point that today it is often easier to run something on top of HTTP than to create something new in its place.
When HTTP was created and released into the world, it was probably perceived rather as a simple and straightforward protocol, but time has shown that this is not the case. HTTP 1.0 in RFC 1945 is 60 pages of specification, released in 1996. RFC 2616, which described HTTP 1.1, was released only three years later in 1999 and has grown significantly to 176 pages. In addition, when we at the IETF worked on updating the specification, it was split into six documents with an even greater number of pages in total. Without a doubt, HTTP 1.1 is large and includes a myriad of details, subtleties and no less an optional section.
The nature of HTTP 1.1, enclosed in the presence of a large number of fine details and options available for subsequent change, has grown an ecosystem of programs where there is not a single implementation that embodies everything - and, in fact, it is impossible to say for sure what this is " everything". What led to a situation where opportunities that were initially little used appeared only in a small number of implementations, and those who realized them after they saw little use of them.
Later, this caused compatibility problems when clients and servers began to make more active use of such features. HTTP pipelining ( HTTP pipelining ) is one illustrative example of such features.
HTTP 1.1 has come a hard way to really take advantage of all the power and performance that TCP provides. HTTP clients and browsers need to be truly inventive in order to find ways to reduce page load times.
Other experiments that have been conducted in parallel over many years have also confirmed that TCP is not so easy to replace, and therefore we continue to work on improving both TCP and the protocols working on top of it.
TCP can be easily started to use fully to avoid pauses or time periods that could be used to send or receive more data. Subsequent chapters will highlight some of these disadvantages of use.
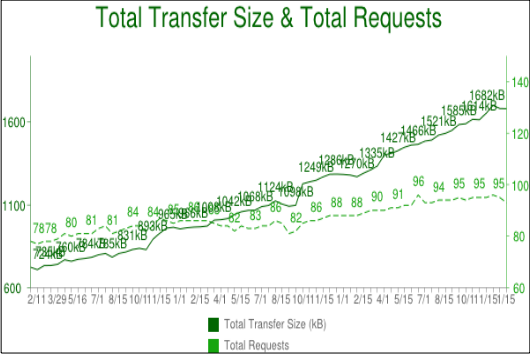
When you look at the development trends of some of the most popular sites today and compare how long it takes to load their main page, the trends become obvious. Over the past few years, the amount of data that needs to be transferred has gradually increased to 1.5 MB and higher, but what is most important for us in this context is the number of objects, which is now close to one hundred on average. One hundred objects must be loaded to display the entire page.
As the chart shows, the trend was growing, but later there are no signs that it will continue to change.
HTTP 1.1 is very sensitive to latency, partly due to the fact that HTTP pipelining still has problems and is turned off by an overwhelming number of users.
While we all have seen a significant increase in user bandwidth over the past few years, we have not seen a similar level of delay reduction. High-latency channels, like many modern mobile technologies, greatly reduce the feeling of good and fast web navigation, even if you have a really high-speed connection.
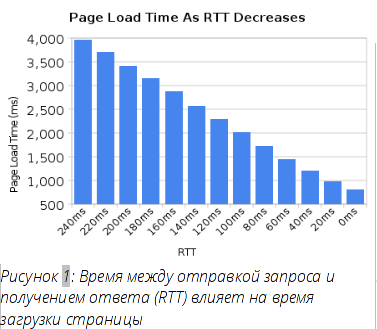
Another example where low latency is really required is certain types of video, such as video conferencing, games, and the like, where not only a previously created stream needs to be transmitted.
HTTP pipelining is a way to send another request, already waiting for a response to a previous request. It looks like a queue to the cashier in a supermarket or bank. You do not know what kind of people are in front of you: fast clients or annoying people who need endless time to complete the service - blocking the beginning of the line.

Of course, you can carefully select a queue and eventually choose the one that you think is right, and sometimes you can create your own queue, but in the end, you cannot avoid making a decision and once you choose a queue, you cannot change it.
Creating a new queue is associated with performance and paying for resources, and cannot scale beyond a small number of queues. There is no perfect solution for this task.
Even today, in 2014, most web browsers on desktops come with the HTTP pipeline disabled by default.
Additional information on this issue can be found in the Firefox bug tracker number 264354 .
As usual, when people encounter errors, they come together to find workarounds. Some workaround paths are skillful and useful, some simply terrifying crutches.
Creating sprites is a term often used to describe an action when you collect many small images into one large one. Then use javascript or CSS to “cut” parts of a large image to display small images.

The site uses this trick to speed up. Getting one large request is much faster in HTTP 1.1 than getting one hundred separate small pictures.
Of course, this has its drawbacks for those pages of the site that require only one or two small pictures. It also throws out all the cached pictures at the same time, instead of possibly leaving some of the most used ones.
Embedding is another trick to avoid sending individual images, using data instead — the URL embedded in the CSS file. This has the same advantages and disadvantages as sprites.
As well as in the two previous cases, today large sites may have a lot of javascript files. Utilities of developers allow you to combine all these files into one huge com, so that the browser receives one file instead of many small ones. A large amount of data is sent, then only as a small fragment is actually required. An excessive amount of data is required to be reloaded when a change is required.
Developer irritation and coercion to fulfill these requirements is, of course, “just” pain for the people involved and is not displayed in any performance graphs.
The final trick I’ll mention, used by site owners to improve browsing, is often called "sharding." This basically means spreading your service across as many different hosts as possible. At first glance, this sounds crazy, but there is a simple reason for this!
Initially, HTTP allowed a client to use a maximum of two TCP connections per host. Thus, in order not to violate the specification, advanced sites simply came up with new host names and voila, you can get more connections for your site and reduce page load time.
Over time, this restriction was removed from the specification and today customers use 6-8 connections per host, but they still have a restriction, so sites continue to increase the number of connections. As the number of objects has increased, as I showed earlier, a large number of connections have been used just to make sure that HTTP copes well and makes the site faster. It is not unusual for sites to use more than 50 or even 100 compounds using this technique.
Another reason for sharding is placing images and similar resources on individual hosts that do not use cookies, since cookies can be of considerable size today. Using the cookie-free image hosts, you can increase your productivity just at the expense of significantly smaller HTTP requests!
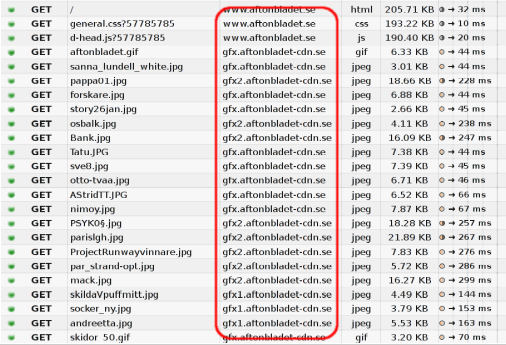
The figure below shows what packet entries look like when browsing one of the top Sweden web sites and how requests are distributed across multiple hosts.
Wouldn't it be better to make an improved protocol? Which would include the following ...
The Internet Engineering Council (IETF) is an organization that develops and promotes Internet standards. Mostly at the protocol level. They are well known for a series of RFC documents documenting everything from TCP, DNS, FTP to best practices, HTTP, and many protocol options that have not been applied anywhere.
Inside the IETF, there are dedicated “working groups” that are formed around a small circle of tasks to achieve the goal. They constitute a “charter” of a set of principles and limitations for achieving the goal. Anyone and everyone can join the discussion and development. Everyone who participates and expresses something has equal opportunities and chances to influence the result and everyone is counted as people and individuals, without regard to the company in which the person works.
The HTTPbis working group was formed during the summer of 2007 and had to update the HTTP 1.1 specification - hence the “bis” suffix. The group discussion of the new version of the HTTP protocol really began at the end of 2012. Work on updating HTTP 1.1 was completed in early 2014.
The final meeting for the HTTPbis working group before the expected final release of the http2 specification version will be held in New York in early June 2014.
Some big players in the HTTP field were missing in the discussions and meetings of the working group. I do not want to name any particular company or product name here, but it is clear that today some actors on the Internet appear to be confident that the IETF will do everything well without involving these companies ...
The group is named HTTPbis, where the “bis” suffix is derived from the Latin dialect, which means “two”. Bis is often used as a suffix or part of a name inside the IETF for an update or a second attempt at working on a specification. Also as in the case of HTTP 1.1.
SPDY is a protocol that was developed and initiated by Google. They were definitely developing it openly and inviting everyone to participate, but it was obvious that they gained tremendous advantages by having control over two implementations: a popular web browser and a large population of servers with heavily used services.
When the HTTPbis group decided to start working on http2, SPDY was already tested as a working concept. He showed that it could be deployed on the Internet, and there were published figures that showed how he coped. Work on http2 subsequently began with the SPDY / 3 draft, which by and large became the http2 draft-00 draft after a couple of search and replace operations.
So what is http2 made for? Where are the boundaries that limit the scope of the HTTPbis group?
They are, in fact, quite clear and impose noticeable restrictions on the team’s ability to innovate.

As noted earlier, existing URI schemes cannot be changed, so http2 should only use them. Since today they are used for HTTP 1.x, we need an explicit way to upgrade the protocol to http2 or otherwise ask the server to use http2 instead of old protocols.
HTTP 1.1 already has a predefined method for this, the so-called Upgrade header, which allows the server to send a response using the new protocol when a similar request is received using the old protocol. At the cost of one iteration of the request-response.
Payoff request-response time was not what the SPDY team could agree on, and since they also developed SPDY over TLS, they created a new TLS extension, which was used to significantly reduce coordination. Using this extension, called NPN from Next Protocol Negotiation (negotiation of the next protocol), the client informs the server on which protocols he would like to communicate and the server can respond to the most preferred one he knows.
Much attention in http2 was paid to ensure that it works correctly on top of TLS. SPDY worked only on top of TLS and there was a strong desire to make TLS mandatory for http2, but consensus was not reached and http2 would be released with the optional TLS. However, two well-known specification developers have clearly stated that they will only implement http2 over TLS: the head of Mozilla Firefox and the head of Google Chrome. These are the two leading browsers for today.
The reasons for choosing TLS-only mode are to take care of the user's privacy, and early research has shown a high level of success with new protocols when using TLS. This is due to the widespread assumption that all that comes to port 80 is HTTP 1.1, and some intermediate network devices interfere and destroy the traffic of other protocols that run on this port.

The subject of compulsory TLS causes many sweep hands and campaign calls on mailing lists and meetings - is it good or evil? This is a sore point - remember this if you decide to ask this question directly in the face of HTTPbis!
The following protocol negotiation (NPN) is the protocol that SPDY used to negotiate with the TLS servers. Since it was not a real standard, it was reworked into the IETF and the ALPN appeared instead: Application Level Protocol Negotiation . ALPN is promoted for use in http2, while SPDY clients and servers still use NPN.
The fact that NPN appeared first, and it took time for ALPN to go through standardization, led to the fact that early implementations of http2 clients and http2 servers used both of these extensions when negotiating http2.
As was briefly noted earlier, for text-based HTTP 1.1, in order to negotiate http2, you need to send a request to the server with the Upgrade header. If the server understands http2, it will respond with “101 Switching” status and then start using http2 in the connection. Of course, you understand that this update procedure is worth the time of one complete network request-response, but on the other hand the http2 connection can be maintained and reused for much longer than the usual HTTP1 connection.
Despite the fact that some representatives of browsers insist that they will not implement this method of matching http2, the Internet Explorer team has expressed its willingness to implement it.
Suffice it to say about prerequisites, history and politics, and now we are here. Let's dive into the specifics of the protocol. Those parts and concepts that make up http2.
http2 is a binary protocol.
Let's try to realize this for a moment. If you were familiar with Internet protocols before, then it is likely that you instinctively strongly oppose this fact and prepare arguments about how useful it is to have protocols that use the / ascii text, and that you wrote HTTP 1.1 requests with your hands hundreds of times. connecting with a telnet to the server.
http2 - binary to make the formation of packages easier. Determining the beginning and end of a packet is one of the most difficult tasks in HTTP 1.1 and in all text protocols in principle. By moving away from optional spaces and all sorts of ways to write the same things, we make implementation easier.
In addition, it makes it much easier to separate the parts associated with the protocol itself and the data packet, which is randomly intermixed in HTTP1.
The fact that the protocol allows the use of compression and often works on top of TLS also reduces the value of the text, since in any case you will no longer see plaintext in the wires. We just have to understand that you need to use Wireshark analyzer or something similar to find out what happens at the protocol level in http2.
Debugging of this protocol will most likely be performed by utilities such as curl, or by analyzing the network stream by the http2-dissector Wireshark or something like that.
http2 sends frames. There are many different frames, but they all have the same structure:
The type, length, flags, flow identifier, and frame payload.
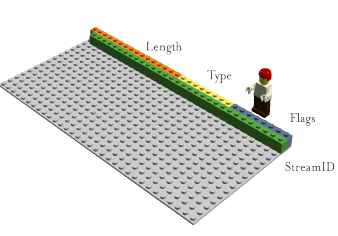
There are twelve different types of frames in the current http2 draft, including two, perhaps the most important, that are associated with HTTP 1.1: DATA (data) and HEADERS (headers). I will describe some of the frames in more detail later.
The stream identifier mentioned in the previous section describing the frame format binds each frame transmitted over http2 to a so-called “stream”. A stream is a logical association. An independent two-way sequence of frames exchanged between the client and the server within the http2 connection.
A single http2 connection may contain multiple simultaneous open streams from either side exchanging frames of multiple streams. Streams can be installed and used unilaterally or shared by both the client and the server, and can be closed by either party. The order in which frames are sent is important. The recipient processes the frames in the order they are received.
Multiplexing streams means that packets of multiple streams are mixed within a single connection. Two (or more) separate data trains are collected into one train, and then divided on the other side. Here are two trains:

They come together one at a time in mixed mode:

In http2 we will see dozens and hundreds of simultaneous stream. The price of creating a thread is very low.
Each thread has a priority used to show the other exchange participant which threads to consider as more important.
The exact details of the work priorities in the protocol have changed several times and are still being discussed. The idea is that the client can specify which of the threads is the most important and there is a dependency parameter that allows you to make one thread dependent on another.
Priorities can be dynamically changed during the exchange, which allows the browser to be sure that when a user scrolls through a page filled with images, he can specify which images are most important, or when you switch tabs, he can increase the priority for threads that suddenly fall into focus.
HTTP is a stateless protocol. In short, this means that each request must contain the maximum number of details that are required by the server to execute the request without having to save a lot of metadata from the previous request. Since http2 does not change any of these paradigms, it has to do the same.
This makes HTTP repetitive. When a client requests multiple resources from a single server, such as images on a web page, this turns into a large series of requests that look almost the same. For a series of something almost the same, compression is self-evident.

As I already mentioned, as the number of objects on the page increases, the use of cookies and the size of requests also continue to grow. Cookies should also be included in all requests that are almost always the same across multiple requests.
The size of an HTTP 1.1 request became so large over time that it sometimes became larger than the original TCP window size, which made it extremely slow in sending, requiring a full send-receive cycle to receive an ACK confirmation from the server before the full request is sent . Another argument for compression.
HTTPS and SPDY compression were found to be vulnerable to the BREACH and CRIME attacks . By inserting a known text into the stream and observing how the encrypted output changes, the attacker could figure out what was sent.
Compression for dynamic content in the protocol without the risk of being exposed to one of the known attacks, requires serious deliberation and attention. What the HTTPbis team is trying to do.
This is how HPACK appeared, HTTP / 2 Header Compression , which, as the name suggests, is a compression format designed specifically for http2 headers and, strictly speaking, this is a separate Internet draft draft specification. The new format is shared with other counter-measures, such as special flags, which ask intermediaries not to compress certain headers and optionally add extra empty data to the frames in order to complicate the attack on compression.
Immediately before the release of draft 12, support for gzip compressed DATA frames was added. Each frame is compressed individually, so there is no common context between them, but this slightly reduces the level of compression. This feature corresponds to using gzip in Transfer-Encoding in HTTP 1.1. An opportunity that is seldom used, but often discussed, as a failure in the protocol, at least for browsers.
One of the drawbacks of HTTP 1.1 is that when an HTTP message is sent with a Content-Length header of a certain length, you cannot just stop it. Of course, you can often (but not always - I’ll skip here a long explanation of why this is so) break the TCP connection, but at the cost of re-negotiating a new TCP connection.
Now you can simply cancel the sending and start a new message. This can be achieved by sending an http2 frame RST_STREAM, which thus prevents bandwidth waste and the need to break the connection.
This feature is also known as “cache”. The idea is that if a client requests a resource X, and the server assumes that the client will probably then ask for resource Z, it sends this resource to the client without a request from him. This helps the customer to put Z into his cache, and he will be there when needed.
Sending a server is something that the client must explicitly allow the server, and even if it does, it can of its choice quickly cancel the sent stream using RST_STREAM if it was not needed by it.
After http2 adaptation, there are reasons to expect that TCP connections will be longer and last longer in working condition than it was with HTTP 1.x connections. The client will be able to do a lot of things that he wants within one connection to each host / site and this connection will probably be open for a very long time.
This will affect the operation of the HTTP balancers, and there may be situations where the site wants to offer the client to connect to another host. This may be for both performance reasons, but also the need for outages for maintenance or similar purposes.
The server sends an Alt-Svc header (or ALTSVC frame to http2), informing the client about the availability of an alternative service. Additional route to the same content using a different service, host and port number.
It is expected that the client will try to asynchronously connect to the service and start using the alternative service if it works normally.
The Alt-Svc header allows a server that provides content on http: // to inform the client about the presence of the same content available over the TLS connection.
This is partly a controversial opportunity. This connection performs unauthenticated TLS and will not be marked “safe” anywhere: it will not show the lock in the program interface and does not inform the user that this is not the usual old open HTTP. But it will be an opportunistic TLS and some people are very confident in opposing this concept.
Each individual stream in http2 has its own declared stream window, which the other side allowed to transfer data. If you imagine how SSH works, then this is very similar and done in the same spirit and style.
For each stream, both ends tell each other that they still have room to accept input data, and the opposite end is allowed to send only a specified amount of data until the window is expanded.
In the draft draft-12, after a long discussion, a frame was added, called BLOCKED. He can be sent once by the http2 member when he has data to send, but the control of the flow prohibits him from sending any data. The idea is that if your implementation receives such a frame, you must understand that your implementation has missed something and / or you cannot achieve high data transfer rates because of this.
Quote from draft-12:
What will it look like when http2 is accepted? Will he be accepted?
http2 is not yet widely represented and used. We can not say exactly how everything goes. We have seen how SPDY was used and we can make some assumptions and calculations based on this and other past and current experiments.

http2 reduces the number of required network round-trips, completely avoids the turn-start blocking dilemmas at the expense of multiplexing and the rapid rejection of unwanted streams.
It allows you to work multiple parallel streams, the number of which can exceed the number of connections even in the most actively using modern sites sharding ...
With the priorities correctly used on the streams, the chances of obtaining important data earlier than the less important ones are much higher.
Putting it all together, I’ll say that the chances are very high that this will speed up page loading and increase the responsiveness of websites. In short: better feeling from the web surfing.
How much faster and how much better we will see. I do not think that we are ready to say so far. Firstly, the technology is still still young, and secondly, we have not yet seen neat implementations of clients and servers that truly use all the power that the new protocol provides.
Over the years, web developers and web development environments have compiled a complete set of techniques and utilities to work around HTTP 1.1 issues, some of which are noted at the beginning of this document.
Most of these workarounds, which tools and developers now use without thinking about by default, are likely to hit http2 performance or at least not take advantage of all the benefits of the new http2 superpower. Sprites and embedding should not be used with http2. Sharding is likely to be bad for http2, since http2 benefits from using fewer connections.
The problem here is of course that web developers will have to develop and implement websites in a world where, at best, for a short period of time, there will be both HTTP 1.1 and http2 clients, and, for maximum performance by all users, It will be costly to offer two different versions of the site.
For this reason alone, I suspect it will take some time before we see the full potential of http2.
Of course, trying to document specific implementations in documents like this is completely useless work, which is doomed to failure and will become obsolete in a very short period of time. Instead, I will explain the situation in a broad sense and direct the readers to the list of implementations on the http2 website.

Already there are a large number of implementations and their number is growing day by day as you work on http2. At the same time, at the time of writing, there are 19 implementations, and some of them implement the latest draft specification.

Firefox has always been at the forefront of the latest version of the draft, Twitter continues to provide services on http2. Google launched support for draft-10 on some of its services in April.

Support for curl and libcurl is made on the basis of a separate implementation of the http2 library, called nghttp2, which supports both plain http2 and on top of TLS. curl can use TLS for http2 using one of the TLS libraries: OpenSSL, NSS or GnuTLS.
In the process of developing a protocol, debates arose again and again, and, of course, there are a number of people who believe that the protocol turned out to be completely wrong. I would like to point out some of the most typical complaints and arguments against him:
There are also variations implying that the world is even more dependent and controlled by Google. It is not true.The protocol was developed internally by the IETF in the same way that protocols were developed over the last 30 years. However, we are all grateful to Google for the unparalleled work on SPDY, which not only proved that it is possible to implement a new protocol in this way, but also helped get estimates of what we can get.
To some extent this is so. One of the main reasons behind http2 development is fixing HTTP pipelining. If in your case pipelining was not required, then http2 will not be particularly useful for you.
This is certainly not the only achievement of the protocol, but the most significant.
As soon as services begin to understand all the power and capabilities of multiplexed streams in one connection, I expect that we will see an increase in the number of applications using http2.
Small REST APIs and simple HTTP 1.x software applications will not benefit greatly from switching to http2. But, nevertheless, there will be very few drawbacks for most users.
To some extent this is true. TLS negotiation gives little overhead, but efforts are already underway to further reduce the number of request-responses for TLS. The cost of performing TLS encryption, compared to plaintext, is not as insignificant and clearly visible, so more processor and time and electricity will be spent on the same traffic as in an insecure protocol. How much and what consequences it will have - a topic for statements and measurements. See, for example, istlsfastyet.com as one of the sources on the topic.
http2 does not require the use of TLS, so we should not mix terms.
Most users on the Internet today want TLS to be more widely used, and we must help protect the privacy of users.
Yes, we like the idea of seeing the protocol openly, as this makes debugging easier. But text protocols are much more prone to errors and are prone to problems of proper parsing.
If you really cannot accept the binary protocol, then you will also not be able to accept both TLS and HTTP 1.x compression, which have been around for quite a long time.
It's still quite early to say for sure, but I can guess and appreciate, and that's what I'm going to do here.
Skeptics will say “look at how well IPv6 was done,” as an example of a new protocol that took decades to simply at least begin to be widely used. http2 is not IPv6 at all. This is a TCP-based protocol, using the usual HTTP update mechanism, port number, TLS, etc. It will not require replacing most routers and brandmauers at all.
Google has proved to the world through its work on SPDY that such a new protocol can be implemented and used by browsers and services with several implementations in a fairly short period of time. Despite the fact that the number of servers on the Internet that today offer SPDY in the region of 1%, but the amount of data with which they work much more. Some of the most popular websites today offer SPDY.
http2, based on the same basic paradigms as SPDY, I’m sure it will probably be implemented even more actively, as this is the official IETF protocol. The implementation of SPDY has always been restrained by the stigma of “this is the Google protocol”.
Behind the release are several well-known browsers. At least, the representatives of Firefox, Chrome and Internet Explorer have expressed their readiness to release a browser with support for http2.
There are several server providers that are likely to offer http2 soon, including Google, Twitter and Facebook, and we expect to see http2 support in popular web server implementations such as Apache HTTP Server and nginx.
Firefox tracks the draft specification very tightly and has provided support for the test http2 implementation for many months now. During the development of the http2 protocol, clients and servers must agree on which version of the draft protocol they implemented, which makes the test run somewhat annoying, just be prepared for this.
Enter "about: config" in the address bar and look for an option called "network.http.spdy.enabled.http2draft". Make sure it is set to true.
Remember that Firefox only implements http2 over TLS. You will see http2 work in Firefox only when you go to https: // sites that support http2.
Any element anywhere in the interface will not say that you are working on http2. You can't understand it that easily. There is only one way to find out by turning on “Web Development-> Network”, check the response headers and see what you got from the server ... The response contains something about “HTTP / 2.0” and Firefox inserts its header with the name “X- Firefox-Spdy ”, as shown in this already outdated screenshot.

The headers that you see in network tools, when communicating over http2, are converted from http2 into similar to the old HTTP1.x headers.
curl http2, 2013 .
curl, http2, . curl -, , http2.
curl http2- HTTP 1.x , HTTP. curl HTTP . curl . curl HTTP 1.x , http2-. , HTTP .
curl http2 Upgrade. HTTP- HTTP 2, curl http2, .
curl TLS- TLS-, - http2. TLS http2 – APLN , , NPN.
curl OpenSSL NSS ALPN NPN. GnuTLS ALPN, NPN.
curl, http2, , TLS, --http2 (« http2»).
https:// http:// URL', curl_easy_setopt CURLOPT_HTTP_VERSION CURL_HTTP_VERSION_2, libcurl http2. http2, , - HTTP 1.1.
A large number of difficult decisions and compromises were made in http2. After deploying http2, there is a way to upgrade to other working versions of the protocol, which makes it possible to create more revisions of the protocol afterwards. It also brings a view and infrastructure that can support many different protocol versions at the same time. Perhaps we do not need to completely remove the old when we create a new one?
http2 still has a lot of outdated HTTP 1 transferred to it because of the desire to keep the ability to proxy traffic in all directions between HTTP 1 and http2. Some of this heritage makes it difficult to further develop and innovate. Maybe http3 will be able to drop some of them?
What do you think is still missing in http?
If you think this document is a little simple in content or technical details, then additional resources are given that will satisfy your curiosity:
It seems to me that today it is one of the best explanations of what the http2 protocol is, why it is needed, how it will affect web development and what future the Internet is facing in connection with its appearance. I think that all people involved in web development and web building information will be useful, because it is expected that the http2 standard will be adopted as early as June of this year after the final meeting of the HTTPbis group in New York.
Many modern browsers to some extent support the latest version of the draft http2, so you can expect that after a short period of time (weeks) after the adoption of the standard, all customers will support it. Many large Internet companies such as Google, Facebook and Twitter are already testing their web services to work with http2.
Therefore, in order not to one day suddenly find yourself in a world that works on a protocol about which you only heard something with the edge of your ear and have no idea what it is and how it works, I advise you to look at this document. Personally, I was under the impression that I made a Russian translation ( Update: the translation is now available directly in this article ). Please, if you find inaccuracies in translation or typographical errors, report. I hope that as a result, the document will be as clear and useful as possible to a large circle of people.
')
http2
History, Protocol, Implementation, and Future
daniel.haxx.se/http2
Story
This is a document that describes http2 from a technical and protocol level. It originally appeared as a presentation that I presented in Stockholm in April 2014. I have since received many questions about the content of the presentation from people who could not attend the event, so I decided to convert it into a full document with details and proper explanations.
At the time of writing (April 28, 2014), the final specification of http2 is not complete and not released. The current version of the draft is called draft-12 , but we expect to see at least one more version before http2 is complete. This document describes the current situation, which may or may not change in the final specification. All errors in this document - my own, which appeared through my fault. Please report them to me and I will release an update with corrections.
The version of this document is 1.2.
Author
My name is Daniel Stenberg and I work at Mozilla. I have been involved in open source software and networks for more than twenty years in various projects. I’m probably best known as the main curl and libcurl developer. For many years, I was involved in the IETF HTTPbis working group and worked on both HTTP 1.1 support, to meet the latest requirements, and work on http2 standardization.
Email: daniel@haxx.se
Twitter: @bagder
Web: daniel.haxx.se
Blog: daniel.haxx.se/blog
Help!
If you find typos, omissions, errors and obvious lies in this document, please send me a corrected version of the paragraph and I will release a corrected version. I will properly mark everyone who helped! I hope that in time it will turn out to make the text better.
This document is available at daniel.haxx.se/http2
License
This document is licensed under the Creative Commons Attribution 4.0 license: creativecommons.org/licenses/by/4.0
HTTP today
HTTP 1.1 has become a protocol that is truly used for everything on the Internet. Huge investments were made in protocols and infrastructure, which are now deriving profit from this. It got to the point that today it is often easier to run something on top of HTTP than to create something new in its place.
HTTP 1.1 is huge
When HTTP was created and released into the world, it was probably perceived rather as a simple and straightforward protocol, but time has shown that this is not the case. HTTP 1.0 in RFC 1945 is 60 pages of specification, released in 1996. RFC 2616, which described HTTP 1.1, was released only three years later in 1999 and has grown significantly to 176 pages. In addition, when we at the IETF worked on updating the specification, it was split into six documents with an even greater number of pages in total. Without a doubt, HTTP 1.1 is large and includes a myriad of details, subtleties and no less an optional section.
World of options
The nature of HTTP 1.1, enclosed in the presence of a large number of fine details and options available for subsequent change, has grown an ecosystem of programs where there is not a single implementation that embodies everything - and, in fact, it is impossible to say for sure what this is " everything". What led to a situation where opportunities that were initially little used appeared only in a small number of implementations, and those who realized them after they saw little use of them.
Later, this caused compatibility problems when clients and servers began to make more active use of such features. HTTP pipelining ( HTTP pipelining ) is one illustrative example of such features.
Inadequate use of TCP
HTTP 1.1 has come a hard way to really take advantage of all the power and performance that TCP provides. HTTP clients and browsers need to be truly inventive in order to find ways to reduce page load times.
Other experiments that have been conducted in parallel over many years have also confirmed that TCP is not so easy to replace, and therefore we continue to work on improving both TCP and the protocols working on top of it.
TCP can be easily started to use fully to avoid pauses or time periods that could be used to send or receive more data. Subsequent chapters will highlight some of these disadvantages of use.
Transfer size and number of objects
When you look at the development trends of some of the most popular sites today and compare how long it takes to load their main page, the trends become obvious. Over the past few years, the amount of data that needs to be transferred has gradually increased to 1.5 MB and higher, but what is most important for us in this context is the number of objects, which is now close to one hundred on average. One hundred objects must be loaded to display the entire page.
As the chart shows, the trend was growing, but later there are no signs that it will continue to change.
Lag kills
HTTP 1.1 is very sensitive to latency, partly due to the fact that HTTP pipelining still has problems and is turned off by an overwhelming number of users.
While we all have seen a significant increase in user bandwidth over the past few years, we have not seen a similar level of delay reduction. High-latency channels, like many modern mobile technologies, greatly reduce the feeling of good and fast web navigation, even if you have a really high-speed connection.
Another example where low latency is really required is certain types of video, such as video conferencing, games, and the like, where not only a previously created stream needs to be transmitted.
Block start queue
HTTP pipelining is a way to send another request, already waiting for a response to a previous request. It looks like a queue to the cashier in a supermarket or bank. You do not know what kind of people are in front of you: fast clients or annoying people who need endless time to complete the service - blocking the beginning of the line.
Of course, you can carefully select a queue and eventually choose the one that you think is right, and sometimes you can create your own queue, but in the end, you cannot avoid making a decision and once you choose a queue, you cannot change it.
Creating a new queue is associated with performance and paying for resources, and cannot scale beyond a small number of queues. There is no perfect solution for this task.
Even today, in 2014, most web browsers on desktops come with the HTTP pipeline disabled by default.
Additional information on this issue can be found in the Firefox bug tracker number 264354 .
Steps taken to overcome the delay
As usual, when people encounter errors, they come together to find workarounds. Some workaround paths are skillful and useful, some simply terrifying crutches.
Creating sprites
Creating sprites is a term often used to describe an action when you collect many small images into one large one. Then use javascript or CSS to “cut” parts of a large image to display small images.
The site uses this trick to speed up. Getting one large request is much faster in HTTP 1.1 than getting one hundred separate small pictures.
Of course, this has its drawbacks for those pages of the site that require only one or two small pictures. It also throws out all the cached pictures at the same time, instead of possibly leaving some of the most used ones.
Embedding
Embedding is another trick to avoid sending individual images, using data instead — the URL embedded in the CSS file. This has the same advantages and disadvantages as sprites.
.icon1 { background: url(data:image/png;base64,<data>) no-repeat; } .icon2 { background: url(data:image/png;base64,<data>) no-repeat; } Union
As well as in the two previous cases, today large sites may have a lot of javascript files. Utilities of developers allow you to combine all these files into one huge com, so that the browser receives one file instead of many small ones. A large amount of data is sent, then only as a small fragment is actually required. An excessive amount of data is required to be reloaded when a change is required.
Developer irritation and coercion to fulfill these requirements is, of course, “just” pain for the people involved and is not displayed in any performance graphs.
Sharding
The final trick I’ll mention, used by site owners to improve browsing, is often called "sharding." This basically means spreading your service across as many different hosts as possible. At first glance, this sounds crazy, but there is a simple reason for this!
Initially, HTTP allowed a client to use a maximum of two TCP connections per host. Thus, in order not to violate the specification, advanced sites simply came up with new host names and voila, you can get more connections for your site and reduce page load time.
Over time, this restriction was removed from the specification and today customers use 6-8 connections per host, but they still have a restriction, so sites continue to increase the number of connections. As the number of objects has increased, as I showed earlier, a large number of connections have been used just to make sure that HTTP copes well and makes the site faster. It is not unusual for sites to use more than 50 or even 100 compounds using this technique.
Another reason for sharding is placing images and similar resources on individual hosts that do not use cookies, since cookies can be of considerable size today. Using the cookie-free image hosts, you can increase your productivity just at the expense of significantly smaller HTTP requests!
The figure below shows what packet entries look like when browsing one of the top Sweden web sites and how requests are distributed across multiple hosts.
HTTP update
Wouldn't it be better to make an improved protocol? Which would include the following ...
- Create a protocol that is less sensitive to RTT
- Fix pipelining and blocking the start of the queue
- Stop the need and desire to increase the number of connections to each host.
- Save existing interfaces, all content, URI format and schemas
- Do it within the IETF HTTPbis working group
IETF and HTTPbis Working Group
The Internet Engineering Council (IETF) is an organization that develops and promotes Internet standards. Mostly at the protocol level. They are well known for a series of RFC documents documenting everything from TCP, DNS, FTP to best practices, HTTP, and many protocol options that have not been applied anywhere.
Inside the IETF, there are dedicated “working groups” that are formed around a small circle of tasks to achieve the goal. They constitute a “charter” of a set of principles and limitations for achieving the goal. Anyone and everyone can join the discussion and development. Everyone who participates and expresses something has equal opportunities and chances to influence the result and everyone is counted as people and individuals, without regard to the company in which the person works.
The HTTPbis working group was formed during the summer of 2007 and had to update the HTTP 1.1 specification - hence the “bis” suffix. The group discussion of the new version of the HTTP protocol really began at the end of 2012. Work on updating HTTP 1.1 was completed in early 2014.
The final meeting for the HTTPbis working group before the expected final release of the http2 specification version will be held in New York in early June 2014.
Some big players in the HTTP field were missing in the discussions and meetings of the working group. I do not want to name any particular company or product name here, but it is clear that today some actors on the Internet appear to be confident that the IETF will do everything well without involving these companies ...
“Bis” suffix
The group is named HTTPbis, where the “bis” suffix is derived from the Latin dialect, which means “two”. Bis is often used as a suffix or part of a name inside the IETF for an update or a second attempt at working on a specification. Also as in the case of HTTP 1.1.
http2 started with SPDY
SPDY is a protocol that was developed and initiated by Google. They were definitely developing it openly and inviting everyone to participate, but it was obvious that they gained tremendous advantages by having control over two implementations: a popular web browser and a large population of servers with heavily used services.
When the HTTPbis group decided to start working on http2, SPDY was already tested as a working concept. He showed that it could be deployed on the Internet, and there were published figures that showed how he coped. Work on http2 subsequently began with the SPDY / 3 draft, which by and large became the http2 draft-00 draft after a couple of search and replace operations.
Http2 concept
So what is http2 made for? Where are the boundaries that limit the scope of the HTTPbis group?
They are, in fact, quite clear and impose noticeable restrictions on the team’s ability to innovate.
- It must support HTTP paradigms. This is still the protocol where clients send requests to the server over TCP.
- Links http: // and https: // can not be changed. You cannot add a new schema or do something like this. The amount of content that uses similar addressing is too large to ever expect such a change.
- HTTP1 servers and clients will exist for decades, we should be able to proxy them to http2 servers.
- Consequently, proxies must be able to convert one-to-one http2 features into HTTP 1.1 for clients.
- Remove or reduce the number of optional parts in the protocol. This is not so much a requirement as a mantra, which came from SPDY and the Google team. Insisting that all requirements are mandatory, you will not have the opportunity not to do something now, and then fall into the trap.
- No more minor versions. It was decided that clients and servers can be either compatible with http2 or not. If it turns out that you need to expand the protocol or change it, then http3 will appear. The http2 will no longer be minor versions.
http2 for existing URI schemes
As noted earlier, existing URI schemes cannot be changed, so http2 should only use them. Since today they are used for HTTP 1.x, we need an explicit way to upgrade the protocol to http2 or otherwise ask the server to use http2 instead of old protocols.
HTTP 1.1 already has a predefined method for this, the so-called Upgrade header, which allows the server to send a response using the new protocol when a similar request is received using the old protocol. At the cost of one iteration of the request-response.
Payoff request-response time was not what the SPDY team could agree on, and since they also developed SPDY over TLS, they created a new TLS extension, which was used to significantly reduce coordination. Using this extension, called NPN from Next Protocol Negotiation (negotiation of the next protocol), the client informs the server on which protocols he would like to communicate and the server can respond to the most preferred one he knows.
http2 for https: //
Much attention in http2 was paid to ensure that it works correctly on top of TLS. SPDY worked only on top of TLS and there was a strong desire to make TLS mandatory for http2, but consensus was not reached and http2 would be released with the optional TLS. However, two well-known specification developers have clearly stated that they will only implement http2 over TLS: the head of Mozilla Firefox and the head of Google Chrome. These are the two leading browsers for today.
The reasons for choosing TLS-only mode are to take care of the user's privacy, and early research has shown a high level of success with new protocols when using TLS. This is due to the widespread assumption that all that comes to port 80 is HTTP 1.1, and some intermediate network devices interfere and destroy the traffic of other protocols that run on this port.
The subject of compulsory TLS causes many sweep hands and campaign calls on mailing lists and meetings - is it good or evil? This is a sore point - remember this if you decide to ask this question directly in the face of HTTPbis!
http2 negotiation over tls
The following protocol negotiation (NPN) is the protocol that SPDY used to negotiate with the TLS servers. Since it was not a real standard, it was reworked into the IETF and the ALPN appeared instead: Application Level Protocol Negotiation . ALPN is promoted for use in http2, while SPDY clients and servers still use NPN.
The fact that NPN appeared first, and it took time for ALPN to go through standardization, led to the fact that early implementations of http2 clients and http2 servers used both of these extensions when negotiating http2.
http2 for http: //
As was briefly noted earlier, for text-based HTTP 1.1, in order to negotiate http2, you need to send a request to the server with the Upgrade header. If the server understands http2, it will respond with “101 Switching” status and then start using http2 in the connection. Of course, you understand that this update procedure is worth the time of one complete network request-response, but on the other hand the http2 connection can be maintained and reused for much longer than the usual HTTP1 connection.
Despite the fact that some representatives of browsers insist that they will not implement this method of matching http2, the Internet Explorer team has expressed its willingness to implement it.
Http2 protocol
Suffice it to say about prerequisites, history and politics, and now we are here. Let's dive into the specifics of the protocol. Those parts and concepts that make up http2.
Binary protocol
http2 is a binary protocol.
Let's try to realize this for a moment. If you were familiar with Internet protocols before, then it is likely that you instinctively strongly oppose this fact and prepare arguments about how useful it is to have protocols that use the / ascii text, and that you wrote HTTP 1.1 requests with your hands hundreds of times. connecting with a telnet to the server.
http2 - binary to make the formation of packages easier. Determining the beginning and end of a packet is one of the most difficult tasks in HTTP 1.1 and in all text protocols in principle. By moving away from optional spaces and all sorts of ways to write the same things, we make implementation easier.
In addition, it makes it much easier to separate the parts associated with the protocol itself and the data packet, which is randomly intermixed in HTTP1.
The fact that the protocol allows the use of compression and often works on top of TLS also reduces the value of the text, since in any case you will no longer see plaintext in the wires. We just have to understand that you need to use Wireshark analyzer or something similar to find out what happens at the protocol level in http2.
Debugging of this protocol will most likely be performed by utilities such as curl, or by analyzing the network stream by the http2-dissector Wireshark or something like that.
Binary format
http2 sends frames. There are many different frames, but they all have the same structure:
The type, length, flags, flow identifier, and frame payload.
There are twelve different types of frames in the current http2 draft, including two, perhaps the most important, that are associated with HTTP 1.1: DATA (data) and HEADERS (headers). I will describe some of the frames in more detail later.
Multiplexing streams
The stream identifier mentioned in the previous section describing the frame format binds each frame transmitted over http2 to a so-called “stream”. A stream is a logical association. An independent two-way sequence of frames exchanged between the client and the server within the http2 connection.
A single http2 connection may contain multiple simultaneous open streams from either side exchanging frames of multiple streams. Streams can be installed and used unilaterally or shared by both the client and the server, and can be closed by either party. The order in which frames are sent is important. The recipient processes the frames in the order they are received.
Multiplexing streams means that packets of multiple streams are mixed within a single connection. Two (or more) separate data trains are collected into one train, and then divided on the other side. Here are two trains:
They come together one at a time in mixed mode:
In http2 we will see dozens and hundreds of simultaneous stream. The price of creating a thread is very low.
Priorities and dependencies
Each thread has a priority used to show the other exchange participant which threads to consider as more important.
The exact details of the work priorities in the protocol have changed several times and are still being discussed. The idea is that the client can specify which of the threads is the most important and there is a dependency parameter that allows you to make one thread dependent on another.
Priorities can be dynamically changed during the exchange, which allows the browser to be sure that when a user scrolls through a page filled with images, he can specify which images are most important, or when you switch tabs, he can increase the priority for threads that suddenly fall into focus.
Header compression
HTTP is a stateless protocol. In short, this means that each request must contain the maximum number of details that are required by the server to execute the request without having to save a lot of metadata from the previous request. Since http2 does not change any of these paradigms, it has to do the same.
This makes HTTP repetitive. When a client requests multiple resources from a single server, such as images on a web page, this turns into a large series of requests that look almost the same. For a series of something almost the same, compression is self-evident.
As I already mentioned, as the number of objects on the page increases, the use of cookies and the size of requests also continue to grow. Cookies should also be included in all requests that are almost always the same across multiple requests.
The size of an HTTP 1.1 request became so large over time that it sometimes became larger than the original TCP window size, which made it extremely slow in sending, requiring a full send-receive cycle to receive an ACK confirmation from the server before the full request is sent . Another argument for compression.
Compression is not an easy topic.
HTTPS and SPDY compression were found to be vulnerable to the BREACH and CRIME attacks . By inserting a known text into the stream and observing how the encrypted output changes, the attacker could figure out what was sent.
Compression for dynamic content in the protocol without the risk of being exposed to one of the known attacks, requires serious deliberation and attention. What the HTTPbis team is trying to do.
This is how HPACK appeared, HTTP / 2 Header Compression , which, as the name suggests, is a compression format designed specifically for http2 headers and, strictly speaking, this is a separate Internet draft draft specification. The new format is shared with other counter-measures, such as special flags, which ask intermediaries not to compress certain headers and optionally add extra empty data to the frames in order to complicate the attack on compression.
Data compression
Immediately before the release of draft 12, support for gzip compressed DATA frames was added. Each frame is compressed individually, so there is no common context between them, but this slightly reduces the level of compression. This feature corresponds to using gzip in Transfer-Encoding in HTTP 1.1. An opportunity that is seldom used, but often discussed, as a failure in the protocol, at least for browsers.
Reset (reset) - changed my mind
One of the drawbacks of HTTP 1.1 is that when an HTTP message is sent with a Content-Length header of a certain length, you cannot just stop it. Of course, you can often (but not always - I’ll skip here a long explanation of why this is so) break the TCP connection, but at the cost of re-negotiating a new TCP connection.
Now you can simply cancel the sending and start a new message. This can be achieved by sending an http2 frame RST_STREAM, which thus prevents bandwidth waste and the need to break the connection.
Server push (server sending)
This feature is also known as “cache”. The idea is that if a client requests a resource X, and the server assumes that the client will probably then ask for resource Z, it sends this resource to the client without a request from him. This helps the customer to put Z into his cache, and he will be there when needed.
Sending a server is something that the client must explicitly allow the server, and even if it does, it can of its choice quickly cancel the sent stream using RST_STREAM if it was not needed by it.
Alternative services
After http2 adaptation, there are reasons to expect that TCP connections will be longer and last longer in working condition than it was with HTTP 1.x connections. The client will be able to do a lot of things that he wants within one connection to each host / site and this connection will probably be open for a very long time.
This will affect the operation of the HTTP balancers, and there may be situations where the site wants to offer the client to connect to another host. This may be for both performance reasons, but also the need for outages for maintenance or similar purposes.
The server sends an Alt-Svc header (or ALTSVC frame to http2), informing the client about the availability of an alternative service. Additional route to the same content using a different service, host and port number.
It is expected that the client will try to asynchronously connect to the service and start using the alternative service if it works normally.
Opportunistic TLS
The Alt-Svc header allows a server that provides content on http: // to inform the client about the presence of the same content available over the TLS connection.
This is partly a controversial opportunity. This connection performs unauthenticated TLS and will not be marked “safe” anywhere: it will not show the lock in the program interface and does not inform the user that this is not the usual old open HTTP. But it will be an opportunistic TLS and some people are very confident in opposing this concept.
Flow control
Each individual stream in http2 has its own declared stream window, which the other side allowed to transfer data. If you imagine how SSH works, then this is very similar and done in the same spirit and style.
For each stream, both ends tell each other that they still have room to accept input data, and the opposite end is allowed to send only a specified amount of data until the window is expanded.
Lock
In the draft draft-12, after a long discussion, a frame was added, called BLOCKED. He can be sent once by the http2 member when he has data to send, but the control of the flow prohibits him from sending any data. The idea is that if your implementation receives such a frame, you must understand that your implementation has missed something and / or you cannot achieve high data transfer rates because of this.
Quote from draft-12:
The BLOCKED frame is included in this version of the draft for easy experimentation. If the result of the experiment does not give positive results, it will be deleted.
Http2 world
What will it look like when http2 is accepted? Will he be accepted?
How does http2 affect ordinary people?
http2 is not yet widely represented and used. We can not say exactly how everything goes. We have seen how SPDY was used and we can make some assumptions and calculations based on this and other past and current experiments.
http2 reduces the number of required network round-trips, completely avoids the turn-start blocking dilemmas at the expense of multiplexing and the rapid rejection of unwanted streams.
It allows you to work multiple parallel streams, the number of which can exceed the number of connections even in the most actively using modern sites sharding ...
With the priorities correctly used on the streams, the chances of obtaining important data earlier than the less important ones are much higher.
Putting it all together, I’ll say that the chances are very high that this will speed up page loading and increase the responsiveness of websites. In short: better feeling from the web surfing.
How much faster and how much better we will see. I do not think that we are ready to say so far. Firstly, the technology is still still young, and secondly, we have not yet seen neat implementations of clients and servers that truly use all the power that the new protocol provides.
How does http2 affect web development?
Over the years, web developers and web development environments have compiled a complete set of techniques and utilities to work around HTTP 1.1 issues, some of which are noted at the beginning of this document.
Most of these workarounds, which tools and developers now use without thinking about by default, are likely to hit http2 performance or at least not take advantage of all the benefits of the new http2 superpower. Sprites and embedding should not be used with http2. Sharding is likely to be bad for http2, since http2 benefits from using fewer connections.
The problem here is of course that web developers will have to develop and implement websites in a world where, at best, for a short period of time, there will be both HTTP 1.1 and http2 clients, and, for maximum performance by all users, It will be costly to offer two different versions of the site.
For this reason alone, I suspect it will take some time before we see the full potential of http2.
http2 implementation
Of course, trying to document specific implementations in documents like this is completely useless work, which is doomed to failure and will become obsolete in a very short period of time. Instead, I will explain the situation in a broad sense and direct the readers to the list of implementations on the http2 website.
Already there are a large number of implementations and their number is growing day by day as you work on http2. At the same time, at the time of writing, there are 19 implementations, and some of them implement the latest draft specification.
Firefox has always been at the forefront of the latest version of the draft, Twitter continues to provide services on http2. Google launched support for draft-10 on some of its services in April.
Support for curl and libcurl is made on the basis of a separate implementation of the http2 library, called nghttp2, which supports both plain http2 and on top of TLS. curl can use TLS for http2 using one of the TLS libraries: OpenSSL, NSS or GnuTLS.
Typical http2 criticism
In the process of developing a protocol, debates arose again and again, and, of course, there are a number of people who believe that the protocol turned out to be completely wrong. I would like to point out some of the most typical complaints and arguments against him:
“The protocol is designed and made by Google”
There are also variations implying that the world is even more dependent and controlled by Google. It is not true.The protocol was developed internally by the IETF in the same way that protocols were developed over the last 30 years. However, we are all grateful to Google for the unparalleled work on SPDY, which not only proved that it is possible to implement a new protocol in this way, but also helped get estimates of what we can get.
“The protocol is only useful for browsers and large services”
To some extent this is so. One of the main reasons behind http2 development is fixing HTTP pipelining. If in your case pipelining was not required, then http2 will not be particularly useful for you.
This is certainly not the only achievement of the protocol, but the most significant.
As soon as services begin to understand all the power and capabilities of multiplexed streams in one connection, I expect that we will see an increase in the number of applications using http2.
Small REST APIs and simple HTTP 1.x software applications will not benefit greatly from switching to http2. But, nevertheless, there will be very few drawbacks for most users.
“Using TLS makes it slow.”
To some extent this is true. TLS negotiation gives little overhead, but efforts are already underway to further reduce the number of request-responses for TLS. The cost of performing TLS encryption, compared to plaintext, is not as insignificant and clearly visible, so more processor and time and electricity will be spent on the same traffic as in an insecure protocol. How much and what consequences it will have - a topic for statements and measurements. See, for example, istlsfastyet.com as one of the sources on the topic.
http2 does not require the use of TLS, so we should not mix terms.
Most users on the Internet today want TLS to be more widely used, and we must help protect the privacy of users.
“Non-ASCII protocol spoils everything”
Yes, we like the idea of seeing the protocol openly, as this makes debugging easier. But text protocols are much more prone to errors and are prone to problems of proper parsing.
If you really cannot accept the binary protocol, then you will also not be able to accept both TLS and HTTP 1.x compression, which have been around for quite a long time.
Will http2 become widespread?
It's still quite early to say for sure, but I can guess and appreciate, and that's what I'm going to do here.
Skeptics will say “look at how well IPv6 was done,” as an example of a new protocol that took decades to simply at least begin to be widely used. http2 is not IPv6 at all. This is a TCP-based protocol, using the usual HTTP update mechanism, port number, TLS, etc. It will not require replacing most routers and brandmauers at all.
Google has proved to the world through its work on SPDY that such a new protocol can be implemented and used by browsers and services with several implementations in a fairly short period of time. Despite the fact that the number of servers on the Internet that today offer SPDY in the region of 1%, but the amount of data with which they work much more. Some of the most popular websites today offer SPDY.
http2, based on the same basic paradigms as SPDY, I’m sure it will probably be implemented even more actively, as this is the official IETF protocol. The implementation of SPDY has always been restrained by the stigma of “this is the Google protocol”.
Behind the release are several well-known browsers. At least, the representatives of Firefox, Chrome and Internet Explorer have expressed their readiness to release a browser with support for http2.
There are several server providers that are likely to offer http2 soon, including Google, Twitter and Facebook, and we expect to see http2 support in popular web server implementations such as Apache HTTP Server and nginx.
http2 in firefox
Firefox tracks the draft specification very tightly and has provided support for the test http2 implementation for many months now. During the development of the http2 protocol, clients and servers must agree on which version of the draft protocol they implemented, which makes the test run somewhat annoying, just be prepared for this.
Turn it on first
Enter "about: config" in the address bar and look for an option called "network.http.spdy.enabled.http2draft". Make sure it is set to true.
TLS only
Remember that Firefox only implements http2 over TLS. You will see http2 work in Firefox only when you go to https: // sites that support http2.
Transparent!
Any element anywhere in the interface will not say that you are working on http2. You can't understand it that easily. There is only one way to find out by turning on “Web Development-> Network”, check the response headers and see what you got from the server ... The response contains something about “HTTP / 2.0” and Firefox inserts its header with the name “X- Firefox-Spdy ”, as shown in this already outdated screenshot.
The headers that you see in network tools, when communicating over http2, are converted from http2 into similar to the old HTTP1.x headers.
http2 in curl
curl http2, 2013 .
curl, http2, . curl -, , http2.
HTTP 1.x
curl http2- HTTP 1.x , HTTP. curl HTTP . curl . curl HTTP 1.x , http2-. , HTTP .
curl http2 Upgrade. HTTP- HTTP 2, curl http2, .
TLS
curl TLS- TLS-, - http2. TLS http2 – APLN , , NPN.
curl OpenSSL NSS ALPN NPN. GnuTLS ALPN, NPN.
curl, http2, , TLS, --http2 (« http2»).
libcurl
https:// http:// URL', curl_easy_setopt CURLOPT_HTTP_VERSION CURL_HTTP_VERSION_2, libcurl http2. http2, , - HTTP 1.1.
http2
A large number of difficult decisions and compromises were made in http2. After deploying http2, there is a way to upgrade to other working versions of the protocol, which makes it possible to create more revisions of the protocol afterwards. It also brings a view and infrastructure that can support many different protocol versions at the same time. Perhaps we do not need to completely remove the old when we create a new one?
http2 still has a lot of outdated HTTP 1 transferred to it because of the desire to keep the ability to proxy traffic in all directions between HTTP 1 and http2. Some of this heritage makes it difficult to further develop and innovate. Maybe http3 will be able to drop some of them?
What do you think is still missing in http?
Further reading
If you think this document is a little simple in content or technical details, then additional resources are given that will satisfy your curiosity:
- HTTPbis mailing list and its archives: lists.w3.org/Archives/Public/ietf-http-wg
- The current specification of the http2 draft and related HTTPbis group documents is: datatracker.ietf.org/wg/httpbis
- Details of network solutions in http2 Firefox: wiki.mozilla.org/Networking/http2
- Details of the implementation of http2 in curl: curl.haxx.se/dev/readme-http2.html
- Website http2: http2.imtqy.com
Source: https://habr.com/ru/post/221427/
All Articles