Magic Tester. How an untrained person notices mistakes, and how to teach the same robot
Hello! My name is Ilya Katsev, and I represent a small research unit in the testing department at Yandex. You could already read about our experimental project Roboster - a robot that can make a significant part of the routine work as a tester.
Our main goal is to invent radically new approaches for finding errors in Yandex. I really like to speculate on how much of the work in the future will fall on the shoulders of robots. They write sports reports very well and carry loads for soldiers . And in general, it seems to me that human progress directly depends on the amount of work that we can transfer to robots - in this case, people have free time and they come up with new cool things.

There is a thesis, which I personally support, that any robot that the unprepared user can notice can be detected. That is what we tried to check. But then the question arises: what exactly does a person think is a mistake?
')
Nobody invented artificial intelligence yet (although Hawking, for example, thinks it is for the best), but we have managed to achieve some successes. In this post, I will talk about how we formulated the experience that testers-people have and tried to teach him our robots, and what came of it.
When we created Robotester, we were faced with the task of automating the routine work that takes the time of the tester. We taught the algorithm to open a web page, understand what actions can be performed with elements, fill in text fields, press buttons and try to guess when an error occurred. But we had a problem - it turned out that with high confidence the robot can detect only the most trivial errors.
The fact is that the principle of operation of the robot - to check as many pages as possible - led to a large number of tests, and this meant that the accuracy of determining the error was becoming a key factor. We calculated that our robot was doing 800,000 different checks per day to check Yandex.Market. Accordingly, if the false positive rate checks an average of 0.001 (which seems to be a small number), then every day there will be a report on the allegedly found 800 errors, which actually are not. Naturally, this does not suit anyone.
It should be noted that "fake" error messages always happen. Especially when it comes to web tests, as they use auxiliary tools - there may be problems with the browser that the robot uses, problems with the Internet, and so on.
There are very “clean” checks. For example, the response code of the link 404 with great probability indicates that there is a problem. An example of a test with low accuracy is the presence of the letter "," (space and comma) in the text. Indeed, when no data is loaded between the space and the comma, such a combination of letters indicates errors. But sometimes it's just a typo. Especially when the text of user comments or content from external sources is in the scan area. Therefore, to find these errors, it is necessary to carry out work manually, separating the “real” problems from the “fake” ones.
As a result, the robot really completely took over some of the work of the testers (for example, found all the broken links), but not at all. And we thought about how to "add robot intelligence."
Traditionally, in testing, the program under test is run with some given input data and compares the results with some kind of “correct” result also in advance. It can be set manually, or, say, saved when the previous version of the program is started (then we can find all the differences between this version and the previous one), but the general principle remains the same. In essence, the approach as a whole does not change here for decades, only the tools for the implementation of these tests change.
However, it turns out that fundamentally different approaches are possible to determine what is an error.
We initially said that the robot must learn to identify errors that anyone can, not necessarily a professional tester of this service.
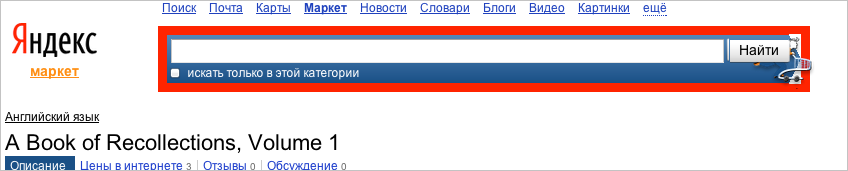
So where is the error on this page?

Of course, the correct answer - among the five sentences from the bottom there are recurring. To understand that this is a mistake, you do not need to be an expert in the Market - you just have a minimum of common sense.
Another example.
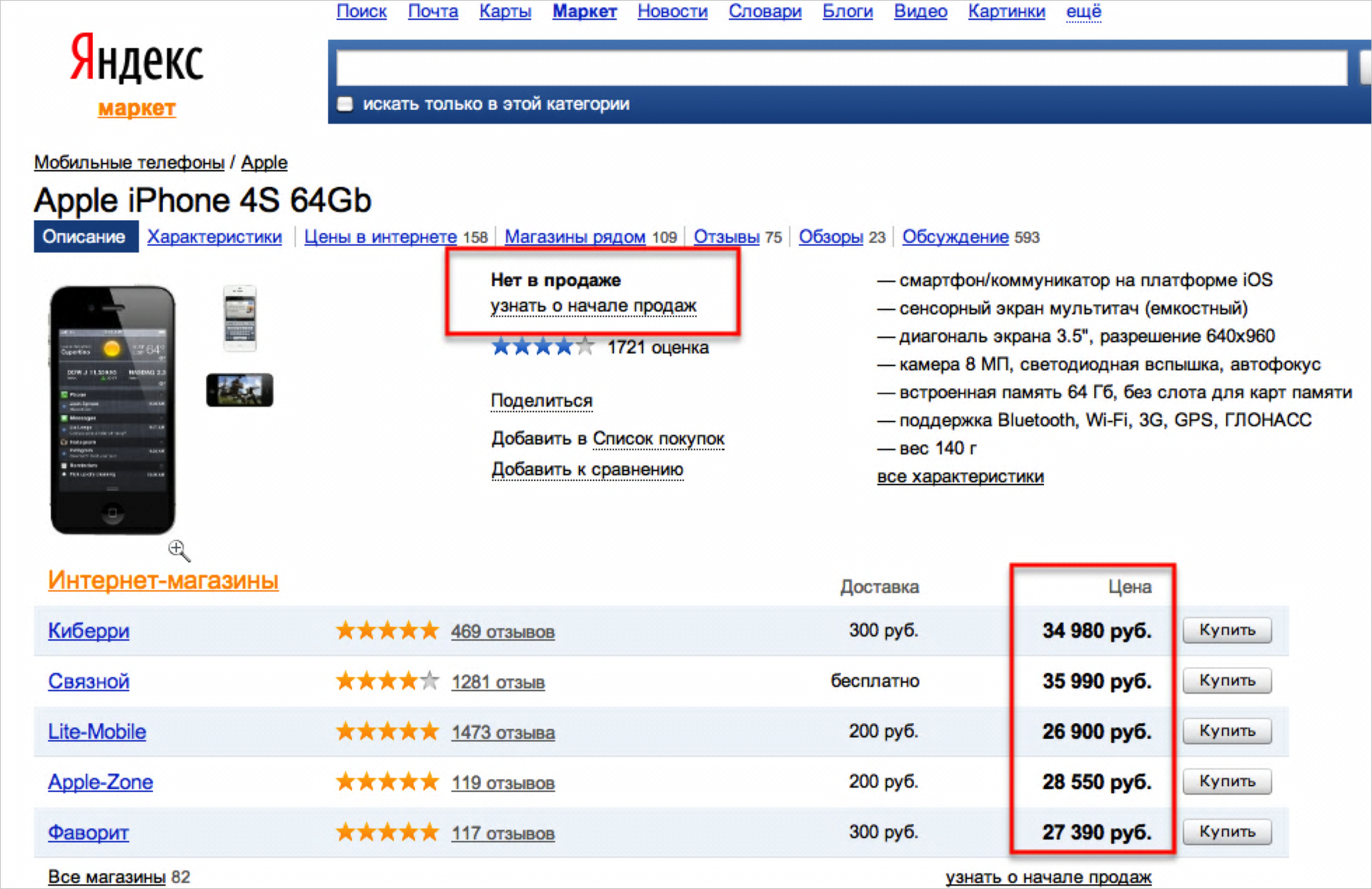
Here it says “not available” in one place, and prices in the other. Again, absolutely anyone understands that this is an incorrect situation.
One more example.
This is just a blank page. That is, it has a standard “cap” and “footer”, but there is no content in the middle.
This is where the key question arises - how does a person understand that this is a mistake? What mechanism is it based on?
We thought for a long time, and it seems that the key word here is experience. That is, a person has already seen many web pages in his life, some of which were of exactly the same type. And it was from them that he formed some kind of pattern. This template can be either very general (“the page should not be empty”, “all search results should be different”), or, conversely, linked to these pages (“two selected blocks contain or do not contain digits simultaneously”). That is, these rules have already been formed in his head and, as we can see from these examples, they look quite simple.
Thus, the further task here became clear - we need to learn how to automatically extract these rules by analyzing a lot of similar or not very similar web pages.
It can be seen that the formulated rules are quite simple, and if we learned how to automatically extract them, it would be possible to form autotests without human intervention. For example, a robot is given many pages of Yandex services for analysis, and he understands that there is a link “About the company” on all of them from below. Accordingly, this fact is formulated as a rule, and the robot will check its implementation for the new version of the service or even for another service.
The simplest application of this idea is this: we analyze all the pages of the service in production, isolate such “rules”, and then check whether they are executed for the new version of the same service.
This approach has long been known to all. It is called back-to-back testing and there are those who use it. However, this method is well applicable only when the work of the service should not significantly change from the version.
Let's look at the search results yesterday and today - the search results and advertising are changing nearby. Onii depend on the region of the user, his preferences, time of day, finally. Accordingly, with direct comparison there will be too much “garbage” (note that in some situations such a direct method is admissible).
Here we develop our idea and carry out a comparison, “cleared” from garbage - we compare not the pages themselves, but some “models” of the pages.
Having formulated a general idea, let's move on to how to implement it. Our task is to automatically retrieve the rules. For human understanding, they are very simple. We formulate them in the language of “blocks” - we are talking about whether a certain part of the page contains an element or not, whether there is a specific block on the page, and so on. For a person, the page is divided into them in a natural way - this is the authorization form, this is the search form (and in it the sub-blocks are the search string, the “find” button). However, the robot “sees” the html-code in front of it, and it is completely incomprehensible to him which part of this code forms a block.
We decided to articulate the concept of a block. That is, at first we decided to understand for ourselves what we, the people, call a block. Let's see what blocks are.
1. Permanent. The whole block is fully present on each page).
2. Changing. Some tag is present on every page, but inside it, everything changes every time.
3. Blocks of the same type on one page.
4. One-type, but essentially different blocks on one page.

At the same time on different pages the same block can stand in different places.



That is, for us, the “block” is a certain part of the page, which when it changes remains more or less constant. For example, a person easily understands that the forms from paragraph 2 (see above) are special cases of the “same orange form”, but the content of the form changes.
A separate problem is represented by several similar blocks going in a row. Sometimes these are just “several blocks of the same type”, and sometimes they are a set of objects of different types, and then you want to understand what type of objects are there.
First of all, we need some way to mark an already selected block on each page. Traditional xpath (for example,
Therefore, we first remove the numbers from the xpath (by getting
Now let's look for the blocks. If we represent the html-code as a tree , then our task is to search for stable paths from the root vertex (stability here means that the path changes little when the page is changed). The algorithm for constructing a set of such stable paths is the main part of our tool. We built it "by trial and error." That is, we modified the algorithm and looked at the result. I will describe the algorithm below, but for now I'll tell you about a completely unexpected problem - we suddenly realized that we did not know how to portray which blocks stood out on the page.
Indeed - the block looks different on different pages. We wanted to get a report in the form of something that looks like a page divided into blocks. But which of the block options to take? Over and over again, we came across instances when an empty or uninformative version came into our report. It was necessary to somehow compactly show all the options on the same page. One of the developers came up with a good idea - to do something like, for example, madeon porn sites in the Coub service: when you hover the mouse on the video, there are shots from there. We did exactly the same thing - if you hover your mouse over a block, this block starts to “blink”, showing how it looks on different pages. It turned out to be very convenient.
As a result, the “page model” looks like this (see below). You can look at it and immediately understand which blocks stand out.
Now about the algorithm. The basic algorithm is as follows:
The great advantage of the algorithm is that it depends linearly on both the number of elements of the first page and the number of pages.
However, as we soon learned, there are places where the algorithm works poorly. For example, for these blocks (isbn, author, and so on):

As html-elements they are exactly the same, they differ only in the sequence number. But it is immediately clear that this number does not mean anything - in the example above ISBN, then the second, then the first. Therefore, it became clear to us that the only way to distinguish such elements is by the text inside. Therefore, we changed the algorithm as follows: at the very beginning we are looking for places where the element has several descendants that differ only in text. Then we collect similar elements of descendants from all pages, and then we cluster them in the text so that each page contains no more than one representative of each cluster.
There were other improvements to the algorithm, but they may not be so interesting to you, since they are associated with Yandex specificity. Even the algorithm described now will work quite well on most page sets.
So, after analyzing the structure of the pages from the training sample, selecting the blocks and understanding which blocks on how many pages are present, we can formulate the rules of the following types:
In principle, it is possible to extract more complex laws, but we have not done it yet.
For which blocks do we form a condition of the first type? For those that are found on a fairly large proportion of pages. This proportion is determined by a special parameter, which we call the confidence level. It is wrong to set this parameter equal to one - the way we wanted to do initially, for two reasons:
We vary this level of significance depending on the stability of the environment in which we train our instrument. By reducing the value of the parameter, you can "remove" the effect of environmental instability. However, if this parameter is greatly reduced, the tool will begin to highlight additional irregular patterns. For example, if 96% of goods have a price, and 4% says “not available,” when setting a parameter to 0.95, pages with “not available” will be marked as erroneous. By default, confidence level is 0.997.
In addition to the conditions for the presence / absence of blocks, we automatically generate conditions for the text inside each block. Conditions are formed in the form of regular expressions. For example, on the block with the year of publication on this page
will be the following regular season:
Year of publication: [0-9] {4}
Or even this:
Year of publication: (19 | 20) [0-9] {2}
At the same time, this block itself is marked as optional. That is, the following is checked - that if there is such a block, then after the words “year of publication” 4 numbers are written in it, or even 4 numbers are written, the first two of which are 19 or 20. A man would write about such a test.
To summarize, our tool is able to do the following: for a set of pages, we extract rules of a certain type, which are executed for a given percentage of these pages. How to find bugs with this? There are two ways.
In fact, in the second case, we get the same thing as in the presence of regression autotests. However, in our case there is a big, even a huge advantage, - the code of these tests should not be written and maintained! As soon as they posted a new version of the service, I press the “rebuild all” button and in a few minutes a new version of “autotests” is ready.
As an implementation experiment, we used this approach when launching the Turkish version of Market . Testing experts wrote a list of required cases and what checks to do on which pages. We crawler selected many pages of the service and divided them into groups - search results pages, category pages and so on. Further, for each group of pages, the rules described above were automatically constructed and manually checked which of the indicated checks were actually carried out. It turned out that about 90% of the checks were generated automatically. In this case, the expected effort to write autotests were about three weeks, and our tool was able to do everything and set it up in one day.
Of course, this does not mean that now any tests can be formed many times faster. For example, our tool is still able to automatically create only static tests (without dynamic operations with page elements).
Now we are busy implementing MT on various Yandex services in order to get an exact answer to the question of what part of human work this tool does. But it is already obvious that quite considerable.
As I said, the projects Roboster and Magic Tester are experimental and are being done in the research department of the testing department. If you are an undergraduate and you are interested in trying yourself in our tasks, come to us for an internship.
Our main goal is to invent radically new approaches for finding errors in Yandex. I really like to speculate on how much of the work in the future will fall on the shoulders of robots. They write sports reports very well and carry loads for soldiers . And in general, it seems to me that human progress directly depends on the amount of work that we can transfer to robots - in this case, people have free time and they come up with new cool things.
There is a thesis, which I personally support, that any robot that the unprepared user can notice can be detected. That is what we tried to check. But then the question arises: what exactly does a person think is a mistake?
')
Nobody invented artificial intelligence yet (although Hawking, for example, thinks it is for the best), but we have managed to achieve some successes. In this post, I will talk about how we formulated the experience that testers-people have and tried to teach him our robots, and what came of it.
Robotster. First approach
When we created Robotester, we were faced with the task of automating the routine work that takes the time of the tester. We taught the algorithm to open a web page, understand what actions can be performed with elements, fill in text fields, press buttons and try to guess when an error occurred. But we had a problem - it turned out that with high confidence the robot can detect only the most trivial errors.
The fact is that the principle of operation of the robot - to check as many pages as possible - led to a large number of tests, and this meant that the accuracy of determining the error was becoming a key factor. We calculated that our robot was doing 800,000 different checks per day to check Yandex.Market. Accordingly, if the false positive rate checks an average of 0.001 (which seems to be a small number), then every day there will be a report on the allegedly found 800 errors, which actually are not. Naturally, this does not suit anyone.
It should be noted that "fake" error messages always happen. Especially when it comes to web tests, as they use auxiliary tools - there may be problems with the browser that the robot uses, problems with the Internet, and so on.
There are very “clean” checks. For example, the response code of the link 404 with great probability indicates that there is a problem. An example of a test with low accuracy is the presence of the letter "," (space and comma) in the text. Indeed, when no data is loaded between the space and the comma, such a combination of letters indicates errors. But sometimes it's just a typo. Especially when the text of user comments or content from external sources is in the scan area. Therefore, to find these errors, it is necessary to carry out work manually, separating the “real” problems from the “fake” ones.
As a result, the robot really completely took over some of the work of the testers (for example, found all the broken links), but not at all. And we thought about how to "add robot intelligence."
How does the robot guess about the error?
Traditionally, in testing, the program under test is run with some given input data and compares the results with some kind of “correct” result also in advance. It can be set manually, or, say, saved when the previous version of the program is started (then we can find all the differences between this version and the previous one), but the general principle remains the same. In essence, the approach as a whole does not change here for decades, only the tools for the implementation of these tests change.
However, it turns out that fundamentally different approaches are possible to determine what is an error.
We initially said that the robot must learn to identify errors that anyone can, not necessarily a professional tester of this service.
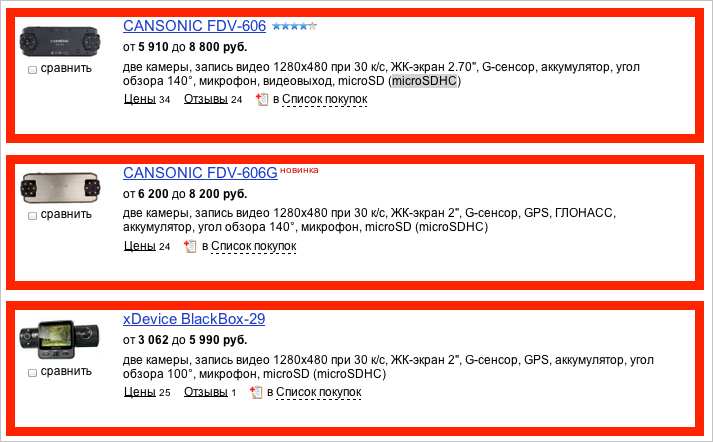
So where is the error on this page?
Of course, the correct answer - among the five sentences from the bottom there are recurring. To understand that this is a mistake, you do not need to be an expert in the Market - you just have a minimum of common sense.
Another example.
Here it says “not available” in one place, and prices in the other. Again, absolutely anyone understands that this is an incorrect situation.
One more example.
This is just a blank page. That is, it has a standard “cap” and “footer”, but there is no content in the middle.
This is where the key question arises - how does a person understand that this is a mistake? What mechanism is it based on?
We thought for a long time, and it seems that the key word here is experience. That is, a person has already seen many web pages in his life, some of which were of exactly the same type. And it was from them that he formed some kind of pattern. This template can be either very general (“the page should not be empty”, “all search results should be different”), or, conversely, linked to these pages (“two selected blocks contain or do not contain digits simultaneously”). That is, these rules have already been formed in his head and, as we can see from these examples, they look quite simple.
Thus, the further task here became clear - we need to learn how to automatically extract these rules by analyzing a lot of similar or not very similar web pages.
It can be seen that the formulated rules are quite simple, and if we learned how to automatically extract them, it would be possible to form autotests without human intervention. For example, a robot is given many pages of Yandex services for analysis, and he understands that there is a link “About the company” on all of them from below. Accordingly, this fact is formulated as a rule, and the robot will check its implementation for the new version of the service or even for another service.
The simplest application of this idea is this: we analyze all the pages of the service in production, isolate such “rules”, and then check whether they are executed for the new version of the same service.
This approach has long been known to all. It is called back-to-back testing and there are those who use it. However, this method is well applicable only when the work of the service should not significantly change from the version.
Let's look at the search results yesterday and today - the search results and advertising are changing nearby. Onii depend on the region of the user, his preferences, time of day, finally. Accordingly, with direct comparison there will be too much “garbage” (note that in some situations such a direct method is admissible).
Here we develop our idea and carry out a comparison, “cleared” from garbage - we compare not the pages themselves, but some “models” of the pages.
Blocks
Having formulated a general idea, let's move on to how to implement it. Our task is to automatically retrieve the rules. For human understanding, they are very simple. We formulate them in the language of “blocks” - we are talking about whether a certain part of the page contains an element or not, whether there is a specific block on the page, and so on. For a person, the page is divided into them in a natural way - this is the authorization form, this is the search form (and in it the sub-blocks are the search string, the “find” button). However, the robot “sees” the html-code in front of it, and it is completely incomprehensible to him which part of this code forms a block.
We decided to articulate the concept of a block. That is, at first we decided to understand for ourselves what we, the people, call a block. Let's see what blocks are.
1. Permanent. The whole block is fully present on each page).
2. Changing. Some tag is present on every page, but inside it, everything changes every time.
3. Blocks of the same type on one page.
4. One-type, but essentially different blocks on one page.
At the same time on different pages the same block can stand in different places.
That is, for us, the “block” is a certain part of the page, which when it changes remains more or less constant. For example, a person easily understands that the forms from paragraph 2 (see above) are special cases of the “same orange form”, but the content of the form changes.
A separate problem is represented by several similar blocks going in a row. Sometimes these are just “several blocks of the same type”, and sometimes they are a set of objects of different types, and then you want to understand what type of objects are there.
First of all, we need some way to mark an already selected block on each page. Traditional xpath (for example,
/html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a ) is bad because the numbers in it can change - the same block can be the third or fifth in a row. Depending on what other blocks there are (see the last two examples).Therefore, we first remove the numbers from the xpath (by getting
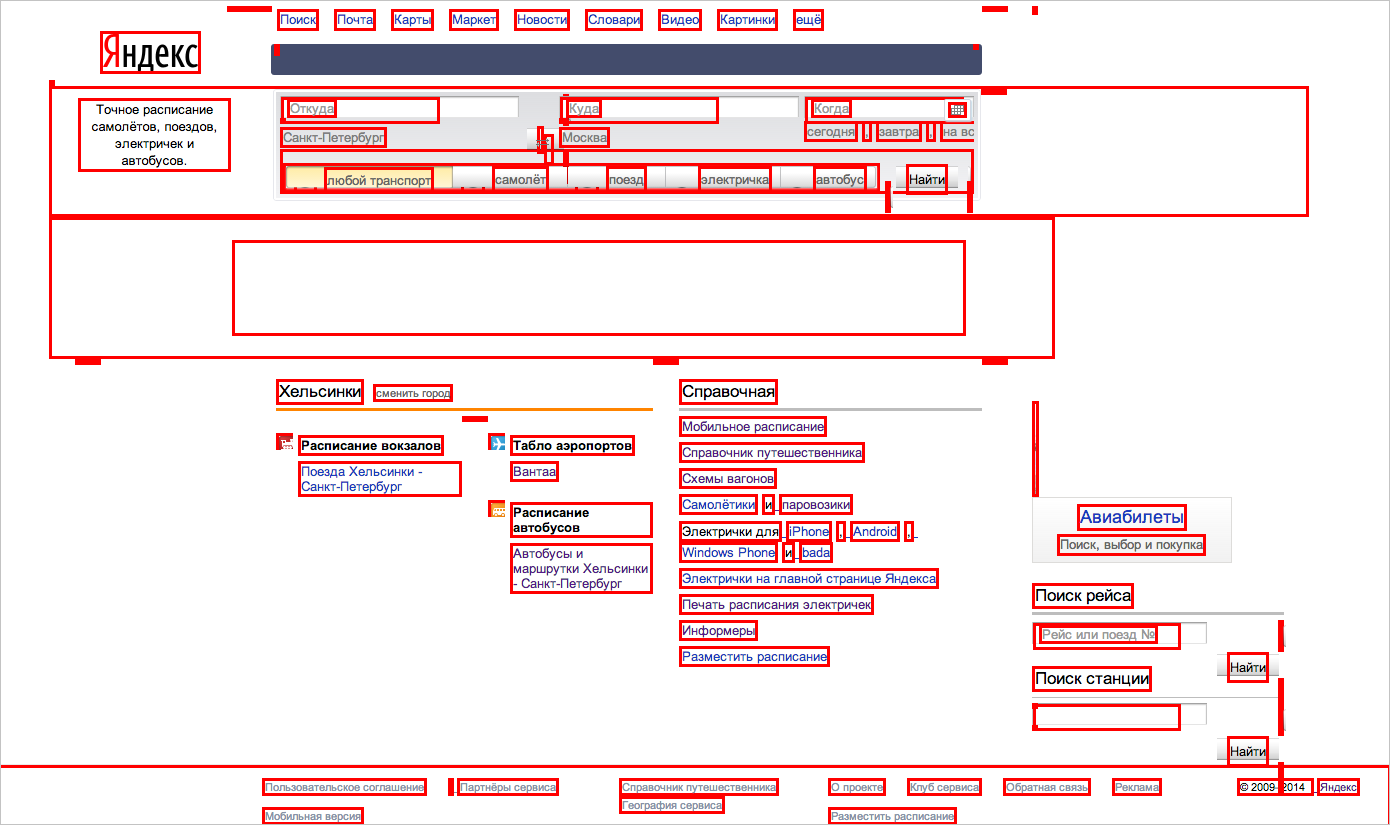
/html/body/div/table/tbody/tr/td/div/ul/li/span/a instead of /html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a ) and we get a much more stable match option (that is, this block will fall under xpath on any page), but less accurate - that is, the same xpath now, of course, can correspond to several elements. To reduce this inaccuracy, we add the values of some of its attributes to the description of each tag. We simply divided the attributes into more or less stable ones. For example, the id attribute is often re-generated when the page is loaded, that is, it is completely uninformative for us. For example, for the block discussed above, the following description was obtained: another ipath <body> <div class="b-max-width"> <table class="l-head"> <tbody> <tr> <td class="l-headc"> <div class="b-head-search" onclick="return {name:'b-head-search'}"> <div class="b-head-searchwrap b-head-searcharrow"> <form class="b-search"> <table class="b-searchtable"> <tbody> <tr> <td class="b-searchinput"> <span class="b-form-input b-form-input_is-bem_yes b-form-input_size_16 i-bem" onclick="return {'b-form-input':{name:'b-form-input'}}"> <span class="b-form-inputbox"> <text src=" Turion II"> Now let's look for the blocks. If we represent the html-code as a tree , then our task is to search for stable paths from the root vertex (stability here means that the path changes little when the page is changed). The algorithm for constructing a set of such stable paths is the main part of our tool. We built it "by trial and error." That is, we modified the algorithm and looked at the result. I will describe the algorithm below, but for now I'll tell you about a completely unexpected problem - we suddenly realized that we did not know how to portray which blocks stood out on the page.
Indeed - the block looks different on different pages. We wanted to get a report in the form of something that looks like a page divided into blocks. But which of the block options to take? Over and over again, we came across instances when an empty or uninformative version came into our report. It was necessary to somehow compactly show all the options on the same page. One of the developers came up with a good idea - to do something like, for example, made
As a result, the “page model” looks like this (see below). You can look at it and immediately understand which blocks stand out.

Block Algorithm
Now about the algorithm. The basic algorithm is as follows:
- Choose one page from the set.
- From the first page we collect all the maximal paths from the root vertex to the others.
- Then for each selected path we try to lay it on all pages.
If you manage to lay a part of the path that is different in length by at least 4, add this part to the set of paths.
If it almost turned out to pave the entire path (did not reach 1-3 tags), then we replace the path in the set with this chopped off variant. - As a result, the resulting paths and correspond to the blocks. Then it is easy to choose from them those that are on all pages, or, say, 95% of the pages.
The great advantage of the algorithm is that it depends linearly on both the number of elements of the first page and the number of pages.
However, as we soon learned, there are places where the algorithm works poorly. For example, for these blocks (isbn, author, and so on):
As html-elements they are exactly the same, they differ only in the sequence number. But it is immediately clear that this number does not mean anything - in the example above ISBN, then the second, then the first. Therefore, it became clear to us that the only way to distinguish such elements is by the text inside. Therefore, we changed the algorithm as follows: at the very beginning we are looking for places where the element has several descendants that differ only in text. Then we collect similar elements of descendants from all pages, and then we cluster them in the text so that each page contains no more than one representative of each cluster.
There were other improvements to the algorithm, but they may not be so interesting to you, since they are associated with Yandex specificity. Even the algorithm described now will work quite well on most page sets.
Rule generation
So, after analyzing the structure of the pages from the training sample, selecting the blocks and understanding which blocks on how many pages are present, we can formulate the rules of the following types:
- Block A must be present on the page.
- Blocks A and B must be present at the same time.
- Blocks A and B cannot be present at the same time.
In principle, it is possible to extract more complex laws, but we have not done it yet.
For which blocks do we form a condition of the first type? For those that are found on a fairly large proportion of pages. This proportion is determined by a special parameter, which we call the confidence level. It is wrong to set this parameter equal to one - the way we wanted to do initially, for two reasons:
- One of the 100 pages of the training sample may not open (by timeout, for example), and as a result, no conditions on the mandatory presence of the block will not stand out.
- Among the pages of the training sample, pages with errors can happen by chance.
We vary this level of significance depending on the stability of the environment in which we train our instrument. By reducing the value of the parameter, you can "remove" the effect of environmental instability. However, if this parameter is greatly reduced, the tool will begin to highlight additional irregular patterns. For example, if 96% of goods have a price, and 4% says “not available,” when setting a parameter to 0.95, pages with “not available” will be marked as erroneous. By default, confidence level is 0.997.
In addition to the conditions for the presence / absence of blocks, we automatically generate conditions for the text inside each block. Conditions are formed in the form of regular expressions. For example, on the block with the year of publication on this page
will be the following regular season:
Year of publication: [0-9] {4}
Or even this:
Year of publication: (19 | 20) [0-9] {2}
At the same time, this block itself is marked as optional. That is, the following is checked - that if there is such a block, then after the words “year of publication” 4 numbers are written in it, or even 4 numbers are written, the first two of which are 19 or 20. A man would write about such a test.
Magic in practice
To summarize, our tool is able to do the following: for a set of pages, we extract rules of a certain type, which are executed for a given percentage of these pages. How to find bugs with this? There are two ways.
- Considering that behavior that occurs infrequently is an error. This is a controversial thesis, but many times it was possible to find functional bugs in this way. Then it is enough to analyze a large number of pages on the service and mark those that are not like the others. In any case, this path will not work if, relatively speaking, “everything is broken.” Therefore, we usually use a different approach.
- Collect pages from the N version of the service (usually just from production), build rules based on them. Then take a lot of pages from the N + 1 version of the service (usually it's just testing) and check on them the implementation of these rules. It turns out a clear list of all the differences between the N and N + 1 versions.
In fact, in the second case, we get the same thing as in the presence of regression autotests. However, in our case there is a big, even a huge advantage, - the code of these tests should not be written and maintained! As soon as they posted a new version of the service, I press the “rebuild all” button and in a few minutes a new version of “autotests” is ready.
As an implementation experiment, we used this approach when launching the Turkish version of Market . Testing experts wrote a list of required cases and what checks to do on which pages. We crawler selected many pages of the service and divided them into groups - search results pages, category pages and so on. Further, for each group of pages, the rules described above were automatically constructed and manually checked which of the indicated checks were actually carried out. It turned out that about 90% of the checks were generated automatically. In this case, the expected effort to write autotests were about three weeks, and our tool was able to do everything and set it up in one day.
Of course, this does not mean that now any tests can be formed many times faster. For example, our tool is still able to automatically create only static tests (without dynamic operations with page elements).
Now we are busy implementing MT on various Yandex services in order to get an exact answer to the question of what part of human work this tool does. But it is already obvious that quite considerable.
As I said, the projects Roboster and Magic Tester are experimental and are being done in the research department of the testing department. If you are an undergraduate and you are interested in trying yourself in our tasks, come to us for an internship.
Source: https://habr.com/ru/post/221379/
All Articles