Genetic algorithms in faces
 Genetic algorithms were invented in the 1950s as the result of the first computer simulation experiments on natural evolution. Since then, they have been used to solve a wide variety of optimization problems where gradient methods for some reason are not suitable. The biological component of genetic algorithms has a very simplified form here and in this case it is more about following the general idea of evolutionary selection than its full-fledged simulation. However, sometimes the results of the work of the GA can be interpreted in a biological sense. In our article, we talk about the experience of applying genetic algorithms for the problem of face recognition in order to obtain "regions of importance" of a person. The use of this approach allowed an average increase in the recognition accuracy of our face recognition system by 20%.
Genetic algorithms were invented in the 1950s as the result of the first computer simulation experiments on natural evolution. Since then, they have been used to solve a wide variety of optimization problems where gradient methods for some reason are not suitable. The biological component of genetic algorithms has a very simplified form here and in this case it is more about following the general idea of evolutionary selection than its full-fledged simulation. However, sometimes the results of the work of the GA can be interpreted in a biological sense. In our article, we talk about the experience of applying genetic algorithms for the problem of face recognition in order to obtain "regions of importance" of a person. The use of this approach allowed an average increase in the recognition accuracy of our face recognition system by 20%. Existing approaches for face recognition
Historically, after about 20 years of intensive research in the field of computer facial recognition, in the early 2000s two basic groups of methods for comparing individuals were distinguished: “holistic approaches”, “holistic approaches” (or “global approaches”) and “featured approaches” "," Feature-based approaches "(or" structural approaches ") [1]. In the first case, the faces are treated as whole images that are compared with each other. In the second case, local features are distinguished from the face image, such as information about the absolute and relative position of the eyes, nose, mouth, etc. Both groups have their drawbacks: holistic approaches have shown, in general, greater reliability in close to ideal recognition conditions as compared to indicative approaches, however, featured approaches have better recommended in a situation when certain parts of the face are not visible for some reason (for example, they are closed by elements of clothing or points). The application of SIFT-like methods for extracting attributes in their pure form to the face recognition problem gives unsatisfactory results, since there are usually too few “angles” on a person’s face for which key points are defined. The algorithms of the “dense-SIFT” type with the calculation of signs for a given lattice of key points, although they demonstrate good recognition quality [2], are not always convenient for practical use due to the large size of the vectors of signs and the long time required for their calculation. Under these conditions, in recent years, a group of methods has gained popularity, which can be conventionally called “modular approaches” [4–9], including the method of local binary patterns .
Cluster approaches for comparing individuals
The essence of cluster approaches for comparing individuals is to divide the face image into a number of areas, to each of which you can apply a holistic approach and compare them in pairs, i.e. regardless of other sites. In this case, it can be hoped that if some pairs of plots of the compared images do not coincide with each other due to the aforementioned interfering factors such as shadows and overlaps, the remaining pairs of plots will provide the necessary degree of mutual correlation, which will be enough for a correct final solution of the individuals .
The method of principal components [4], moment invariants [5], local binary patterns (LBT) [6, 7], Gabor wavelets [8], Haar wavelets [9] and other methods can be used as a holistic approach. In our project we use the combined approach of the LBP [7] and the moments of the pseudo-Zernike [5].
')
Matrix of importance scales
In our face recognition system embedded in the ZZPhoto application, we consider the unequal importance of different face areas for comparing faces by dividing the face image into
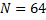 plot (Fig. 1) and assigning each of them their own weights
plot (Fig. 1) and assigning each of them their own weights 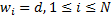 , weights take one of four discrete values,
, weights take one of four discrete values, 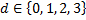 .
.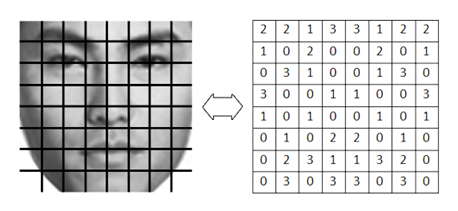
Figure 1. a) Separation of the face into 8x8 = 64 non-overlapping square sections. b) Values of the weights matrix of the importance of the face areas.
The greater the weight value, the greater the influence / mismatch of the corresponding area of the face on the final decision of the comparison algorithm. In fig. 6 more important areas of the face are highlighted in more red.
The use of complete enumeration to determine the optimal weight weights matrix is difficult in practice, since we would have to consider
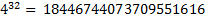 variants of the matrix of weights (here there is a degree of 32, not 64, since the matrix of weights that are symmetrically horizontal are used because of, in general, the symmetrical nature of the human face). Therefore, to search for a better matrix, it is necessary to use a more intelligent search algorithm. As a result, we stopped on genetic algorithms (GA).
variants of the matrix of weights (here there is a degree of 32, not 64, since the matrix of weights that are symmetrically horizontal are used because of, in general, the symmetrical nature of the human face). Therefore, to search for a better matrix, it is necessary to use a more intelligent search algorithm. As a result, we stopped on genetic algorithms (GA).Genetic algorithms
Genetic algorithms have proven themselves well as a means of global optimization when gradient optimization methods cannot be applied. Their advantages are: no differentiable model of the object to be optimized is required, as well as a lower risk of falling into a local minimum. Their disadvantage is a significantly lower convergence rate compared to gradient methods. The essence of genetic algorithms is to simulate the process of natural selection as a means of finding the optimal solution, using the mechanism for transmitting hereditary information from generation to generation through genes. As a measure of the success of the "life" of the organism, the objective optimization function is used, which in terms of the GA is called the "fitness function". Before describing the work of the GA algorithm for our case, we list the concepts with which we operate and briefly explain their meaning.
Fitness function - determines the quality of "life" of an individual in a generation (population). In our case, the role of the fitness function is performed by a program experiment on face recognition using our face comparison algorithm on a given database of face images. The result of the fitness function is the percentage of correctly recognized persons for a particular chromosome.
Chromosome - defines the individual in the population, in fact, this is our matrix of weights of the importance of the areas of the face. Each chromosome is a candidate for solving the target problem.
Fitness is the quality of life of an individual encoded by the chromosome. It is the result of applying a fitness function to the chromosome. In our case, this is the classification accuracy with a given weights matrix of the importance of face areas.
A population is a set of 100 different chromosomes, the genes are encoded by values from the allowable set {0,1,2,3}. Values can be either completely random (the first population) or be the product of an evolutionary process (crossing and mutations).
Crossing (reproduction) - the procedure for obtaining a new chromosome. A new “child” chromosome is formed from parts of the “parent” chromosomes. The crossing point is selected using a random number generator each time for each pair of parents. The choice of parents is performed by the selection procedure.
Breeding is a procedure for selecting “parent” chromosomes from which chromosomes will be formed for a new population. Breeding is designed to increase the likelihood of hitting the set of “parents” of chromosomes that showed the best fitness in the last currently populated population. We use the stochastic approach, the probability
 Choosing the i-th chromosome:
Choosing the i-th chromosome:
Where:
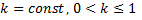 .
.Mutation - the procedure of replacing a single chromosome value with a random value after crossing, the probability of a mutation is set in advance.
Elitism is a feature of the formation of a new generation, the essence of which lies in the fact that the best parents are directly included in the new generation. Their number can be from 1 and more.
Description of the experiment
- An initial population of 100 chromosomes is generated, the values of which are filled with random values.
- A fitness function is applied to each chromosome of the population, which determines the value of fitness for chromosomes.
- With the help of selection, the most adapted chromosomes are selected, which form a multitude of “parents”.
- Random pairs are selected from a variety of parents, crossing is performed, and chromosomes of "children" are formed.
- The mutation procedure is applied to the chromosomes of "children".
- The resulting chromosomes form a new population, to which steps 2) - 5) are performed.
- If the improvement does not occur for a long time (say, 30 populations or more), then stop. Chromosome, which showed the best fitness, is the solution to the problem.
Experiments
The following biological interpretation can be given for our experiments: biological individuals who pay attention to the “wrong” parts of the face are dying out; the same individuals who have a good recognition ability survive and produce more numerous offspring.
The first experiment was carried out on the well-known Color FERET face image database [11]. From this database, images of the faces of 100 people, photographed during several sessions, 5 examples of persons per person were selected. Examples of images from the Color FERET Face Database are shown in Figure. 2. This database contains images of faces taken from several photo sessions in different lighting conditions and with different facial expressions. The selection of the actual sites of persons was carried out automatically by the module for the selection of persons based on the Viola-Jones face detector, which is part of OpenCV. It additionally includes the normalization of the image in size, position and angle of rotation in the frontal plane (for which the face, eye, nose and mouth are additionally searched for).

Fig. 2. Examples of faces from the Color FERET Face Database.
The essence of the experiment consists in the classification of persons in the “Single face Per Person” mode. The recognition algorithm receives as input one photo of each person’s face from the database, after which it compares the selected person with all its other and other people's faces in the database and builds dependencies of authentication errors of the 1st and 2nd kind on the authentication threshold, i.e. . False Accept Rate (FAR) dependency curves, and False Reject Rate (FRR). The FAR error corresponds to the “false access” situation, when the system falsely “recognizes someone else as its own”; The FRR error is “goal skipping” when the system falsely “does not recognize its own.” According to the conditions of the applied problem that we are solving, the value of the FRR was fixed and should not exceed 20%. According to the results of experiments, a total recognition error is formed on all faces, in the role of which the error HTER (Half Total Error Rate) is used, i.e. access error equal to the average of FAR and FRR.
For the Color FERET Face Database, the FAR recognition error with unit weights was 21% (ie, 79% of correct answers), which is close to the current state-of-the-art level of face recognition methods. After applying genetic algorithms to optimize the weights matrix of the importance of the face areas (Fig. 3), the FAR recognition error was reduced to 12%, i.e. reduce by almost 2 times compared to the original.
Fig. 3. The result of applying genetic algorithms to optimize the matrix of weights of the importance of areas of the face based on Color FERET.
To organize an experiment with different races, as well as, more close to real conditions, we collected our own database of ZZWolf ABC Face Database, which includes faces of people of different races (ABC = Asian, Black, Caucasian). The base of persons contains samples of persons for three main races, 10 persons for 10 persons (5 men and 5 women) of each race, photos of persons were collected on the Internet, only 300 persons. These are mainly the faces of famous people (actors and politicians), the pictures were taken by various photo cameras, at different times (the difference in the filming can be years) and in different lighting conditions.

Fig. 4. Examples of persons from the ZZWolf ABC Face Database. Allocation, normalization and preprocessing of individuals was carried out automatically.
As a result, the face recognition error on the new base averaged 37.2%. After applying the genetic algorithms, it was possible to reduce the error to 32%.
Fig. 5. The result of applying genetic algorithms to optimize the weights matrix of the importance of facial areas based on the ZZWolf ABC Face Database for different races.
Table 1. Recognition results based on ZZWolf ABC Faces
| For Asians | For blacks | For whites | The average | |
| Unit weight weights (all parts of the face are equal) | 38.0% | 35.3% | 38.3% | 37.2% |
| Weights of importance optimized by genetic algorithms | 34.3% | 29.0% | 32.8% | 32.0% |
The final optimized matrices of importance of the areas of the faces are shown in Fig. 6, they differ for different races. Our sample of faces “ZZWolf ABC Face Database” is small in size, so we do not pretend that the experimentally obtained matrices of importance of areas of people for different races are optimal under any conditions and fully correspond to biological systems of face recognition in real people.
Fig. 6. Matrix of importance of sites of persons for various races. The more red, the more important it is.
Nevertheless, if we accept the hypothesis that people of different races, when recognizing each other's faces, pay more attention to areas of the face that are characteristic of their race and because of this, it is difficult for representatives of different races (for example, Europeans and Asians) to recognize each other , the results can be interpreted as follows: for whites, the most important is the eye area, for blacks the nose area, and for Asians the ear area and the forehead above the standard arches.
findings
The article presents a method for improving the accuracy of the face recognition algorithm, which is used in the ZZPhoto program based on the use of genetic algorithms. Experiments on various bases of individuals show an improvement in the quality of recognition from 20% to 2 times. The method is quite general and can be applied to various cluster face recognition algorithms. The results of experiments on a sample of individuals from different races give interesting results, possibly explaining some natural mechanisms for recognizing faces in humans.
Bibliography
- W. Zhao, R. Chellappa, PJ Phillips, A. Rosenfeld. Face recognition: A literature survey, ACM Computing Surveys (CSUR), 2003, Volume 35, Issue 4, pp. 399 - 458.
- P. Dreuw, P. Steingrube, H. Hanselmann, H. Ney. SURF-Face: Face Recognition Under Viewpoint Consistency Constraints // Proceedings British Machine Vision Conference, 2009.
- R. Gottumukkal, VK Asari. An Approach for a Modified PCA Approach // Pattern Recognition Letters, 2004, Volume 25, Issue 4, pp. 429 - 436.
- HV Nguyen, L. Bai, L. Shen. Biblical Pattern: Personality: A Novel Approach for Person Recognition of Individual Persons // Advances in Biometrics. Lecture Notes in Computer Science Volume 5558, 2009, pp. 269-278.
- HR Kanana, K. Faez, Y. Gaob. Face recognition using an adaptively weighted PZM array pattern for a person // Pattern Recognition, 2008, Volume 41, Issue 12, pp. 3799-3812.
- S. Nikan, M. Ahmadi. Human face recognition under occlusion using LBP and entropy weighted voting // 2012 21st International Conference on Pattern Recognition (ICPR), 11-15 Nov. 2012, pp. 1699 - 1702.
- T. Ahonen, A. Hadid, M. Pietikainen. Face Description with Local Binary Patterns: Application to Face Recognition // Pattern Analysis and Machine, 2006, Volume 28, Issue, 12, pp. 2037-2041.
- B. Kepenekci, FB Tek, G. Bozdagi Akar, Occluded face recognition based on Gabor wavelets, ICIP 2002, September 2002, Rochester, NY, MP-P3.10.
- H.-S. Le, H. Li, Recognizing images of the 17th International Conference on Pattern Recognition (ICPR04), vol. 1, 2004, pp. 318–321.
- D. Rutkovskaya, M. Pilinsky, L. Rutkovsky. Neural networks, genetic algorithms and fuzzy systems // Per. from Polish M .: Hotline-Telecom, 2004 - 452 p.
- www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
- www.nist.gov/itl/iad/ig/colorferet.cfm
UPDATE: The names of the races are aligned with the English-language Wikipedia.
Source: https://habr.com/ru/post/221137/
All Articles