Indexing handwriting in images: from European languages to Asian
By Evgeny Livshits, Head of Research Group, Evernote Moscow Office
With the recently added support of the Chinese recognition system, Evernote (ENRS, Evernote Recognition System) now indexes handwritten notes in 24 languages. Every time we take on a new language, we face new challenges related to the specifics of a particular alphabet and writing style.
')
Additional difficulties arose when we took up the East Asian languages: Chinese, Japanese, and Korean (CJK). These languages require support by two orders of magnitude more characters, and each of them is much more complicated than those with which we dealt before; spaces between words are optional; with a high writing rate, people often switch to cursive, which makes the interpretation largely context-dependent.
Before diving into the specifics of supporting CJK, let's quickly go through the difficulties that we had to overcome in recognizing handwriting in European languages. Our recognition engine starts parsing the handwritten page by finding text strings. This may already be a non-trivial task. Consider this example:

Lines can be jagged, letters from different lines intersect with each other, and the distance between lines can vary in a wide range. The string segmentation algorithm should unravel random intersections of the trajectories of adjacent rows.
After the lines are built, we are faced with the next task - how to properly divide them into words. This is usually not difficult for typed text, where the difference in spacing between letters and between words is relatively well defined. In the case of handwriting, in many cases it is impossible simply to determine from the distance between letters whether we are faced with a word or word break.

Understanding what is written in the text can help here. Then, understanding the words, we will be able to determine where their beginning is and where the end is. However, this requires the ability to understand the entire line, and not just read one word after another - as most text recognition engines usually do. For European languages, the problem of handwriting recognition is often not much easier than for Asian texts. For example, here’s a sample of handwriting in Korean:

Similarly, you need to select the lines of the text, unraveling the possible intersection. When it is clear that the construction of a separate unit, engaged in word segmentation, is unrealistic. As in the case of European handwriting, the solution was the recognition and segmentation within a single algorithm by understanding the recognized words and defining their boundaries accordingly.
Now let's take a look at the character recognition process. First of all, we need to find the boundaries of symbols. They can pass through small spaces between the strokes or along connecting lines characteristic of fast writing. We do not have a reliable way to determine the points of borders between characters, so we are forced to select potential points of intersymbol fission with a certain margin (we do oversegmentation). At the same time, at this stage, we do not have a clear understanding of whether this or that potential dividing point is in the right place and separates the symbols, or falls inside one of them. As a result, the entire string falls into small blocks.
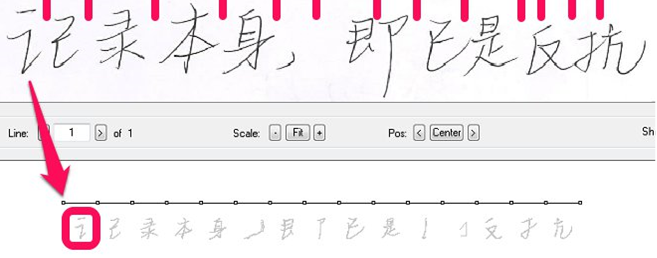
To collect real characters, we try to combine these small blocks into bigger blocks, evaluating each such combination. The image below shows an attempt to recognize a combination of the first two blocks.

Of course, this means that we will have to recognize many more character variants than were actually written. And for CJK languages, this in turn means that the recognition process will be much slower than for European languages, since the evaluation of various combinations requires consideration of a much larger number of “candidates”. The core of our character recognition system is a set of SVM-solvers (Support Vector Machine), each of which solves the problem “one against all” for the symbol assigned to it.
And if for English we need about 50 such solvers (all Latin letters + characters), then we would need 3,750 to support the most common Chinese characters! This would make the process 75 times slower, unless we found a way to run only a fraction of all these solvers each time.
To do this, we first launch a set of much simpler and faster SVMs, which would select a group of characters similar in writing. A standard SVM work only on characters found in the first stage. This approach usually allows us to use only 5-6% of the entire character set, which speeds up the recognition process as a whole by about 20 times.
In order to decide which options from among the many possible interpretations of written characters to choose for the final answer, we need to refer to different language models - this is the context that would allow us to create a more meaningful interpretation of all possible options generated by SVM. Interpretation begins with a simple weighting of the most common two-character combinations, then the context level expands to frequent three-character sequences and then to words from dictionaries and familiar structured models - dates, phones, email addresses. Next come the probable combinations of suggested words and patterns. And without weighing all the possibilities, we cannot say for sure how best to interpret this or that line. Only a comparative assessment of millions and millions of possible combinations, similar to how Deep Blue analyzed a variety of chess positions, playing against Kasparov, allows you to get closer to the optimal interpretation.
As soon as the best interpretation for the string is presented, we can finally define word boundaries. The green frames in the image below show the best way to separate the words, from those that managed to come up.
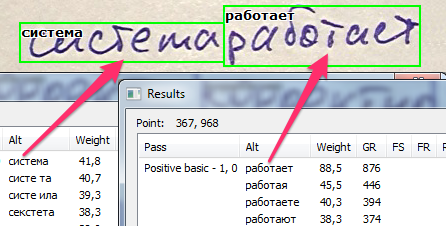
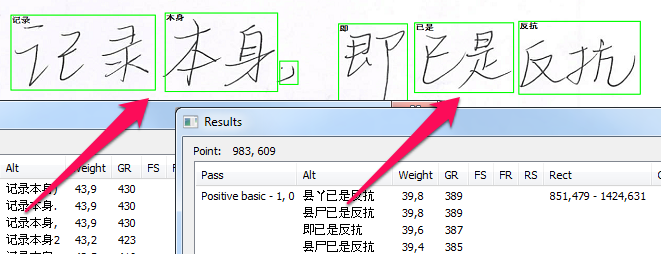
And, as you can see, the process is obtained in many respects the same for both European handwritten texts and CJK.
Source: https://habr.com/ru/post/220369/
All Articles