Demonstration of high-speed processing capabilities of IP packets, for example, a simple DDOS filter developed on the basis of the NETMAP framework
As soon as I became interested in Netmap, I immediately became curious about how many packets per second could be “squeezed out” on ordinary hardware in the packet generation mode and / or in the packet reception and filtering mode? With what performance, it will be possible to filter the traffic of various attacks that are popular today and what packet losses will be at the same time.
The data that the author shows Netmap Luigi Rizzo is very impressive. As is well known, according to published tests by Luigi, Netmap easily generates 14Mpps and allows you to “raise” the flow of 14Mpps from the network cable to the userspace, using only one Core i7 processor core. It became interesting to apply this technology in traffic filtering filters.
So, at the 2013 InfosecurityRussia 2013 exhibition in September, we presented a booth where, at the request of everyone, they generated various attacks and demonstrated protection against them, collecting statistics and drawing various charts with Zabbix.
In this article, we will focus on some of the features of the NETMAP architecture, as well as indicators of packet processing speed, which are obtained with its help on "ordinary" hardware.
')
Before moving on to performance measurements and tests, a few words should be written about the NETMAP framework, which does the basic work of speeding packet processing. A detailed review of NETMAP, made on the basis of a compilation of all materials submitted by its author, was made by me earlier in this article (http://habrahabr.ru/post/183832/). For those who do not need such a deep immersion, a brief description of the framework is offered.
Network adapters (NICs) use ring queues (rings) of memory buffer descriptors to process incoming and outgoing packets, as shown in Figure 2.
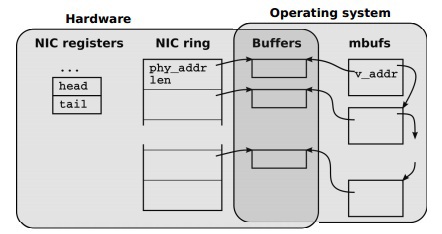
"NIC data structures and their relationship with OS data structures"
Each slot in the ring queue (rings) contains the length and physical address of the buffer. Available (addressable) for the CPU registers NIC contain information about the queues for receiving and transmitting packets.
When a packet arrives on the network card, it is placed in the current memory buffer, its size and status are written to the slot, and information that new incoming data has appeared for processing is written to the corresponding NIC register. The network card initiates an interrupt to inform the CPU of the arrival of new data.
In the case when a packet is sent to the network, the NIC assumes that the OS fills the current buffer, places information about the size of the transmitted data in the slot, writes the number of slots for transmission in the corresponding NIC register, which triggers the sending of packets to the network.
In the case of high rates of reception and transmission of packets, a large number of interruptions can lead to the inability to perform any useful work ("receive live-lock"). To solve these problems, the OS uses the mechanism of polling or interrupt throttling. Some high-performance NICs use multiple queues for receiving / transmitting packets, which allows you to distribute the load on the processor across multiple cores or split a network card into several devices for use in virtual systems working with such a network card.
The OS copies the NIC data structures to the queue of memory buffers, which is specific to each OS. In the case of FreeBSD, these are mbufs equivalents to sk_buffs (Linux) and NdisPackets (Windows). In essence, these memory buffers are containers that contain a large amount of metadata about each packet: the size, the interface with / to which the packet arrived, various attributes and flags defining the processing order of the memory buffer data in the NIC and / or OS.
The NIC driver and the operating system TCP / IP stack (hereinafter referred to as the host stack), as a rule, assume that the packets can be broken into an arbitrary number of fragments, hence the driver and the host stack should be ready to handle packet fragmentation.
When transferring a packet between a network cable and userspace, several copy operations are performed:
As can be seen, the corresponding API exported to userspace implies that different subsystems can leave packets for delayed processing, therefore memory buffers and metadata cannot simply be passed by reference during call processing, but they must be copied or processed by the reference counting mechanism. ). All this is a high overhead fee for flexibility and convenience.
The analysis of the path of a packet through the sendto () system call discussed in the previous article, then the OS stack of FreeBSD on the network showed that the packet passes through several very expensive levels. Using this standard API, there are no opportunities to bypass the memory allocation and copying mechanisms in mbufs, check the correct routes, prepare and construct TCP / UDP / IP / MAC headers and at the end of this processing chain, convert mbuf structures and metadata to NIC format to transfer the packet to the network. Even in the case of local optimization, for example, caching routes and headers instead of building them from scratch, there is no radical increase in the speed that is required for processing packets on 10 Gbit / s interfaces.
One simple way to avoid additional copying in the process of transferring a package from the kernel space to the user space and vice versa is the ability to allow an application direct access to NIC structures. As a rule, this requires that the application runs in the OS kernel. Examples include the Click software router project or the traffic mode kernel mode pkt-gen. Along with ease of access, the kernel space is a very fragile environment, errors in which can lead to a system crash, so a more correct mechanism is to export packet buffers to userspace.
NETMAP, is a system that provides userspace application with very fast access to network packets, both for receiving and sending, both when communicating with the network and when working with the TCP / IP OS stack (host stack). At the same time, efficiency is not sacrificed for risks arising from the full opening of data structures and network card registers in userspace. The framework independently manages the network card, the operating system, at the same time, performs memory protection.
A distinctive feature of NETMAP is tight integration with existing OS mechanisms and the lack of dependence on the hardware features of specific network cards. To achieve the desired high performance characteristics, NETMAP uses several well-known techniques:
In NETMAP, each subsystem does exactly what it is intended for: the NIC transfers data between the network and RAM, the OS kernel performs memory protection, provides multitasking and synchronization.
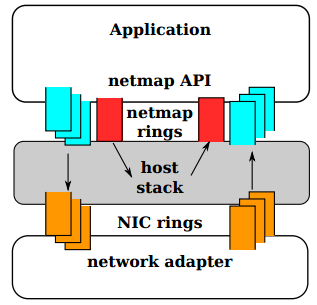
Fig. In NETMAP mode, the NIC queues are disconnected from the TCP / IP OS stack. Exchange between the network and the host stack is carried out only through the NETMAP API.
At the topmost level, when an application through the NETMAP API puts the network card into NETMAP mode, the NIC queues are disconnected from the host stack. The program thus gets the ability to control the exchange of packets between the network and the OS stack, using circular buffers called “netmap rings”. Netmap rings, in turn, are implemented in shared memory. To synchronize the queues in the NIC and the OS stack, the usual OS system calls are used: select () / poll (). Despite the disconnection of the TCP / IP stack from the network card, the operating system continues to operate and execute its operations.
To demonstrate the performance of the DDOS traffic filter, at InfoSecurity Russia 2013, which took place in September 2013, we prepared a booth at which DDOS was generated and protected from large traffic streams. Iron for the stand was chosen the most common:
Traffic / Attack Generator
DDOS filter server
Switch
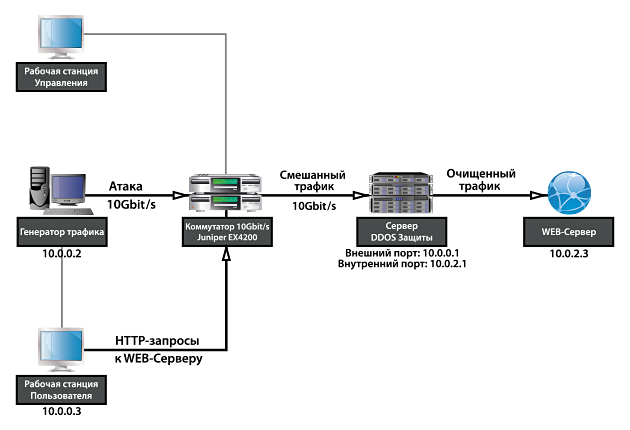
The stand works as follows:
On request, the generator will launch a variety of attacks with adjustable power on the values of PPS and Gbit / s. Attack traffic arrives at Juniper through the 10Gbit / s interface and through the second 10Gbit / s interface arrives at the DDOS protection server. Legal traffic comes to Juniper from the workstation via the 1Gbit / s interface and is mixed in the switch by attack traffic. On the DDOS protection server, traffic is cleared and cleared traffic is sent to the protected server. As a protected service, an HTTP web site is used, the main page of which contains the page access time.
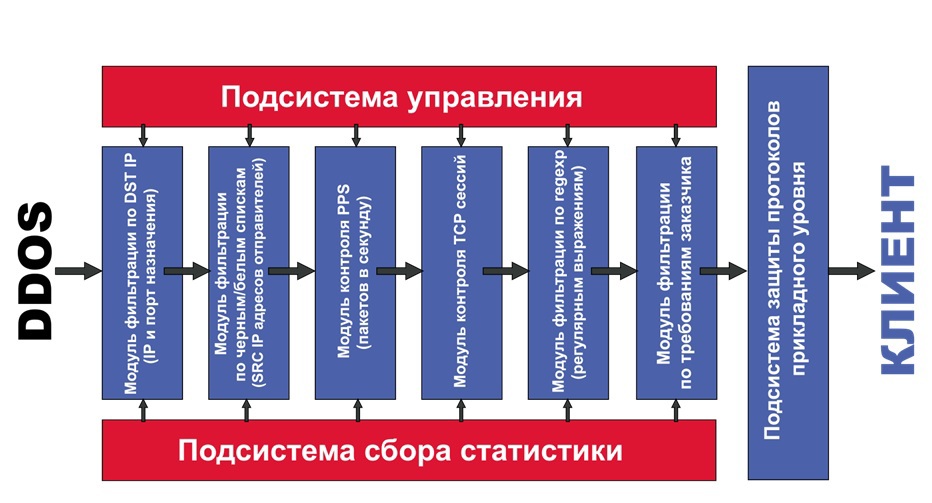
The DDOS protection server, in addition to the modules for working with the NETMAP and TCP / IP stack, contains several filters through which the network packets pass.
As a software for generating traffic, a traffic generator is used, which was also made on the basis of NETMAP and implements the following types of attacks:
The attack uses the parameter - the number of SRC_IP per second, from which traffic flows. Obviously, it does not make much sense to test DDOS by generating an attack from a single ip-address. The tests use from 160 thousand to 1600 thousand new IP-addresses every second to generate an attack.
Short packet SYNflood attack
Long batch SYNflood attack
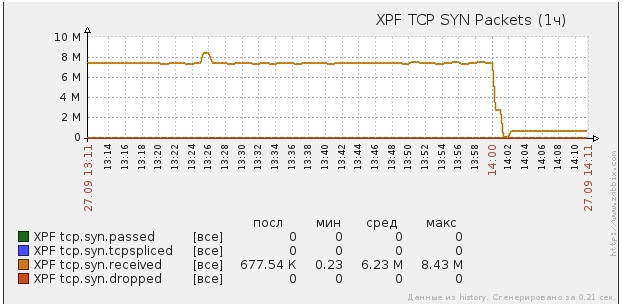
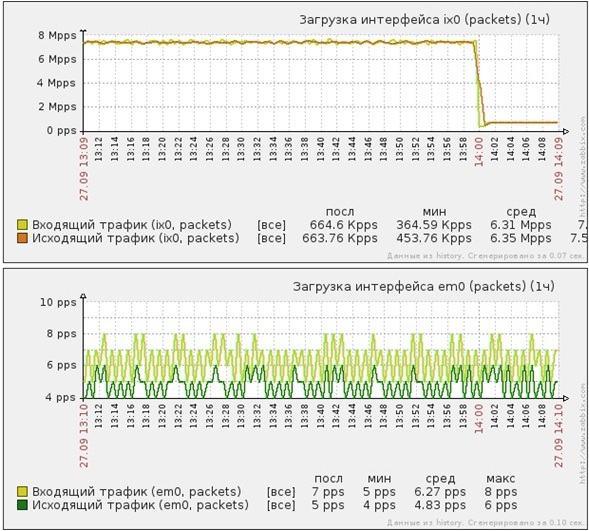
Fig. Incoming SYN packets
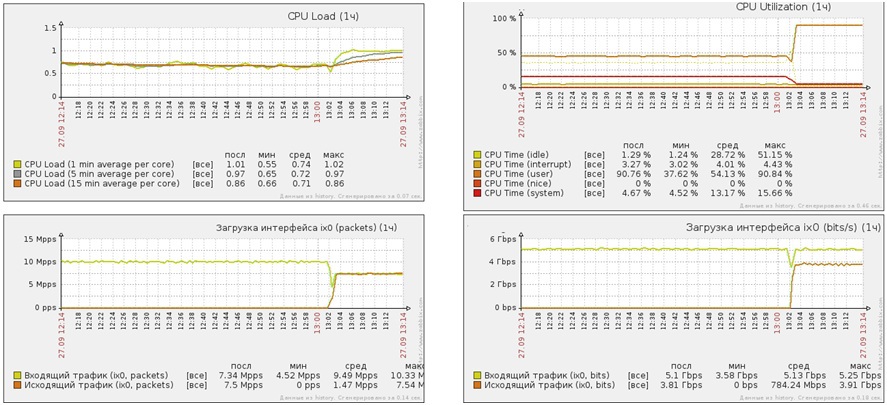
Attack UDP flood short packets
Short packet SYN flood attack
The NETMAP framework can be used as an effective traffic clearing filter, as well as an effective tool for developing load testing tools. As a main advantage, it can be noted that the programs built on the NETMAP framework work on regular hardware and achieve very high performance, which makes it possible to use them as a replacement for the much more expensive alternative solutions offered by Arbor, Radware, Spirent, RioRey etc.
The data that the author shows Netmap Luigi Rizzo is very impressive. As is well known, according to published tests by Luigi, Netmap easily generates 14Mpps and allows you to “raise” the flow of 14Mpps from the network cable to the userspace, using only one Core i7 processor core. It became interesting to apply this technology in traffic filtering filters.
So, at the 2013 InfosecurityRussia 2013 exhibition in September, we presented a booth where, at the request of everyone, they generated various attacks and demonstrated protection against them, collecting statistics and drawing various charts with Zabbix.
In this article, we will focus on some of the features of the NETMAP architecture, as well as indicators of packet processing speed, which are obtained with its help on "ordinary" hardware.
')
1. A brief introduction to NETMAP
Before moving on to performance measurements and tests, a few words should be written about the NETMAP framework, which does the basic work of speeding packet processing. A detailed review of NETMAP, made on the basis of a compilation of all materials submitted by its author, was made by me earlier in this article (http://habrahabr.ru/post/183832/). For those who do not need such a deep immersion, a brief description of the framework is offered.
1.1. NIC data structures and operations with them
Network adapters (NICs) use ring queues (rings) of memory buffer descriptors to process incoming and outgoing packets, as shown in Figure 2.
"NIC data structures and their relationship with OS data structures"
Each slot in the ring queue (rings) contains the length and physical address of the buffer. Available (addressable) for the CPU registers NIC contain information about the queues for receiving and transmitting packets.
When a packet arrives on the network card, it is placed in the current memory buffer, its size and status are written to the slot, and information that new incoming data has appeared for processing is written to the corresponding NIC register. The network card initiates an interrupt to inform the CPU of the arrival of new data.
In the case when a packet is sent to the network, the NIC assumes that the OS fills the current buffer, places information about the size of the transmitted data in the slot, writes the number of slots for transmission in the corresponding NIC register, which triggers the sending of packets to the network.
In the case of high rates of reception and transmission of packets, a large number of interruptions can lead to the inability to perform any useful work ("receive live-lock"). To solve these problems, the OS uses the mechanism of polling or interrupt throttling. Some high-performance NICs use multiple queues for receiving / transmitting packets, which allows you to distribute the load on the processor across multiple cores or split a network card into several devices for use in virtual systems working with such a network card.
1.2. Packet handling problems with TCP / IP OS stack
The OS copies the NIC data structures to the queue of memory buffers, which is specific to each OS. In the case of FreeBSD, these are mbufs equivalents to sk_buffs (Linux) and NdisPackets (Windows). In essence, these memory buffers are containers that contain a large amount of metadata about each packet: the size, the interface with / to which the packet arrived, various attributes and flags defining the processing order of the memory buffer data in the NIC and / or OS.
The NIC driver and the operating system TCP / IP stack (hereinafter referred to as the host stack), as a rule, assume that the packets can be broken into an arbitrary number of fragments, hence the driver and the host stack should be ready to handle packet fragmentation.
When transferring a packet between a network cable and userspace, several copy operations are performed:
- Populating NIC data structures with network data
- Copy data from NIC data structures to mbufs / sk_bufs / NdisPackets
- Copying data from mbuf / sk_buf / NdisPackets to userspace
As can be seen, the corresponding API exported to userspace implies that different subsystems can leave packets for delayed processing, therefore memory buffers and metadata cannot simply be passed by reference during call processing, but they must be copied or processed by the reference counting mechanism. ). All this is a high overhead fee for flexibility and convenience.
The analysis of the path of a packet through the sendto () system call discussed in the previous article, then the OS stack of FreeBSD on the network showed that the packet passes through several very expensive levels. Using this standard API, there are no opportunities to bypass the memory allocation and copying mechanisms in mbufs, check the correct routes, prepare and construct TCP / UDP / IP / MAC headers and at the end of this processing chain, convert mbuf structures and metadata to NIC format to transfer the packet to the network. Even in the case of local optimization, for example, caching routes and headers instead of building them from scratch, there is no radical increase in the speed that is required for processing packets on 10 Gbit / s interfaces.
1.3. Techniques to increase productivity when processing packets used in NETMAP
One simple way to avoid additional copying in the process of transferring a package from the kernel space to the user space and vice versa is the ability to allow an application direct access to NIC structures. As a rule, this requires that the application runs in the OS kernel. Examples include the Click software router project or the traffic mode kernel mode pkt-gen. Along with ease of access, the kernel space is a very fragile environment, errors in which can lead to a system crash, so a more correct mechanism is to export packet buffers to userspace.
NETMAP, is a system that provides userspace application with very fast access to network packets, both for receiving and sending, both when communicating with the network and when working with the TCP / IP OS stack (host stack). At the same time, efficiency is not sacrificed for risks arising from the full opening of data structures and network card registers in userspace. The framework independently manages the network card, the operating system, at the same time, performs memory protection.
A distinctive feature of NETMAP is tight integration with existing OS mechanisms and the lack of dependence on the hardware features of specific network cards. To achieve the desired high performance characteristics, NETMAP uses several well-known techniques:
- Compact and lightweight package metadata structures. Simple to use, they hide hardware-specific mechanisms, providing a convenient and easy way to work with packages. In addition, the NETMAP metadata is designed to handle many different packets for a single system call, thus reducing packet overhead.
- Linear preallocated buffers, fixed sizes. Allow to reduce memory management overhead
- Zero copy operations for packet forwarding between interfaces, as well as between interfaces and host stack
- Linear preallocated buffers, fixed sizes. Allow to reduce memory management overhead
- Zero copy operations for packet forwarding between interfaces, as well as between interfaces and host stack
- Support for useful network card hardware features such as multiple hardware queues
In NETMAP, each subsystem does exactly what it is intended for: the NIC transfers data between the network and RAM, the OS kernel performs memory protection, provides multitasking and synchronization.
Fig. In NETMAP mode, the NIC queues are disconnected from the TCP / IP OS stack. Exchange between the network and the host stack is carried out only through the NETMAP API.
At the topmost level, when an application through the NETMAP API puts the network card into NETMAP mode, the NIC queues are disconnected from the host stack. The program thus gets the ability to control the exchange of packets between the network and the OS stack, using circular buffers called “netmap rings”. Netmap rings, in turn, are implemented in shared memory. To synchronize the queues in the NIC and the OS stack, the usual OS system calls are used: select () / poll (). Despite the disconnection of the TCP / IP stack from the network card, the operating system continues to operate and execute its operations.
2. Stand for testing
To demonstrate the performance of the DDOS traffic filter, at InfoSecurity Russia 2013, which took place in September 2013, we prepared a booth at which DDOS was generated and protected from large traffic streams. Iron for the stand was chosen the most common:
Traffic / Attack Generator
- Intel Core i7-2600 3.4GHz TurboBoost processor
- RAM 8GB 1333MHz DDR3
- HDD SATA 500GB
- OS FreeBSD 9-STABLE
- Intel X520 10Gbit / s SFP + dual-port network card
DDOS filter server
- Intel Xeon E3-1230 3.2GHz TurboBoost processor
- RAM 8GB 1333MHz DDR3
- HDD SATA 500GB
- OS FreeBSD 9-STABLE
- Intel X520 10Gbit / s SFP + dual-port network card
Switch
- Juniper EX4200 with 2x10Gbit / s SFP + interfaces
The stand works as follows:
On request, the generator will launch a variety of attacks with adjustable power on the values of PPS and Gbit / s. Attack traffic arrives at Juniper through the 10Gbit / s interface and through the second 10Gbit / s interface arrives at the DDOS protection server. Legal traffic comes to Juniper from the workstation via the 1Gbit / s interface and is mixed in the switch by attack traffic. On the DDOS protection server, traffic is cleared and cleared traffic is sent to the protected server. As a protected service, an HTTP web site is used, the main page of which contains the page access time.
3. A simplified description of the coarse traffic clearing mechanisms
The DDOS protection server, in addition to the modules for working with the NETMAP and TCP / IP stack, contains several filters through which the network packets pass.
- The first filter is to check the destination address of the packet, the protocol and the destination port. It makes no sense to spend resources on processing packets, if for example the tcp / port to which the packet arrived, is not served. Such packages are immediately "forgotten" in the netmap-rings and overwritten by newcomers.
- The second filter works by limiting pps / bandwidth for an ip-address, or an ip-network / group of networks, etc. Using this filter, for example, you can allow to pass a strictly specified number of packets per second from “any” ip-addresses from the Internet, packets going to a specific address and port of the protected server. All packages above the specified limit will be "killed"
- The third filter is an implementation of the syncookie mechanism to protect against SYNflood attacks. If a legal connection arrives, the client is connected to the protected server, for increased performance, the TCP splicing technique is used ( www.pam2010.ethz.ch/papers/full-length/5.pdf )
- The last filter is a search engine based on “regular expressions”, working to add ip-addresses to “black”, “white”, as well as “black-gray” and “white-gray” lists, in which the IP address is temporarily
4. Measurement of the speed of processing packages at the booth of the exhibition Infosecurity 2013
As a software for generating traffic, a traffic generator is used, which was also made on the basis of NETMAP and implements the following types of attacks:
- UDP flood in short and / or long packets
- Synflood short and / or long packages
The attack uses the parameter - the number of SRC_IP per second, from which traffic flows. Obviously, it does not make much sense to test DDOS by generating an attack from a single ip-address. The tests use from 160 thousand to 1600 thousand new IP-addresses every second to generate an attack.
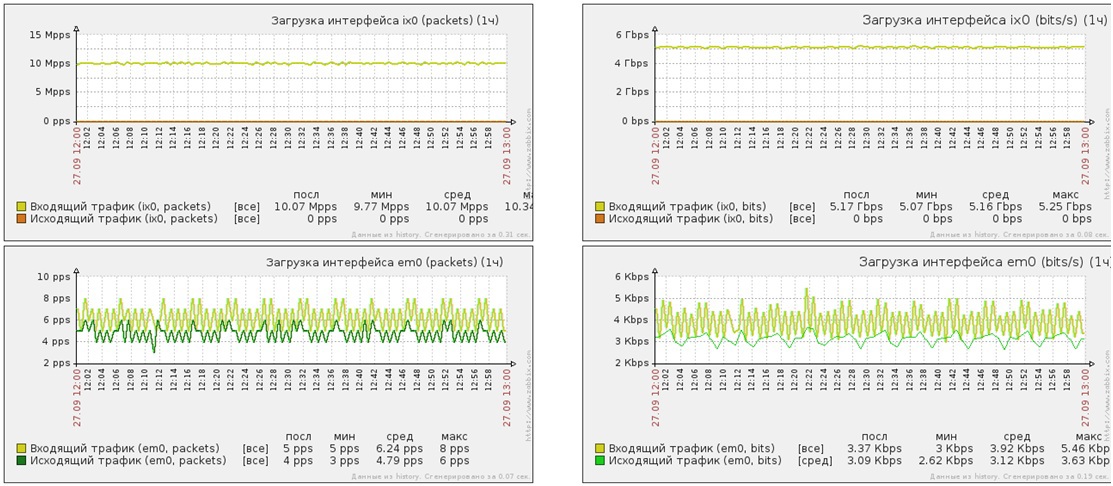
UDP flood flood attack on port 53 of the protected web server
- Attack power - 10 million PPS
- Attack power - 5Gbit / s
- Traffic after cleaning - 8 PPS
- Traffic after cleaning - 5Kbit / s
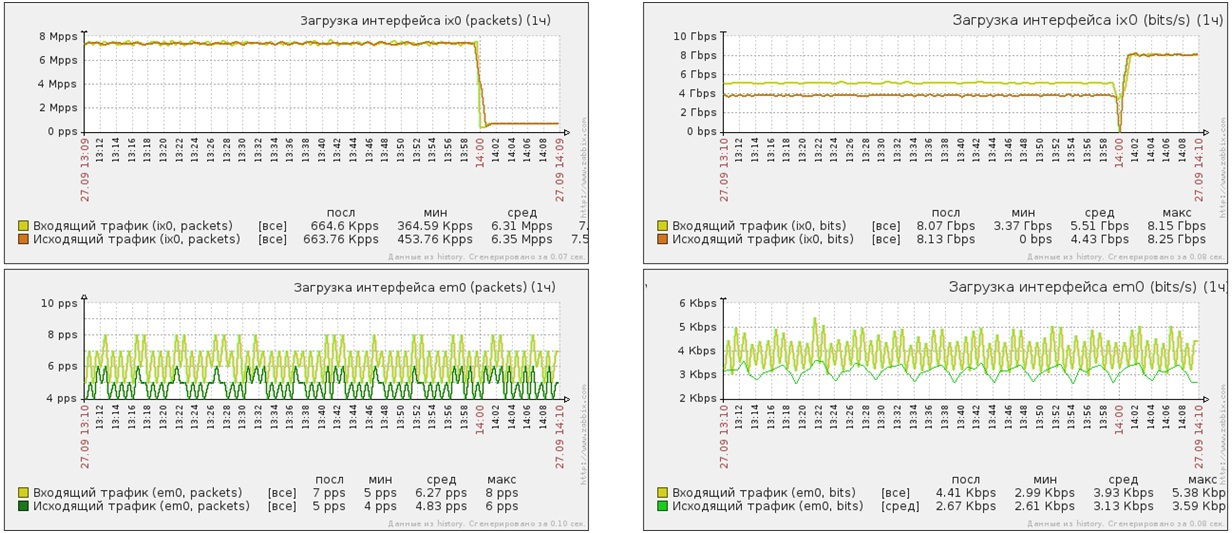
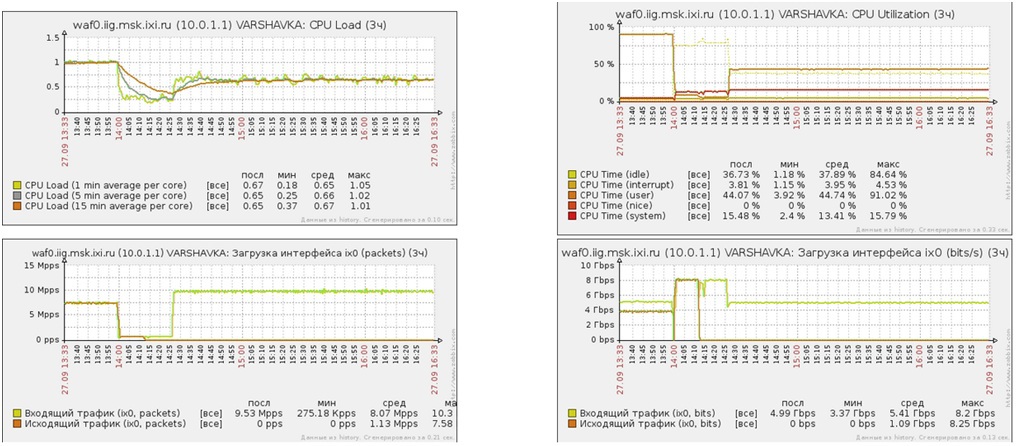
SYN-flood attack short, then long packets on port 80 of the protected server
Short packet SYNflood attack
- Attack power - 7 million PPS
- Attack power - 5 Gbit / s
- Traffic after cleaning - 8 PPS
- Traffic after cleaning - 5Kbit / s
Long batch SYNflood attack
- Attack power - 600 thousand PPS
- Attack power - 8 Gbit / s
- Traffic after cleaning - 8 PPS
- Traffic after cleaning - 5Kbit / s
Fig. Incoming SYN packets
CPU load under UDP / SYN flood attack
Attack UDP flood short packets
- Attack power - 10 million PPS
- Attack power - 5 Gbit / s
- Average CPU load (user) 50%
- Average CPU load (system) 15%
Short packet SYN flood attack
- PPS attack power 7 million PPS
- Attack power in Gbit / s 5 Gbit / s
- Average CPU load (user) 90%
- Average CPU load (system) 5%
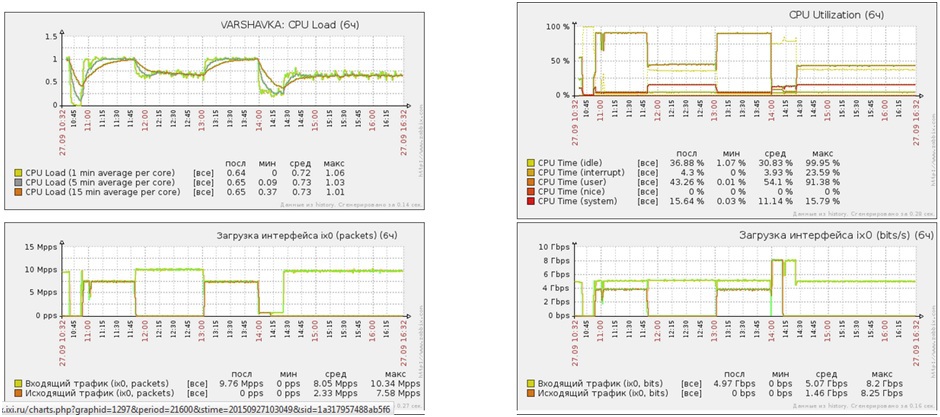
Long work under Flood-attacks
- Attack time 6 hours
- Types of SYNflood / UDPflood attacks
- Attack power 5 Gbit / s - 10 Gbit / s
- Average CPU load (user) 50%
- Average CPU load (system) 11%
5. Conclusion
The NETMAP framework can be used as an effective traffic clearing filter, as well as an effective tool for developing load testing tools. As a main advantage, it can be noted that the programs built on the NETMAP framework work on regular hardware and achieve very high performance, which makes it possible to use them as a replacement for the much more expensive alternative solutions offered by Arbor, Radware, Spirent, RioRey etc.
Source: https://habr.com/ru/post/220331/
All Articles