(Self) processor identification. Part one. Architecture Comparison
I work with software models of central processors as part of a full-platform simulator. This occupation is, of course, very interesting - it is necessary to deal with the technologies of interpretation, binary translation, virtualization (I already wrote about this here ). One day my attention was attracted by the fact that for a significant part of the time I was hovering over the only seemingly not very computationally intensive instruction. The reason is that there are many types of processors, and they are all very similar; however, it is critical to very precisely represent the differences between them.
In this article, I describe why and how processors are able to communicate about their capabilities, and how different manufacturers approached this issue. In its continuation, I will talk about the evolution and features of the CPUID instruction for Intel IA-32, for example, why its description takes about 40 pages in Intel SDM [1].

First I want to focus on the usual and therefore not too surprising fact: the same program for the PC without any modifications of the binary code can be run on systems that are differently arranged inside. After all, the CPU of different manufacturers, different generations and the internal structure is not repeated: the sizes of transistors are different, the frequency varies, the memory is differently organized, the conveyor has a different number of stages, etc. Sometimes there is no processor either - instead of it, the virtual machine slipped something strange. However, the same binary code almost always works! This is possible thanks to the agreement between hardware developers and programmers, which is fixed in the form of a specification for an instruction set (ISA, instruction set architecture). The invariability of this interface is often the key to the commercial success of initiatives in the microprocessor industry.
')
And yet, almost every "adult" architecture of the central processor during its evolution acquires different extensions of ISA. They bring improvements in computing speed, lower power consumption, security features, faster encryption, signal processing, virtualization, etc. A contradictory situation arises: on the one hand, there is a need for stability; on the other hand, regular supplements from competing manufacturers.
Programmers have to clear up, if not applied, then writers of operating systems and compilers are so accurate. Their programs should be able to “distinguish” the features of the equipment on which they are running, and select the branches of execution that optimally use the detected extensions.
In the specifications for processor architectures for this purpose, identification means are usually described in the form of specialized registers and instructions. Once I wondered - what differences exist in what information, how much detail and in what format different vendors convey to system programmers?
I offer a brief overview of the means of identification of a number of popular CPU families. I prepared it by studying the online documentation available, using my own experiments where it was possible to get a piece of hardware and find time to play around, studying the sources of the architecture-dependent parts of the kernels of open operating systems such as Linux and FreeBSD, and also due to discussions with friends development of system software for these architectures. In each case, I will evaluate the full capacity of the provided architectural state in bits.
The MIPS32 architecture [6, 7] (now owned by Imagination Technologies) stores the identification information in the PRid register — the 15th zero coprocessor register [8]. It contains only 32 bits:
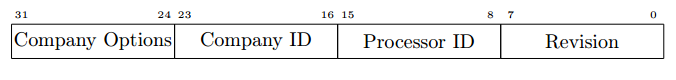
In addition, the Floating Point Implementation Register (FIR) is used to describe the capabilities of the floating-point number module (FPU). It also works only on reading and has a width of 32 bits.

This popular RISC architecture does not indulge developers with convenient means of identifying the extensions present. This conclusion can be drawn from the fact that the unification of the ARM support code in Linux was made only in release 3.7 . Approximately the same opinion was expressed by a friend of mine from Samsung. It surprises me a little, considering that ARM is the architecture with which many vendors produce processors. Why this is so, I will try to speculate closer to the end of this note.
The 32-bit cpuid [10] register of System Control Control Server defines several properties, including the vendor code and revision:

Examples of the values of this register for different products: Intel (XScale) PXA272 - 0x69054117, Qualcomm MSM7200A - 0x4117b362.
Much more information can be obtained through the Debug registers, but this will require kernel privileges. Theoretically, in 18 registers of 32 bits each one can encode 576 bits. User yulyugin wrote a Linux kernel module [2] and collected data for the ARM1176JZFS used in Raspberry Pi, for which he thanks a lot.
IBM System z [4], which generates ancestry from mainframes, is very different in organization from more familiar to most systems, derived from “calculators”. But on the mainframe it was necessary to be able to recognize extensions, which from the 60s could gain a lot. For this, the architecture has STSI and STIDP instructions.
STSI is used to obtain information about the model, the identifier of the capacity of the basic configuration.
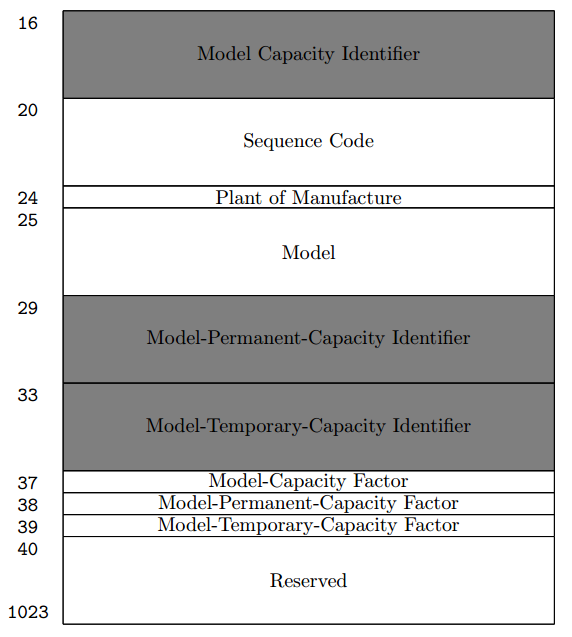
In the 44 registers of 32 bits can be placed about 1.4 kbps of data.
STIDP reports the processor type, serial number, and logical partition identifier used for virtualization.

The only PVR in PowerPC [5] is 32 bits wide and contains only the vendor ID and revision.

However, for the expansion of ISA, an APU (application processor units) mechanism is provided - separate “devices” that provide decoding and execution of additional commands. Unfortunately, I could not find detailed information on whether it is possible to programmatically list all available APUs. I would be grateful if they tell me.
SPARC v9 [9] standard was not tied to any vendor from the very beginning and therefore its specifications look very “politically correct”. Relatively many items in the documentation are intentionally labeled as “implementation dependent”. For identification, the 64-bit VER register is entered:

Intel IA-64, also known as Itanium, was designed after the Intel 80x86 series and was originally intended to supplant the latter (what happened next is history). Not surprisingly, the set of cpuid registers used to identify the IA-64 [8] resembles the output structure of the CPUID instruction on Intel IA-32 aka x86 .
Currently, IA-64 systems offer up to five cpuid registers. In the event that expansion is required in the future, bits 0–7 of cpuid3 store the total number of such registers (i.e., there can be as many as 256).
The contents of the cpuid registers for Intel Itanium 9100 (codename Montvale), obtained using the ggg-cpuid program [2]:
The total capacity of the identification data can be estimated as 5 × 64 = 320 bits.
All familiar modern PCs, derived from the IBM PC, use Intel IA-32. Starting with Intel Pentium (and its clones), CPUID instructions are available in the processors of this architecture. The 64-bit extension, known as Intel 64 [1] or AMD64 [3], did not make fundamental changes to its work, so we will not distinguish them further.
The CPUID accepts two 32-bit values in EAX and ECX, called leaf and subsheet (English leaf and subleaf), and places the results in four 32-bit registers: EAX, EBX, ECX and EDX. I note that in the 64-bit mode, only 32 bits of all registers are still used.
Theoretically, the list and podlist encode 64 bits of the key, and the output contains 128 data bits. Fortunately, not all combinations are allowed by now. Unfortunately, combinations of sheets with podlisty have a specific logic. Since the introduction of the command, the CPUID output volume (i.e., the number of valid combinations of sheets and sublist) has been expanded many times.
CPUID is interesting enough to devote a separate article to it. Here I will only say that according to its conclusion, it is possible to understand how many cores the processor has, how its caches are arranged, what instructions are present in it, and, of course, who made it.
CPUID output for Intel Xeon CPU E5-2690, obtained using ggg-cpuid [2]:
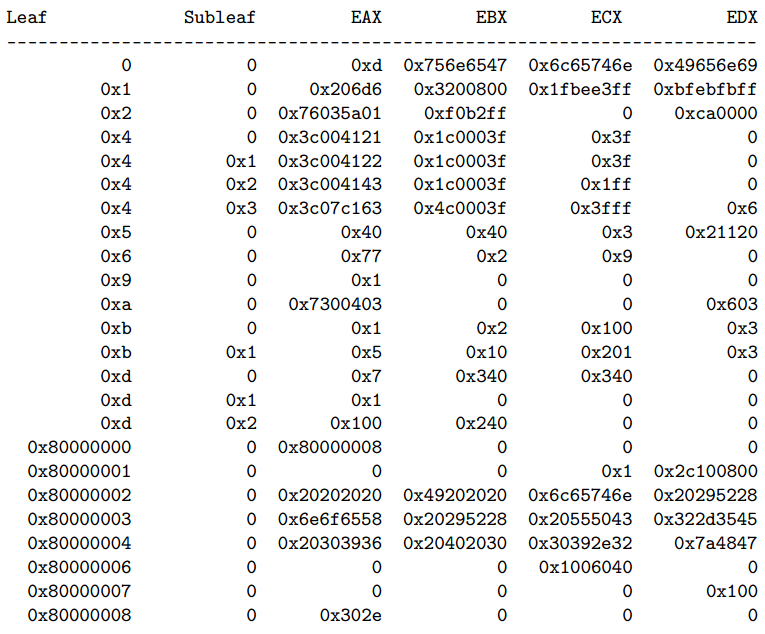
In its current state, the CPUID is able to encode about 3 kbps of data.
This comparison, alas, will not be here. Too different in composition of the proposed extensions are different processors. But the general is still there. All the considered systems allow finding out at least two parameters: the manufacturer and a certain number of the processor “revision”. Indeed, this seems to be the minimum necessary set for identification. If you store in the software application the vendor compliance table → “product” → “extension list”, then it will be able to uniquely identify the properties of the specific piece of hardware on which it was launched. This approach, by the way, I found in the source code of operating systems: one or two (nested) large switch'a.
This is not to say that this minimalism is convenient. First, it is necessary to somehow form and store such a table, and for this you will have to search through a fair amount of documentation and conduct full-scale experiments. Secondly, there is an extreme inflexibility of the resulting code in relation to future systems. It is enough for a new vendor to enter the market or to already present to release a seemingly compatible CPU with a new revision number, and such a program will not be able to recognize it without updating the table and then recompiling it. Using bitmasks to encode the available extensions allows the “old” code to ignore the new extensions, but to recognize the known ones, which is useful for backward compatibility.
What really varies across all architectures is the amount of identification data provided. In this graph, I have gathered together the approximate values of the capacity of the associated architectural state in bits for all the processors described above.
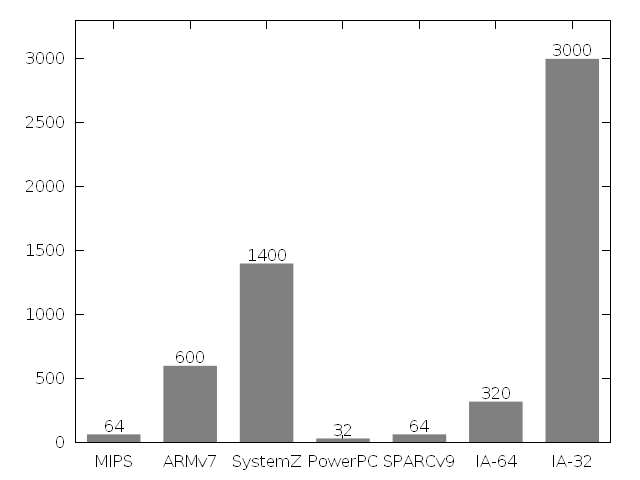
Then I tried to find some correlation of values on the features of each architecture, but I did not really succeed. For example, the "age" of the system does not affect the amount of data. In general, it is quite difficult to determine the age of architecture, since one often grows from another. At first, I wanted to write that system z was announced in 2005, but I remembered that it comes from System / 360, which appeared in the 1960s. Same story with Intel IA-32. Identification for it in its present form appeared in 1993 (as it was before, I will write in the second part); but 8086 is from the 1970s! Intel IA-64 (announced at the beginning of the two thousandths) simply did not have time to incorporate uncountable extensions in order to be able to “flash” the confusing cpuid contents. MIPS and ARM also cannot be called young systems, they already existed at least in the 1980s, but they somehow did not add reliable identification.
What seemed to be actually observable to me was the fact of the dependence of the quantity and quality of the means of identifying extensions on the “embeddedness” property of the architecture. If the system was originally intended for the embedded market in which the portability of a binary code is not a selling factor, then its identification means are relatively modest. On the contrary, the PC market, the CPU for which at one time was produced by almost ten companies (I was surprised to learn yesterday that even the clone 8086 was from Siemens !), And the range of architecture applications varies from IoT to supercomputers with specialized accelerators , dictated the need for clear differentiation simultaneously with the portability of the binary code, which led to the "swelling" of the IA-32 CPUID to incredible sizes.
In this small review I was not able to describe in detail the details of identifying specific CPU models with examples. Also, some of the less popular processor families were not mentioned at all: ARC, Alpha, AVR, Z80, 68000, 6502, Cell, Elbrus ... And, if for Intel IA-32 I can still try to make a detailed description, then on other architectures, alas, my knowledge is rather poor. However, I hope to gradually get to them. Therefore, I would be grateful if in the comments readers will share links to documentation or simply tell about their experience with the code, which requires identification of processor extensions.
Thanks for attention!
In this article, I describe why and how processors are able to communicate about their capabilities, and how different manufacturers approached this issue. In its continuation, I will talk about the evolution and features of the CPUID instruction for Intel IA-32, for example, why its description takes about 40 pages in Intel SDM [1].
Why do we need processor identification
First I want to focus on the usual and therefore not too surprising fact: the same program for the PC without any modifications of the binary code can be run on systems that are differently arranged inside. After all, the CPU of different manufacturers, different generations and the internal structure is not repeated: the sizes of transistors are different, the frequency varies, the memory is differently organized, the conveyor has a different number of stages, etc. Sometimes there is no processor either - instead of it, the virtual machine slipped something strange. However, the same binary code almost always works! This is possible thanks to the agreement between hardware developers and programmers, which is fixed in the form of a specification for an instruction set (ISA, instruction set architecture). The invariability of this interface is often the key to the commercial success of initiatives in the microprocessor industry.
')
And yet, almost every "adult" architecture of the central processor during its evolution acquires different extensions of ISA. They bring improvements in computing speed, lower power consumption, security features, faster encryption, signal processing, virtualization, etc. A contradictory situation arises: on the one hand, there is a need for stability; on the other hand, regular supplements from competing manufacturers.
Programmers have to clear up, if not applied, then writers of operating systems and compilers are so accurate. Their programs should be able to “distinguish” the features of the equipment on which they are running, and select the branches of execution that optimally use the detected extensions.
In the specifications for processor architectures for this purpose, identification means are usually described in the form of specialized registers and instructions. Once I wondered - what differences exist in what information, how much detail and in what format different vendors convey to system programmers?
Comparing different architectures
I offer a brief overview of the means of identification of a number of popular CPU families. I prepared it by studying the online documentation available, using my own experiments where it was possible to get a piece of hardware and find time to play around, studying the sources of the architecture-dependent parts of the kernels of open operating systems such as Linux and FreeBSD, and also due to discussions with friends development of system software for these architectures. In each case, I will evaluate the full capacity of the provided architectural state in bits.
Mips32
The MIPS32 architecture [6, 7] (now owned by Imagination Technologies) stores the identification information in the PRid register — the 15th zero coprocessor register [8]. It contains only 32 bits:
In addition, the Floating Point Implementation Register (FIR) is used to describe the capabilities of the floating-point number module (FPU). It also works only on reading and has a width of 32 bits.
ARM
This popular RISC architecture does not indulge developers with convenient means of identifying the extensions present. This conclusion can be drawn from the fact that the unification of the ARM support code in Linux was made only in release 3.7 . Approximately the same opinion was expressed by a friend of mine from Samsung. It surprises me a little, considering that ARM is the architecture with which many vendors produce processors. Why this is so, I will try to speculate closer to the end of this note.
The 32-bit cpuid [10] register of System Control Control Server defines several properties, including the vendor code and revision:
Examples of the values of this register for different products: Intel (XScale) PXA272 - 0x69054117, Qualcomm MSM7200A - 0x4117b362.
Much more information can be obtained through the Debug registers, but this will require kernel privileges. Theoretically, in 18 registers of 32 bits each one can encode 576 bits. User yulyugin wrote a Linux kernel module [2] and collected data for the ARM1176JZFS used in Raspberry Pi, for which he thanks a lot.
IBM system z
IBM System z [4], which generates ancestry from mainframes, is very different in organization from more familiar to most systems, derived from “calculators”. But on the mainframe it was necessary to be able to recognize extensions, which from the 60s could gain a lot. For this, the architecture has STSI and STIDP instructions.
STSI is used to obtain information about the model, the identifier of the capacity of the basic configuration.
In the 44 registers of 32 bits can be placed about 1.4 kbps of data.
STIDP reports the processor type, serial number, and logical partition identifier used for virtualization.
PowerPC
The only PVR in PowerPC [5] is 32 bits wide and contains only the vendor ID and revision.
However, for the expansion of ISA, an APU (application processor units) mechanism is provided - separate “devices” that provide decoding and execution of additional commands. Unfortunately, I could not find detailed information on whether it is possible to programmatically list all available APUs. I would be grateful if they tell me.
SPARC
SPARC v9 [9] standard was not tied to any vendor from the very beginning and therefore its specifications look very “politically correct”. Relatively many items in the documentation are intentionally labeled as “implementation dependent”. For identification, the 64-bit VER register is entered:
Intel IA-64 (Itanium)
Intel IA-64, also known as Itanium, was designed after the Intel 80x86 series and was originally intended to supplant the latter (what happened next is history). Not surprisingly, the set of cpuid registers used to identify the IA-64 [8] resembles the output structure of the CPUID instruction on Intel IA-32 aka x86 .
Currently, IA-64 systems offer up to five cpuid registers. In the event that expansion is required in the future, bits 0–7 of cpuid3 store the total number of such registers (i.e., there can be as many as 256).
The contents of the cpuid registers for Intel Itanium 9100 (codename Montvale), obtained using the ggg-cpuid program [2]:
The total capacity of the identification data can be estimated as 5 × 64 = 320 bits.
Intel IA-32 and Intel 64
All familiar modern PCs, derived from the IBM PC, use Intel IA-32. Starting with Intel Pentium (and its clones), CPUID instructions are available in the processors of this architecture. The 64-bit extension, known as Intel 64 [1] or AMD64 [3], did not make fundamental changes to its work, so we will not distinguish them further.
The CPUID accepts two 32-bit values in EAX and ECX, called leaf and subsheet (English leaf and subleaf), and places the results in four 32-bit registers: EAX, EBX, ECX and EDX. I note that in the 64-bit mode, only 32 bits of all registers are still used.
Theoretically, the list and podlist encode 64 bits of the key, and the output contains 128 data bits. Fortunately, not all combinations are allowed by now. Unfortunately, combinations of sheets with podlisty have a specific logic. Since the introduction of the command, the CPUID output volume (i.e., the number of valid combinations of sheets and sublist) has been expanded many times.
CPUID is interesting enough to devote a separate article to it. Here I will only say that according to its conclusion, it is possible to understand how many cores the processor has, how its caches are arranged, what instructions are present in it, and, of course, who made it.
CPUID output for Intel Xeon CPU E5-2690, obtained using ggg-cpuid [2]:
In its current state, the CPUID is able to encode about 3 kbps of data.
Identification Comparison
This comparison, alas, will not be here. Too different in composition of the proposed extensions are different processors. But the general is still there. All the considered systems allow finding out at least two parameters: the manufacturer and a certain number of the processor “revision”. Indeed, this seems to be the minimum necessary set for identification. If you store in the software application the vendor compliance table → “product” → “extension list”, then it will be able to uniquely identify the properties of the specific piece of hardware on which it was launched. This approach, by the way, I found in the source code of operating systems: one or two (nested) large switch'a.
This is not to say that this minimalism is convenient. First, it is necessary to somehow form and store such a table, and for this you will have to search through a fair amount of documentation and conduct full-scale experiments. Secondly, there is an extreme inflexibility of the resulting code in relation to future systems. It is enough for a new vendor to enter the market or to already present to release a seemingly compatible CPU with a new revision number, and such a program will not be able to recognize it without updating the table and then recompiling it. Using bitmasks to encode the available extensions allows the “old” code to ignore the new extensions, but to recognize the known ones, which is useful for backward compatibility.
What really varies across all architectures is the amount of identification data provided. In this graph, I have gathered together the approximate values of the capacity of the associated architectural state in bits for all the processors described above.
Then I tried to find some correlation of values on the features of each architecture, but I did not really succeed. For example, the "age" of the system does not affect the amount of data. In general, it is quite difficult to determine the age of architecture, since one often grows from another. At first, I wanted to write that system z was announced in 2005, but I remembered that it comes from System / 360, which appeared in the 1960s. Same story with Intel IA-32. Identification for it in its present form appeared in 1993 (as it was before, I will write in the second part); but 8086 is from the 1970s! Intel IA-64 (announced at the beginning of the two thousandths) simply did not have time to incorporate uncountable extensions in order to be able to “flash” the confusing cpuid contents. MIPS and ARM also cannot be called young systems, they already existed at least in the 1980s, but they somehow did not add reliable identification.
What seemed to be actually observable to me was the fact of the dependence of the quantity and quality of the means of identifying extensions on the “embeddedness” property of the architecture. If the system was originally intended for the embedded market in which the portability of a binary code is not a selling factor, then its identification means are relatively modest. On the contrary, the PC market, the CPU for which at one time was produced by almost ten companies (I was surprised to learn yesterday that even the clone 8086 was from Siemens !), And the range of architecture applications varies from IoT to supercomputers with specialized accelerators , dictated the need for clear differentiation simultaneously with the portability of the binary code, which led to the "swelling" of the IA-32 CPUID to incredible sizes.
Conclusion
In this small review I was not able to describe in detail the details of identifying specific CPU models with examples. Also, some of the less popular processor families were not mentioned at all: ARC, Alpha, AVR, Z80, 68000, 6502, Cell, Elbrus ... And, if for Intel IA-32 I can still try to make a detailed description, then on other architectures, alas, my knowledge is rather poor. However, I hope to gradually get to them. Therefore, I would be grateful if in the comments readers will share links to documentation or simply tell about their experience with the code, which requires identification of processor extensions.
Thanks for attention!
Literature
- Intel Corporation. Intel 64 and IA-32 Architects Software Developer's Manual. Volumes 1-3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Grigory Rechistov. A set of CPU identification tools for Intel IA-32, IA-64 and other systems. github.com/grigory-rechistov/ggg-cpuid
- Advanced Micro Devices. AMD64 Architecture Programmer's Manual Volume 1: Application Programming, 2012. support.amd.com/us/Processor_TechDocs/24592_APM_v1.pdf
- Per Fremstad, Wolfgang Fries, Marian Gasparovic, Parwez Hamid, Brian Hatfield, Dick Jorna, Fernando Nogal, and Karl-Erik Stenfors. IBM System z10 Enterprise Class Technical Guide. IBM, November 2009.
- Ibm. PowerPC Microprocessor Family for The 64-bit Microprocessors Version 3.0, July 2005.
- Imagination Technologies. MIPS32 Architecture, 2014. www.imgtec.com/mips/mips32-architecture.asp
- MIPS Technologies, Inc. MIPS Architecture For Programmers Volume IA: Introduction to the MIPS32 Architecture, March 2011.
- Intel Corporation. Intel Itanium Architecture Software Developer's Manual. Volumes 1–4, 2010. www.intel.com/content/dam/doc/manual/itanium-architecture-vol-1-2-3-4-reference-set-manual.pdf
- DL Weaver, T. Germond, and SPARC International. The SPARC architecture manual: version 9. PTR Prentice Hall, 1994. books.google.com/books?id=JNVQAAAAMAAJ
- ARM Limited. CPUID Base Register. Cortex-M1 FPGA Development Kit Cortex-M1 User Guide. infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0395b/CIHCAGHH.html
Source: https://habr.com/ru/post/220203/
All Articles